Architecture of Grabbing Text, Indexing and Retrieving Information From
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-
Download Windows Live Messenger for Linux Ubuntu
Download windows live messenger for linux ubuntu But installing applications in Ubuntu that were originally made for I found emescene to be the best Msn Messenger for Ubuntu Linux so far. It really gives you the feel as if you are using Windows Live Messenger. Its builds are available for Archlinux, Debian, Ubuntu, Fedora, Mandriva and Windows. At first I found it quite difficult to use Pidgin Internet Messenger on Ubuntu Linux. Even though it allows signing into MSN, Yahoo! Messenger and Google Talk. While finding MSN Messenger for Linux / Ubuntu, I found different emesene is also available and could be downloaded and installed for. At first I found it quite difficult to use Pidgin Internet Messenger on Ubuntu Linux. Even though it allows signing into MSN, Yahoo! Messenger. A simple & beautiful app for Facebook Messenger. OS X, Windows & Linux By downloading Messenger for Desktop, you acknowledge that it is not an. An alternative MSN Messenger chat client for Linux. It allows Linux users to chat with friends who use MSN Messenger in Windows or Mac OS. The strength of. Windows Live Messenger is an instant messenger application that For more information on installing applications, see InstallingSoftware. sudo apt-get install chromium-browser. 2. After the installation is Windows Live Messenger running in LinuxMint / Ubuntu. You can close the. Linux / X LAN Messenger for Debian/Ubuntu LAN Messenger for Fedora/openSUSE Download LAN Messenger for Windows. Windows installer A MSN Messenger / Live Messenger client for Linux, aiming at integration with the KDE desktop Ubuntu: Ubuntu has KMess in its default repositories. -

Msn 9 Offline Installer
Msn 9 offline installer click here to download Since the link to install the windows live essentials version has officially dropped from Microsoft Windows Live Essentials () ENG Offline Installer Link alexisnik UTC #9. Internet Explorer 9 is the recommended browser for Windows Vista. Now with Bing and MSN defaults for an improved web experience. Microsoft does not provide any link to download full offline installer of Windows Live Messenger , instead you will find the integrated live. MSN Messenger 9 Offline Installer. Live Messenger Microsoft does not provide any link to download full offline installer of Windows Live. Install MSN software. To download and install MSN software, click Install Now. Install System requirements and recommendations. Minimum. Microsoft®. Follow the instructions to order and install from a CD here. 9. Click Next to complete installation. Once the installation has completed the install wizard will. MSN Windows Live Messenger Full Offline Installer. calculo70 MSN e offline Links Windows XP SP3 Pt Br Original IE 8 MSN 9 a Istalador. msn ie8 windows 7 full installer Download Link . 9/14/ · To download the offline installer for Internet Explorer 11, choose your language and system below. Windows Live Messenger (formerly MSN Messenger) is a software, Using Microsoft, MSN, MSN Windows Live, offline installer, offline setup, Send Sms For. Smash • 9 months ago. Thank you for the offline installer. Well just installed, i choose only to download MSN Messenger, but it said that i had. Yahoo messenger 9 final full offline installer You can add and check status of your MSN Live messenger contacts in Yahoo messenger. -
Instant Messaging Video Converter, Iphone Converter Application
