Pattern Matching
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Pattern Matching Using Similarity Measures
Pattern matching using similarity measures Patroonvergelijking met behulp van gelijkenismaten (met een samenvatting in het Nederlands) PROEFSCHRIFT ter verkrijging van de graad van doctor aan de Universiteit Utrecht op gezag van Rector Magnificus, Prof. Dr. H. O. Voorma, ingevolge het besluit van het College voor Promoties in het openbaar te verdedigen op maandag 18 september 2000 des morgens te 10:30 uur door Michiel Hagedoorn geboren op 13 juli 1972, te Renkum promotor: Prof. Dr. M. H. Overmars Faculteit Wiskunde & Informatica co-promotor: Dr. R. C. Veltkamp Faculteit Wiskunde & Informatica ISBN 90-393-2460-3 PHILIPS '$ The&&% research% described in this thesis has been made possible by financial support from Philips Research Laboratories. The work in this thesis has been carried out in the graduate school ASCI. Contents 1 Introduction 1 1.1Patternmatching.......................... 1 1.2Applications............................. 4 1.3Obtaininggeometricpatterns................... 7 1.4 Paradigms in geometric pattern matching . 8 1.5Similaritymeasurebasedpatternmatching........... 11 1.6Overviewofthisthesis....................... 16 2 A theory of similarity measures 21 2.1Pseudometricspaces........................ 22 2.2Pseudometricpatternspaces................... 30 2.3Embeddingpatternsinafunctionspace............. 40 2.4TheHausdorffmetric........................ 46 2.5Thevolumeofsymmetricdifference............... 54 2.6 Reflection visibility based distances . 60 2.7Summary.............................. 71 2.8Experimentalresults....................... -

Pattern Matching Using Fuzzy Methods David Bell and Lynn Palmer, State of California: Genetic Disease Branch
Pattern Matching Using Fuzzy Methods David Bell and Lynn Palmer, State of California: Genetic Disease Branch ABSTRACT The formula is : Two major methods of detecting similarities Euclidean Distance and 2 a "fuzzy Hamming distance" presented in a paper entitled "F %%y Dij : ; ( <3/i - yj 4 Hamming Distance: A New Dissimilarity Measure" by Bookstein, Klein, and Raita, will be compared using entropy calculations to Euclidean distance is especially useful for comparing determine their abilities to detect patterns in data and match data matching whole word object elements of 2 vectors. The records. .e find that both means of measuring distance are useful code in Java is: depending on the context. .hile fuzzy Hamming distance outperforms in supervised learning situations such as searches, the Listing 1: Euclidean Distance Euclidean distance measure is more useful in unsupervised pattern matching and clustering of data. /** * EuclideanDistance.java INTRODUCTION * * Pattern matching is becoming more of a necessity given the needs for * Created: Fri Oct 07 08:46:40 2002 such methods for detecting similarities in records, epidemiological * * @author David Bell: DHS-GENETICS patterns, genetics and even in the emerging fields of criminal * @version 1.0 behavioral pattern analysis and disease outbreak analysis due to */ possible terrorist activity. 0nfortunately, traditional methods for /** Abstact Distance class linking or matching records, data fields, etc. rely on exact data * @param None matches rather than looking for close matches or patterns. 1f course * @return Distance Template proximity pattern matches are often necessary when dealing with **/ messy data, data that has inexact values and/or data with missing key abstract class distance{ values. -

CSCI 2041: Pattern Matching Basics
CSCI 2041: Pattern Matching Basics Chris Kauffman Last Updated: Fri Sep 28 08:52:58 CDT 2018 1 Logistics Reading Assignment 2 I OCaml System Manual: Ch I Demo in lecture 1.4 - 1.5 I Post today/tomorrow I Practical OCaml: Ch 4 Next Week Goals I Mon: Review I Code patterns I Wed: Exam 1 I Pattern Matching I Fri: Lecture 2 Consider: Summing Adjacent Elements 1 (* match_basics.ml: basic demo of pattern matching *) 2 3 (* Create a list comprised of the sum of adjacent pairs of 4 elements in list. The last element in an odd-length list is 5 part of the return as is. *) 6 let rec sum_adj_ie list = 7 if list = [] then (* CASE of empty list *) 8 [] (* base case *) 9 else 10 let a = List.hd list in (* DESTRUCTURE list *) 11 let atail = List.tl list in (* bind names *) 12 if atail = [] then (* CASE of 1 elem left *) 13 [a] (* base case *) 14 else (* CASE of 2 or more elems left *) 15 let b = List.hd atail in (* destructure list *) 16 let tail = List.tl atail in (* bind names *) 17 (a+b) :: (sum_adj_ie tail) (* recursive case *) The above function follows a common paradigm: I Select between Cases during a computation I Cases are based on structure of data I Data is Destructured to bind names to parts of it 3 Pattern Matching in Programming Languages I Pattern Matching as a programming language feature checks that data matches a certain structure the executes if so I Can take many forms such as processing lines of input files that match a regular expression I Pattern Matching in OCaml/ML combines I Case analysis: does the data match a certain structure I Destructure Binding: bind names to parts of the data I Pattern Matching gives OCaml/ML a certain "cool" factor I Associated with the match/with syntax as follows match something with | pattern1 -> result1 (* pattern1 gives result1 *) | pattern2 -> (* pattern 2.. -

