Semantic Emoji Similarity Modeling to Support Expressive Communication � � �
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Old German Translation Tips
OLD GERMAN TRANSLATION TIPS BASIC STEPS 1. Identify the alphabet used (Fraktur, Sütterlin/Suetterlin, or Kurrent) and convert the letters to modern equivalents, and then; 2. Translate from German to English. CONVERTING OLD ALPHABETS Helps for Translating That Old German Handwriting http://nancysfamilyhistoryblog.blogspot.com/2011/06/helps-for-translating-that-old- german.html Helps for Translating the Old German Typeface http://nancysfamilyhistoryblog.blogspot.com/2011/10/helps-for-translating-old-german.html Omniglot https://www.omniglot.com/writing/german.htm –Scroll down for script styles. ONLINE TRANSLATORS AND DICTIONARIES Abkuerzungen http://abkuerzungen.de/main.php?language=de – for finding the meaning of abbreviations. Leo https://www.leo.org/german-english Members can also connect with each other via the LEO forums to ask for help. Langenscheidt online dictionary: Lingojam https://lingojam.com/OldGerman Linguee https://www.linguee.com/ Choose German → English from the dropdown menu. This site uses human translators, not machines! It gives you examples of the words used in a real-life context and provides all possible German translations of the word. You will find that anti-virus software treats some translation sites/apps (e.g. Babylon translator) as malware. ‘GENEALOGICAL GERMAN’ Family words in German https://www.omniglot.com/language/kinship/german.htm German Genealogical Word List: https://www.familysearch.org/wiki/en/German_Genealogical_Word_List Understanding a German Baptism Records http://www.stemwedegenealogy.com/baptism_sample.htm Understanding German Marriage Records http://www.stemwedegenealogy.com/marriage_sample.htm FACEBOOK HELP Genealogy Translations https://www.facebook.com/groups/genealogytranslation/ – for a wide range of languages, not only German. • Work out as much as you can for yourself first. -

ETAO Keyboard: Text Input Technique on Smartwatches
Available online at www.sciencedirect.com ScienceDirect Procedia Computer Science 84 ( 2016 ) 137 – 141 7th International conference on Intelligent Human Computer Interaction, IHCI 2015 ETAO Keyboard: Text Input Technique on Smartwatches Rajkumar Darbara,∗, Punyashlok Dasha, Debasis Samantaa aSchool of Information Technology, IIT Kharagpur, West Bengal, India Abstract In the present day context of wearable computing, smartwatches augment our mobile experience even further by providing in- formation at our wrists. What they fail to do is to provide a comprehensive text entry solution for interacting with the various app notifications they display. In this paper we present ETAO keyboard, a full-fledged keyboard for smartwatches, where a user can input the most frequent English alphabets with a single tap. Other keys which include numbers and symbols are entered by a double tap. We conducted a user study that involved sitting and walking scenarios for our experiments and after a very short training session, we achieved an average words per minute (WPM) of 12.46 and 9.36 respectively. We expect that our proposed keyboard will be a viable option for text entry on smartwatches. ©c 20162015 TheThe Authors. Authors. Published Published by byElsevier Elsevier B.V. B.V. This is an open access article under the CC BY-NC-ND license (Peer-reviehttp://creativecommons.org/licenses/by-nc-nd/4.0/w under responsibility of the Scientific). Committee of IHCI 2015. Peer-review under responsibility of the Organizing Committee of IHCI 2015 Keywords: Text entry; smartwatch; mobile usability 1. Introduction Over the past few years, the world has seen a rapid growth in wearable computing and a demand for wearable prod- ucts. -

