Latent Relation Language Models
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

26MF321B LCD TV English
Owner’s Manual Manuel du Propriétaire Manual del Propietario 26MF321B LCD TV English Necesita ayuda inmediata? Français Español 1-866-341-3738 1-866-341-3738 1-866-341-3738 Quick Use Guide Inside! Guide d’usage Rapide Incluse! Guía de Uso Rápido Incluida! MODEL NUMBER SERIAL NUMBER 2 Return your Product Registration Card or visit at www.magnavox.com/support today to get the very most from your purchase. Registering your model with MAGNAVOX makes you eligible for all of the valuable benefits listed below, so don't miss out. Complete and return your Product Registration Card at once or visit at www.magnavox.com/support to ensure: *Product Safety Notification *Additional Benefits By registering your product, you'll receive notification - Registering your product guarantees that you'll receive directly from the manufacturer - in the rare case of a all of the privileges to which you're entitled, including product recall or safety defect. special money-saving offers. Know these safety symbols The lightning flash with arrowhead symbol, within an equilateral triangle, is intended to alert the user to the presence of CAUTION uninsulated “dangerous voltage” within the apparatus’s enclosure that may be of sufficient magnitude to constitute a risk of RISK OF ELECTRIC SHOCK electric shock to persons. DO NOT OPEN CAUTION: TO REDUCE THE RISK OF ELECTRIC SHOCK, DO NOT The exclamation point within an equilateral triangle is intended to REMOVE COVER (OR BACK). NO USER-SERVICEABLE PARTS alert the user to the presence of important operating and INSIDE. REFER SERVICING TO QUALIFIED SERVICE PERSONNEL. maintenance (servicing) instructions in the literature accompanying The caution marking is located on the rear or bottom of the cabinet. -

Présentation Powerpoint
Compatible Games 1941 Frozen Front Chicken Invaders Dr. Droid 3D MOTOR Chicken Invaders 2 DRAG racing 4 seasons Hunt 3D Chicken Invaders 3 Dream League Soccer Acceler 8 Chicken Invaders 4 Dungeon Hunter 3 Aces of the Luftwaffe Chrono&Cash Dungeon Hunter4 Aftermath XHD Clash - Space Shooter Dungeon Quest Angry Birds GO Cordy EDGE Extended Another World Cordy 2 EtERNITY WARRIORS Antigen Crazy Snowboard ETERNITY WARRIORS 2 Arma Tactics Critter Rollers EVAC HD Army Academy CS portable Everland: Unleashed Asphalt 5 Cup! Cup! Golf 3D! ExZeus Asphalt 6 Dark Incursion ExZeus 2 Asphalt 7 DB42 Farm Invasion USA Asphalt 8 Airborne Dead Effect Farming Simulator Asteriod 2012 Dead Rushing HD Fields Of Battle Auralux Dead Space Final Freeway 2R Avenger Dead Trigger FIST OF AWESOME AVP: Evolution Dead Trigger 2 Forsaken Planet B.M.Snowboard Free DEER HUNTER 2012 Fractal Combat Babylonian Twins Platform Game DEER HUNTER 2013 Fright fight Bermuda Dash DEER HUNTER 2014 Gangstar Vegas Beyond Ynth Dig! Grand Theft Auto : Vice City Beyond Ynth Xams edition Digger HD Grand Theft Auto III Bike Mania Dink smallwood Gravi Bird Bomb Diversion Grudger Blasto! Invaders Dizzy - Prince of the Yolkfolk GT Racing 2 Blazing Souls Acceleration Doom GLES Guns n Glory Block Story Doptrix Gunslugs Brotherhood of Violence II Double Dragon Trilogy Halloween Temple'n Zombies Run Compatible Games Helium Boy Demo Overdroy Sonic 4 Episode II Heretik GLEX Particle arcade shooter Sonic CD Heroes of Loot PewPew Sonic Racing transformed Hexen GLES Pinball Arcade Sonic the Hedgehog -

Equipment Setup and Self-Installation Programming Your WOW! Atlas Universal Remote Control
table of contents WOW! equipment setup and self-installation Programming Your WOW! Atlas Universal Remote Control ...........................................................E-1 Programming Channel Control Lock ......................................................................................................E-3 Programming ID Lock ..................................................................................................................................E-3 Programming “Tune-In” Keys For Specific Channels ........................................................................E-4 table of contents Using The Master Power Key ....................................................................................................................E-4 Re-Assigning Device Keys ..........................................................................................................................E-5 Changing Volume Lock ...............................................................................................................................E-5 Atlas Cable Remote Control Codes ........................................................................................................E-7 Digital Cable Self-Installation ..................................................................................................................E-13 Advanced Digital Equipment Setup .....................................................................................................E-16 Connecting a Non-Stereo TV .............................................................................................................E-16 -

