Reinders SIGGRAPH 2017 As Presented
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Operating Systems and Applications for Embedded Systems >>> Toolchains
>>> Operating Systems And Applications For Embedded Systems >>> Toolchains Name: Mariusz Naumowicz Date: 31 sierpnia 2018 [~]$ _ [1/19] >>> Plan 1. Toolchain Toolchain Main component of GNU toolchain C library Finding a toolchain 2. crosstool-NG crosstool-NG Installing Anatomy of a toolchain Information about cross-compiler Configruation Most interesting features Sysroot Other tools POSIX functions AP [~]$ _ [2/19] >>> Toolchain A toolchain is the set of tools that compiles source code into executables that can run on your target device, and includes a compiler, a linker, and run-time libraries. [1. Toolchain]$ _ [3/19] >>> Main component of GNU toolchain * Binutils: A set of binary utilities including the assembler, and the linker, ld. It is available at http://www.gnu.org/software/binutils/. * GNU Compiler Collection (GCC): These are the compilers for C and other languages which, depending on the version of GCC, include C++, Objective-C, Objective-C++, Java, Fortran, Ada, and Go. They all use a common back-end which produces assembler code which is fed to the GNU assembler. It is available at http://gcc.gnu.org/. * C library: A standardized API based on the POSIX specification which is the principle interface to the operating system kernel from applications. There are several C libraries to consider, see the following section. [1. Toolchain]$ _ [4/19] >>> C library * glibc: Available at http://www.gnu.org/software/libc. It is the standard GNU C library. It is big and, until recently, not very configurable, but it is the most complete implementation of the POSIX API. * eglibc: Available at http://www.eglibc.org/home. -

XL C/C++: Language Reference About This Document
IBM XL C/C++ for Linux, V16.1.1 IBM Language Reference Version 16.1.1 SC27-8045-01 IBM XL C/C++ for Linux, V16.1.1 IBM Language Reference Version 16.1.1 SC27-8045-01 Note Before using this information and the product it supports, read the information in “Notices” on page 63. First edition This edition applies to IBM XL C/C++ for Linux, V16.1.1 (Program 5765-J13, 5725-C73) and to all subsequent releases and modifications until otherwise indicated in new editions. Make sure you are using the correct edition for the level of the product. © Copyright IBM Corporation 1998, 2018. US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents About this document ......... v Chapter 4. IBM extension features ... 11 Who should read this document........ v IBM extension features for both C and C++.... 11 How to use this document.......... v General IBM extensions ......... 11 How this document is organized ....... v Extensions for GNU C compatibility ..... 15 Conventions .............. v Extensions for vector processing support ... 47 Related information ........... viii IBM extension features for C only ....... 56 Available help information ........ ix Extensions for GNU C compatibility ..... 56 Standards and specifications ........ x Extensions for vector processing support ... 58 Technical support ............ xi IBM extension features for C++ only ...... 59 How to send your comments ........ xi Extensions for C99 compatibility ...... 59 Extensions for C11 compatibility ...... 59 Chapter 1. Standards and specifications 1 Extensions for GNU C++ compatibility .... 60 Chapter 2. Language levels and Notices .............. 63 language extensions ......... 3 Trademarks ............. -

Section “Common Predefined Macros” in the C Preprocessor
The C Preprocessor For gcc version 12.0.0 (pre-release) (GCC) Richard M. Stallman, Zachary Weinberg Copyright c 1987-2021 Free Software Foundation, Inc. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.3 or any later version published by the Free Software Foundation. A copy of the license is included in the section entitled \GNU Free Documentation License". This manual contains no Invariant Sections. The Front-Cover Texts are (a) (see below), and the Back-Cover Texts are (b) (see below). (a) The FSF's Front-Cover Text is: A GNU Manual (b) The FSF's Back-Cover Text is: You have freedom to copy and modify this GNU Manual, like GNU software. Copies published by the Free Software Foundation raise funds for GNU development. i Table of Contents 1 Overview :::::::::::::::::::::::::::::::::::::::: 1 1.1 Character sets:::::::::::::::::::::::::::::::::::::::::::::::::: 1 1.2 Initial processing ::::::::::::::::::::::::::::::::::::::::::::::: 2 1.3 Tokenization ::::::::::::::::::::::::::::::::::::::::::::::::::: 4 1.4 The preprocessing language :::::::::::::::::::::::::::::::::::: 6 2 Header Files::::::::::::::::::::::::::::::::::::: 7 2.1 Include Syntax ::::::::::::::::::::::::::::::::::::::::::::::::: 7 2.2 Include Operation :::::::::::::::::::::::::::::::::::::::::::::: 8 2.3 Search Path :::::::::::::::::::::::::::::::::::::::::::::::::::: 9 2.4 Once-Only Headers::::::::::::::::::::::::::::::::::::::::::::: 9 2.5 Alternatives to Wrapper #ifndef :::::::::::::::::::::::::::::: -