How to Speak Emoji : a Guide to Decoding Digital Language Pdf, Epub, Ebook
HOW TO SPEAK EMOJI : A GUIDE TO DECODING DIGITAL LANGUAGE PDF, EPUB, EBOOK National Geographic Kids | 176 pages | 05 Apr 2018 | HarperCollins Publishers | 9780007965014 | English | London, United Kingdom How to Speak Emoji : A Guide to Decoding Digital Language PDF Book Secondary Col 2. Primary Col 1. Emojis are everywhere on your phone and computer — from winky faces to frowns, cats to footballs. They might combine a certain face with a particular arrow and the skull emoji, and it means something specific to them. Get Updates. Using a winking face emoji might mean nothing to us, but our new text partner interprets it as flirty. And yet, once he Parenting in the digital age is no walk in the park, but keep this in mind: children and teens have long used secret languages and symbols. However, not all users gave a favourable response to emojis. Black musicians, particularly many hip-hop artists, have contributed greatly to the evolution of language over time. A collection of poems weaving together astrology, motherhood, music, and literary history. Here begins the new dawn in the evolution the language of love: emoji. She starts planning how they will knock down the wall between them to spend more time together. Irrespective of one's political standpoint, one thing was beyond dispute: this was a landmark verdict, one that deserved to be reported and analysed with intelligence - and without bias. Though somewhat If a guy likes you, he's going to make sure that any opportunity he has to see you, he will. Here and Now Here are 10 emoticons guys use only when they really like you! So why do they do it? The iOS 6 software. -

ISO/IEC International Standard 10646-1
Final Proposed Draft Amendment (FPDAM) 5 ISO/IEC 10646:2003/Amd.5:2007 (E) Information technology — Universal Multiple-Octet Coded Character Set (UCS) — AMENDMENT 5: Tai Tham, Tai Viet, Avestan, Egyptian Hieroglyphs, CJK Unified Ideographs Extension C, and other characters Page 2, Clause 3 Normative references Page 20, Sub-clause 26.1 Hangul syllable Update the reference to the Unicode Bidirectional Algo- composition method rithm and the Unicode Normalization Forms as follows: Replace the three parenthetical notations in the second Unicode Standard Annex, UAX#9, The Unicode Bidi- sentence of the first paragraph with: rectional Algorithm, Version 5.2.0, [Date TBD]. (syllable-initial or initial consonant) (syllable-peak or medial vowel) Unicode Standard Annex, UAX#15, Unicode Normali- (syllable-final or final consonant) zation Forms, Version 5.2.0, [Date TBD]. Page 2, Clause 4 Terms and definitions Page 20, Clause 27 Source references for CJK Ideographs Replace the Code table entry with: In the list after the second paragraph, insert the follow- Code chart ing entry: Code table Hanzi M sources, A rectangular array showing the representation of coded characters allocated to the octets in a code. In the third paragraph, replace “(G, H, T, J, K, KP, V, and U)” with “(G, H, M, T, J, K, KP, V, and U)”. Remove the „Detailed code table‟ entry. Replace all further occurrences of „code table‟ in the Page 21, Sub-clause 27.1 Source references text of the standard with „code chart‟. for CJK Unified Ideographs Replace the last sentence of the second paragraph Page 13, Clause 17 Structure of the code with the following: tables and lists (now renamed „Structure of the code charts and lists‟) The current full set of CJK Unified Ideographs is represented by the collection 385 CJK UNIFIED Insert the following note after the first paragraph. -

Gaze-Typing for Everyday Use Keyboard Usability Observations and a "Tolerant'' Keyboard Prototype
DEGREE PROJECT IN INFORMATION AND COMMUNICATION TECHNOLOGY, SECOND CYCLE, 30 CREDITS STOCKHOLM, SWEDEN 2018 Gaze-typing for Everyday Use Keyboard Usability Observations and a "Tolerant'' Keyboard Prototype JIAYAO YU KTH ROYAL INSTITUTE OF TECHNOLOGY SCHOOL OF ELECTRICAL ENGINEERING AND COMPUTER SCIENCE Sammandrag Blick-skrivande möjliggör en ny inmatningskanal, men dess tangentborddesign är inte än redo för dagligt bruk. För att utforska blick-skriftstangentbord för sådant bruk, som är enkla att lära sig använda, snabba att skriva med, och robusta för olika användning, analyserade jag användbarheten hos tre brett använda blick-skriftstangentbord genom en användarstudie med skrivprestationsmätningar, och syntetiserade ett designutrymme för blick-skriftstangentbord för dagsbruk baserat på teman av typningsscheman och tangentbordslayout, feed-back, användarvänlighet för text redigering, och system design. I synnerhet identifierade jag att blick-skriftstangentbord behöver ha "toleranta" designer som tillåter implicit blickkontroll och balans mellan inmatningsambiguitet och typningseffektivitet. Därför prototypade jag ett blick-skriftstangentbord som använder ett formskriftsschema som är avsett för vardagligt skrivande med blickgester, och anpassat till att segmentera blickpunkten när du skriver ord från en kontinuerlig ström av blickdata. Systemet erbjuder realtidsformskrivning i hastigheten 11.70 WPM och felfrekvensen 0.14 utvärderat med en erfaren användare, och har stöd för att skriva fler än 20000 ord från lexikonet. Gaze-typing for Everyday Use: Keyboard Usability Observations and a “Tolerant” Keyboard Prototype Jiayao Yu KTH Royal Institute of Technology, Aalto University Stockholm, Sweden [email protected] Figure 1: Representative gaze-input properties requiring “tolerant” design. Left: Jittering fixations require larger interactive elements. Middle: Gaze are hard to gesture along complex, precise, or long trajectories. -