Verbatim Inside
VOLUME 53, ISSUE 18 MONDAY, FEBRUARY 24, 2020 WWW.UCSDGUARDIAN.ORG LABOR PHOTOSPORTS: TEASE ?E$"FG#H+1%-# MEN’S VOLLEYBALL GOES HERE IJKK#G&4+20)0# B)2&()#$%&4)20 Sanders has been a vocal proponent of the union’s goals for years. !.##2;A&'K=%#+T=T>=GL; .%#(&$/0($#1'+&$("& The University of California’s largest employment union, the American Federation of State, County, and Municipal Employees Local 3299, announced their decision to PHOTO BY NAME HERE /GUARDIAN endorse Bernie Sanders for President ahead of California’s CAPTION"...UCSD PREVIEWING was able to Estelle performing at Warren Live 2020 // Photo by Ellie Wang 2020 Democratic Primary on Feb. THEdominate ARTICLE in PAIRED every facet WITH 14. The endorsement comes two ofTHE the PHOTO game TEASE.in the win, FOR weeks before the state’s election day on March 3. EXAMPLEshowing o IFf THEa balanced PHOTO CAMPUS attackWERE onOF oAf BABYense, YOUcrisp In an interview with the Times of San Diego, AFSCME Local WOULDpassing, SAY and “BABIES great team SUCK! !"$'#8)9)9:)20#;<=>)%2#?&&(5)20%2@#+A #B-%1C#D(&.)2 THEY ARE WEAK AND 3299 Executive Vice President chemistry." !"##$%&"##$'(')%&###!"#$%&'!()**'+&$("& Michael Avant explained that the reasoning behind the +38$1/2C##0,H3##ESports, page 16 he Associated Students Office of which focused on a wide range of topics Diversity, Equity, & Inclusion and the including the panelists’ personal involvement endorsement was because of +18I23++##0/-1813+ Black Student Union held an event in with student organization during Black Winter the union’s push for collective *+*,--.##/0121/2##$3,+3 Tremembrance of the ten-year anniversary of and how non-black students can be effective bargaining rights. -
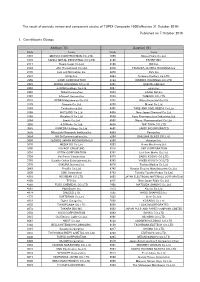
Published on 7 October 2016 1. Constituents Change the Result Of
The result of periodic review and component stocks of TOPIX Composite 1500(effective 31 October 2016) Published on 7 October 2016 1. Constituents Change Addition( 70 ) Deletion( 60 ) Code Issue Code Issue 1810 MATSUI CONSTRUCTION CO.,LTD. 1868 Mitsui Home Co.,Ltd. 1972 SANKO METAL INDUSTRIAL CO.,LTD. 2196 ESCRIT INC. 2117 Nissin Sugar Co.,Ltd. 2198 IKK Inc. 2124 JAC Recruitment Co.,Ltd. 2418 TSUKADA GLOBAL HOLDINGS Inc. 2170 Link and Motivation Inc. 3079 DVx Inc. 2337 Ichigo Inc. 3093 Treasure Factory Co.,LTD. 2359 CORE CORPORATION 3194 KIRINDO HOLDINGS CO.,LTD. 2429 WORLD HOLDINGS CO.,LTD. 3205 DAIDOH LIMITED 2462 J-COM Holdings Co.,Ltd. 3667 enish,inc. 2485 TEAR Corporation 3834 ASAHI Net,Inc. 2492 Infomart Corporation 3946 TOMOKU CO.,LTD. 2915 KENKO Mayonnaise Co.,Ltd. 4221 Okura Industrial Co.,Ltd. 3179 Syuppin Co.,Ltd. 4238 Miraial Co.,Ltd. 3193 Torikizoku co.,ltd. 4331 TAKE AND GIVE. NEEDS Co.,Ltd. 3196 HOTLAND Co.,Ltd. 4406 New Japan Chemical Co.,Ltd. 3199 Watahan & Co.,Ltd. 4538 Fuso Pharmaceutical Industries,Ltd. 3244 Samty Co.,Ltd. 4550 Nissui Pharmaceutical Co.,Ltd. 3250 A.D.Works Co.,Ltd. 4636 T&K TOKA CO.,LTD. 3543 KOMEDA Holdings Co.,Ltd. 4651 SANIX INCORPORATED 3636 Mitsubishi Research Institute,Inc. 4809 Paraca Inc. 3654 HITO-Communications,Inc. 5204 ISHIZUKA GLASS CO.,LTD. 3666 TECNOS JAPAN INCORPORATED 5998 Advanex Inc. 3678 MEDIA DO Co.,Ltd. 6203 Howa Machinery,Ltd. 3688 VOYAGE GROUP,INC. 6319 SNT CORPORATION 3694 OPTiM CORPORATION 6362 Ishii Iron Works Co.,Ltd. 3724 VeriServe Corporation 6373 DAIDO KOGYO CO.,LTD. 3765 GungHo Online Entertainment,Inc. -

