Say What? Why Users Choose to Speak Their Web Queries
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-
Only Imagine
I CAN ONLY IMAGINE I CAN A Memoir ONLY IMAGINE Bart Millard a memoir With Robert Noland Bart Millard with robert noland Imagine_A.indd 7 10/3/17 10:11 AM Appendix 1 YOUR IDENTITY IN CHRIST My mentor, Rusty Kennedy, was integral in discipling me in my walk with Christ. He gave me these seventy- five verses and state- ments while I was unpacking my past and starting to understand who I truly am in Jesus. Ever since then, I have carried these close to my heart. I pray these will minister to you the way they have to me so that you, too, can understand that in Christ, you are free indeed! 1. John 1:12—I am a child of God. 2. John 15:1–5—I am a part of the true vine, a channel (branch) of His life. 3. John 15:15—I am Christ’s friend. 4. John 15:16—I am chosen and appointed by Christ to bear His fruit. 5. Acts 1:8—I am a personal witness of Christ for Christ. 6. Romans 3:24—I have been justified and redeemed. 7. Romans 5:1—I have been justified (completely forgiven and made righteous) and am at peace with God. 8. Romans 6:1–6—I died with Christ and died to the power of sin’s rule in my life. APPENDIX 1 9. Romans 6:7—I have been freed from sin’s power over me. 10. Romans 6:18—I am a slave of righteousness. 11. Romans 6:22—I am enslaved to God. -

Celebrity and Race in Obama's America. London
Cashmore, Ellis. "To be spoken for, rather than with." Beyond Black: Celebrity and Race in Obama’s America. London: Bloomsbury Academic, 2012. 125–135. Bloomsbury Collections. Web. 29 Sep. 2021. <http://dx.doi.org/10.5040/9781780931500.ch-011>. Downloaded from Bloomsbury Collections, www.bloomsburycollections.com, 29 September 2021, 05:30 UTC. Copyright © Ellis Cashmore 2012. You may share this work for non-commercial purposes only, provided you give attribution to the copyright holder and the publisher, and provide a link to the Creative Commons licence. 11 To be spoken for, rather than with ‘“I’m not going to put a label on it,” said Halle Berry about something everyone had grown accustomed to labeling. And with that short declaration she made herself arguably the most engaging black celebrity.’ uperheroes are a dime a dozen, or, if you prefer, ten a penny, on Planet SAmerica. Superman, Batman, Captain America, Green Lantern, Marvel Girl; I could fi ll the rest of this and the next page. The common denominator? They are all white. There are benevolent black superheroes, like Storm, played most famously in 2006 by Halle Berry (of whom more later) in X-Men: The Last Stand , and Frozone, voiced by Samuel L. Jackson in the 2004 animated fi lm The Incredibles. But they are a rarity. This is why Will Smith and Wesley Snipes are so unusual: they have both played superheroes – Smith the ham-fi sted boozer Hancock , and Snipes the vampire-human hybrid Blade . Pulling away from the parallel reality of superheroes, the two actors themselves offer case studies. -

Praise & Worship from Moody Radio
Praise & Worship from Moody Radio 04/28/15 Tuesday 12 A (CT) Air Time (CT) Title Artist Album 12:00:10 AM Hold Me Jesus Big Daddy Weave Every Time I Breathe (2006) 12:03:59 AM Do Something Matthew West Into The Light 12:07:59 AM Wonderful Merciful Savior Selah Press On (2001) 12:12:20 AM Jesus Loves Me Chris Tomlin Love Ran Red (2014) 12:15:45 AM Crown Him With Many Crowns Michael W. Smith/Anointed I'll Lead You Home (1995) 12:21:51 AM Gloria Todd Agnew Need (2009) 12:24:36 AM Glory Phil Wickham The Ascension (2013) 12:27:47 AM Do Everything Steven Curtis Chapman Do Everything (2011) 12:31:29 AM O Love Of God Laura Story God Of Every Story (2013) 12:34:26 AM Hear My Worship Jaime Jamgochian Reason To Live (2006) 12:37:45 AM Broken Together Casting Crowns Thrive (2014) 12:42:04 AM Love Has Come Mark Schultz Come Alive (2009) 12:45:49 AM Reach Beyond Phil Stacey/Chris August Single (2015) 12:51:46 AM He Knows Your Name Denver & the Mile High Orches EP 12:55:16 AM More Than Conquerors Rend Collective The Art Of Celebration (2014) Praise & Worship from Moody Radio 04/28/15 Tuesday 1 A (CT) Air Time (CT) Title Artist Album 1:00:08 AM You Are My All In All Nichole Nordeman WOW Worship: Yellow (2003) 1:03:59 AM How Can It Be Lauren Daigle How Can It Be (2014) 1:08:12 AM Truth Calvin Nowell Start Somewhere 1:11:57 AM The One Aaron Shust Morning Rises (2013) 1:15:52 AM Great Is Thy Faithfulness Avalon Faith: A Hymns Collection (2006) 1:21:50 AM Beyond Me Toby Mac TBA (2015) 1:25:02 AM Jesus, You Are Beautiful Cece Winans Throne Room 1:29:53 AM No Turning Back Brandon Heath TBA (2015) 1:32:59 AM My God Point of Grace Steady On 1:37:28 AM Let Them See You JJ Weeks Band All Over The World (2009) 1:40:46 AM Yours Steven Curtis Chapman This Moment 1:45:28 AM Burn Bright Natalie Grant Hurricane (2013) 1:51:42 AM Indescribable Chris Tomlin Arriving (2004) 1:55:27 AM Made New Lincoln Brewster Oxygen (2014) Praise & Worship from Moody Radio 04/28/15 Tuesday 2 A (CT) Air Time (CT) Title Artist Album 2:00:09 AM Beautiful MercyMe The Generous Mr. -