Compiling Pattern Matching to Good Decision Trees
Submitted to ML’08 Compiling Pattern Matching to good Decision Trees Luc Maranget INRIA Luc.marangetinria.fr Abstract In this paper we study compilation to decision tree, whose We address the issue of compiling ML pattern matching to efficient primary advantage is never testing a given subterm of the subject decisions trees. Traditionally, compilation to decision trees is op- value more than once (and whose primary drawback is potential timized by (1) implementing decision trees as dags with maximal code size explosion). Our aim is to refine naive compilation to sharing; (2) guiding a simple compiler with heuristics. We first de- decision trees, and to compare the output of such an optimizing sign new heuristics that are inspired by necessity, a notion from compiler with optimized backtracking automata. lazy pattern matching that we rephrase in terms of decision tree se- Compilation to decision can be very sensitive to the testing mantics. Thereby, we simplify previous semantical frameworks and order of subject value subterms. The situation can be explained demonstrate a direct connection between necessity and decision by the example of an human programmer attempting to translate a ML program into a lower-level language without pattern matching. tree runtime efficiency. We complete our study by experiments, 1 showing that optimized compilation to decision trees is competi- Let f be the following function defined on triples of booleans : tive. We also suggest some heuristics precisely. l e t f x y z = match x,y,z with | _,F,T -> 1 Categories and Subject Descriptors D 3. 3 [Programming Lan- | F,T,_ -> 2 guages]: Language Constructs and Features—Patterns | _,_,F -> 3 | _,_,T -> 4 General Terms Design, Performance, Sequentiality. -