The Emoji Factor: Humanizing the Emerging Law of Digital Speech
The Emoji Factor: Humanizing the Emerging Law of Digital Speech 1 Elizabeth A. Kirley and Marilyn M. McMahon Emoji are widely perceived as a whimsical, humorous or affectionate adjunct to online communications. We are discovering, however, that they are much more: they hold a complex socio-cultural history and perform a role in social media analogous to non-verbal behaviour in offline speech. This paper suggests emoji are the seminal workings of a nuanced, rebus-type language, one serving to inject emotion, creativity, ambiguity – in other words ‘humanity’ - into computer mediated communications. That perspective challenges doctrinal and procedural requirements of our legal systems, particularly as they relate to such requisites for establishing guilt or fault as intent, foreseeability, consensus, and liability when things go awry. This paper asks: are we prepared as a society to expand constitutional protections to the casual, unmediated ‘low value’ speech of emoji? It identifies four interpretative challenges posed by emoji for the judiciary or other conflict resolution specialists, characterizing them as technical, contextual, graphic, and personal. Through a qualitative review of a sampling of cases from American and European jurisdictions, we examine emoji in criminal, tort and contract law contexts and find they are progressively recognized, not as joke or ornament, but as the first step in non-verbal digital literacy with potential evidentiary legitimacy to humanize and give contour to interpersonal communications. The paper proposes a separate space in which to shape law reform using low speech theory to identify how we envision their legal status and constitutional protection. 1 Dr. Kirley is Barrister & Solicitor in Canada and Seniour Lecturer and Chair of Technology Law at Deakin University, MelBourne Australia; Dr. -

