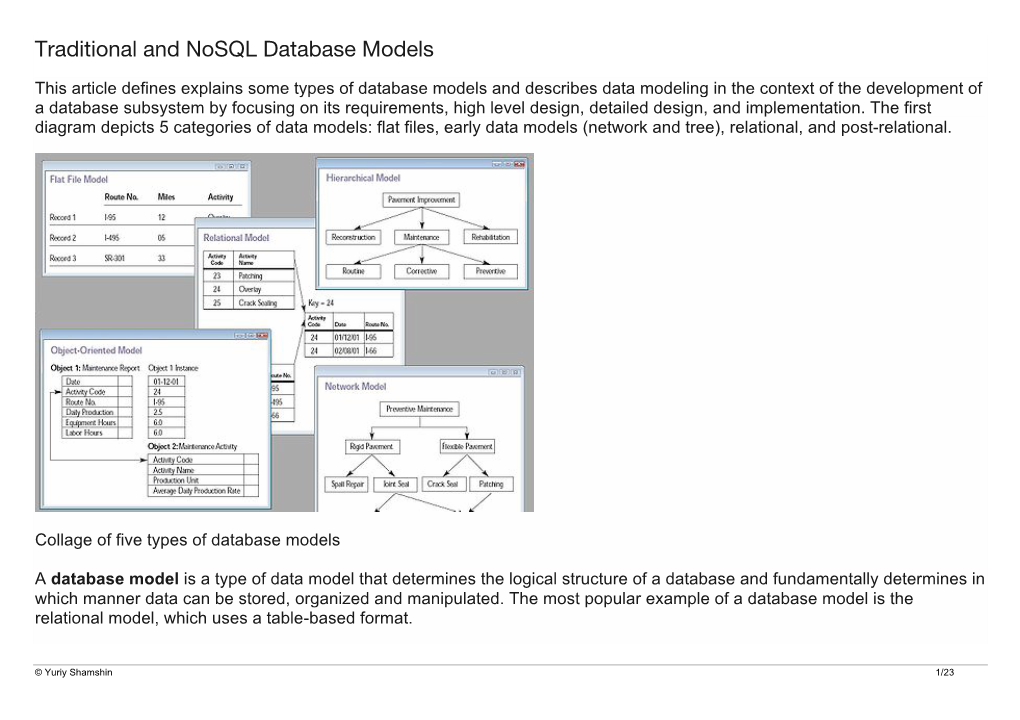
Traditional and Nosql Database Models
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The World Is Not Flat and Neither Is Your Business. So Why Should Your Data Be?
A R EVELATION W HITE P APER The world is not flat and neither is your business. So why should your data be? Revelation Software’s Post Relational, Multi-Dimensional Database Environment. Contents CONTENTS 3 INTRODUCTION 4 The Purpose of this White Paper 5 DISCUSSION 6 MultiValue – An evolution based on success 6 Revelation’s ARev and OpenInsight 7 Maintaining a competitive edge over RDBMS 8 Supporting Embedded DBMS ISVs 9 Optimising systems for a modern world 11 Market Stats 12 CONCLUSION 13 APPENDIX A 15 APPENDIX B 18 APPENDIX C 23 APPENDIX D 27 COPYRIGHT NOTICE © 2006 Revelation Software Limited. All rights reserved. No part of this publication may be reproduced by any means, be it transmitted, transcribed, photocopied, stored in a retrieval system, or translated into any language in any form, without the written permission of Revelation Software Limited. TRADEMARK NOTICE OpenInsight is a registered trademark of Revelation Technologies, Inc. Advanced Revelation is a registered trademark of Revelation Technologies, Inc. OpenInsight for Workgroups is a registered trademark of Revelation Technologies, Inc. Report Builder+ is a trademark of Revelation Technologies, Inc. Microsoft, MS, MS-DOS and Windows are registered trademarks of Microsoft Corporation in the USA and other countries. IBM, U2, UniData and the IBM e-business logo are registered trademarks of International Business Machines Corporation. Intel is a registered trademark of Intel Corporation. Lotus, Lotus Notes and Notes are registered trademarks of Lotus Development Corporation. All other product names are trademarks or registered trademarks of their respective owners. Introduction The world is not flat and neither is your business. -

