Learning and Classification of Malware Behavior
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Synthesizing Near-Optimal Malware Specifications from Suspicious
Synthesizing Near-Optimal Malware Specifications from Suspicious Behaviors Somesh Jha∗, Matthew Fredrikson∗, Mihai Christodoresu†, Reiner Sailer‡, Xifeng Yan§ ∗University of Wisconsin–Madison, †Qualcomm Research Silicon Valley, ‡IBM T.J Watson Research Center, §University of California–Santa Barbara Abstract—Behavior-based detection techniques are a promis- and errors. ing solution to the problem of malware proliferation. However, We make the observation that behavioral specifications they require precise specifications of malicious behavior that do not result in an excessive number of false alarms, while still are best viewed as a form of discriminative specification.A remaining general enough to detect new variants before tradi- discriminative specification describes the unique properties tional signatures can be created and distributed. In this paper, of a given class, in contrast to the properties exhibited by we present an automatic technique for extracting optimally discriminative specifications a second mutually-exclusive class. This paper presents an , which uniquely identify a class automated technique that combines program analysis, graph of programs. Such a discriminative specification can be used by a behavior-based malware detector. Our technique, based mining, and stochastic optimization to synthesize malware on graph mining and stochastic optimization, scales to large behavior specifications. We represent program behaviors as classes of programs. When this work was originally published, graphs that are mined for discriminative patterns. As there the technique yielded favorable results on malware targeted are many ways in which malware can accomplish the same towards workstations (~86% detection rates on new malware). goal, we use these patterns as building blocks for construct- We believe that it can be brought to bear on emerging malware- based threats for new platforms, and discuss several promising ing discriminative specifications that are general across vari- avenues for future work in this direction. -

Cyber Warfare a “Nuclear Option”?
CYBER WARFARE A “NUCLEAR OPTION”? ANDREW F. KREPINEVICH CYBER WARFARE: A “NUCLEAR OPTION”? BY ANDREW KREPINEVICH 2012 © 2012 Center for Strategic and Budgetary Assessments. All rights reserved. About the Center for Strategic and Budgetary Assessments The Center for Strategic and Budgetary Assessments (CSBA) is an independent, nonpartisan policy research institute established to promote innovative thinking and debate about national security strategy and investment options. CSBA’s goal is to enable policymakers to make informed decisions on matters of strategy, secu- rity policy and resource allocation. CSBA provides timely, impartial, and insight- ful analyses to senior decision makers in the executive and legislative branches, as well as to the media and the broader national security community. CSBA encour- ages thoughtful participation in the development of national security strategy and policy, and in the allocation of scarce human and capital resources. CSBA’s analysis and outreach focus on key questions related to existing and emerging threats to US national security. Meeting these challenges will require transforming the national security establishment, and we are devoted to helping achieve this end. About the Author Dr. Andrew F. Krepinevich, Jr. is the President of the Center for Strategic and Budgetary Assessments, which he joined following a 21-year career in the U.S. Army. He has served in the Department of Defense’s Office of Net Assessment, on the personal staff of three secretaries of defense, the National Defense Panel, the Defense Science Board Task Force on Joint Experimentation, and the Defense Policy Board. He is the author of 7 Deadly Scenarios: A Military Futurist Explores War in the 21st Century and The Army and Vietnam. -

The Botnet Chronicles a Journey to Infamy
The Botnet Chronicles A Journey to Infamy Trend Micro, Incorporated Rik Ferguson Senior Security Advisor A Trend Micro White Paper I November 2010 The Botnet Chronicles A Journey to Infamy CONTENTS A Prelude to Evolution ....................................................................................................................4 The Botnet Saga Begins .................................................................................................................5 The Birth of Organized Crime .........................................................................................................7 The Security War Rages On ........................................................................................................... 8 Lost in the White Noise................................................................................................................. 10 Where Do We Go from Here? .......................................................................................................... 11 References ...................................................................................................................................... 12 2 WHITE PAPER I THE BOTNET CHRONICLES: A JOURNEY TO INFAMY The Botnet Chronicles A Journey to Infamy The botnet time line below shows a rundown of the botnets discussed in this white paper. Clicking each botnet’s name in blue will bring you to the page where it is described in more detail. To go back to the time line below from each page, click the ~ at the end of the section. 3 WHITE -