Web Browsing Mozilla Firefox The premier free, open-source browser. Tabs, pop-up blocking, themes, and extensions. Considered by many to be the world's best browser. Download Page Video Player, Torrents, Podcasting Miro Beautiful interface. Plays any video type (much more than quicktime). Subscribe to video RSS, download, and watch all in one. Torrent support. Search and download from YouTube and others. Download Page IM - Instant Messaging Adium Connect to multiple IM accounts simultaneously in a single app, including: AOL IM, MSN, and Jabber. Beautiful, themable interface. Download Page Video Converter, iPhone Converter Miro Video Converter Convert any type of video to mp4 or theora. Convert any video for use with iPhone, iPod, Android, etc. Very clean, easy to use interface. Download Page Application Launching Quicksilver Quicksilver lets you start applications (and do just about everything) with a few quick taps of your fingers. Warning: start using Quicksilver and you won't be able to imagine using a Mac without it. Download Page Email Mozilla Thunderbird Powerful spam filtering, solid interface, and all the features you need. Download Page Utilities The Unarchiver Uncompress RAR, 7zip, tar, and bz2 files on your Mac. Many new Mac users will be puzzled the first time they download a RAR file. Do them a favor and download UnRarX for them! Download Page DVD Ripping Handbrake DVD ripper and MPEG-4 / H.264 encoding. Very simple to use. Download Page RSS Vienna Very nice, native RSS client. Download Page RSSOwl Solid cross-platform RSS client. Download Page Peer-to-Peer Filesharing Cabos A simple, easy to use filesharing program. -

Unpermitted Resources
Process Check and Unpermitted Resources Common and Important Virtual Machines Parallels VMware VirtualBox CVMCompiler Windows Virtual PC Other Python Citrix Screen/File Sharing/Saving .exe File Name VNC, VPN, RFS, P2P and SSH Virtual Drives ● Dropbox.exe ● Dropbox ● OneDrive.exe ● OneDrive ● <name>.exe ● Google Drive ● etc. ● iCloud ● etc. Evernote / One Note ● Evernote_---.exe ● onenote.exe Go To Meeting ● gotomeeting launcher.exe / gotomeeting.exe TeamViewer ● TeamViewer.exe Chrome Remote ● remoting_host.exe www.ProctorU.com ● [email protected] ● 8883553043 Messaging / Video (IM, IRC) / .exe File Name Audio Bonjour Google Hangouts (chrome.exe - shown as a tab) (Screen Sharing) Skype SkypeC2CPNRSvc.exe Music Streaming ● Spotify.exe (Spotify, Pandora, etc.) ● PandoraService.exe Steam Steam.exe ALL Processes Screen / File Sharing / Messaging / Video (IM, Virtual Machines (VM) Other Saving IRC) / Audio Virtual Box Splashtop Bonjour ● iChat ● iTunes ● iPhoto ● TiVo ● SubEthaEdit ● Contactizer, ● Things ● OmniFocuse phpVirtualBox TeamViewer MobileMe Parallels Sticky Notes Team Speak VMware One Note Ventrilo Windows Virtual PC Dropbox Sandboxd QEM (Linux only) Chrome Remote iStumbler HYPERBOX SkyDrive MSN Chat Boot Camp (dual boot) OneDrive Blackboard Chat CVMCompiler Google Drive Yahoo Messenger Office (Word, Excel, Skype etc.) www.ProctorU.com ● [email protected] ● 8883553043 2X Software Notepad Steam AerooAdmin Paint Origin AetherPal Go To Meeting Spotify Ammyy Admin Jing Facebook Messenger AnyDesk -

Product Guide Revision A
Product Guide Revision A McAfee Data Loss Prevention 9.3.1 For use with ePolicy Orchestrator 4.5, 4.6, 5.0 Software COPYRIGHT Copyright © 2014 McAfee, Inc. Do not copy without permission. TRADEMARK ATTRIBUTIONS McAfee, the McAfee logo, McAfee Active Protection, McAfee DeepSAFE, ePolicy Orchestrator, McAfee ePO, McAfee EMM, Foundscore, Foundstone, Policy Lab, McAfee QuickClean, Safe Eyes, McAfee SECURE, SecureOS, McAfee Shredder, SiteAdvisor, McAfee Stinger, McAfee Total Protection, TrustedSource, VirusScan, WaveSecure are trademarks or registered trademarks of McAfee, Inc. or its subsidiaries in the United States and other countries. Other names and brands may be claimed as the property of others. Product and feature names and descriptions are subject to change without notice. Please visit mcafee.com for the most current products and features. LICENSE INFORMATION License Agreement NOTICE TO ALL USERS: CAREFULLY READ THE APPROPRIATE LEGAL AGREEMENT CORRESPONDING TO THE LICENSE YOU PURCHASED, WHICH SETS FORTH THE GENERAL TERMS AND CONDITIONS FOR THE USE OF THE LICENSED SOFTWARE. IF YOU DO NOT KNOW WHICH TYPE OF LICENSE YOU HAVE ACQUIRED, PLEASE CONSULT THE SALES AND OTHER RELATED LICENSE GRANT OR PURCHASE ORDER DOCUMENTS THAT ACCOMPANY YOUR SOFTWARE PACKAGING OR THAT YOU HAVE RECEIVED SEPARATELY AS PART OF THE PURCHASE (AS A BOOKLET, A FILE ON THE PRODUCT CD, OR A FILE AVAILABLE ON THE WEBSITE FROM WHICH YOU DOWNLOADED THE SOFTWARE PACKAGE). IF YOU DO NOT AGREE TO ALL OF THE TERMS SET FORTH IN THE AGREEMENT, DO NOT INSTALL THE SOFTWARE. IF APPLICABLE, YOU MAY RETURN THE PRODUCT TO MCAFEE OR THE PLACE OF PURCHASE FOR A FULL REFUND. -