5892 Cisco Category: Standards Track August 2010 ISSN: 2070-1721
Internet Engineering Task Force (IETF) P. Faltstrom, Ed. Request for Comments: 5892 Cisco Category: Standards Track August 2010 ISSN: 2070-1721 The Unicode Code Points and Internationalized Domain Names for Applications (IDNA) Abstract This document specifies rules for deciding whether a code point, considered in isolation or in context, is a candidate for inclusion in an Internationalized Domain Name (IDN). It is part of the specification of Internationalizing Domain Names in Applications 2008 (IDNA2008). Status of This Memo This is an Internet Standards Track document. This document is a product of the Internet Engineering Task Force (IETF). It represents the consensus of the IETF community. It has received public review and has been approved for publication by the Internet Engineering Steering Group (IESG). Further information on Internet Standards is available in Section 2 of RFC 5741. Information about the current status of this document, any errata, and how to provide feedback on it may be obtained at http://www.rfc-editor.org/info/rfc5892. Copyright Notice Copyright (c) 2010 IETF Trust and the persons identified as the document authors. All rights reserved. This document is subject to BCP 78 and the IETF Trust's Legal Provisions Relating to IETF Documents (http://trustee.ietf.org/license-info) in effect on the date of publication of this document. Please review these documents carefully, as they describe your rights and restrictions with respect to this document. Code Components extracted from this document must include Simplified BSD License text as described in Section 4.e of the Trust Legal Provisions and are provided without warranty as described in the Simplified BSD License. -
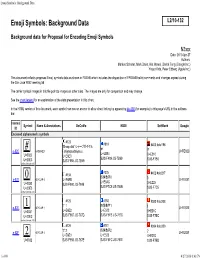
Emoji Symbols: Background Data
Emoji Symbols: Background Data Emoji Symbols: Background Data Background data for Proposal for Encoding Emoji Symbols N3xxx Date: 2010-Apr-27 Authors: Markus Scherer, Mark Davis, Kat Momoi, Darick Tong (Google Inc.) Yasuo Kida, Peter Edberg (Apple Inc.) This document reflects proposed Emoji symbols data as shown in FDAM8 which includes the disposition of FPDAM8 ballot comments and changes agreed during the San José WG2 meeting 56. The carrier symbol images in this file point to images on other sites. The images are only for comparison and may change. See the chart legend for an explanation of the data presentation in this chart. In the HTML version of this document, each symbol row has an anchor to allow direct linking by appending #e-4B0 (for example) to this page's URL in the address bar. Internal Symbol Name & Annotations DoCoMo KDDI SoftBank Google ID Enclosed alphanumeric symbols #123 #818 'Sharp dial' シャープダイヤル #403 #old196 # # # e-82C ⃣ HASH KEY 「shiyaapudaiyaru」 U+FE82C U+EB84 U+0023 U+E6E0 U+E210 SJIS-F489 JIS-7B69 U+20E3 SJIS-F985 JIS-7B69 SJIS-F7B0 unified (Unicode 3.0) #325 #134 #402 #old217 0 四角数字0 0 e-837 ⃣ KEYCAP 0 U+E6EB U+FE837 U+E5AC U+0030 SJIS-F990 JIS-784B U+E225 U+20E3 SJIS-F7C9 JIS-784B SJIS-F7C5 unified (Unicode 3.0) #125 #180 #393 #old208 1 '1' 1 四角数字1 1 e-82E ⃣ KEYCAP 1 U+FE82E U+0031 U+E6E2 U+E522 U+E21C U+20E3 SJIS-F987 JIS-767D SJIS-F6FB JIS-767D SJIS-F7BC unified (Unicode 3.0) #126 #181 #394 #old209 '2' 2 四角数字2 e-82F KEYCAP 2 2 U+FE82F 2⃣ U+E6E3 U+E523 U+E21D U+0032 SJIS-F988 JIS-767E SJIS-F6FC JIS-767E SJIS-F7BD -

Public Company Analysis 6
MOBILE SMART FUNDAMENTALS MMA MEMBERS EDITION NOVEMBER 2014 messaging . advertising . apps . mcommerce www.mmaglobal.com NEW YORK • LONDON • SINGAPORE • SÃO PAULO MOBILE MARKETING ASSOCIATION NOVEMBER 2014 REPORT Measurement & Creativity Thoughts for 2015 Very simply, mobile marketing will continue to present the highest growth opportunities for marketers faced with increasing profitability as well as reaching and engaging customers around the world. Widely acknowledged to be the channel that gets you the closest to your consumers, those marketers that leverage this uniqueness of mobile will gain competitive footholds in their vertical markets, as well as use mobile to transform their marketing and their business. The MMA will be focused on two cores issues which we believe will present the biggest opportunities and challenges for marketers and the mobile industry in 2015: Measurement and Creativity. On the measurement side, understanding the effectiveness of mobile: the ROI of a dollar spent and the optimized level for mobile in the marketing mix will become more and more critical as increased budgets are being allocated towards mobile. MMA’s SMoX (cross media optimization research) will provide the first-ever look into this. Additionally, attribution and understanding which mobile execution (apps, video, messaging, location etc…) is working for which mobile objective will be critical as marketers expand their mobile strategies. On the Creative side, gaining a deeper understanding of creative effectiveness cross-screen and having access to case studies from marketers that are executing some beautiful campaigns will help inspire innovation and further concentration on creating an enhanced consumer experience specific to screen size. We hope you’ve had a successful 2014 and we look forward to being a valuable resource to you again in 2015. -

