Introduction to Unix Part 2: Looking Into a File Now We Want to See How the Files Are Structured
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Application for a Certificate of Eligibility to Employ Child Performers
Division of Labor Standards Permit and Certificate Unit Harriman State Office Campus Building 12, Room 185B Albany, NY 12240 www.labor.ny.gov Application for a Certificate of Eligibility to Employ Child Performers A. Submission Instructions A Certificate of Eligibility to Employ Child Performers must be obtained prior to employing any child performer. Certificates are renew able every three (3) years. To obtain or renew a certificate: • Complete Parts B, C, D and E of this application. • Attach proof of New York State Workers’ Compensation and Disability Insurance. o If you currently have employees in New York, you must provide proof of coverage for those New York State w orkers by attaching copies of Form C-105.2 and DB-120.1, obtainable from your insurance carrier. o If you are currently exempt from this requirement, complete Form CE-200 attesting that you are not required to obtain New York State Workers’ Compensation and Disability Insurance Coverage. Information on and copies of this form are available from any district office of the Workers’ Compensation Board or from their w ebsite at w ww.wcb.ny.gov, Click on “WC/DB Exemptions,” then click on “Request for WC/DB Exemptions.” • Attach a check for the correct amount from Section D, made payable to the Commissioner of Labor. • Sign and mail this completed application and all required documents to the address listed above. If you have any questions, call (518) 457-1942, email [email protected] or visit the Department’s w ebsite at w ww.labor.ny.gov B. Type of Request (check one) New Renew al Current certificate number _______________________________________________ Are you seeking this certificate to employ child models? Yes No C. -

Program #6: Word Count
CSc 227 — Program Design and Development Spring 2014 (McCann) http://www.cs.arizona.edu/classes/cs227/spring14/ Program #6: Word Count Due Date: March 11 th, 2014, at 9:00 p.m. MST Overview: The UNIX operating system (and its variants, of which Linux is one) includes quite a few useful utility programs. One of those is wc, which is short for Word Count. The purpose of wc is to give users an easy way to determine the size of a text file in terms of the number of lines, words, and bytes it contains. (It can do a bit more, but that’s all of the functionality that we are concerned with for this assignment.) Counting lines is done by looking for “end of line” characters (\n (ASCII 10) for UNIX text files, or the pair \r\n (ASCII 13 and 10) for Windows/DOS text files). Counting words is also straight–forward: Any sequence of characters not interrupted by “whitespace” (spaces, tabs, end–of–line characters) is a word. Of course, whitespace characters are characters, and need to be counted as such. A problem with wc is that it generates a very minimal output format. Here’s an example of what wc produces on a Linux system when asked to count the content of a pair of files; we can do better! $ wc prog6a.dat prog6b.dat 2 6 38 prog6a.dat 32 321 1883 prog6b.dat 34 327 1921 total Assignment: Write a Java program (completely documented according to the class documentation guidelines, of course) that counts lines, words, and bytes (characters) of text files. -