Combinatorial Pattern Matching
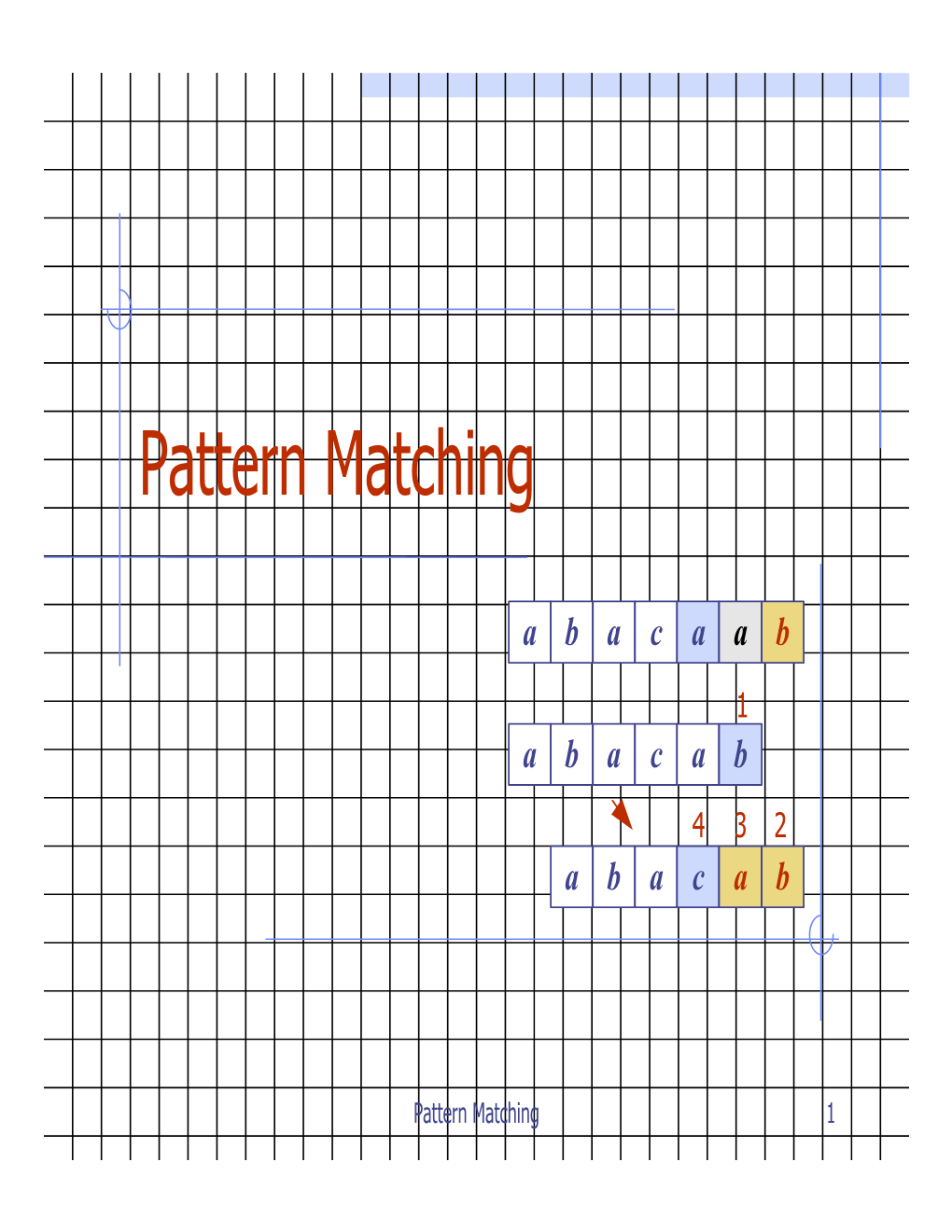
Combinatorial Pattern Matching 1 A Recurring Problem Finding patterns within sequences Variants on this idea Finding repeated motifs amoungst a set of strings What are the most frequent k-mers How many time does a specific k-mer appear Fundamental problem: Pattern Matching Find all positions of a particular substring in given sequence? 2 Pattern Matching Goal: Find all occurrences of a pattern in a text Input: Pattern p = p1, p2, … pn and text t = t1, t2, … tm Output: All positions 1 < i < (m – n + 1) such that the n-letter substring of t starting at i matches p def bruteForcePatternMatching(p, t): locations = [] for i in xrange(0, len(t)-len(p)+1): if t[i:i+len(p)] == p: locations.append(i) return locations print bruteForcePatternMatching("ssi", "imissmissmississippi") [11, 14] 3 Pattern Matching Performance Performance: m - length of the text t n - the length of the pattern p Search Loop - executed O(m) times Comparison - O(n) symbols compared Total cost - O(mn) per pattern In practice, most comparisons terminate early Worst-case: p = "AAAT" t = "AAAAAAAAAAAAAAAAAAAAAAAT" 4 We can do better! If we preprocess our pattern we can search more effciently (O(n)) Example: imissmissmississippi 1. s 2. s 3. s 4. SSi 5. s 6. SSi 7. s 8. SSI - match at 11 9. SSI - match at 14 10. s 11. s 12. s At steps 4 and 6 after finding the mismatch i ≠ m we can skip over all positions tested because we know that the suffix "sm" is not a prefix of our pattern "ssi" Even works for our worst-case example "AAAAT" in "AAAAAAAAAAAAAAT" by recognizing the shared prefixes ("AAA" in "AAAA"). -

Integrating Pattern Matching Within String Scanning a Thesis
Integrating Pattern Matching Within String Scanning A Thesis Presented in Partial Fulfillment of the Requirements for the Degree of Master of Science with a Major in Computer Science in the College of Graduate Studies University of Idaho by John H. Goettsche Major Professor: Clinton Jeffery, Ph.D. Committee Members: Robert Heckendorn, Ph.D.; Robert Rinker, Ph.D. Department Administrator: Frederick Sheldon, Ph.D. July 2015 ii Authorization to Submit Thesis This Thesis of John H. Goettsche, submitted for the degree of Master of Science with a Major in Computer Science and titled \Integrating Pattern Matching Within String Scanning," has been reviewed in final form. Permission, as indicated by the signatures and dates below, is now granted to submit final copies to the College of Graduate Studies for approval. Major Professor: Date: Clinton Jeffery, Ph.D. Committee Members: Date: Robert Heckendorn, Ph.D. Date: Robert Rinker, Ph.D. Department Administrator: Date: Frederick Sheldon, Ph.D. iii Abstract A SNOBOL4 like pattern data type and pattern matching operation were introduced to the Unicon language in 2005, but patterns were not integrated with the Unicon string scanning control structure and hence, the SNOBOL style patterns were not adopted as part of the language at that time. The goal of this project is to make the pattern data type accessible to the Unicon string scanning control structure and vice versa; and also make the pattern operators and functions lexically consistent with Unicon. To accomplish these goals, a Unicon string matching operator was changed to allow the execution of a pattern match in the anchored mode, pattern matching unevaluated expressions were revised to handle complex string scanning functions, and the pattern matching lexemes were revised to be more consistent with the Unicon language. -