Featuring the Multivalue Database Players Featuring the Multivalue Database Players
INSIDE! UNLOCK THE POWER OF YOUR MULTIVALUE DATABASE $7.00 U.S. INTERNATIONAL ® SPECTRUMSPECTRUMTHE BUSINESS COMPUTER MAGAZINE MAY/JUNE 2002 • AN IDBMA, INC. PUBLICATION IndependentIndependent Databa se Revie Featur Appearing! ing Featuring the M Database Review ult PLAYERS iV DatabaseDATABASE a DatabaseMULTIVALUE l Now Appearing! Review of the tabases MV Da IndustryIndustry yers base Pla eData ReviewReviewFeaturing the MultiValue Database Players Come in from the rain Featuring the UniVision MultiValue database - compatible with existing applications running on Pick AP, D3, R83, General Automation, Mentor, mvBase and Ultimate. We’re off to see the WebWizard Starring a “host” centric web integration solution. Watch WebWizard create sophisticated web-based applications from your existing computing environment. Why a duck? Featuring ViaDuct 2000, the world’s easiest-to-use terminal emulation and connectivity software, designed to integrate your host data and applications with your Windows desktop. Caught in the middle? With an all-star cast from the WinLink32 product family (ViaOD- BC, ViaAPI for Visual Basic, ViaObjects, and mvControls), Via Sys- tems’ middleware solutions will entertain (and enrich!) you. Appearing soon on a screen near you. Advanced previews available from Via Systems. Via Systems Inc. 660 Southpointe Court, Suite 300 Colorado Springs, Colorado 80906 Phone: 888 TEAMVIA Fax: 719-576-7246 e-mail: [email protected] On the web: www.via.com The Freedom To Soar. With jBASE – the remarkably liberating multidimensional database – there are no limits to where you can go. Your world class applications can now run on your choice of database: jBASE, Oracle, SQL Server or DB2 without modification and can easily share data with other applications using those databases. -

Rocket D3 Database Management System
datasheet Rocket® D3 Database Management System Delivering Proven Multidimensional Technology to the Evolving Enterprise Ecient Performance: C#, and C++. In addition, Java developers can access Delivers high performance via Proven Technology the D3 data files using its Java API. The MVS Toolkit ecient le management For over 30 years, the Pick Universal Data Model (Pick provides access to data and business processes via that requires minimal system UDM) has been synonymous with performance and and memory resources both SOAP and RESTful Web Services. reliability; providing the flexible multidimensional Scalability and Flexibility: database infrastructure to develop critical transac- Scales with your enterprise, tional and analytical business applications. Based on from one to thousands of Why Developers the Pick UDM, the Rocket® D3 Database Manage- users ment System offers enterprise-level scalability and Choose D3 D3 is the choice of more than a thousand applica- Seamless Interoperability: efficiency to support the dynamic growth of any tion developers world-wide—serving top industries Interoperates with varied organization. databases and host including manufacturing, distribution, healthcare, environments through government, retail, and other vertical markets. connectivity tools Rapid application development and application Rocket D3 database-centric development environ- customization requires an underlying data structure Data Security: ment provides software developers with all the that can respond effectively to ever-changing Provides secure, simultaneous necessary tools to quickly adapt to changes and access to the database from business requirements. Rocket D3 is simplistic in its build critical business applications in a fraction of the remote or disparate locations structure, yet allows for complex definitions of data time as compared to other databases; without worldwide structures and program logic. -

Database Software Market: Billy Fitzsimmons +1 312 364 5112
Equity Research Technology, Media, & Communications | Enterprise and Cloud Infrastructure March 22, 2019 Industry Report Jason Ader +1 617 235 7519 [email protected] Database Software Market: Billy Fitzsimmons +1 312 364 5112 The Long-Awaited Shake-up [email protected] Naji +1 212 245 6508 [email protected] Please refer to important disclosures on pages 70 and 71. Analyst certification is on page 70. William Blair or an affiliate does and seeks to do business with companies covered in its research reports. As a result, investors should be aware that the firm may have a conflict of interest that could affect the objectivity of this report. This report is not intended to provide personal investment advice. The opinions and recommendations here- in do not take into account individual client circumstances, objectives, or needs and are not intended as recommen- dations of particular securities, financial instruments, or strategies to particular clients. The recipient of this report must make its own independent decisions regarding any securities or financial instruments mentioned herein. William Blair Contents Key Findings ......................................................................................................................3 Introduction .......................................................................................................................5 Database Market History ...................................................................................................7 Market Definitions -

A Brief History of the Pick Environment in Australia Stasys Lukaitis
A Brief History of the Pick Environment in Australia Stasys Lukaitis To cite this version: Stasys Lukaitis. A Brief History of the Pick Environment in Australia. IFIP WG 9.7 International Conference on History of Computing (HC) / Held as Part of World Computer Congress (WCC), Sep 2010, Brisbane, Australia. pp.146-158, 10.1007/978-3-642-15199-6_15. hal-01054657 HAL Id: hal-01054657 https://hal.inria.fr/hal-01054657 Submitted on 7 Aug 2014 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Distributed under a Creative Commons Attribution| 4.0 International License A Brief History of the Pick Environment in Australia Stasys Lukaitis School of Business Information Technology RMIT Melbourne Australia [email protected] Abstract. Mainstream Information Technology professionals have misunderstood the Pick environment for many years. The Pick environment has been conceived, designed and built with business solutions as its key driver. At its heyday there were over 3,000 business applications available across a very wide range of hardware platforms supporting from 1 to thousands of real time users. The tentative economic recovery of the 90’s and the Y2K fears created cautious and conservative corporate decision-making. -