Cheat Sheets of the C Standard Library
Cheat Sheets of the C standard library Version 1.06 Last updated: 2012-11-28 About This document is a set of quick reference sheets (or ‘cheat sheets’) of the ANSI C standard library. It contains function and macro declarations in every header of the library, as well as notes about their usage. This document covers C++, but does not cover the C99 or C11 standard. A few non-ANSI-standard functions, if they are interesting enough, are also included. Style used in this document Function names, prototypes and their parameters are in monospace. Remarks of functions and parameters are marked italic and enclosed in ‘/*’ and ‘*/’ like C comments. Data types, whether they are built-in types or provided by the C standard library, are also marked in monospace. Types of parameters and return types are in bold. Type modifiers, like ‘const’ and ‘unsigned’, have smaller font sizes in order to save space. Macro constants are marked using proportional typeface, uppercase, and no italics, LIKE_THIS_ONE. One exception is L_tmpnum, which is the constant that uses lowercase letters. Example: int system ( const char * command ); /* system: The value returned depends on the running environment. Usually 0 when executing successfully. If command == NULL, system returns whether the command processor exists (0 if not). */ License Copyright © 2011 Kang-Che “Explorer” Sung (宋岡哲 <explorer09 @ gmail.com>) This work is licensed under the Creative Commons Attribution 3.0 Unported License. http://creativecommons.org/licenses/by/3.0/ . When copying and distributing this document, I advise you to keep this notice and the references section below with your copies, as a way to acknowledging all the sources I referenced. -

Nesc 1.2 Language Reference Manual
nesC 1.2 Language Reference Manual David Gay, Philip Levis, David Culler, Eric Brewer August 2005 1 Introduction nesC is an extension to C [3] designed to embody the structuring concepts and execution model of TinyOS [2]. TinyOS is an event-driven operating system designed for sensor network nodes that have very limited resources (e.g., 8K bytes of program memory, 512 bytes of RAM). TinyOS has been reimplemented in nesC. This manual describes v1.2 of nesC, changes from v1.0 and v1.1 are summarised in Section 2. The basic concepts behind nesC are: • Separation of construction and composition: programs are built out of components, which are assembled (“wired”) to form whole programs. Components define two scopes, one for their specification (containing the names of their interfaces) and one for their implementation. Components have internal concurrency in the form of tasks. Threads of control may pass into a component through its interfaces. These threads are rooted either in a task or a hardware interrupt. • Specification of component behaviour in terms of set of interfaces. Interfaces may be provided or used by the component. The provided interfaces are intended to represent the functionality that the component provides to its user, the used interfaces represent the functionality the component needs to perform its job. • Interfaces are bidirectional: they specify a set of functions to be implemented by the inter- face’s provider (commands) and a set to be implemented by the interface’s user (events). This allows a single interface to represent a complex interaction between components (e.g., registration of interest in some event, followed by a callback when that event happens). -