Practical Authenticated Pattern Matching with Optimal Proof Size
Practical Authenticated Pattern Matching with Optimal Proof Size Dimitrios Papadopoulos Charalampos Papamanthou Boston University University of Maryland [email protected] [email protected] Roberto Tamassia Nikos Triandopoulos Brown University RSA Laboratories & Boston University [email protected] [email protected] ABSTRACT otherwise. More elaborate models for pattern matching involve We address the problem of authenticating pattern matching queries queries expressed as regular expressions over Σ or returning multi- over textual data that is outsourced to an untrusted cloud server. By ple occurrences of p, and databases allowing search over multiple employing cryptographic accumulators in a novel optimal integrity- texts or other (semi-)structured data (e.g., XML data). This core checking tool built directly over a suffix tree, we design the first data-processing problem has numerous applications in a wide range authenticated data structure for verifiable answers to pattern match- of topics including intrusion detection, spam filtering, web search ing queries featuring fast generation of constant-size proofs. We engines, molecular biology and natural language processing. present two main applications of our new construction to authen- Previous works on authenticated pattern matching include the ticate: (i) pattern matching queries over text documents, and (ii) schemes by Martel et al. [28] for text pattern matching, and by De- exact path queries over XML documents. Answers to queries are vanbu et al. [16] and Bertino et al. [10] for XML search. In essence, verified by proofs of size at most 500 bytes for text pattern match- these works adopt the same general framework: First, by hierarchi- ing, and at most 243 bytes for exact path XML search, indepen- cally applying a cryptographic hash function (e.g., SHA-2) over the dently of the document or answer size. -

Pattern Matching
Pattern Matching Document #: P1371R1 Date: 2019-06-17 Project: Programming Language C++ Evolution Reply-to: Sergei Murzin <[email protected]> Michael Park <[email protected]> David Sankel <[email protected]> Dan Sarginson <[email protected]> Contents 1 Revision History 3 2 Introduction 3 3 Motivation and Scope 3 4 Before/After Comparisons4 4.1 Matching Integrals..........................................4 4.2 Matching Strings...........................................4 4.3 Matching Tuples...........................................4 4.4 Matching Variants..........................................5 4.5 Matching Polymorphic Types....................................5 4.6 Evaluating Expression Trees.....................................6 4.7 Patterns In Declarations.......................................8 5 Design Overview 9 5.1 Basic Syntax.............................................9 5.2 Basic Model..............................................9 5.3 Types of Patterns........................................... 10 5.3.1 Primary Patterns....................................... 10 5.3.1.1 Wildcard Pattern................................. 10 5.3.1.2 Identifier Pattern................................. 10 5.3.1.3 Expression Pattern................................ 10 5.3.2 Compound Patterns..................................... 11 5.3.2.1 Structured Binding Pattern............................ 11 5.3.2.2 Alternative Pattern................................ 12 5.3.2.3 Parenthesized Pattern............................... 15 5.3.2.4 Case Pattern................................... -

Pattern Matching
Pattern Matching Gonzalo Navarro Department of Computer Science University of Chile Abstract An important subtask of the pattern discovery process is pattern matching, where the pattern sought is already known and we want to determine how often and where it occurs in a sequence. In this paper we review the most practical techniques to find patterns of different kinds. We show how regular expressions can be searched for with general techniques, and how simpler patterns can be dealt with more simply and efficiently. We consider exact as well as approximate pattern matching. Also, we cover both sequential searching, where the sequence cannot be preprocessed, and indexed searching, where we have a data structure built over the sequence to speed up the search. 1 Introduction A central subproblem in pattern discovery is to determine how often a candidate pattern occurs, as well as possibly some information on its frequency distribution across the text. In general, a pattern will be a description of a (finite or infinite) set of strings, each string being a sequence of symbols. Usually, a good pattern must be as specific (that is, denote a small set of strings) and as frequent as possible. Hence, given a candidate pattern, it is usual to ask for its frequency, as well as to examine its occurrences looking for more specific instances of the pattern that are frequent enough. In this paper we focus on pattern matching. Given a known pattern (which can be more general or more specific), we wish to count how many times it occurs in the text, and to point out its occurrence positions. -

