Computational Intelligence and Games
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Air France, Latécoère and Ubisoft Unveil the “Lifi Power” Exhibition at the International Paris Air Show
AIR FRANCE, LATÉCOÈRE AND UBISOFT UNVEIL THE “LIFI POWER” EXHIBITION AT THE INTERNATIONAL PARIS AIR SHOW Paris, 4 June 2019 – At the International Paris Air Show in Le Bourget (Salon du Bourget), Air France, Latécoère and Ubisoft will be trialing their new LiFi (Light Fidelity) technology using light to transmit data and will run an in-flight video game tournament showcasing this technology. LiFi, the next standard for in-flight data transmission, to be showcased at Le Bourget During the International Paris Air Show, Latécoère’s stand (Hall 2a – B254) will feature a full-scale, medium- range Air France cabin mock-up featuring LiFi technology. Visitors at the show will be able to put the speed and reliability of this innovative new technology through its paces in a live demo. Latécoère, a tier 1 partner to major international aircraft manufacturers, has designed a LiFi infrastructure solution enabling entertainment and communication system providers to deliver the best possible in-flight connectivity. This technology offers multiple benefits: • Very high-speed multimedia data throughput (a speed currently 100 times faster than existing WiFi systems); • Less on-board cabling (eliminating copper cables and replacing them with optical systems), leading to overall weight savings for the aircraft and making it more fuel-efficient. It is thanks to the pioneering mindset of Air France Industries KLM Engineering & Maintenance, a major international player in aircraft maintenance, that it is possible to deploy this solution within an Air France Cabin for the first time. LiFi was spotted at an early stage by its cabin modification experts, who then began to think about how to implement this innovative technology on board an aircraft. -

How to Buy DVD PC Games : 6 Ribu/DVD Nama
www.GamePCmurah.tk How To Buy DVD PC Games : 6 ribu/DVD Nama. DVD Genre Type Daftar Game Baru di urutkan berdasarkan tanggal masuk daftar ke list ini Assassins Creed : Brotherhood 2 Action Setup Battle Los Angeles 1 FPS Setup Call of Cthulhu: Dark Corners of the Earth 1 Adventure Setup Call Of Duty American Rush 2 1 FPS Setup Call Of Duty Special Edition 1 FPS Setup Car and Bike Racing Compilation 1 Racing Simulation Setup Cars Mater-National Championship 1 Racing Simulation Setup Cars Toon: Mater's Tall Tales 1 Racing Simulation Setup Cars: Radiator Springs Adventure 1 Racing Simulation Setup Casebook Episode 1: Kidnapped 1 Adventure Setup Casebook Episode 3: Snake in the Grass 1 Adventure Setup Crysis: Maximum Edition 5 FPS Setup Dragon Age II: Signature Edition 2 RPG Setup Edna & Harvey: The Breakout 1 Adventure Setup Football Manager 2011 versi 11.3.0 1 Soccer Strategy Setup Heroes of Might and Magic IV with Complete Expansion 1 RPG Setup Hotel Giant 1 Simulation Setup Metal Slug Anthology 1 Adventure Setup Microsoft Flight Simulator 2004: A Century of Flight 1 Flight Simulation Setup Night at the Museum: Battle of the Smithsonian 1 Action Setup Naruto Ultimate Battles Collection 1 Compilation Setup Pac-Man World 3 1 Adventure Setup Patrician IV Rise of a Dynasty (Ekspansion) 1 Real Time Strategy Setup Ragnarok Offline: Canopus 1 RPG Setup Serious Sam HD The Second Encounter Fusion (Ekspansion) 1 FPS Setup Sexy Beach 3 1 Eroge Setup Sid Meier's Railroads! 1 Simulation Setup SiN Episode 1: Emergence 1 FPS Setup Slingo Quest 1 Puzzle -

