Fast and Robust Vectorized In-Place Sorting of Primitive Types
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Overview of Sorting Algorithms
Unit 7 Sorting Algorithms Simple Sorting algorithms Quicksort Improving Quicksort Overview of Sorting Algorithms Given a collection of items we want to arrange them in an increasing or decreasing order. You probably have seen a number of sorting algorithms including ¾ selection sort ¾ insertion sort ¾ bubble sort ¾ quicksort ¾ tree sort using BST's In terms of efficiency: ¾ average complexity of the first three is O(n2) ¾ average complexity of quicksort and tree sort is O(n lg n) ¾ but its worst case is still O(n2) which is not acceptable In this section, we ¾ review insertion, selection and bubble sort ¾ discuss quicksort and its average/worst case analysis ¾ show how to eliminate tail recursion ¾ present another sorting algorithm called heapsort Unit 7- Sorting Algorithms 2 Selection Sort Assume that data ¾ are integers ¾ are stored in an array, from 0 to size-1 ¾ sorting is in ascending order Algorithm for i=0 to size-1 do x = location with smallest value in locations i to size-1 swap data[i] and data[x] end Complexity If array has n items, i-th step will perform n-i operations First step performs n operations second step does n-1 operations ... last step performs 1 operatio. Total cost : n + (n-1) +(n-2) + ... + 2 + 1 = n*(n+1)/2 . Algorithm is O(n2). Unit 7- Sorting Algorithms 3 Insertion Sort Algorithm for i = 0 to size-1 do temp = data[i] x = first location from 0 to i with a value greater or equal to temp shift all values from x to i-1 one location forwards data[x] = temp end Complexity Interesting operations: comparison and shift i-th step performs i comparison and shift operations Total cost : 1 + 2 + .. -

Batcher's Algorithm
18.310 lecture notes Fall 2010 Batcher’s Algorithm Prof. Michel Goemans Perhaps the most restrictive version of the sorting problem requires not only no motion of the keys beyond compare-and-switches, but also that the plan of comparison-and-switches be fixed in advance. In each of the methods mentioned so far, the comparison to be made at any time often depends upon the result of previous comparisons. For example, in HeapSort, it appears at first glance that we are making only compare-and-switches between pairs of keys, but the comparisons we perform are not fixed in advance. Indeed when fixing a headless heap, we move either to the left child or to the right child depending on which child had the largest element; this is not fixed in advance. A sorting network is a fixed collection of comparison-switches, so that all comparisons and switches are between keys at locations that have been specified from the beginning. These comparisons are not dependent on what has happened before. The corresponding sorting algorithm is said to be non-adaptive. We will describe a simple recursive non-adaptive sorting procedure, named Batcher’s Algorithm after its discoverer. It is simple and elegant but has the disadvantage that it requires on the order of n(log n)2 comparisons. which is larger by a factor of the order of log n than the theoretical lower bound for comparison sorting. For a long time (ten years is a long time in this subject!) nobody knew if one could find a sorting network better than this one. -