Pattern Matching
Pattern Matching An Introduction to File Globs and Regular Expressions Copyright 20062009 Stewart Weiss The danger that lies ahead Much to your disadvantage, there are two different forms of patterns in UNIX, one used when representing file names, and another used by commands, such as grep, sed, awk, and vi. You need to remember that the two types of patterns are different. Still worse, the textbook covers both of these in the same chapter, and I will do the same, so as not to digress from the order in the book. This will make it a little harder for you, but with practice you will get the hang of it. 2 CSci 132 Practical UNIX with Perl File globs In card games, a wildcard is a playing card that can be used as if it were any other card, such as the Joker. Computer science has borrowed the idea of a wildcard, and taken it several steps further. All shells give you the ability to write patterns that represent sets of filenames, using special characters called wildcards. (These patterns are not regular expressions, but they look like them.) The patterns are called file globs. The name "glob" comes from the name of the original UNIX program that expanded the pattern into a set of matching filenames. A string is a wildcard pattern if it contains one of the characters '?', '*' or '['. 3 CSci 132 Practical UNIX with Perl File glob rules Rule 1: a character always matches itself, except for the wildcards. So a matches 'a' and 'b' matches 'b' and so on. -

Regular Expressions and Pattern Matching [email protected]
Regular Expressions and Pattern Matching [email protected] Regular Expression (regex): a separate language, allowing the construction of patterns. used in most programming languages. very powerful in Perl. Pattern Match: using regex to search data and look for a match. Overview: how to create regular expressions how to use them to match and extract data biological context So Why Regex? Parse files of data and information: fasta embl / genbank format html (web-pages) user input to programs Check format Find illegal characters (validation) Search for sequences motifs Simple Patterns place regex between pair of forward slashes (/ /). try: #!/usr/bin/perl while (<STDIN>) { if (/abc/) { print “1 >> $_”; } } Run the script. Type in something that contains abc: abcfoobar Type in something that doesn't: fgh cba foobar ab c foobar print statement is returned if abc is matched within the typed input. Simple Patterns (2) Can also match strings from files. genomes_desc.txt contains a few text lines containing information about three genomes. try: #!/usr/bin/perl open IN, “<genomes_desc.txt”; while (<IN>) { if (/elegans/) { #match lines with this regex print; #print lines with match } } Parses each line in turn. Looks for elegans anywhere in line $_ Flexible matching There are many characters with special meanings – metacharacters. star (*) matches any number of instances /ab*c/ => 'a' followed by zero or more 'b' followed by 'c' => abc or abbbbbbbc or ac plus (+) matches at least one instance /ab+c/ => 'a' followed by one or more 'b' followed by 'c' => abc or abbc or abbbbbbbbbbbbbbc NOT ac question mark (?) matches zero or one instance /ab?c/ => 'a' followed by 0 or 1 'b' followed by 'c' => abc or ac More General Quantifiers Match a character a specific number or range of instances {x} will match x number of instances. -

Cartesian Tree Matching and Indexing
Cartesian Tree Matching and Indexing Sung Gwan Park Seoul National University, Korea [email protected] Amihood Amir Bar-Ilan University, Israel [email protected] Gad M. Landau University of Haifa, Israel and New York University, USA [email protected] Kunsoo Park1 Seoul National University, Korea [email protected] Abstract We introduce a new metric of match, called Cartesian tree matching, which means that two strings match if they have the same Cartesian trees. Based on Cartesian tree matching, we define single pattern matching for a text of length n and a pattern of length m, and multiple pattern matching for a text of length n and k patterns of total length m. We present an O(n + m) time algorithm for single pattern matching, and an O((n + m) log k) deterministic time or O(n + m) randomized time algorithm for multiple pattern matching. We also define an index data structure called Cartesian suffix tree, and present an O(n) randomized time algorithm to build the Cartesian suffix tree. Our efficient algorithms for Cartesian tree matching use a representation of the Cartesian tree, called the parent-distance representation. 2012 ACM Subject Classification Theory of computation → Pattern matching Keywords and phrases Cartesian tree matching, Pattern matching, Indexing, Parent-distance representation Digital Object Identifier 10.4230/LIPIcs.CPM.2019.13 1 Introduction String matching is one of fundamental problems in computer science, and it can be applied to many practical problems. In many applications string matching has variants derived from exact matching (which can be collectively called generalized matching), such as order- preserving matching [19, 20, 22], parameterized matching [4, 7, 8], jumbled matching [9], overlap matching [3], pattern matching with swaps [2], and so on.