En Première Mondiale, Air France Expérimente La Technologie Du Lifi En Vol, En Partenariat Avec Latécoère Et Ubisoft
Roissy, le 31 octobre 2019 En première mondiale, Air France expérimente la technologie du LiFi en vol, en partenariat avec Latécoère et Ubisoft Air France a testé, ce mercredi 30 octobre 2019, le tout premier vol équipé du LiFi (Light Fidelity), développé par Latécoère à bord du vol commercial AF6114 effectué en Airbus A321 au départ de Paris-Orly et à destination de Toulouse. Engagée dans une recherche de nouveaux cas d'usage en vol pour ses clients, Air France a également accueilli des gamers, finalistes du « Air France Trackmania Cup » développé par Ubisoft qui se sont affrontés en plein vol. Le LiFi, le prochain standard de transmission des données en vol Air France et Latécoère expérimentent aujourd'hui la simplicité d'intégration et de certification de cette technologie pour des vols commerciaux. L'infrastructure LiFi Latécoère installée sur 12 sièges de l'Airbus A321 d'Air France présente de nombreux avantages. Elle permet : un échange de données multimédias parfaitement stable à très haut débit et très faible latence ; une réduction du poids de l'avion et donc de sa consommation carburant, grâce à l'élimination de câbles en cuivre au profit de la fibre optique. Une finale en plein vol Avec la collaboration de leur partenaire Ubisoft, la compagnie nationale et l'équipementier toulousain a organisé la finale du tournoi « Air France Trackmania Cup », lancé lors du salon du Bourget en juin 2019(1). Les gamers finalistes se sont affrontés sur cette version personnalisée du jeu vidéo toutpublic Trackmania² Stadium. Le vainqueur du tournoi a reçu deux billets aller/retour Paris-Montréal pour une visite privée des studios Ubisoft ainsi qu' une sélection de produits Razer (qui a équipé la compétition de ses casques Bluetooth Hammerhead). -

09062299296 Omnislashv5
09062299296 omnislashv5 1,800php all in DVDs 1,000php HD to HD 500php 100 titles PSP GAMES Title Region Size (MB) 1 Ace Combat X: Skies of Deception USA 1121 2 Aces of War EUR 488 3 Activision Hits Remixed USA 278 4 Aedis Eclipse Generation of Chaos USA 622 5 After Burner Black Falcon USA 427 6 Alien Syndrome USA 453 7 Ape Academy 2 EUR 1032 8 Ape Escape Academy USA 389 9 Ape Escape on the Loose USA 749 10 Armored Core: Formula Front – Extreme Battle USA 815 11 Arthur and the Minimoys EUR 1796 12 Asphalt Urban GT2 EUR 884 13 Asterix And Obelix XXL 2 EUR 1112 14 Astonishia Story USA 116 15 ATV Offroad Fury USA 882 16 ATV Offroad Fury Pro USA 550 17 Avatar The Last Airbender USA 135 18 Battlezone USA 906 19 B-Boy EUR 1776 20 Bigs, The USA 499 21 Blade Dancer Lineage of Light USA 389 22 Bleach: Heat the Soul JAP 301 23 Bleach: Heat the Soul 2 JAP 651 24 Bleach: Heat the Soul 3 JAP 799 25 Bleach: Heat the Soul 4 JAP 825 26 Bliss Island USA 193 27 Blitz Overtime USA 1379 28 Bomberman USA 110 29 Bomberman: Panic Bomber JAP 61 30 Bounty Hounds USA 1147 31 Brave Story: New Traveler USA 193 32 Breath of Fire III EUR 403 33 Brooktown High USA 1292 34 Brothers in Arms D-Day USA 1455 35 Brunswick Bowling USA 120 36 Bubble Bobble Evolution USA 625 37 Burnout Dominator USA 691 38 Burnout Legends USA 489 39 Bust a Move DeLuxe USA 70 40 Cabela's African Safari USA 905 41 Cabela's Dangerous Hunts USA 426 42 Call of Duty Roads to Victory USA 641 43 Capcom Classics Collection Remixed USA 572 44 Capcom Classics Collection Reloaded USA 633 45 Capcom Puzzle -