Praise & Worship
pg0144_Layout 1 4/4/2017 1:07 PM Page 44 Soundtracks! H ot New Artist! pages 24–27 ease! ew Rele page N 43 More than 10,000 CDs and 186,000 Music Downloads available at Christianbook.com! page 8 1–800–CHRISTIAN (1-800-247-4784) pg0203_Layout 1 4/4/2017 1:07 PM Page 2 NEW! Elvis Presley Joey Feek NEW! Crying in If Not for You the Chapel Showcasing some of the Celebrating Elvis’s commitment first songs Joey Feek ever to his faith, this newly compiled recorded, this album in- collection features “His Hand cludes “That’s Important to in Mine,” “How Great Thou Art,” Me,” “Strong Enough to Cry,” “Peace in the Valley,” “He “Nothing to Remember,” Touched Me,” “Amaz ing Grace,” “The Cowboy’s Mine,” and more. “Southern Girl,” and more. WRCD31415 Retail $9.99 . .CBD $8.99 WRCD34415 Retail $11.99 . .CBD $9.99 Also available: WR933623 If Not for You—Book and CD . 15.99 14.99 David Phelps NEW! Hymnal Deal! Phelps’s flawless tenor inter- pretations will lift your appre- Joey+Rory Hymns That Are ciation of favorite hymns to a whole new level! Features “In Important to Us the Garden,” “How Great Thou The beloved country duo Art,” “Battle Hymn of the Re- sings their favorite hymns! public,” and more. Includes “I Need Thee Every Hour,” “He Touched WRCD32200 Retail $13.99 . .CBD $11.99 Me,” “I Surrender All,” “The Also available: Old Rugged Cross,” “How WRCD49082 Freedom . 13.99 11.99 WR918393 Freedom—DVD . 19.99 15.99 Great Thou Art,” and more. -
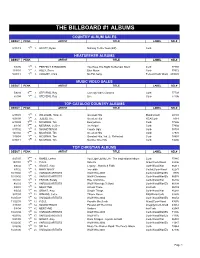
Billboard #1 Records
THE BILLBOARD #1 ALBUMS COUNTRY ALBUM SALES DEBUTPEAK ARTIST TITLE LABEL SEL# (1) 5/11/19 1 1. SCOTT, Dylan Nothing To Do Town (EP) Curb HEATSEEKER ALBUMS DEBUTPEAK ARTIST TITLE LABEL SEL# (1) 7/8/95 1 1. PERFECT STRANGER You Have The Right To Remain Silent Curb 77799 (1) 11/3/01 1 2. HOLY, Steve Blue Moon Curb 77972 (1) 5/21/11 1 3. AUGUST, Chris No Far Away Fervent/Curb-Word 888065 MUSIC VIDEO SALES DEBUTPEAK ARTIST TITLE LABEL SEL# (28) 5/8/93 1 1. STEVENS, Ray Comedy Video Classics Curb 77703 (6) 5/7/94 1 2. STEVENS, Ray Live Curb 77706 TOP CATALOG COUNTRY ALBUMS DEBUTPEAK ARTIST TITLE LABEL SEL# (1) 6/15/91 1 1. WILLIAMS, Hank Jr. Greatest Hits Elektra/Curb 60193 (2) 8/21/93 1 2. JUDDS, The Greatest Hits RCA/Curb 8318 (26) 6/19/99 1 3. MCGRAW, Tim Everywhere Curb 77886 (18) 4/1/00 1 4. MESSINA, Jo Dee I'm Alright Curb 77904 (1) 8/17/02 1 5. SOUNDTRACK Coyote Ugly Curb 78703 (54) 12/7/02 1 6. MCGRAW, Tim Greatest Hits Curb 77978 (2) 1/19/08 1 7. MCGRAW, Tim Greatest Hits, Vol. 2: Reflected Curb 78891 (4) 6/16/11 1 8. MCGRAW, Tim Number One Hits Curb 79205 TOP CHRISTIAN ALBUMS DEBUTPEAK ARTIST TITLE LABEL SEL# (35) 9/27/97 1 1. RIMES, LeAnn You Light Up My Life: The Inspirational Album Curb 77885 (35) 10/7/01 1 2. P.O.D. Satellite Atlant/Curb-Word 83496 (5) 6/8/02 1 3. -