Kapitel 1 Einleitung
Kapitel 1 Einleitung 1.1 Parallele Rechenmodelle Ein Parallelrechner besteht aus einer Menge P = {P0,...,Pn−1} von Prozessoren und einem Kommunikationsmechanismus. Wir unterscheiden drei Typen von Kommunikationsmechanismen: a) Kommunikation ¨uber einen gemeinsamen Speicher Jeder Prozessor hat Lese- und Schreibzugriff auf die Speicherzellen eines großen ge- meinsamen Speichers (shared memory). Einen solchen Rechner nennen wir sha- red memory machine, Parallele Registermaschine oder Parallel Random Ac- cess Machine (PRAM). Dieses Modell zeichnet sich dadurch aus, daß es sehr kom- fortabel programmiert werden kann, da man sich auf das Wesentliche“ beschr¨anken ” kann, wenn man Algorithmen entwirft. Auf der anderen Seite ist es jedoch nicht (auf direktem Wege) realisierbar, ohne einen erheblichen Effizienzverlust dabei in Kauf neh- men zu mussen.¨ b) Kommunikation ¨uber Links Hier sind die Prozessoren gem¨aß einem ungerichteten Kommunikationsgraphen G = (P, E) untereinander zu einem Prozessornetzwerk (kurz: Netzwerk) verbunden. Die Kommunikation wird dabei folgendermaßen durchgefuhrt:¨ Jeder Prozessor Pi hat ein Lesefenster, auf das er Schreibzugriff hat. Falls {Pi,Pj} ∈ E ist, darf Pj im Lese- fenster von Pi lesen. Pi hat zudem ein Schreibfenster, auf das er Lesezugriff hat. Falls {Pi,Pj} ∈ E ist, darf Pj in das Schreibfenster von Pi schreiben. Zugriffskonflikte (gleichzeitiges Lesen und Schreiben im gleichen Fenster) k¨onnen auf verschiedene Arten gel¨ost werden. Wie dies geregelt wird, werden wir, wenn n¨otig, jeweils spezifizieren. Ebenso werden wir manchmal von der oben beschriebenen Kommunikation abweichen, wenn dadurch die Rechnungen vereinfacht werden k¨onnen. Auch darauf werden wir jeweils hinweisen. Die Zahl aller m¨oglichen Leitungen, die es in einem Netzwerk mit n Prozessoren geben n 10 kann, ist 2 . -

Hacking a Google Interview – Handout 2
Hacking a Google Interview – Handout 2 Course Description Instructors: Bill Jacobs and Curtis Fonger Time: January 12 – 15, 5:00 – 6:30 PM in 32‐124 Website: http://courses.csail.mit.edu/iap/interview Classic Question #4: Reversing the words in a string Write a function to reverse the order of words in a string in place. Answer: Reverse the string by swapping the first character with the last character, the second character with the second‐to‐last character, and so on. Then, go through the string looking for spaces, so that you find where each of the words is. Reverse each of the words you encounter by again swapping the first character with the last character, the second character with the second‐to‐last character, and so on. Sorting Often, as part of a solution to a question, you will need to sort a collection of elements. The most important thing to remember about sorting is that it takes O(n log n) time. (That is, the fastest sorting algorithm for arbitrary data takes O(n log n) time.) Merge Sort: Merge sort is a recursive way to sort an array. First, you divide the array in half and recursively sort each half of the array. Then, you combine the two halves into a sorted array. So a merge sort function would look something like this: int[] mergeSort(int[] array) { if (array.length <= 1) return array; int middle = array.length / 2; int firstHalf = mergeSort(array[0..middle - 1]); int secondHalf = mergeSort( array[middle..array.length - 1]); return merge(firstHalf, secondHalf); } The algorithm relies on the fact that one can quickly combine two sorted arrays into a single sorted array. -