MODELING the PROPAGATION of WORMS in NETWORKS: a SURVEY 943 in Section 2, Which Set the Stage for Later Sections
942 IEEE COMMUNICATIONS SURVEYS & TUTORIALS, VOL. 16, NO. 2, SECOND QUARTER 2014 Modeling the Propagation of Worms in Networks: ASurvey Yini Wang, Sheng Wen, Yang Xiang, Senior Member, IEEE, and Wanlei Zhou, Senior Member, IEEE, Abstract—There are the two common means for propagating attacks account for 1/4 of the total threats in 2009 and nearly worms: scanning vulnerable computers in the network and 1/5 of the total threats in 2010. In order to prevent worms from spreading through topological neighbors. Modeling the propa- spreading into a large scale, researchers focus on modeling gation of worms can help us understand how worms spread and devise effective defense strategies. However, most previous their propagation and then, on the basis of it, investigate the researches either focus on their proposed work or pay attention optimized countermeasures. Similar to the research of some to exploring detection and defense system. Few of them gives a nature disasters, like earthquake and tsunami, the modeling comprehensive analysis in modeling the propagation of worms can help us understand and characterize the key properties of which is helpful for developing defense mechanism against their spreading. In this field, it is mandatory to guarantee the worms’ spreading. This paper presents a survey and comparison of worms’ propagation models according to two different spread- accuracy of the modeling before the derived countermeasures ing methods of worms. We first identify worms characteristics can be considered credible. In recent years, although a variety through their spreading behavior, and then classify various of models and algorithms have been proposed for modeling target discover techniques employed by them. -
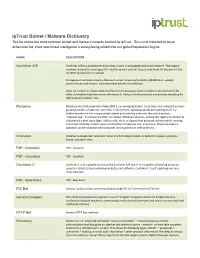
Iptrust Botnet / Malware Dictionary This List Shows the Most Common Botnet and Malware Variants Tracked by Iptrust
ipTrust Botnet / Malware Dictionary This list shows the most common botnet and malware variants tracked by ipTrust. This is not intended to be an exhaustive list, since new threat intelligence is always being added into our global Reputation Engine. NAME DESCRIPTION Conficker A/B Conficker A/B is a downloader worm that is used to propagate additional malware. The original malware it was after was rogue AV - but the army's current focus is undefined. At this point it has no other purpose but to spread. Propagation methods include a Microsoft server service vulnerability (MS08-067) - weakly protected network shares - and removable devices like USB keys. Once on a machine, it will attach itself to current processes such as explorer.exe and search for other vulnerable machines across the network. Using a list of passwords and actively searching for legitimate usernames - the ... Mariposa Mariposa was first observed in May 2009 as an emerging botnet. Since then it has infected an ever- growing number of systems; currently, in the millions. Mariposa works by installing itself in a hidden location on the compromised system and injecting code into the critical process ͞ĞdžƉůŽƌĞƌ͘ĞdžĞ͘͟/ƚŝƐknown to affect all modern Windows versions, editing the registry to allow it to automatically start upon login. Additionally, there is a guard that prevents deletion while running, and it automatically restarts upon crash/restart of explorer.exe. In essence, Mariposa opens a backdoor on the compromised computer, which grants full shell access to ... Unknown A botnet is designated 'unknown' when it is first being tracked, or before it is given a publicly- known common name. -

Common Threats to Cyber Security Part 1 of 2
Common Threats to Cyber Security Part 1 of 2 Table of Contents Malware .......................................................................................................................................... 2 Viruses ............................................................................................................................................. 3 Worms ............................................................................................................................................. 4 Downloaders ................................................................................................................................... 6 Attack Scripts .................................................................................................................................. 8 Botnet ........................................................................................................................................... 10 IRCBotnet Example ....................................................................................................................... 12 Trojans (Backdoor) ........................................................................................................................ 14 Denial of Service ........................................................................................................................... 18 Rootkits ......................................................................................................................................... 20 Notices ......................................................................................................................................... -