Airfrance Trackmania
AIRFRANCE TRACKMANIA CUP Règlement général Sommaire I. Informations générales ........................................................................................................................ 3 Section I - 1. Règlement général ............................................................................................................. 3 Section I - 2. Application du règlement ................................................................................................... 3 Section I - 3. Inscription ........................................................................................................................... 3 Section I - 4. MapPack ............................................................................................................................. 3 Section I - 5. Contact ............................................................................................................................... 3 II. Règles Trackmania² ............................................................................................................................. 4 Section II - 1. Version de jeu .................................................................................................................... 4 Section II - 2. Configuration joueur ......................................................................................................... 4 Section II - 3. Configuration serveur ........................................................................................................ 4 III. Format de match ............................................................................................................................... -

Buy Painkiller Black Edition (PC) Reviews,Painkiller Black Edition (PC) Best Buy Amazon
Buy Painkiller Black Edition (PC) Reviews,Painkiller Black Edition (PC) Best Buy Amazon #1 Find the Cheapest on Painkiller Black Edition (PC) at Cheap Painkiller Black Edition (PC) US Store . Best Seller discount Model Painkiller Black Edition (PC) are rated by Consumers. This US Store show discount price already from a huge selection including Reviews. Purchase any Cheap Painkiller Black Edition (PC) items transferred directly secure and trusted checkout on Amazon Painkiller Black Edition (PC) Price List Price:See price in Amazon Today's Price: See price in Amazon In Stock. Best sale price expires Today's Weird and wonderful FPS. I've just finished the massive demo of this game and i'm very impressed with everything about it,so much so that i've ordered it through Amazon.The gameplay is smooth and every detail is taken care of.No need for annoying torches that run on batteries,tanks,aeroplanes, monsters and the environment are all lit and look perfect.Weird weapons fire stakes.Revolving blades makes minceme...Read full review --By Gary Brown Painkiller Black Edition (PC) Description 1 x DVD-ROM12 Page Manual ... See all Product Description Painkiller Black Ed reviewed If you like fps games you will love this one, great story driven action, superb graphics and a pounding soundtrack. The guns are wierd and wacky but very effective. The black edition has the main game plus the first expansion gamePainkiller Black Edition (PC). Very highly recommended. --By Greysword Painkiller Black Edition (PC) Details Amazon Bestsellers Rank: 17,932 in PC & Video Games (See Top 100 in PC & Video Games) Average Customer Review: 4.2 out of 5 stars Delivery Destinations: Visit the Delivery Destinations Help page to see where this item can be file:///D|/...r%20Black%20Edition%20(PC)%20Reviews,Painkiller%20Black%20Edition%20(PC)%20Best%20Buy%20Amazon.html[2012-2-5 22:40:11] Buy Painkiller Black Edition (PC) Reviews,Painkiller Black Edition (PC) Best Buy Amazon delivered. -

Fueled ONLINE COURSES Course Catalog | 2014–2015 Fueled Online Courses Table of Contents / 2014–2015
FuelEd ONLINE COURSES Course Catalog | 2014–2015 FuelEd Online Courses Table of Contents / 2014–2015 Middle School Overview ............................................................... 3 Language Arts ........................................................................................... 4 Math .......................................................................................................... 5 Science ...................................................................................................... 6 Social Studies ............................................................................................ 7 Electives .................................................................................................... 8 World Languages .......................................................................................12 Extended Electives ....................................................................................19 High School Overview .................................................................. 20 Advanced Placement ................................................................................ 22 Language Arts .......................................................................................... 27 Math ......................................................................................................... 29 Science ..................................................................................................... 33 Social Studies .......................................................................................... -