Writing Your First U2 Application
Writing your first Rocket U2 Application Brian Leach Writing Your First UniVerse or UniData Application Brian Leach About this Book The book is available in published form or as a free download in PDF format from Brian Leach (www.brianleach.co.uk). You may distribute it freely. About the Author Brian Leach is an independent U2 and MultiValue consultant based in the UK. Brian has worked with UniVerse since 1989 and has designed some of the most advanced development and reporting tools in the U2 market. Brian is a past President of the International U2 User Group, of which he was a founder board member. You can contact the author at www.brianleach.co.uk. Table of Contents About this Book ....................................................................................................................... 4 About the Author ............................................................................................................. 4 Acknowledgements .......................................................................................................... 8 Thank You ......................................................................................................................... 8 Introduction ............................................................................................................................. 9 UniVerse or UniData?..................................................................................................... 10 What we will cover ........................................................................................................ -

Caché Technology Guide
Caché Tech nolo gy Guide Table of Contents Chapter One Introduction 1 4 Data ModRellaitniogn a–l TReechlanotliogny al or Object Access 5 Object Technology and Object Databases 6 Object vs. Relational Access 6 Overview of the Caché Object Data Model and Object Programming 6 Key Object Concepts 8 Why Choose Objects for Your Data Model? 8 Object Data Storage ... Plus Relational Access 9 Chapter Two Not Only SQL 9 10 Caché’s MInutelgtriadteimd Deantasbiaosne aAlc cDesas ta Server 10 Multidimensional Data Model 11 SQL Access 14 Caché Objects 16 Transactional Bit-Map Indexing 18 Word-Aware Text Searching 19 InterSystems iKnow Technology 20 Enterprise Cache Protocol for Distributed Systems 22 Disaster Recovery and High Availability 25 Chapter Three Security Model 27 30 Caché’s ATphep Cliaccahéti Voinrt uSael Mrvaechr ine and Scripting Languages 30 Caché ObjectScript 32 Basic 38 MV Basic 40 C++ 40 Java 40 Caché eXTreme for Java 41 Caché and .NET 42 Caché and XML 43 Caché and Web Services 44 Caché and MultiValue 46 Chapter Four Migrating Applications to Caché 47 48 Building CRSiPc The cWhneoblo gAy pplications Fast with InterSystems Zen Technology 48 Class Architecture of Web Pages 49 Zen and Component-Based Web Pages 50 The computing world has entered the "post-relational" era Introduction Thirty years ago, relational databases were hailed as a great innovation. Instead of monolithic legacy databases, each with its unique data schema, data would be stored in a tabular format, and be accessi - ble to anyone who knew SQL. Relational databases were highly successful, and SQL became a common standard for database access. -

Comparative Study O. Relational Database Model and Multivalue Database Model
International Journal of Information Technology and Knowledge Management July-December 2008, Volume 1, No. 2, pp. 469-474 COMPARATIVE STUDY O RELATIONAL DATABASE MODEL AND MULTIVALUE DATABASE MODEL MEGHNA SHARMA & RUCHI SEHRAWAT ABSTRACT In the current business processing management operations, most of the companies and organizations use Relational (SQL) databases tools which are prevalent, owing to the IT marketplace being dominated by the big companies like IBM, Oracle, Microsoft as well as some companies which give open solutions for database management through relational data model but one more technology coming up these days at large scale, use the concept of Multivalue database which in many ways is considered more efficient by the supporters of this concept. We have done the comparative study of these two types of models ,one is relational database and other is Multivalue database. Keywords: Cache, Logical Data Model, Multivalue Database, Relational Database. 1. INTRODUCTION Multivalue database is not a new concept. It was started in mid 1960s by first designing a model and then its implementation. It is an efficient and flexible database technology which when compared to relational (SQL) database has some features, which makes it useful for many applications. Unlike Relational Database Management System, in Multivalue database, we can have repeating values in a single record/row (item in Multivalue) and each value can have multiple sub-values. Each attribute, value and sub-value is dynamic in length All records are of variable-length, and field and values are marked off by special delimiters, so that any file, record, or field may contain any number of entries of the lower level of entity. -