Parallel Sorting Algorithms + Topic Overview
+ Design of Parallel Algorithms Parallel Sorting Algorithms + Topic Overview n Issues in Sorting on Parallel Computers n Sorting Networks n Bubble Sort and its Variants n Quicksort n Bucket and Sample Sort n Other Sorting Algorithms + Sorting: Overview n One of the most commonly used and well-studied kernels. n Sorting can be comparison-based or noncomparison-based. n The fundamental operation of comparison-based sorting is compare-exchange. n The lower bound on any comparison-based sort of n numbers is Θ(nlog n) . n We focus here on comparison-based sorting algorithms. + Sorting: Basics What is a parallel sorted sequence? Where are the input and output lists stored? n We assume that the input and output lists are distributed. n The sorted list is partitioned with the property that each partitioned list is sorted and each element in processor Pi's list is less than that in Pj's list if i < j. + Sorting: Parallel Compare Exchange Operation A parallel compare-exchange operation. Processes Pi and Pj send their elements to each other. Process Pi keeps min{ai,aj}, and Pj keeps max{ai, aj}. + Sorting: Basics What is the parallel counterpart to a sequential comparator? n If each processor has one element, the compare exchange operation stores the smaller element at the processor with smaller id. This can be done in ts + tw time. n If we have more than one element per processor, we call this operation a compare split. Assume each of two processors have n/p elements. n After the compare-split operation, the smaller n/p elements are at processor Pi and the larger n/p elements at Pj, where i < j. -
Sorting Networks
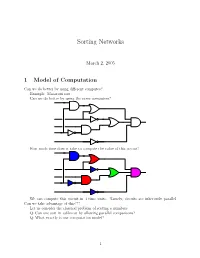
Sorting Networks March 2, 2005 1 Model of Computation Can we do better by using different computes? Example: Macaroni sort. Can we do better by using the same computers? How much time does it take to compute the value of this circuit? We can compute this circuit in 4 time units. Namely, circuits are inherently parallel. Can we take advantage of this??? Let us consider the classical problem of sorting n numbers. Q: Can one sort in sublinear by allowing parallel comparisons? Q: What exactly is our computation model? 1 1.1 Computing with a circuit We are going to design a circuit, where the inputs are the numbers, and we compare two numbers using a comparator gate: ¢¤¦© ¡ ¡ Comparator ¡£¢¥¤§¦©¨ ¡ For our drawings, we will draw such a gate as follows: ¢¡¤£¦¥¨§ © ¡£¦ So, circuits would just be horizontal lines, with vertical segments (i.e., gates) between them. A complete sorting network, looks like: The inputs come on the wires on the left, and are output on the wires on the right. The largest number is output on the bottom line. The surprising thing, is that one can generate circuits from a sorting algorithm. In fact, consider the following circuit: Q: What does this circuit does? A: This is the inner loop of insertion sort. Repeating this inner loop, we get the following sorting network: 2 Alternative way of drawing it: Q: How much time does it take for this circuit to sort the n numbers? Running time = how many time clocks we have to wait till the result stabilizes. In this case: 5 1 2 3 4 6 7 8 9 In general, we get: Lemma 1.1 Insertion sort requires 2n − 1 time units to sort n numbers. -

Foundations of Differentially Oblivious Algorithms
Foundations of Differentially Oblivious Algorithms T-H. Hubert Chan Kai-Min Chung Bruce Maggs Elaine Shi August 5, 2020 Abstract It is well-known that a program's memory access pattern can leak information about its input. To thwart such leakage, most existing works adopt the technique of oblivious RAM (ORAM) simulation. Such an obliviousness notion has stimulated much debate. Although ORAM techniques have significantly improved over the past few years, the concrete overheads are arguably still undesirable for real-world systems | part of this overhead is in fact inherent due to a well-known logarithmic ORAM lower bound by Goldreich and Ostrovsky. To make matters worse, when the program's runtime or output length depend on secret inputs, it may be necessary to perform worst-case padding to achieve full obliviousness and thus incur possibly super-linear overheads. Inspired by the elegant notion of differential privacy, we initiate the study of a new notion of access pattern privacy, which we call \(, δ)-differential obliviousness". We separate the notion of (, δ)-differential obliviousness from classical obliviousness by considering several fundamental algorithmic abstractions including sorting small-length keys, merging two sorted lists, and range query data structures (akin to binary search trees). We show that by adopting differential obliv- iousness with reasonable choices of and δ, not only can one circumvent several impossibilities pertaining to full obliviousness, one can also, in several cases, obtain meaningful privacy with little overhead relative to the non-private baselines (i.e., having privacy \almost for free"). On the other hand, we show that for very demanding choices of and δ, the same lower bounds for oblivious algorithms would be preserved for (, δ)-differential obliviousness. -