DC Console Using DC Console Application Design Software
DC Console Using DC Console Application Design Software DC Console is easy-to-use, application design software developed specifically to work in conjunction with AML’s DC Suite. Create. Distribute. Collect. Every LDX10 handheld computer comes with DC Suite, which includes seven (7) pre-developed applications for common data collection tasks. Now LDX10 users can use DC Console to modify these applications, or create their own from scratch. AML 800.648.4452 Made in USA www.amltd.com Introduction This document briefly covers how to use DC Console and the features and settings. Be sure to read this document in its entirety before attempting to use AML’s DC Console with a DC Suite compatible device. What is the difference between an “App” and a “Suite”? “Apps” are single applications running on the device used to collect and store data. In most cases, multiple apps would be utilized to handle various operations. For example, the ‘Item_Quantity’ app is one of the most widely used apps and the most direct means to take a basic inventory count, it produces a data file showing what items are in stock, the relative quantities, and requires minimal input from the mobile worker(s). Other operations will require additional input, for example, if you also need to know the specific location for each item in inventory, the ‘Item_Lot_Quantity’ app would be a better fit. Apps can be used in a variety of ways and provide the LDX10 the flexibility to handle virtually any data collection operation. “Suite” files are simply collections of individual apps. Suite files allow you to easily manage and edit multiple apps from within a single ‘store-house’ file and provide an effortless means for device deployment. -
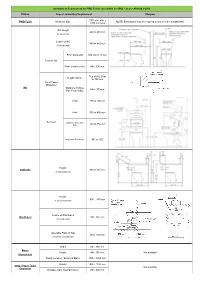
Summary of Requirement for PWD Toilets (Not Within an SOU) – As Per AS1428.1-2009
Summary of Requirement for PWD Toilets (not within an SOU) – as per AS1428.1-2009 Fixture Aspect and/or Key Requirement Diagram 1900 mm wide x PWD Toilet Minimum Size NOTE: Extra space may be required to allow for the a washbasin. 2300 mm long WC Height 460 to 480 mm (to top of seat) Centre of WC 450 to 460 mm (from side wall) From back wall 800 mm ± 10 mm Front of WC From cistern or like Min. 600 mm Top of WC Seat Height of Zone to 700 mm Toilet Paper Dispenser WC Distance of Zone Max. 300mm from Front of QC Height 150 to 200 mm Width 350 to 400 mm Backrest Distance above WC Seat 120 to 150 mm Angle from Seat Hinge 90° to 100° Height Grabrails 800 to 810 mm (to top of grab rail) Height 800 – 830 mm (to top of washbasin) Centre of Washbasin Washbasin Min. 425 mm (from side wall) Operable Parts of Tap Max. 300 mm (from front of washbasin) Width Min. 350 mm Mirror Height Min. 950 mm Not available (if provided) Fixing Location / Extent of Mirror 900 – 1850 mm Height 900 – 1100 mm Soap / Paper Towel Not available Dispenser Distance from Internal Corner Min. 500 mm Summary of Requirement for PWD Toilets (not within an SOU) – as per AS1428.1-2009 Fixture Aspect and/or Key Requirement Diagram Height 1200 – 1350 mm PWD Clothes Hook Not available Distance from Internal Corner Min. 500 mm Height 800 – 830 mm As vanity bench top Width Min. 120 mm Depth 300 – 400 mm Shelves Not available Height 900 – 1000 mm As separate fixture (if within any required Width 120 – 150 mm circulation space) Length 300 – 400 mm Width Min. -

Useful Commands in Linux and Other Tools for Quality Control
Useful commands in Linux and other tools for quality control Ignacio Aguilar INIA Uruguay 05-2018 Unix Basic Commands pwd show working directory ls list files in working directory ll as before but with more information mkdir d make a directory d cd d change to directory d Copy and moving commands To copy file cp /home/user/is . To copy file directory cp –r /home/folder . to move file aa into bb in folder test mv aa ./test/bb To delete rm yy delete the file yy rm –r xx delete the folder xx Redirections & pipe Redirection useful to read/write from file !! aa < bb program aa reads from file bb blupf90 < in aa > bb program aa write in file bb blupf90 < in > log Redirections & pipe “|” similar to redirection but instead to write to a file, passes content as input to other command tee copy standard input to standard output and save in a file echo copy stream to standard output Example: program blupf90 reads name of parameter file and writes output in terminal and in file log echo par.b90 | blupf90 | tee blup.log Other popular commands head file print first 10 lines list file page-by-page tail file print last 10 lines less file list file line-by-line or page-by-page wc –l file count lines grep text file find lines that contains text cat file1 fiel2 concatenate files sort sort file cut cuts specific columns join join lines of two files on specific columns paste paste lines of two file expand replace TAB with spaces uniq retain unique lines on a sorted file head / tail $ head pedigree.txt 1 0 0 2 0 0 3 0 0 4 0 0 5 0 0 6 0 0 7 0 0 8 0 0 9 0 0 10 -

Install and Run External Command Line Softwares
job monitor and control top: similar to windows task manager (space to refresh, q to exit) w: who is there ps: all running processes, PID, status, type ps -ef | grep yyin bg: move current process to background fg: move current process to foreground jobs: list running and suspended processes kill: kill processes kill pid (could find out using top or ps) 1 sort, cut, uniq, join, paste, sed, grep, awk, wc, diff, comm, cat All types of bioinformatics sequence analyses are essentially text processing. Unix Shell has the above commands that are very useful for processing texts and also allows the output from one command to be passed to another command as input using pipe (“|”). less cosmicRaw.txt | cut -f2,3,4,5,8,13 | awk '$5==22' | cut -f1 | sort -u | wc This makes the processing of files using Shell very convenient and very powerful: you do not need to write output to intermediate files or load all data into the memory. For example, combining different Unix commands for text processing is like passing an item through a manufacturing pipeline when you only care about the final product 2 Hands on example 1: cosmic mutation data - Go to UCSC genome browser website: http://genome.ucsc.edu/ - On the left, find the Downloads link - Click on Human - Click on Annotation database - Ctrl+f and then search “cosmic” - On “cosmic.txt.gz” right-click -> copy link address - Go to the terminal and wget the above link (middle click or Shift+Insert to paste what you copied) - Similarly, download the “cosmicRaw.txt.gz” file - Under your home, create a folder -