Computer Security Fundamentals Third Edition
Computer Security Fundamentals Third Edition Chuck Easttom 800 East 96th Street, Indianapolis, Indiana 46240 USA Computer Security Fundamentals, Third Edition Executive Editor Brett Bartow Copyright © 2016 by Pearson Education, Inc. All rights reserved. No part of this book shall be reproduced, stored in a retrieval system, or Acquisitions Editor transmitted by any means, electronic, mechanical, photocopying, recording, or otherwise, Betsy Brown without written permission from the publisher. No patent liability is assumed with respect Development Editor to the use of the information contained herein. Although every precaution has been taken in Christopher Cleveland the preparation of this book, the publisher and author assume no responsibility for errors or omissions. Nor is any liability assumed for damages resulting from the use of the information Managing Editor contained herein. Sandra Schroeder ISBN-13: 978-0-7897-5746-3 ISBN-10: 0-7897-5746-X Senior Project Editor Tonya Simpson Library of Congress control number: 2016940227 Copy Editor Printed in the United States of America Gill Editorial Services First Printing: May 2016 Indexer Brad Herriman Trademarks All terms mentioned in this book that are known to be trademarks or service marks have Proofreader been appropriately capitalized. Pearson IT Certification cannot attest to the accuracy of this Paula Lowell information. Use of a term in this book should not be regarded as affecting the validity of any trademark or service mark. Technical Editor Dr. Louay Karadsheh Warning and Disclaimer Publishing Coordinator Every effort has been made to make this book as complete and as accurate as possible, but Vanessa Evans no warranty or fitness is implied. -

Emerging Threats and Attack Trends
Emerging Threats and Attack Trends Paul Oxman Cisco Security Research and Operations PSIRT_2009 © 2009 Cisco Systems, Inc. All rights reserved. Cisco Public 1 Agenda What? Where? Why? Trends 2008/2009 - Year in Review Case Studies Threats on the Horizon Threat Containment PSIRT_2009 © 2009 Cisco Systems, Inc. All rights reserved. Cisco Public 2 What? Where? Why? PSIRT_2009 © 2009 Cisco Systems, Inc. All rights reserved. Cisco Public 3 What? Where? Why? What is a Threat? A warning sign of possible trouble Where are Threats? Everywhere you can, and more importantly cannot, think of Why are there Threats? The almighty dollar (or euro, etc.), the underground cyber crime industry is growing with each year PSIRT_2009 © 2009 Cisco Systems, Inc. All rights reserved. Cisco Public 4 Examples of Threats Targeted Hacking Vulnerability Exploitation Malware Outbreaks Economic Espionage Intellectual Property Theft or Loss Network Access Abuse Theft of IT Resources PSIRT_2009 © 2009 Cisco Systems, Inc. All rights reserved. Cisco Public 5 Areas of Opportunity Users Applications Network Services Operating Systems PSIRT_2009 © 2009 Cisco Systems, Inc. All rights reserved. Cisco Public 6 Why? Fame Not so much anymore (more on this with Trends) Money The root of all evil… (more on this with the Year in Review) War A battlefront just as real as the air, land, and sea PSIRT_2009 © 2009 Cisco Systems, Inc. All rights reserved. Cisco Public 7 Operational Evolution of Threats Emerging Threat Nuisance Threat Threat Evolution Unresolved Threat Policy and Process Reactive Process Socialized Process Formalized Process Definition Reaction Mitigation Technology Manual Process Human “In the Automated Loop” Response Evolution Burden Operational End-User “Help-Desk” Aware—Know End-User No End-User Increasingly Self- Awareness Knowledge Enough to Call Burden Reliant Support PSIRT_2009 © 2009 Cisco Systems, Inc. -

Containing Conficker to Tame a Malware
#5###4#(#%#5#6#%#5#&###,#'#(#7#5#+###9##:65#,-;/< Know Your Enemy: Containing Conficker To Tame A Malware The Honeynet Project http://honeynet.org Felix Leder, Tillmann Werner Last Modified: 30th March 2009 (rev1) The Conficker worm has infected several million computers since it first started spreading in late 2008 but attempts to mitigate Conficker have not yet proved very successful. In this paper we present several potential methods to repel Conficker. The approaches presented take advantage of the way Conficker patches infected systems, which can be used to remotely detect a compromised system. Furthermore, we demonstrate various methods to detect and remove Conficker locally and a potential vaccination tool is presented. Finally, the domain name generation mechanism for all three Conficker variants is discussed in detail and an overview of the potential for upcoming domain collisions in version .C is provided. Tools for all the ideas presented here are freely available for download from [9], including source code. !"#$%&'()*+&$(% The big years of wide-area network spreading worms were 2003 and 2004, the years of Blaster [1] and Sasser [2]. About four years later, in late 2008, we witnessed a similar worm that exploits the MS08-067 server service vulnerability in Windows [3]: Conficker. Like its forerunners, Conficker exploits a stack corruption vulnerability to introduce and execute shellcode on affected Windows systems, download a copy of itself, infect the host and continue spreading. SRI has published an excellent and detailed analysis of the malware [4]. The scope of this paper is different: we propose ideas on how to identify, mitigate and remove Conficker bots. -