Lecture 8.Key
CSC 391/691: GPU Programming Fall 2015 Parallel Sorting Algorithms Copyright © 2015 Samuel S. Cho Sorting Algorithms Review 2 • Bubble Sort: O(n ) 2 • Insertion Sort: O(n ) • Quick Sort: O(n log n) • Heap Sort: O(n log n) • Merge Sort: O(n log n) • The best we can expect from a sequential sorting algorithm using p processors (if distributed evenly among the n elements to be sorted) is O(n log n) / p ~ O(log n). Compare and Exchange Sorting Algorithms • Form the basis of several, if not most, classical sequential sorting algorithms. • Two numbers, say A and B, are compared between P0 and P1. P0 P1 A B MIN MAX Bubble Sort • Generic example of a “bad” sorting 0 1 2 3 4 5 algorithm. start: 1 3 8 0 6 5 0 1 2 3 4 5 Algorithm: • after pass 1: 1 3 0 6 5 8 • Compare neighboring elements. • Swap if neighbor is out of order. 0 1 2 3 4 5 • Two nested loops. after pass 2: 1 0 3 5 6 8 • Stop when a whole pass 0 1 2 3 4 5 completes without any swaps. after pass 3: 0 1 3 5 6 8 0 1 2 3 4 5 • Performance: 2 after pass 4: 0 1 3 5 6 8 Worst: O(n ) • 2 • Average: O(n ) fin. • Best: O(n) "The bubble sort seems to have nothing to recommend it, except a catchy name and the fact that it leads to some interesting theoretical problems." - Donald Knuth, The Art of Computer Programming Odd-Even Transposition Sort (also Brick Sort) • Simple sorting algorithm that was introduced in 1972 by Nico Habermann who originally developed it for parallel architectures (“Parallel Neighbor-Sort”). -

Sorting Algorithm 1 Sorting Algorithm
Sorting algorithm 1 Sorting algorithm In computer science, a sorting algorithm is an algorithm that puts elements of a list in a certain order. The most-used orders are numerical order and lexicographical order. Efficient sorting is important for optimizing the use of other algorithms (such as search and merge algorithms) that require sorted lists to work correctly; it is also often useful for canonicalizing data and for producing human-readable output. More formally, the output must satisfy two conditions: 1. The output is in nondecreasing order (each element is no smaller than the previous element according to the desired total order); 2. The output is a permutation, or reordering, of the input. Since the dawn of computing, the sorting problem has attracted a great deal of research, perhaps due to the complexity of solving it efficiently despite its simple, familiar statement. For example, bubble sort was analyzed as early as 1956.[1] Although many consider it a solved problem, useful new sorting algorithms are still being invented (for example, library sort was first published in 2004). Sorting algorithms are prevalent in introductory computer science classes, where the abundance of algorithms for the problem provides a gentle introduction to a variety of core algorithm concepts, such as big O notation, divide and conquer algorithms, data structures, randomized algorithms, best, worst and average case analysis, time-space tradeoffs, and lower bounds. Classification Sorting algorithms used in computer science are often classified by: • Computational complexity (worst, average and best behaviour) of element comparisons in terms of the size of the list . For typical sorting algorithms good behavior is and bad behavior is . -

Fragile Complexity of Comparison-Based Algorithms
Fragile Complexity of Comparison-Based Algorithms∗ Peyman Afshani Aarhus University, Denmark [email protected] Rolf Fagerberg University of Southern Denmark, Odense, Denmark [email protected] David Hammer Goethe University Frankfurt, Germany University of Southern Denmark, Odense, Denmark [email protected] Riko Jacob IT University of Copenhagen, Denmark [email protected] Irina Kostitsyna TU Eindhoven, The Netherlands [email protected] Ulrich Meyer Goethe University Frankfurt, Germany [email protected] Manuel Penschuck Goethe University Frankfurt, Germany [email protected] Nodari Sitchinava University of Hawaii at Manoa [email protected] Abstract We initiate a study of algorithms with a focus on the computational complexity of individual elements, and introduce the fragile complexity of comparison-based algorithms as the maximal number of comparisons any individual element takes part in. We give a number of upper and lower bounds on the fragile complexity for fundamental problems, including Minimum, Selection, Sorting and Heap Construction. The results include both deterministic and randomized upper and lower bounds, and demonstrate a separation between the two settings for a number of problems. The depth of a comparator network is a straight-forward upper bound on the worst case fragile complexity of the corresponding fragile algorithm. We prove that fragile complexity is a different and strictly easier property than the depth of comparator networks, in the sense that for some problems a fragile complexity equal -