INTRODUCTION to ANSI C Outline
1/17/14 INTRODUCTION TO ANSI C Dr. Chokchai (Box) Leangsuksun Louisiana Tech University Original slides were created by Dr. Tom Chao Zhou, https://www.cse.cuhk.edu.hk 1 Outline • History • Introduction to C – Basics – If Statement – Loops – Functions – Switch case – Pointers – Structures – File I/O Louisiana Tech University 2 1 1/17/14 Introduction • The C programming language was designed by Dennis Ritchie at Bell Laboratories in the early 1970s • Influenced by – ALGOL 60 (1960), – CPL (Cambridge, 1963), – BCPL (Martin Richard, 1967), – B (Ken Thompson, 1970) • Traditionally used for systems programming, though this may be changing in favor of C++ • Traditional C: – The C Programming Language, by Brian Kernighan and Dennis Ritchie, 2nd Edition, Prentice Hall – Referred to as K&R Original by Fred Kuhns) Louisiana Tech University 3 Standard C • Standardized in 1989 by ANSI (American National Standards Institute) known as ANSI C • International standard (ISO) in 1990 which was adopted by ANSI and is known as C89 • As part of the normal evolution process the standard was updated in 1995 (C95) and 1999 (C99) • C++ and C – C++ extends C to include support for Object Oriented Programming and other features that facilitate large software development projects – C is not strictly a subset of C++, but it is possible to write “Clean C” that conforms to both the C++ and C standards. Original by Fred Kuhns) Original by Fred Kuhns) Louisiana Tech University 4 2 1/17/14 Elements of a C Program • A C development environment: – Application Source: application source and header files – System libraries and headers: a set of standard libraries and their header files. -
C Language Features
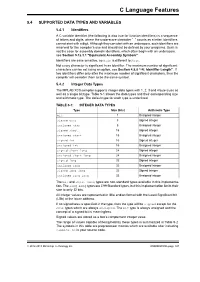
C Language Features 5.4 SUPPORTED DATA TYPES AND VARIABLES 5.4.1 Identifiers A C variable identifier (the following is also true for function identifiers) is a sequence of letters and digits, where the underscore character “_” counts as a letter. Identifiers cannot start with a digit. Although they can start with an underscore, such identifiers are reserved for the compiler’s use and should not be defined by your programs. Such is not the case for assembly domain identifiers, which often begin with an underscore, see Section 5.12.3.1 “Equivalent Assembly Symbols”. Identifiers are case sensitive, so main is different to Main. Not every character is significant in an identifier. The maximum number of significant characters can be set using an option, see Section 4.8.8 “-N: Identifier Length”. If two identifiers differ only after the maximum number of significant characters, then the compiler will consider them to be the same symbol. 5.4.2 Integer Data Types The MPLAB XC8 compiler supports integer data types with 1, 2, 3 and 4 byte sizes as well as a single bit type. Table 5-1 shows the data types and their corresponding size and arithmetic type. The default type for each type is underlined. TABLE 5-1: INTEGER DATA TYPES Type Size (bits) Arithmetic Type bit 1 Unsigned integer signed char 8 Signed integer unsigned char 8 Unsigned integer signed short 16 Signed integer unsigned short 16 Unsigned integer signed int 16 Signed integer unsigned int 16 Unsigned integer signed short long 24 Signed integer unsigned short long 24 Unsigned integer signed long 32 Signed integer unsigned long 32 Unsigned integer signed long long 32 Signed integer unsigned long long 32 Unsigned integer The bit and short long types are non-standard types available in this implementa- tion. -

Choosing System C Library
Choosing System C library Khem Raj Comcast Embedded Linux Conference Europe 2014 Düsseldorf Germany Introduction “God defined C standard library everything else is creation of man” Introduction • Standard library for C language • Provides primitives for OS service • Hosted/freestanding • String manipulations • Types • I/O • Memory • APIs Linux Implementations • GNU C library (glibc) • uClibc • eglibc – Now merged into glibc • Dietlibc • Klibc • Musl • bionic Multiple C library FAQs • Can I have multiple C libraries side by side ? • Can programs compiled with glibc run on uclibc or vice versa ? • Are they functional compatible ? • Do I need to choose one over other if I am doing real time Linux? • I have a baremetal application what libc options do I have ? Posix Compliance • Posix specifies more than ISO C • Varying degree of compliance What matters to you ? • Code Size • Functionality • Interoperability • Licensing • Backward Compatibility • Variety of architecture support • Dynamic Linking • Build system Codesize • Dietlibc/klibc – Used in really small setup e.g. initramfs • Bionic – Small linked into every process • uClibc – Configurable • Size can be really small at the expense of functionality • Eglibc – Has option groups can be ( < 1M ) License • Bionic – BSD/Apache-2.0 • Musl - MIT • Uclibc – LGPL-2.1 • Eglibc/Glibc – LGPL-2.1 Assigned to FSF • Dietlibc – GPLv2 • Klibc – GPLv2 • Newlib – some parts are GPLv3 Compliance • Musl strives for ISO/C and POSIX compliance No-mmu • uClibc supported No-mmu Distributions • Glibc is used in -

An ECMA-55 Minimal BASIC Compiler for X86-64 Linux®
Computers 2014, 3, 69-116; doi:10.3390/computers3030069 OPEN ACCESS computers ISSN 2073-431X www.mdpi.com/journal/computers Article An ECMA-55 Minimal BASIC Compiler for x86-64 Linux® John Gatewood Ham Burapha University, Faculty of Informatics, 169 Bangsaen Road, Tambon Saensuk, Amphur Muang, Changwat Chonburi 20131, Thailand; E-mail: [email protected] Received: 24 July 2014; in revised form: 17 September 2014 / Accepted: 1 October 2014 / Published: 1 October 2014 Abstract: This paper describes a new non-optimizing compiler for the ECMA-55 Minimal BASIC language that generates x86-64 assembler code for use on the x86-64 Linux® [1] 3.x platform. The compiler was implemented in C99 and the generated assembly language is in the AT&T style and is for the GNU assembler. The generated code is stand-alone and does not require any shared libraries to run, since it makes system calls to the Linux® kernel directly. The floating point math uses the Single Instruction Multiple Data (SIMD) instructions and the compiler fully implements all of the floating point exception handling required by the ECMA-55 standard. This compiler is designed to be small, simple, and easy to understand for people who want to study a compiler that actually implements full error checking on floating point on x86-64 CPUs even if those people have little programming experience. The generated assembly code is also designed to be simple to read. Keywords: BASIC; compiler; AMD64; INTEL64; EM64T; x86-64; assembly 1. Introduction The Beginner’s All-purpose Symbolic Instruction Code (BASIC) language was invented by John G. -