Emoticon Style: Interpreting Differences in Emoticons Across Cultures
Emoticon Style: Interpreting Differences in Emoticons Across Cultures Jaram Park Vladimir Barash Clay Fink Meeyoung Cha Graduate School of Morningside Analytics Johns Hopkins University Graduate School of Culture Technology, KAIST [email protected] Applied Physics Laboratory Culture Technology, KAIST [email protected] clayton.fi[email protected] [email protected] Abstract emotion not captured by language elements alone (Lo 2008; Gajadhar and Green 2005). With the advent of mobile com- Emoticons are a key aspect of text-based communi- cation, and are the equivalent of nonverbal cues to munications, the use of emoticons has become an everyday the medium of online chat, forums, and social media practice for people throughout the world. Interestingly, the like Twitter. As emoticons become more widespread emoticons used by people vary by geography and culture. in computer mediated communication, a vocabulary Easterners, for example employ a vertical style like ^_^, of different symbols with subtle emotional distinctions while westerners employ a horizontal style like :-). This dif- emerges especially across different cultures. In this pa- ference may be due to cultural reasons since easterners are per, we investigate the semantic, cultural, and social as- known to interpret facial expressions from the eyes, while pects of emoticon usage on Twitter and show that emoti- westerners favor the mouth (Yuki, Maddux, and Masuda cons are not limited to conveying a specific emotion 2007; Mai et al. 2011; Jack et al. 2012). or used as jokes, but rather are socio-cultural norms, In this paper, we study emoticon usage on Twitter based whose meaning can vary depending on the identity of the speaker. -

New Emoji Requests from Twitter Users: When, Where, Why, and What We Can Do About Them
1 New Emoji Requests from Twitter Users: When, Where, Why, and What We Can Do About Them YUNHE FENG, University of Tennessee, Knoxville, USA ZHENG LU, University of Tennessee, Knoxville, USA WENJUN ZHOU, University of Tennessee, Knoxville, USA ZHIBO WANG, Wuhan University, China QING CAO∗, University of Tennessee, Knoxville, USA As emojis become prevalent in personal communications, people are always looking for new, interesting emojis to express emotions, show attitudes, or simply visualize texts. In this study, we collected more than thirty million tweets mentioning the word “emoji” in a one-year period to study emoji requests on Twitter. First, we filtered out bot-generated tweets and extracted emoji requests from the raw tweets using a comprehensive list of linguistic patterns. To our surprise, some extant emojis, such as fire and hijab , were still frequently requested by many users. A large number of non-existing emojis were also requested, which were classified into one of eight emoji categories by Unicode Standard. We then examined patterns of new emoji requests by exploring their time, location, and context. Eagerness and frustration of not having these emojis were evidenced by our sentiment analysis, and we summarize users’ advocacy channels. Focusing on typical patterns of co-mentioned emojis, we also identified expressions of equity, diversity, and fairness issues due to unreleased but expected emojis, and summarized the significance of new emojis on society. Finally, time- continuity sensitive strategies at multiple time granularity levels were proposed to rank petitioned emojis by the eagerness, and a real-time monitoring system to track new emoji requests is implemented. -

Deciphering Old German Documents Using the Online German Script Tutorial Bradley J
Deciphering Old German Documents Using the Online German Script Tutorial Bradley J. York Center for Family History and Genealogy at Brigham Young University Abstract The German Script Tutorial (http://script.byu.edu/german) is a new online resource for learning how to decipher documents written in old German script. The German Script Tutorial provides descriptions and actual examples of each German letter. Animations demonstrate how each letter is written. Tests assess users’ ability to read and write letters, words, and passages. User accounts allow users to save their test scores and keep track of which letters they need to practice. The tutorial also provides basic guidelines on how to find vital (i.e., genealogical) in- formation in old German documents. Introduction One of the greatest difficulties in German genealogical research is deciphering old docu- ments and manuscripts written in old German script. The term old German script refers to the handwriting and typefaces that were widely used in German-speaking countries from me- dieval times to the end of World War II. Al- though old German script was based on the Latin alphabet, as were old English, French, Italian, and Spanish scripts, individual letters of old German script may appear to the untrained eye as unique as letters of the Cyrillic or even Arabic alphabets. Since old German script has not been taught in German schools since the 1950’s, even most native Germans are unable to read and write it nowadays. Thus, decipher- This is an old German emigration document consisting of printed and handwritten information. Both the hand- ing old German documents is problematic for writing and the printed Fraktur typeface are styles of old German script.