Trackmania Unlimiter User Manual Table of Contents
Trackmania Unlimiter user manual Created by Kemot0055 and Remix Current unlimiter version: 1.0 beta 3 Manual version: 1.1 eng Translation by Remix, Suchor and Kemot0055 Link for main topic on tmx: https://united.tm- exchange.com/main.aspx?action=threadshow&id=4724293&postid=4724294 Table of contents 1. How to install TM Unlimiter? – p.1 2. TMUnlimiter.ini file description – p.3 3. Track editor - Keyboard shortcuts – p.4 4. MediaTracker – p.6 4.1 MediaTracker – Keyboard shortcuts – p.8 4.2 MediaTracker - Changing physics parameters – p.9 4.3 MediaTracker - Communication between clips – p.11 4.4 MediaTracker - Advanced example – p.11 4.5 MediaTracker - Default car parameters – p.16 5. Custom blocks – p.17 5.1 How to install custom blocks? – p.17 5.2 How to create custom blocks? – p.18 6. Known issues – p.18 7. Full changelog – p.19 1. How to install TM Unlimiter? Installation of TM Unlimiter is very simple. All you have to do is copy all files from *.zip file to your game folder, “TmUnitedForever” or “TmNationsForever” (depended from version) and everything should work correct. Files that you need to run TM Unlimiter: - TMUnlimiter.exe - Launching program to start game with Unlimiter - TMUnlimiter.ini - Configuration file - TMUnlimiterProbe.dll - File that modify game code - Folder Icons which include new terrain icons in editor This package has also TMUnlimiterOld.exe file, which is taken from previous TM Unlimiter versions and added in case of some problems with new TMUnlimiter.exe file even if doesn't work with tips written below, and works on previous versions. -

EVENT STAFF FUZE Trackmania Nation Forever / Trackmania United Forever
EVENT STAFF FUZE TrackMania Nation Forever / TrackMania United Forever Guide de démarrage By Wistaro Table des matières I / Installation du jeu.............................................................................................................................3 1.1 - Introduction.............................................................................................................................3 1.2 – Installation via Steam..............................................................................................................3 1.3 – Installation sans Steam............................................................................................................3 1.4 – Les touches pour jouer............................................................................................................3 II / Rejoindre le serveur........................................................................................................................4 2.1 – Étape 1....................................................................................................................................4 2.2 – Étape 2....................................................................................................................................5 2.3 – Étape 3...................................................................................................................................5 2.4 – Étape 4....................................................................................................................................6 -

Trackmania Is NP-Complete
TrackMania is NP-complete Franck Dernoncourt CSAIL, MIT [email protected] Abstract. We prove that completing an untimed, unbounded track in TrackMania Nations Forever is NP-complete by using a reduction from 3-SAT and showing that a solution can be checked in polynomial time. 1 Introduction TrackMania Nations Forever (TMNF, or TMF) is a 3D racing game that was released in 2008 by video game developer Nadeo. It is part of the racing game series TrackMania. It was designed for the Electronic Sports World Cup, which is a yearly international professional gaming championship that have distributed millions of dollars in prizes since its creation in 2003. Over 13 million online players signed up for TMNF, as the game is free of charge and its reception in video game mag- azines was largely positive. Guinness World Records [1] awarded TrackMania six world records in 2008: “biggest online race”, “most popular online racing simulation”, “most nationalities in an offline racing competition”, “largest content base of any racing game”, “first publicly available game developed specifically for an online competition” and “most popular user-created video”. In TMNF, the player’s goal is to complete a track as quickly as possible. To complete a track, the player must first go through all checkpoints, which he can do in any order, then reach the finish gate. Figure1 shows an example of a track. arXiv:1411.5765v1 [cs.CC] 21 Nov 2014 Figure 1: A track in TrackMania Nations Forever (TMNF) This paper is, to the best of our knowledge, the first consideration of the complexity of playing TrackMania or any other real-time racing game (see [2] for a complexity proof for a non-real-time racing game). -