1 Resources List Songbooks (Contains Printable Sheet Music
1 Resources List Songbooks (contains printable sheet music, chord charts and lyric text files for every song of the album) & trax (backing tracks) 1 Alvin Slaughter On The Inside Trax R&B/Gospel R 100 2 Alvin Slaughter The Faith Life Songbook Praise+Worship R 155 Matching songbook to Alvin Slaughter's The Faith Life album, including all songs arranged for vocal and piano. 3 Alvin Slaughter The Faith Life Trax Praise+Worship R 100 4 Beth Moore An Invitation to Freedom CD Spoken Word R 80 5 Brian Doerksen Holy God Trax Praise+Worship R 100 6 Brian Doerksen Worship Songwriting 6DVD Box Set Praise+Worship R 205 7 Brian Doerksen You Shine WLA Praise+Worship R 120 8 Casting Crowns Casting Crowns Songbook CCM R 190 9 Casting Crowns Lifesong Songbook CCM R 190 10 Casting Crowns The Altar And The Door Songbook CCM R 190 Matching songbook to Casting Crowns' The Altar and the Door, including all songs arranged for easy piano. 11 CeCe Winans The Best of CeCe Winans Songbook R&B/Gospel R 190 14 favourite songs from the gospel superstar: Alabaster Box . All That I Need . Hallelujah Praise . He's Always There . It Wasn't Easy . King of Kings (He's a Wonder) . Looking Back at You . Pray . Purified . Say a Prayer . Slippin' . Throne Room . Well Alright . What About You. 12 Chris Tomlin The Chris Tomlin Collection Songbook Praise+Worship R 190 13 Delirious Glo Songbook CCM R 120 14 Delirious King of Fools Songbook CCM R 120 15 Delirious The Mission Bell Songbook CCM R 120 16 Deluge Unshakable CD-ROM Praise+Worship R 145 17 Deluge Unshakable TRAX Praise+Worship R 100 18 Desperation Band Desperation Band CD-Rom Praise+Worship R 200 19 Desperation Band Light Up The World CD-Rom CD-Rom Praise+Worship R 145 20 Don Moen Hiding Place Songbook Praise+Worship R 120 This companion songbook to Don Moen's Hiding Place includs all songs from the album, arranged for piano, vocal, and guitar. -

HAPPENINGS at HOLY SPIRIT 17Th Sunday After Pentecost—Bible Sunday 7:00 PM Outreach Mission Team (Zoom) September 27, 2020 7:00 PM Staff Support (Zoom) Weds
CALENDAR Sun. 9/27 2:30 PM Rejoicing Spirits Connections (Zoom) Mon. 9/28 10:00 AM Fly to A.B.E. (Zoom) 5:30 PM Color/Décor Sub-Team (Narthex) 7:00 PM Bldg. Project Leaders/Sub teams (Zoom) Tues. 9/29 10:00 AM Staff Meeting (Zoom) 6:00 PM Bldg. Reopening Team (Zoom) HAPPENINGS AT HOLY SPIRIT 17th Sunday after Pentecost—Bible Sunday 7:00 PM Outreach Mission Team (Zoom) September 27, 2020 7:00 PM Staff Support (Zoom) Weds. 9/30 6:00 PM Picnic-N-Prayer (Church Lawn) PLEASE NOTE THAT FOR THIS SUNDAY ONLY, WE WILL NOT BE ON FACEBOOK LIVE—PLEASE CONNECT WITH US ON ZOOM. Sat. 10/3 2:30 PM Blessing of the Animals (Zoom) Sun. 10/11 2:30 PM Rejoicing Spirits Service Sunday Worship Schedule via Zoom: 8:50 am Zoom Worship Room opens and remains open Sun. 10/18 2:00 PM Pumpkins in the Parking Lot Fall Event 8:57 am Children’s Music 9:00 am Family Worship 9:20 am Kids Connections 9:40 am Readers and Assisting Ministers Log on 9:50 am Gathering Music *See note below * 10:00 am Spirit Worship followed by Connections 11:00 am Center for Faith and Life (CFL), CAT Class 2:30 pm Rejoicing Spirits Fellowship Time Please remember to have bread, grape juice or wine available and ready for digital communion which will be offered at both services. The following three year olds, third graders and sixth graders will be receiving a Bible on Sunday * PICNIC -n- PRAYER * as a gift from the congregation. -