Programmable AC/DC Electronic Load
Programmable AC/DC Electronic Load Programming Guide for IT8600 Series Model: IT8615/IT8615L/IT8616/IT8617 /IT8624/IT8625/IT8626/IT8627/IT8628 Version: V2.3 Notices Warranty Safety Notices © ItechElectronic, Co., Ltd. 2019 No part of this manual may be The materials contained in this reproduced in any form or by any means document are provided .”as is”, and (including electronic storage and is subject to change, without prior retrieval or translation into a foreign notice, in future editions. Further, to A CAUTION sign denotes a language) without prior permission and the maximum extent permitted by hazard. It calls attention to an written consent from Itech Electronic, applicable laws, ITECH disclaims operating procedure or practice Co., Ltd. as governed by international all warrants, either express or copyright laws. implied, with regard to this manual that, if not correctly performed and any information contained or adhered to, could result in Manual Part Number herein, including but not limited to damage to the product or loss of IT8600-402266 the implied warranties of important data. Do not proceed merchantability and fitness for a beyond a CAUTION sign until Revision particular purpose. ITECH shall not the indicated conditions are fully be held liable for errors or for 2nd Edition: Feb. 20, 2019 understood and met. incidental or indirect damages in Itech Electronic, Co., Ltd. connection with the furnishing, use or application of this document or of Trademarks any information contained herein. A WARNING sign denotes a Pentium is U.S. registered trademarks Should ITECh and the user enter of Intel Corporation. into a separate written agreement hazard. -

Program That Runs Other Programs Unix/Linux Process Hierarchy Shell
shell: program that runs other programs Building a Shell 1 5 Unix/Linux Process Hierarchy shell program that runs other programs on behalf of the user sh Original Unix shell (Stephen Bourne, AT&T Bell Labs, 1977) [0] bash “Bourne-Again” Shell, widely used default on most Unix/Linux/Mac OS X systems others.. init [1] while (true) { Print command prompt. Daemon Login shell Read command line from user. e.g. httpd Parse command line. If command is built-in, do it. Child Child Child Else fork process to execute command. in child: Execute requested command with execv. (never returns) Grandchild Grandchild in parent: Wait for child to complete. } 6 7 1 terminal ≠ shell Background vs. Foreground User interface to shell and other programs. Users generally run one command at a time Graphical (GUI) vs. command-line (CLI) Type command, read output, type another command Command-line terminal (emulator): Input (keyboard) Some programs run “for a long time” Output (screen) $ emacs fizz. txt # shell stuck until ema cs exi ts. A “background” job is a process we don't want to wait for $ emacs boom. txt & # em acs ru ns in backg round [1] 9073 # wh ile sh ell i s... $ gdb ./ umbre lla # im mediat ely r eady f or nex t com mand don't do this with emacs un l es s u si n g X wi nd o ws vers i o n 8 9 Managing Background Jobs Signals Signal: small message notifying a process of event in system Shell waits for and reaps foreground jobs. -

Student Batch File Layout – Version 1.0
Student Batch File Layout – Version 1.0 This document shall set forth the layout of the Student Batch File that will be used for feeding student records into the Uniq-ID System for id assignment and/or student information updates. The Student Batch File should contain three different types of records. The three types of records are: (1) Header record (2) Detail Record (3) Trailer Record. The Header and Trailer record should be delimited by a single tab or space character. The Detail records can be either tab or comma delimited and the Header record should identify which type is being used (in the delimiter field). All records should be delimited from each by the source operating system’s end of line character or character sequence. In the Uniq-ID System, errors in the Student Batch File will be handled in two different ways. One way is to flag the particular record and allow the user to repair it in the “Fix Errors” stage. The other way is to reject the entire Student Batch File and require that the user resubmit it. Rejection of a Student Batch File will occur if: 1. One or more record types are missing. 2. One or more fields have been omitted from a record. 3. The “Number of Records” field in the trailer record is incorrect. 4. The “Transmission ID” fields in the header and trailer records do not match. 5. The maximum allowable number of detail record errors has been exceeded. 6. The maximum allowable number of records in the entire file has been exceeded. -