Visvesvaraya Technological University a Project Report
` VISVESVARAYA TECHNOLOGICAL UNIVERSITY “Jnana Sangama”, Belagavi – 590 018 A PROJECT REPORT ON “PREDICTIVE SCHEDULING OF SORTING ALGORITHMS” Submitted in partial fulfillment for the award of the degree of BACHELOR OF ENGINEERING IN COMPUTER SCIENCE AND ENGINEERING BY RANJIT KUMAR SHA (1NH13CS092) SANDIP SHAH (1NH13CS101) SAURABH RAI (1NH13CS104) GAURAV KUMAR (1NH13CS718) Under the guidance of Ms. Sridevi (Senior Assistant Professor, Dept. of CSE, NHCE) DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING NEW HORIZON COLLEGE OF ENGINEERING (ISO-9001:2000 certified, Accredited by NAAC ‘A’, Permanently affiliated to VTU) Outer Ring Road, Panathur Post, Near Marathalli, Bangalore – 560103 ` NEW HORIZON COLLEGE OF ENGINEERING (ISO-9001:2000 certified, Accredited by NAAC ‘A’ Permanently affiliated to VTU) Outer Ring Road, Panathur Post, Near Marathalli, Bangalore-560 103 DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING CERTIFICATE Certified that the project work entitled “PREDICTIVE SCHEDULING OF SORTING ALGORITHMS” carried out by RANJIT KUMAR SHA (1NH13CS092), SANDIP SHAH (1NH13CS101), SAURABH RAI (1NH13CS104) and GAURAV KUMAR (1NH13CS718) bonafide students of NEW HORIZON COLLEGE OF ENGINEERING in partial fulfillment for the award of Bachelor of Engineering in Computer Science and Engineering of the Visvesvaraya Technological University, Belagavi during the year 2016-2017. It is certified that all corrections/suggestions indicated for Internal Assessment have been incorporated in the report deposited in the department library. The project report has been approved as it satisfies the academic requirements in respect of Project work prescribed for the Degree. Name & Signature of Guide Name Signature of HOD Signature of Principal (Ms. Sridevi) (Dr. Prashanth C.S.R.) (Dr. Manjunatha) External Viva Name of Examiner Signature with date 1. -

Reactive Sorting Networks
Reactive Sorting Networks Bjarno Oeyen Sam Van den Vonder Wolfgang De Meuter [email protected] [email protected] [email protected] Vrije Universiteit Brussel Vrije Universiteit Brussel Vrije Universiteit Brussel Brussels, Belgium Brussels, Belgium Brussels, Belgium Abstract is a key part of many applications. Implementing the stand- Sorting is a central problem in computer science and one ard textbook set of sorting algorithms is also used to serve of the key components of many applications. To the best of as a litmus test to study the expressiveness of new program- our knowledge, no reactive programming implementation ming languages and programming paradigms. To the best of of sorting algorithms has ever been presented. our knowledge, this exercise is currently lacking from the In this paper we present reactive implementations of so- literature on reactive programming. called sorting networks. Sorting networks are networks of This paper presents an implementation of a number of comparators that are wired up in a particular order. Data elementary sorting algorithms in an experimental reactive enters a sorting network along various input wires and leaves programming language called Haai [22]. One of the key in- the sorting network on the same number of output wires spirations of our research is that the canonical representation that carry the data in sorted order. of reactive programs, using directed acyclic graphs (DAGs) This paper shows how sorting networks can be expressed as dependency graphs, naturally maps onto the visual rep- elegantly in a reactive programming language by aligning the resentation of so-called sorting networks.