New from Hillsong! New Release!
pg0144v2_Layout 1 3/30/2018 3:44 PM Page 45 40th Anniversary Spring/Summer 2018 New Release! NEW CD by Smitty on back cover and backlist on pages 2 & 3 $ Deal!5 page 2 New from Hillsong! page 6 More than 15,000 albums and 215,000 downloads available at Christianbook.com! page 7 1–800–CHRISTIAN (1-800-247-4784) pg0203_Layout 1 3/30/2018 3:40 PM Page 2 Price good Deal! through 5/31/18, then $9.99! Paul Baloche: Ultimate Collection For three decades, Baloche has helped believers world- wide praise the “King of Heav- en.” Worship along with “Open the Eyes of My Heart,” “Glori- ous,” “Offering,” “Above All,” “My Hope,” and more. UECD71072 Retail $13.99 . .CBD $7.99 NEW! NEW! Country Faith Love Songs Celebrate love with some of the biggest names in country music! Enjoy “Thank You” (Keith Ur- ban); “Don’t Take the Girl” (Tim McGraw); “When I’m Gone” (Joey & Rory); and more. UECD83315 Retail $13.98 . .CBD $11.99 Michael W. Smith Surrounded A brand-new soul-stirring offering to the worldwide church! This Table of Contents powerful live recording includes “Your House”; “Light to You”; “Reckless Accompaniment Tracks . .24–27 Love”; “Do It Again”; “Great Are You, Lord”; the title track; and more. Bargains . .3 UECD25509 Retail $13.99 . .CBD $9.79 Black Gospel . .35 Have you heard . Contemporary & Pop . .36–41 UECD16827 Decades of Worship . 11.99 9.99 UECD11535 Worship . 9.99 8.49 Favorite Artists . .42, 43 UECD9658 Worship Again . 9.99 8.99 Hymns . -

Pg0140 Layout 1
New Releases HILLSONG UNITED: LIVE IN MIAMI Table of Contents Giving voice to a generation pas- Accompaniment Tracks . .14, 15 sionate about God, the modern Bargains . .20, 21, 38 rock praise & worship band shares 22 tracks recorded live on their Collections . .2–4, 18, 19, 22–27, sold-out Aftermath Tour. Includes 31–33, 35, 36, 38, 39 the radio single “Search My Heart,” “Break Free,” “Mighty to Save,” Contemporary & Pop . .6–9, back cover “Rhythms of Grace,” “From the Folios & Songbooks . .16, 17 Inside Out,” “Your Name High,” “Take It All,” “With Everything,” and the Gifts . .back cover tour theme song. Two CDs. Hymns . .26, 27 $ 99 KTCD23395 Retail $14.99 . .CBD Price12 Inspirational . .22, 23 Also available: Instrumental . .24, 25 KTCD28897 Deluxe CD . 19.99 15.99 KT623598 DVD . 14.99 12.99 Kids’ Music . .18, 19 Movie DVDs . .A1–A36 he spring and summer months are often New Releases . .2–5 Tpacked with holidays, graduations, celebra- Praise & Worship . .32–37 tions—you name it! So we had you and all your upcoming gift-giving needs in mind when we Rock & Alternative . .10–13 picked the products to feature on these pages. Southern Gospel, Country & Bluegrass . .28–31 You’ll find $5 bargains on many of our best-sell- WOW . .39 ing albums (pages 20 & 21) and 2-CD sets (page Search our entire music and film inventory 38). Give the special grad in yourConGRADulations! life something unique and enjoyable with the by artist, title, or topic at Christianbook.com! Class of 2012 gift set on the back cover. -