Ethical Hacking
Official Certified Ethical Hacker Review Guide Steven DeFino Intense School, Senior Security Instructor and Consultant Contributing Authors Barry Kaufman, Director of Intense School Nick Valenteen, Intense School, Senior Security Instructor Larry Greenblatt, Intense School, Senior Security Instructor Australia • Brazil • Japan • Korea • Mexico • Singapore • Spain • United Kingdom • United States Official Certified Ethical Hacker © 2010 Course Technology, Cengage Learning Review Guide ALL RIGHTS RESERVED. No part of this work covered by the copyright herein Steven DeFino may be reproduced, transmitted, stored or used in any form or by any means Barry Kaufman graphic, electronic, or mechanical, including but not limited to photocopying, Nick Valenteen recording, scanning, digitizing, taping, Web distribution, information networks, Larry Greenblatt or information storage and retrieval systems, except as permitted under Section 107 or 108 of the 1976 United States Copyright Act, without the prior Vice President, Career and written permission of the publisher. Professional Editorial: Dave Garza Executive Editor: Stephen Helba For product information and technology assistance, contact us at Managing Editor: Marah Bellegarde Cengage Learning Customer & Sales Support, 1-800-354-9706 For permission to use material from this text or product, Senior Product Manager: submit all requests online at www.cengage.com/permissions Michelle Ruelos Cannistraci Further permissions questions can be e-mailed to Editorial Assistant: Meghan Orvis [email protected] -

THE CONFICKER MYSTERY Mikko Hypponen Chief Research Officer F-Secure Corporation Network Worms Were Supposed to Be Dead. Turns O
THE CONFICKER MYSTERY Mikko Hypponen Chief Research Officer F-Secure Corporation Network worms were supposed to be dead. Turns out they aren't. In 2009 we saw the largest outbreak in years: The Conficker aka Downadup worm, infecting Windows workstations and servers around the world. This worm infected several million computers worldwide - most of them in corporate networks. Overnight, it became as large an infection as the historical outbreaks of worms such as the Loveletter, Melissa, Blaster or Sasser. Conficker is clever. In fact, it uses several new techniques that have never been seen before. One of these techniques is using Windows ACLs to make disinfection hard or impossible. Another is infecting USB drives with a technique that works *even* if you have USB Autorun disabled. Yet another is using Windows domain rights to create a remote jobs to infect machines over corporate networks. Possibly to most clever part is the communication structure Conficker uses. It has an algorithm to create a unique list of 250 random domain names every day. By precalcuting one of these domain names and registering it, the gang behind Conficker could take over any or all of the millions of computers they had infected. Case Conficker The sustained growth of malicious software (malware) during the last few years has been driven by crime. Theft – whether it is of personal information or of computing resources – is obviously more successful when it is silent and therefore the majority of today's computer threats are designed to be stealthy. Network worms are relatively "noisy" in comparison to other threats, and they consume considerable amounts of bandwidth and other networking resources. -

Modeling of Computer Virus Spread and Its Application to Defense
University of Aizu, Graduation Thesis. March, 2005 s1090109 1 Modeling of Computer Virus Spread and Its Application to Defense Jun Shitozawa s1090109 Supervised by Hiroshi Toyoizumi Abstract 2 Two Systems The purpose of this paper is to model a computer virus 2.1 Content Filtering spread and evaluate content filtering and IP address blacklisting with a key parameter of the reaction time R. Content filtering is a containment system that has a We model the Sasser worm by using the Pure Birth pro- database of content signatures known to represent par- cess in this paper. Although our results require a short ticular worms. Packets containing one of these signa- reaction time, this paper is useful to obviate the outbreak tures are dropped when a containment system member of the new worms having high reproduction rate λ. receives the packets. This containment system is able to stop computer worm outbreaks immediately when the systems obtain information of content signatures. How- 1 Introduction ever, it takes too much time to create content signatures, and this system has no effect on polymorphic worms In recent years, new computer worms are being created at a rapid pace with around 5 new computer worms per a [10]. A polymorphic worm is one whose code is trans- day. Furthermore, the speed at which the new computer formed regularly, so no single signature identifies it. worms spread is amazing. For example, Symantec [5] 2.2 The IP Address Blacklisting received 12041 notifications of an infection by Sasser.B in 7 days. IP address blacklisting is a containment system that has Computer worms are a kind of computer virus.