Airfrance Trackmania
AIRFRANCE TRACKMANIA CUP Rules Summary I. General Information ............................................................................................................................. 3 Section I - 1. General rules ...................................................................................................................... 3 Section I - 2. Application of the rules ...................................................................................................... 3 Section I - 3. Registration ........................................................................................................................ 3 Section I - 4. Mappack ............................................................................................................................. 3 Section I - 5. Contact ............................................................................................................................... 3 II. Trackmania² Rules ............................................................................................................................... 4 Section II - 1. Game version ..................................................................................................................... 4 Section II - 2. Players configuration ......................................................................................................... 4 Section II - 3. Server settings ................................................................................................................... 4 III. Match format .................................................................................................................................... -
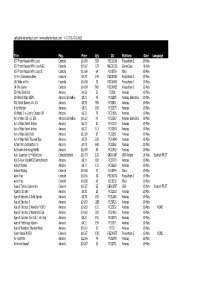
[email protected] +1 (718) 701 2662 Title Pkg. Price Qty ID Platform Date Language 007 from Russ
[email protected] www.entertainbest.com +1 (718) 701 2662 Title Pkg. Price Qty ID Platform Date Language 007 From Russia With Love Console $14.68 358 PS201240 Playstation 2 10-May 007 From Russia With Love NGC Console $15.67 129 NGC20136 GameCube 10-May 007 From Russia With Love SE Console $12.69 64 XB10259 XBox 10-May 10 Pin Champions Alley Console $9.70 149 PS200383 Playstation 2 10-May 187 Ride or Die Console $14.68 30 PS200453 Playstation 2 10-May 24 The Game Console $14.68 860 PS200805 Playstation 2 10-May 3D Pets Sold Out Amaray $4.23 21 50018 Amaray 10-May 3D World Atlas SIEPC Amaray SierraBox $8.71 45 PC32285 Amaray SierraBox 10-May 501 Great Games Vol. 18 Amaray $5.72 350 PC32831 Amaray 10-May 8:th Wonder Amaray $8.71 189 PC32575 Amaray 10-May AA Make It + Comic Creator DP Amaray $6.22 79 PC31906 Amaray 10-May Act of War Coll. Ed. SIE Amaray SierraBox $16.67 42 PC32587 Amaray SierraBox 10-May Act of War Direct Action Amaray $6.72 87 PC31172 Amaray 10-May Act of War Direct Action Amaray $6.72 513 PC32560 Amaray 10-May Act of War Gold Pack Amaray $12.69 67 PC32561 Amaray 10-May Act of War High Treason Exp. Amaray $9.70 230 PC31484 Amaray 10-May Action Man Destruction X Amaray $4.73 649 PC32562 Amaray 10-May Activision Anthology ReMix Amaray $12.69 64 PC31932 Amaray 10-May Adv. Guardian H. Mint/sticker Console Refurb $10.70 132 GBA10667 GBA Refurb 10-May Spanish FR IT Adv.3-Pack BlackM/J2Centre/Watch Amaray $8.71 650 PC32729 Amaray 10-May Advent Rising Amaray $8.71 131 PC30680 Amaray 10-May Advent Rising Console $14.68 37 XB10294 XBox 10-May Aeon Flux Console $18.66 28 PS200878 Playstation 2 10-May Aeon Flux Console $14.68 40 XB10532 XBox 10-May Agassi Tennis Generation Console $16.67 22 GBA10597 GBA 10-May Spanish FR IT Agatha Christie Amaray $9.70 25 PC32133 Amaray 10-May Age of Empires 1 Gold Xplosiv Amaray $6.72 183 PC31286 Amaray 10-May Age of Empires 3 Amaray $24.63 1188 PC30826 Amaray 10-May Age of Empires 3 Warchief NORD Amaray $24.63 125 PC32532 Amaray 10-May NORD Age of Empires 3 Warchiefs Exp.