Mining Criminal Networks from Chat Log
2012 IEEE/WIC/ACM International Conferences on Web Intelligence and Intelligent Agent Technology This is the preprint version. See IEEE for the final official version. Mining Criminal Networks from Chat Log Farkhund Iqbal Benjamin C. M. Fung Mourad Debbabi College of Information Technology CIISE CIISE Zayed University Concordia University Concordia University Abu Dhabi, United Arab Emirates Montreal, Canada H3G 1M8 Montreal, Canada H3G 1M8 Email: [email protected] Email: [email protected] Email: [email protected] Abstract—Cybercriminals exploit opportunities for anonymity and masquerade in web-based communication to conduct illegal activities such as phishing, spamming, cyber predation, cyber threatening, blackmail, and drug trafficking. One way to fight cybercrime is to collect digital evidence from online documents and to prosecute cybercriminals in the court of law. In this paper, we propose a unified framework using data mining and natural language processing techniques to analyze online messages for the purpose of crime investigation. Our framework takes the chat log from a confiscated computer as input, extracts the social networks from the log, summarizes chat conversations into topics, identifies the information relevant to crime investigation, and visualizes the knowledge for an investigator. To ensure that the implemented framework meets the needs of law enforcement officers in real-life investigation, we closely collaborate with the cybercrime unit of a law enforcement agency in Canada. Both the feedback from the law enforcement officers and experimental results suggest that the proposed chat log mining framework is effective for crime Fig. 1. Framework overview investigation. Index Terms—crime investigation; criminal networks; data level information, such as IPs, protocols, and path traveled mining; frequent patterns; topic mining. -

Débuter Avec Miranda IM
Débuter avec Miranda IM TUTORIEL RÉALISÉ PAR DRUSS Présentation Miranda est un client de messagerie instantanée multi-protocoles, gratuit, open-source, léger, portable, personnalisable et esthétique. Il est une alternative à MSN (WLM) qui est un programme propriétaire de Microsoft, et dont certaines fonctionnalités laissent à désirer. Miranda vous permettra non seulement d'utiliser le protocole MSN, mais aussi IRC, AIM, Gtalk, ICQ, Yahoo Messenger, et bien d'autres. Cependant, il est relativement difficile pour un nouvel utilisateur de s'y retrouver dans la multitude d'options que ce programme propose. Ce tutoriel a donc pour but de vous faire découvrir Miranda et de vous guider dans vos premières utilisations, afin que le logiciel soit convivial et adapté à vos besoins. Miranda ne fonctionne actuellement que pour Windows, de 95 à Vista. Des projets pour le porter sous Linux sont en cours, mais pour l'instant, il vous faudra utiliser Wine. Avantages Je liste ci dessous les avantages de Miranda, du moins par rapport à MSN : – multi-protocoles – libre et gratuit – sans publicité – personnalisable, skinnable... esthétique – possibilité de renommer les contacts – possibilité de créer des sous-groupes – discussions par onglets (ou fenêtres, c'est au choix) – des centaines de plugins Sites et IRC Site Français : http://www.miranda-fr.net/ Page de téléchargements : http://www.miranda-fr.net/telechargements/ Le forum français : http://forum.miranda-fr.net/ Officiel, anglais : http://miranda-im.org/ Les addons : http://addons.miranda-im.org/ Liste des tutoriels français : http://forum.miranda-fr.net/tutoriaux-vf14.html Autre tutoriel pour les premiers pas sous Miranda : http://www.miranda-fr.net/faqs/premiers_pas,_installation_et_configuration..html IRC : #miranda-fr et #miranda sur le serveur FreeNode. -

Linux Journal