VHS to DVD Manual
Introduction Connections ZV427FX4 ZV427FX4 A DVD Recorder/VCR LINE-IN RECORDING (No Tuner) Basic Setup Owner's Manual Recording INSTRUCCIONES EN ESPAÑOL INCLUIDAS. Playback Editing Function Setup VCR Functions Others Español © 2013 Funai Electric Co., Ltd. SAFETY INFORMATION The model and serial numbers of this unit may be found on the cabinet. Model No.: You should record and retain those numbers for future reference. Serial No.: WARNING: TO REDUCE THE RISK OF FIRE OR ELECTRIC SHOCK, DO NOT EXPOSE THIS APPARATUS TO RAIN OR MOISTURE. APPARATUS SHALL NOT BE EXPOSED TO DRIPPING OR SPLASHING AND NO OBJECTS FILLED WITH LIQUIDS, SUCH AS VASES, SHALL BE PLACED ON THE APPARATUS. The lightning flash with arrowhead symbol, within an CAUTION equilateral triangle, is intended to alert the user to the RISK OF ELECTRIC SHOCK presence of uninsulated “dangerous voltage” within the DO NOT OPEN product’s enclosure that may be of sufficient magnitude to constitute a risk of electric shock to persons. CAUTION: TO REDUCE THE RISK OF ELECTRIC SHOCK, DO NOT The exclamation point within an equilateral triangle is REMOVE COVER (OR BACK). NO USER SERVICEABLE intended to alert the user to the presence of important operating and maintenance (servicing) instructions in PARTS INSIDE. REFER SERVICING TO QUALIFIED the literature accompanying the appliance. SERVICE PERSONNEL. The importantp note and rating are located on the rear or The symbol for CLASS ll (Double Insulation) bottom of the cabinet. IMPORTANT SAFETY INSTRUCTIONS 1. Read these instructions. 10. Protect the powerpgp cord from being walked on 2. Keep these instructions. or pinchedpp particularlypypg ypg at plugs, convenience 3. -