Strlen Strcpy
Strlen Description The strlen() function shall compute the number of bytes in the string to which s points, not including the terminating null byte. Return value The strlen() function shall return the length of s; the function has no failure mode and no error return. Prototype Declared in string.h size_t strlen(const char *s); Strcpy Prototype Declared in string.h In C90, the prototype is: char *strcpy(char *dest, const char *src); The C99 prototype is identical but adds the new restrict qualifiers: char *strcpy(char * restrict dest, const char * restrict src); Description The strcpy() function shall copy the null-terminated string pointed to by src to the memory pointed to by dest. Source and destination may not overlap. Return value The strcpy() function shall return the pointer dest; the function has no failure mode and no error return. Strcat Description The strcat() function shall append the null-terminated string pointed to by src to the null-terminated string pointed to by dest. The first character of src overwrites the null-terminator of dest. Source and destination may not overlap. Return value The strcat() function shall return the pointer dest; the function has no failure mode and no error return. Prototype Declared in string.h In C90, the prototype is: char *strcat(char *dest, const char *src); Strcmp Description The strcmp() function compares the string pointed to by s1 to the string pointed to by s2. Return value The strcmp() function returns an integer greater than, equal to, or less than zero, accordingly as the string pointed to by s1 is greater than, equal to, or less than the string pointed to by s2. -

Advanced Openmp
Advanced OpenMP Other APIs What’s wrong with OpenMP? • OpenMP is designed for programs where you want a fixed number of threads, and you always want the threads to be consuming CPU cycles. – cannot arbitrarily start/stop threads – cannot put threads to sleep and wake them up later • OpenMP is good for programs where each thread is doing (more-or-less) the same thing. • Although OpenMP supports C++, it’s not especially OO friendly – though it is gradually getting better. • OpenMP doesn’t support Java What’s wrong with Java threads? • Lacks some of the higher level functionality of OpenMP • Performance of Java may not match that of Fortran or C • OO model doesn’t suit some types of scientific computation very well • Some HPC systems don’t support Java – there is no standardised interface for message passing in Java What are the alternatives? • POSIX threads • C++ threads • Intel TBB • Cilk • OpenCL (not an exhaustive list!) POSIX threads • POSIX threads (or Pthreads) is a standard library for shared memory programming without directives. – Part of the ANSI/IEEE 1003.1 standard (1996) • Interface is a C library – no standard Fortran interface – can be used with C++, but not OO friendly • Widely available – even for Windows – typically installed as part of OS – code is pretty portable • Lots of low-level control over behaviour of threads • Execution model similar to Java threads Thread forking #include <pthread.h> int pthread_create( pthread_t *thread, const pthread_attr_t *attr, void*(*start_routine, void*), void *arg) • Creates a new thread: – first argument returns a pointer to a thread descriptor. – can set attributes. -

02 - Lecture - C Language Basics
02 - Lecture - C language basics --------------------------------- Data types in C ---------------- char <= short <= int <= long <= long long - C standard does not specify byte sizes of these types. - on most systems: char is 1 byte, short is 2, int is 4, long long is 8. - long is the problematic one: Most 32-bit systems and 64-bit Windows: 4 bytes 64-bit UNIX (such as our Linux system): 8 bytes Java: 8 bytes - if you need to ensure byte sizes, use int<N>_t types: - int8_t, int16_t, int32_t, int64_t - #include <stdint.h> - defined in C99 standard - binary numbers and their hexadecimal representations Binary Dec Hex Binary Dec Hex 0000 0 0 1000 8 8 0001 1 1 1001 9 9 0010 2 2 1010 10 A 0011 3 3 1011 11 B 0100 4 4 1100 12 C 0101 5 5 1101 13 D 0110 6 6 1110 14 E 0111 7 7 1111 15 F - two’s-complement encoding for representing negative numbers - assign negative weight to the most significant bit (MSB) - results in asymmetry - there is one more negative number - some important numbers at the boundaries: 0x00....00 0x7F....FF 0x80....00 0xFF....FF - to negate n-bit integer: binary-subtract the number from 2^n, or equivalently, flip the bits and binary-add 1. - examples of integer variable decralations: int x; int x, y; int x = 0, y; char c = ’x’; char c = ’\n’; char c = ’\13’; char c = ’0’; char c = ’\0’; char c = 0; long x = 0L; unsigned version of all of the above unsigned long x = 0, y = 0xff00ff00ff00ff00UL uint32_t x = 0xffffffff - conversion between signed and unsigned preserves bit patterns: char c = -1; unsigned char uc = c; int i = uc;