Open Science Travel Laptop Auto-Download Means Open Source Tips Linux Journal Since 1994: The original magazine of the Linux community PHOTOGRAPHY AND FOSS +DEEP DIVE: High Performance Computing ISSUE 293 | DECEMBER 2018 www.linuxjournal.com DECEMBER 2018 CONTENTS ISSUE 293 78 DEEP DIVE: High-Performance Computing 79 Linux and Supercomputers by Bryan Lunduke As we sit here, in the year Two Thousand and Eighteen (better known as “the future, where the robots live”), our beloved Linux is the undisputed king of supercomputing. Of the top 500 supercomputers in the world, approximately zero of them don’t run Linux (give or take...zero). 90 Data in a Flash, Part I: the Evolution of Disk Storage and an Introduction to NVMe by Petros Koutoupis NVMe drives have paved the way for computing at stellar speeds, but the technology didn’t suddenly appear overnight. It was through an evolutionary process that we now rely on the very performant SSD for our primary storage tier. 106 Data in a Flash, Part II: Using NVMe Drives and Creating an NVMe over Fabrics Network by Petros Koutoupis By design, NVMe drives are intended to provide local access to the machines they are plugged in to; however, the NVMe over Fabric specification seeks to address this very limitation by enabling remote network access to that same device. 2 | December 2018 | http://www.linuxjournal.com CONTENTS 6 The High-Performance Computing Issue by Bryan Lunduke 10 From the Editor—Doc Searls How Can We Bring FOSS to the Virtual World? 16 Letters UPFRONT 24 Auto-Download Linux Journal Each Month by Mitch Frazier 29 FOSS Project Spotlight: Appaserver by Tim Riley 35 Patreon and Linux Journal 36 Using Linux for Logic by Joey Bernard 44 Lessons in Vendor Lock-in: Messaging by Kyle Rankin 49 Reality 2.0: a Linux Journal Podcast 50 News Briefs COLUMNS 52 Kyle Rankin’s Hack and / Travel Laptop Tips in Practice 56 Reuven M. -

Sample Chapter
5674ch01.qxd_jt 9/24/03 8:44 AM Page 1 11 TheThe OnlineOnline WorldWorld 5674ch01.qxd_jt 9/24/03 8:44 AM Page 2 Today’s online world has changed dramatically in the last decade. Back then, online to the average user meant a telephone connection directly to either another computer or to an online service, such as CompuServe or AOL. The Internet now dominates all online activity. In popular parlance, the Internet is synonymous with the World Wide Web, although it is much more, as we’ll explain in this book. The Internet can be described generally as a “network” of networks. It is a transportation vehicle for applications. In fact, the visual representations of the Net look like a road map. If lines are drawn between each connection, between larger and larger connections, and between smaller and smaller ones, the end result is a web of connections—a virtual road map. This book is divided into four rough sections. The first is for beginners. It is to get anyone up to speed quickly with the information needed about the Web. Each chapter has recommended Web sites (to type the address, or Uniform Resource Locator [URL] into your Web browser) to help direct you. The second section has more detailed information about downloads, email, secu- rity, and information on virus protection. The third part is about how to create a Web site, Web tools, blogging, and what you can add to your Web site (such as streaming media, RSS feeds, and XML, among other things). The fourth part is by far the densest. -
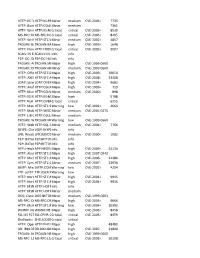
HTTP: IIS "Propfind" Rem HTTP:IIS:PROPFIND Minor Medium
HTTP: IIS "propfind"HTTP:IIS:PROPFIND RemoteMinor DoS medium CVE-2003-0226 7735 HTTP: IkonboardHTTP:CGI:IKONBOARD-BADCOOKIE IllegalMinor Cookie Languagemedium 7361 HTTP: WindowsHTTP:IIS:NSIISLOG-OF Media CriticalServices NSIISlog.DLLcritical BufferCVE-2003-0349 Overflow 8035 MS-RPC: DCOMMS-RPC:DCOM:EXPLOIT ExploitCritical critical CVE-2003-0352 8205 HTTP: WinHelp32.exeHTTP:STC:WINHELP32-OF2 RemoteMinor Buffermedium Overrun CVE-2002-0823(2) 4857 TROJAN: BackTROJAN:BACKORIFICE:BO2K-CONNECT Orifice 2000Major Client Connectionhigh CVE-1999-0660 1648 HTTP: FrontpageHTTP:FRONTPAGE:FP30REG.DLL-OF fp30reg.dllCritical Overflowcritical CVE-2003-0822 9007 SCAN: IIS EnumerationSCAN:II:IIS-ISAPI-ENUMInfo info P2P: DC: DirectP2P:DC:HUB-LOGIN ConnectInfo Plus Plus Clientinfo Hub Login TROJAN: AOLTROJAN:MISC:AOLADMIN-SRV-RESP Admin ServerMajor Responsehigh CVE-1999-0660 TROJAN: DigitalTROJAN:MISC:ROOTBEER-CLIENT RootbeerMinor Client Connectmedium CVE-1999-0660 HTTP: OfficeHTTP:STC:DL:OFFICEART-PROP Art PropertyMajor Table Bufferhigh OverflowCVE-2009-2528 36650 HTTP: AXIS CommunicationsHTTP:STC:ACTIVEX:AXIS-CAMERAMajor Camerahigh Control (AxisCamControl.ocx)CVE-2008-5260 33408 Unsafe ActiveX Control LDAP: IpswitchLDAP:OVERFLOW:IMAIL-ASN1 IMail LDAPMajor Daemonhigh Remote BufferCVE-2004-0297 Overflow 9682 HTTP: AnyformHTTP:CGI:ANYFORM-SEMICOLON SemicolonMajor high CVE-1999-0066 719 HTTP: Mini HTTP:CGI:W3-MSQL-FILE-DISCLSRSQL w3-msqlMinor File View mediumDisclosure CVE-2000-0012 898 HTTP: IIS MFCHTTP:IIS:MFC-EXT-OF ISAPI FrameworkMajor Overflowhigh (via -

A Case Study of Effective Practices for the Management of Global Software Development Projects
University of Nebraska at Omaha DigitalCommons@UNO Student Work 12-1-2005 A case study of effective practices for the management of global software development projects Mudita Agarwal University of Nebraska at Omaha Follow this and additional works at: https://digitalcommons.unomaha.edu/studentwork Recommended Citation Agarwal, Mudita, "A case study of effective practices for the management of global software development projects" (2005). Student Work. 1361. https://digitalcommons.unomaha.edu/studentwork/1361 This Thesis is brought to you for free and open access by DigitalCommons@UNO. It has been accepted for inclusion in Student Work by an authorized administrator of DigitalCommons@UNO. For more information, please contact [email protected]. A CASE STUDY OF EFFECTIVE PRACTICES FOR THE MANAGEMENT OF GLOBAL SOFTWARE DEVELOPMENT PROJECTS A Thesis Presented to the Department of Information Systems and Quantitative Analysis and the Faculty of the Graduate College University of Nebraska In Partial Fulfillment of the Requirements for the Degree Master of Science in Management Information Systems University of Nebraska at Omaha By Mudita Agarwal December, 2005 UMI Number: EP73401 All rights reserved INFORMATION TO ALL USERS The quality of this reproduction is dependent upon the quality of the copy submitted. In the unlikely event that the author did not send a complete manuscript and there are missing pages, these will be noted. Also, if material had to be removed, a note will indicate the deletion. Dissertation Pubi shmq UMI EP73401 Published by ProQuest LLC (2015). Copyright in the Dissertation held by the Author. Microform Edition © ProQuest LLC. All rights reserved. This work is protected against unauthorized copying under Title 17, United States Code ProQuest LLC. -
Computer Forensic Tools Comparison Chart
FOR INTERNAL USE ONLY Computer Forensic Tools Comparison Chart Guidance Software AccessData X-Ways Paraben’s Belkasoft TechPathways EnCase Forensic 7 FTK 5 Forensic P2 Commander 3.0 Evidence Center ProDiscover Price $3,600** $4,603*** €999.90 $1,095 $1,099 $2,195 Annual Maintenance $599 $840 $220 $363 $395 Annual Maintenance Included? Yes No Yes Yes No No Additional Requirements None Oracle Adv. Server None None MS SQL Server None System Requirements Average PC High-End PC Average to Low PC Average PC Average to High PC Average to Low PC Case File Single/Separate File Server Database Single/Separate File Server Database Single/Separate File 64-bit OS Support Windows 8 Support Supported Disk Images Raw DD PFR EnCase Safeback 2 Safeback 3 S.M.A.R.T. WinImage Non-Compressed Images WinImage Compressed Images vmWare Static & Dynamic Disk Images VirtualPC Static & Dynamic Disk Images & VirtualPC Snapshots Supported File Systems Fat 12/16/32 NTFS EXT2 & 3 HFS+, HFSX HSFX Solaris UFS BSD FFS JFS LV2M CD/DVD RAIDS File Analysis - View, Search, & Export Multimedia Files Documents Microsoft Exchange E-mail (EDB) Corrupted MS Exchange E-mail (EDB) Advanced Data Recovery of EDB Lotus Notes E-mail (NSF) Corrupted Lotus Notes E-mail (NSF) Advanced Data Recovery of NSF Novell Groupwise E-mail Microsoft Outlook E-mail (PST) Microsoft Outlook Express Windows Mail E-mail The Bat! E-mail America Online (AOL) Database Thunderbird E-mail Eudora E-mail E-mail Files (EML) Maildir Database Yahoo! Messenger Chat History MSN Chat History Skype Chat/Call History