DC Load Application Note
DC Electronic Load Applications and Examples Application Note V 3032009 22820 Savi Ranch Parkway Yorba Linda CA, 92887-4610 www.bkprecision.com Table of Contents INTRODUCTION.........................................................................................................................3 Overview of software examples........................................................................................................3 POWER SUPPLY TESTING.......................................................................................................4 Load Transient Response.................................................................................................................4 Load Regulation................................................................................................................................5 Current Limiting................................................................................................................................6 BATTERY TESTING...................................................................................................................7 Battery Discharge Curves.................................................................................................................7 Battery Internal Resistances.............................................................................................................8 PERFORMANCE TESTING OF DC LOADS...........................................................................10 Slew Rate.......................................................................................................................................10 -

CS2043 - Unix Tools & Scripting Cornell University, Spring 20141
CS2043 - Unix Tools & Scripting Cornell University, Spring 20141 Instructor: Bruno Abrahao January 31, 2014 1 Slides evolved from previous versions by Hussam Abu-Libdeh and David Slater Instructor: Bruno Abrahao CS2043 - Unix Tools & Scripting Vim: Tip of the day! Line numbers Displays line number in Vim: :set nu Hides line number in Vim: :set nonu Goes to line number: :line number Instructor: Bruno Abrahao CS2043 - Unix Tools & Scripting Counting wc How many lines of code are in my new awesome program? How many words are in this document? Good for bragging rights Word, Character, Line, and Byte count with wc wc -l : count the number of lines wc -w : count the number of words wc -m : count the number of characters wc -c : count the number of bytes Instructor: Bruno Abrahao CS2043 - Unix Tools & Scripting Sorting sort Sorts the lines of a text file alphabetically. sort -ru file sorts the file in reverse order and deletes duplicate lines. sort -n -k 2 -t : file sorts the file numerically by using the second column, separated by a colon Example Consider a file (numbers.txt) with the numbers 1, 5, 8, 11, 62 each on a separate line, then: $ sort numbers.txt $ sort numbers.txt -n 1 1 11 5 5 8 62 11 8 62 Instructor: Bruno Abrahao CS2043 - Unix Tools & Scripting uniq uniq uniq file - Discards all but one of successive identical lines uniq -c file - Prints the number of successive identical lines next to each line Instructor: Bruno Abrahao CS2043 - Unix Tools & Scripting Character manipulation! The Translate Command tr [options] <char_list1> [char_list2] Translate or delete characters char lists are strings of characters By default, searches for characters in char list1 and replaces them with the ones that occupy the same position in char list2 Example: tr 'AEIOU' 'aeiou' - changes all capital vowels to lower case vowels Instructor: Bruno Abrahao CS2043 - Unix Tools & Scripting Pipes and redirection tr only receives input from standard input (stdin) i.e. -

Cash Valves Ls Series Pressure Reducing and Regulating Valves
CASH VALVES LS SERIES PRESSURE REDUCING AND REGULATING VALVES High pressure single-seated, spring loaded, direct acting diaphragm type regulators for inlet pressures to 2400 psig (165.5 barg) FEATURES • Automatically reduce high inlet pressures to lower outlet pressures within close limits regardless of fluctuations. • Designed for use on air, water, oil, oxygen, carbon-dioxide and other gases and fluids. • Designed and built to meet the rugged requirements of high pressure regulation and reduction. • Exceptional flow characteristics. • Stainless steel piston/piston assemblies, cylinders, seat ring and strainer screens as standard. • NBR diaphragm and O-rings. • Self-renewable seat ring is simply flipped over and re-installed rather than replaced. • NPTF ‘Dryseal’ threaded ends as standard. • Closing cap or T-handle adjusting screw options available. GENERAL APPLICATION TECHNICAL DATA Type LS Series regulators are recommended Materials: Bronze for use on high pressure test rigs and pressure Sizes: ⅜”, ½”, ¾” (10.5, vessel or casting test equipment, hydraulic 15, 19 mm) cylinders and air tanks. Also available for Connections: Threaded NPTF cryogenic service. Inlet pressure range: 500 to 2400 psig (34.5 to 165.5 barg) Reduced pressure range: 40 to 500 psig (2.8 to 34.5 barg) Temperature range: -320° to 180°F (-195° to 82°C) Emerson.com/FinalControl © 2017 Emerson. All Rights Reserved. VCTDS-00513-EN 17/07 CASH VALVES LS SERIES PRESSURE REDUCING AND REGULATING VALVES MODELS OVERVIEW Type LS-3 is furnished with a modified cylinder and no strainer screen for applications All LS Series valves are designed and built involving heavy or high viscosity fluids. to meet the rugged requirements of a high pressure regulating and reducing valve with a Type LS-4 is constructed for cryogenic service bronze body, spring chamber and bottom plug.