Sailor Mars Meet Maroku
sailor mars meet maroku By GIRNESS Submitted: August 11, 2005 Updated: August 11, 2005 sailor mars and maroku meet during a battle then fall in love they start to go futher and futher into their relationship boy will sango be mad when she comes back =:) hope you like it Provided by Fanart Central. http://www.fanart-central.net/stories/user/GIRNESS/18890/sailor-mars-meet-maroku Chapter 1 - sango leaves 2 Chapter 2 - sango leaves 15 1 - sango leaves Fanart Central A.whitelink { COLOR: #0000ff}A.whitelink:hover { BACKGROUND-COLOR: transparent}A.whitelink:visited { COLOR: #0000ff}A.BoxTitleLink { COLOR: #000; TEXT-DECORATION: underline}A.BoxTitleLink:hover { COLOR: #465584; TEXT-DECORATION: underline}A.BoxTitleLink:visited { COLOR: #000; TEXT-DECORATION: underline}A.normal { COLOR: blue}A.normal:hover { BACKGROUND-COLOR: transparent}A.normal:visited { COLOR: #000020}A { COLOR: #0000dd}A:hover { COLOR: #cc0000}A:visited { COLOR: #000020}A.onlineMemberLinkHelper { COLOR: #ff0000}A.onlineMemberLinkHelper:hover { COLOR: #ffaaaa}A.onlineMemberLinkHelper:visited { COLOR: #cc0000}.BoxTitleColor { COLOR: #000000} picture name Description Keywords All Anime/Manga (0)Books (258)Cartoons (428)Comics (555)Fantasy (474)Furries (0)Games (64)Misc (176)Movies (435)Original (0)Paintings (197)Real People (752)Tutorials (0)TV (169) Add Story Title: Description: Keywords: Category: Anime/Manga +.hack // Legend of Twilight's Bracelet +Aura +Balmung +Crossovers +Hotaru +Komiyan III +Mireille +Original .hack Characters +Reina +Reki +Shugo +.hack // Sign +Mimiru -
DIRECTV® Universal Remote Control User's Guide
DirecTV-M2081A.qxd 12/22/2004 3:44 PM Page 1 ® DIRECTV® Universal Remote Control User’s Guide DirecTV-M2081A.qxd 12/22/2004 3:44 PM Page 2 TABLE OF CONTENTS Introduction . .3 Features and Functions . .4 Key Charts . .4 Installing Batteries . .8 Controlling DIRECTV® Receiver. .9 Programming DIRECTV Remote . .9 Setup Codes for DIRECTV Receivers . .10 Setup Codes for DIRECTV HD Receivers . .10 Setup Codes for DIRECTV DVRs . .10 Programming to Control Your TV. .11 Programming the TV Input Key . .11 Deactivate the TV Input Select Key . .11 Programming Other Component Controls . .12 Manufacturer Codes . .13 Setup Codes for TVs . .13 Setup Codes for VCRs . .16 Setup Codes for DVD Players . .19 Setup Codes for Stereo Receivers . .20 Setup Codes for Stereo Amplifiers . .22 Searching For Your Code in AV1 or AV2 Mode . .23 Verifying The Codes . .23 Changing Volume Lock . .24 Restore Factory Default Settings . .25 Troubleshooting . .26 Repair or Replacement Policy . .27 Additional Information . .28 2 DirecTV-M2081A.qxd 12/22/2004 3:44 PM Page 3 INTRODUCTION Congratulations! You now have an exclusive DIRECTV® Universal Remote Control that will control four components, including a DIRECTV Receiver, TV, and two stereo or video components (e.g 2nd TV, DVD, or stereo). Moreover, its sophisticated technology allows you to consolidate the clutter of your original remote controls into one easy-to-use unit that's packed with features such as: z Four-position slide switch for easy component selection z Code library for popular video and stereo components z Code search to help program control of older or discon- tinued components z Memory protection to ensure you will not have to re- program the remote when the batteries are replaced Before using your DIRECTV Universal Remote Control, you may need to program it to operate with your particular com- ponent. -

Titles Ordered December 13-20, 2019
Titles ordered December 13-20, 2019 Book Adult Fiction Release Date: Islington, James, 1981- author. The light of all that falls / James Islington. http://catalog.waukeganpl.org/record=b1610199 12/10/2019 Lupica, Mike, author. Robert B. Parker's Grudge match / Mike Lupica. http://catalog.waukeganpl.org/record=b1610200 5/5/2020 Adult Non-Fiction Release Date: Andrés, José, 1969- author. Vegetables unleashed : a cookbook / José http://catalog.waukeganpl.org/record=b1610197 5/21/2019 Andrés and Matt Goulding ; photography by Peter Frank Edwards. Buettner, Dan, author. The Blue Zones kitchen : 100 recipes to live to 100 / http://catalog.waukeganpl.org/record=b1610241 12/3/2019 Dan Buettner ; with photographs by David McLain. Fleming, Paula L. (EDT) ASVAB prep 2020-2021. 4 Practice Tests + Proven http://catalog.waukeganpl.org/record=b1610679 12/3/2019 Strategies + Online Haynes Manuals (COR) Jeep Liberty & Dodge Nitro from 2002 thru 2012 http://catalog.waukeganpl.org/record=b1610677 2/28/2020 Haynes Repair Manual : All Gasoline Models Haynes Manuals (COR)/ Killingsworth, Jeff/ Haynes Toyota Tundra 2007 Thru 2019 and Sequoia http://catalog.waukeganpl.org/record=b1610676 6/4/2019 Haynes, John H. 2008 Thru 2019 : All 2WD and 4WD Models J. K. Lasser Institute (COR) J.K. Lasser's your income tax 2020 / For Preparing http://catalog.waukeganpl.org/record=b1610678 12/24/2019 Your 2019 Tax Return prepared by the J.K. Lasser Institute. Children's Graphic Novels Release Date: Akai, Higasa, author, artist. The royal tutor. 12 / Higasa Akai ; translation: http://catalog.waukeganpl.org/record=b1610330 8/27/2019 Amanda Haley. -