Epiphany Star
Epiphany Star Editor: Rusty Ogden Episcopal Church of the Epiphany 1101 Sunset Drive; P. O. Box 116 December 2016 Guntersville, AL 35976 256-582-4897 www.EpiphanyGuntersville.org POINSETTIAS FOR FLOWERS AND CANDLES FOR 2017 CHRISTMAS 2016 The Altar Guild is taking dedications for The Altar Guild is taking dedications for flowers and candles for 2017. This is a red Poinsettias. We will need 50 to beautiful and thoughtful way to celebrate, decorate the church for Christmas. and remember those in our lives who mean Each poinsettia plant is $15.00. so much to us. Dedication forms are at the back of the The candle and flowers signup sheets for nave and on the counter in the church 2017 are posted on the nave bulletin board. Please re- office. This dedication, which appears in the Christmas bul- member that these are done on a first come – first serve letins, is a beautiful way to honor those people who are basis. Place your order now or you may call Susan Arm- special in our lives and to celebrate the birth of a baby born strong at 256-302-3801. If a flower date you would like is so long ago in a stable and under a starry sky. already spoken for, look at that same date on the candle list. We appreciate your payment when you sign up or no later than December 23rd, so it can be processed for year-end. Rodney’s Flowers bills each individual directly for the Sunday altar flowers. If you have any questions please see/call Susan Armstrong at 256-302-3801. -

Music and Memory: an Erp Examination of Music As a Mnemonic
MUSIC AND MEMORY: AN ERP EXAMINATION OF MUSIC AS A MNEMONIC DEVICE by Andrew Santana BA A thesis submitted to the Graduate Council of Texas State University in partial fulfillment of the requirements for the degree of Master of Psychology with a Major in Psychological Research August 2016 Committee Members: Rebecca Deason - Chair Carmen Westerberg William Kelemen COPYRIGHT by Andrew Santana 2016 FAIR USE AND AUTHOR’S PERMISSION STATEMENT Fair Use This work is protected by the Copyright Laws of the United States (Public Law 94-553, section 107). Consistent with fair use as defined in the Copyright Laws, brief quotations from this material are allowed with proper acknowledgment. Use of this material for financial gain without the author’s express written permission is not allowed. Duplication Permission As the copyright holder of this work I, Andrew Santana, authorize duplication of this work, in whole or in part, for educational or scholarly purposes only. ACKNOWLEDGEMENTS I would like to thank my committee, especially Dr. Deason, for their patience during the process of obtaining my Masters. I would also like to thank Katherine Mooney, Ruben Vela, Gregory Caparis, Ilanna Tariff, and David Russell for helping make this research a possibility. iv TABLE OF CONTENTS Page ACKNOWLEDGEMENTS ............................................................................................... iv LIST OF TABLES ............................................................................................................. vi LIST OF FIGURES ......................................................................................................... -

1914 the Ascap Story 1964 to Page 27
FEBRUARY 29, 1964 SEVENTIETH YEAR 50 CENTS New Radio Study 7A^ I NEW YORK-Response Ratings, a new and unique continuing study measuring radio station and jockey effectiveness, will he 'r, launched in next week's issue. This comprehensive radio analysis- another exclusive Billboard feature-will he carried weekly. Three different markets will be profiled in each issue. It will kick off in the March 7 Billboard with a complete study of the New York, Nashville, and San Francisco markets. In subsequent weeks, the study will consider all key areas. This service has been hailed by broadcast The International Music -Record Newsweekly industry leaders as a major breakthrough in station and personality Radio -TV Programming Phono-Tape Merchandising Coin Machine Operating analysis. Beatles Business Booms But Blessings Mixed Beatles Bug BeatlesGross r z As They 17 Mil. Plus Paris Dealer, 31-4*- t 114 In 6 Months 150 Yrs. Old, Control Air NEW YORK - In the six By JACK MAHER six months prior to the peak of Keeps Pace NEW YORK - While a few their American success, Beatles manufacturers were congratu- records grossed $17,500,000 ac- Story on Page 51 lating the Beatles for infusing cording to EMI managing direc- new life and excitement into the tor John Wall. record business others were This figure, which does not quietly venting their spleen include the huge sales of Beatles against the British group. records ín the U. S., shows the At the nub of their blasphe- staggering impact the group has mies was the enormous amount had on the record industry t r 1.+ra.