{DOWNLOAD} Hailey the Hedgehog Ebook, Epub
HAILEY THE HEDGEHOG PDF, EPUB, EBOOK Lily Small | 144 pages | 29 Aug 2013 | Egmont UK Ltd | 9781405266604 | English | London, United Kingdom Hailey the Hedgehog PDF Book Home Services. June 23, Genomic analysis of smoothened inhibitor resistance in basal cell carcinoma. Jozh W. The Tea Tree Rosemary face soap works especially well. The cable network has also inked talent deals with three up-and-comers, who were discovered from a talent showcase at Los Angeles' Groundlings Theatre: Noah Urrea, Jace Norman and Haley Tju. Strawberry Hedgehog is amazing. In this enchanted realm, every creature has glittery fairy wings and a special job to do to make their home beautiful. I was very pleased with my order and customer service. She also appeared in the television movie Den Brother. Not available in stores. Average rating 4. We even planned a week ago , commenting on their instagram about how we'd be in soon for our Mother's Day gifts I brought my niece and her friend , we had been planning a week in advance- we drove from Scottsdale to phx in Friday rush hour to get there. Paperback , pages. Great gift for your guy. It's rare that I find a chapter book series I can recommend to readers, but this charming little story - like the Rainbow Fairies, but lacking the dull repetitiveness - is charming, and the sprinkle of British words hedgerow, dock leaf gives it a Beatrix Potter feel while adding new vocabulary and not feeling condescending. Lily Small. Collections Including Strawberry Hedgehog. From the organic essential oils to recycled packaging, everything selected is done so with care and consciousness. -

MAD SCIENCE! Ab Science Inc
MAD SCIENCE! aB Science Inc. PROGRAM GUIDEBOOK “Leaders in Industry” WARNING! MAY CONTAIN: Vv Highly Evil Violations of Volatile Sentient :D Space-Time Materials Robots Laws FOOT table of contents 3 Letters from the Co-Chairs 4 Guests of Honor 10 Events 15 Video Programming 18 Panels & Workshops 28 Artists’ Alley 32 Dealers Room 34 Room Directory 35 Maps 41 Where to Eat 48 Tipping Guide 49 Getting Around 50 Rules 55 Volunteering 58 Staff 61 Sponsors 62 Fun & Games 64 Autographs APRIL 2-4, 2O1O 1 IN MEMORY OF TODD MACDONALD “We will miss and love you always, Todd. Thank you so much for being a friend, a staffer, and for the support you’ve always offered, selflessly and without hesitation.” —Andrea Finnin LETTERS FROM THE CO-CHAIRS Anime Boston has given me unique growth Hello everyone, welcome to Anime Boston! opportunities, and I have become closer to people I already knew outside of the convention. I hope you all had a good year, though I know most of us had a pretty bad year, what with the economy, increasing healthcare This strengthening of bonds brought me back each year, but 2010 costs and natural disasters (donate to Haiti!). At Anime Boston, is different. In the summer of 2009, Anime Boston lost a dear I hope we can provide you with at least a little enjoyment. friend and veteran staffer when Todd MacDonald passed away. We’ve been working long and hard to get composer Nobuo When Todd joined staff in 2002, it was only because I begged. Uematsu, most famous for scoring most of the music for the Few on staff imagined that our three-day convention was going Final Fantasy games as well as other Square Enix games such to be such an amazing success. -

Gals at Archie Comics and the Best
FROM YOUR PALS ‘N’ GALS AT ARCHIE COMICS AND THE BEST COMIC STORE IN THE WORLD: Welcome to the exclusive prequel comic to Sega’s hottest new videogame, Sonic Lost World™, where Sonic is about to embark on an all new journey! A NEW ADVENTURE AWAITS! Sonic the Hedgehog and his pals are the only force able to stand up to the evil scientist, Dr. Eggman! The mad doctor is at it again swiping up critters to power his ever growing badnik army, and this time, he’s bringing his aramda to take over a new land, the mysterious hidden world of Lost Hex! Always ready for the next adventure, Sonic leaps into action, and is currently hot on the heels of Dr. Eggman... SONIC LOST WORLD™, HALLOWEEN COMIC FEST EDITION, No 1, October, 2013. Published by Archie Comic Publications, Inc., 325 Fayette Avenue, Mamaroneck, NY 10543-2318. Jonathan Goldwater, Publisher/Co-CEO, Nancy Silberkleit, Co-CEO, Mike Pellerito, President. Victor Gorelick, Co-President. SEGA, Sonic The Hedgehog, and all related characters and indicia are either registered trademarks or trademarks of SEGA CORPORATION © 1991-2013. SEGA CORPORATION and SONICTEAM, LTD./SEGA CORPORATION © 1991-2013. All Rights Reserved. The product is manufactured under license from Sega of America, Inc., 350 Rhode Island Street, Ste 400, San Francisco, CA 94103 www.sega.com. Any similarities between characters, names, persons, and/or institutions in this book and any living, dead, or fictional characters, names, persons, and/or institutions are not intended and if they exist, are purely coincidental. Printed in USA. 2 3 4 5 8.