The Impact of the Y2K Event on the Popularity of the Pick Database Environment
The Impact of the Y2K Event on the Popularity of the Pick Database Environment Stasys Lukaitis School of Business Information Technology RMIT Melbourne Australia [email protected] Abstract. At Pick’s heyday there were over 3,000 business applications available across a very wide range of hardware platforms supporting from one to thousands of real time users. The tentative economic recovery of the 90s and the Y2K fears created cautious and conservative corporate decision-making. During those tumultuous years there were startling leaps in information and communications technology rewarding those who invested in the future and in themselves. The Pick community at the time were fragmented and somewhat narrow-minded in their view of the future and were unable to collectively invest in developing new technologies. Intense marketing by ‘mainstream’ relational database vendors combined with ERP software vendors brought executive peer group pressure to adopt ‘vanilla’ relational technologies and the desire for homogeneity and perceived immunity from the impending Y2K event. A new corporate jargon was developed to further seduce executive corporate decision makers. Keywords: Pick; Universe; Unidata; Prime; Revelation; jBase; Reality; Multivalue; Correlative; D3; SAP; Oracle. 1. Introduction Decision making in ICT is rarely on the basis of cold hard logic or actual facts, but more often based on prejudice, comfort and expediency. Lots of decisions are sometimes made in the absence of, or despite important information. This paper seeks to highlight an interesting historical period in the development of Information and Communications Technology in Australia and to notice the various influences of (then) emerging factors on the Information Systems that were in use at that time, and the Pick Operating Systems and Database environment as an interesting example. -

An Introduction of Nosql Databases Based on Their Categories And
algorithms Article An Introduction of NoSQL Databases Based on Their y Categories and Application Industries Jeang-Kuo Chen * and Wei-Zhe Lee Department of Information Management, Chaoyang University of Technology, Taichung 41349, Taiwan; [email protected] * Correspondence: [email protected] This Paper is an Extended Version of the Conference Paper (ID: 1070) in Taichung, Taiwan, y 6–8 December 2018, IS3C2018. Received: 31 January 2019; Accepted: 9 May 2019; Published: 16 May 2019 Abstract: The popularization of big data makes the enterprise need to store more and more data. The data in the enterprise’s database must be accessed as fast as possible, but the Relational Database (RDB) has the speed limitation due to the join operation. Many enterprises have changed to use a NoSQL database, which can meet the requirement of fast data access. However, there are more than hundreds of NoSQL databases. It is important to select a suitable NoSQL database for a certain enterprise because this decision will affect the performance of the enterprise operations. In this paper, fifteen categories of NoSQL databases will be introduced to find out the characteristics of every category. Some principles and examples are proposed to choose an appropriate NoSQL database for different industries. Keywords: big data; NoSQL database; RDB; HBase; MongoDB; Neo4j 1. Introduction The Relational Database (RDB) was developed from the 1970s to present. Through a powerful Relational Database Management System (RDBMS), RDB is easy to use and maintain, and becomes a widely used kind of database [1]. Due to the popularization of big data acquisition technologies and applications, enterprises need to store more data than ever before. -

Nested Relational Databases
WHITE PAPER Nested Relational Databases ® Contents 1 Table of Contents 2 Introduction 2 Abstract 3 Basic Relational Database Technology 4 Normalization of Relational Databases 7 Relationship Relations 8 Limits of 1NF Relational Databases 9 Eliminating the 1NF Constraint 9 Nested Relational Databases 10 Nested Tables 12 Implicit Relationship Relations 13 Technical Advantages of Nested Relational Databases 14 Conversion of Databases 14 Mapping Hierarchical Data to Nested Relational Databases 15 Performance of Converted Legacy Systems 16 Appendix A: Questions and Answers 16 Nested Relational Databases and the Industry 16 Nested Relational Database Technology 17 Nested Relational Database Compatibility 18 Bibliographical References 2 Nested Relational Databases Introduction Abstract This paper discusses technical advantages represented by nested relational database technology. We focus on the removal of the requirement that relational databases conform to the first normal form (atomic attributes). Nested relational databases are technically called non-first-normal-form (NF2) databases, but are commonly referred to as MultiValue or extended relational databases. We explain the difference between traditional relational databases, such as Oracle, MySQL and SQL Server to the Rocket MultiValue databases (principally the ability to nest tables and store complex data structures). Next, we outline the implications of this technology for the user of relational databases. We conclude by answering questions that are frequently asked about nested relational databases. An extensive bibliography of published material concerning nested relational databases is provided. 3 Basic Relational Database Technology The well-known and widely-used relational database systems, including the Rocket MultiValue databases, Rocket UniData®, Rocket UniVerse™ and Rocket D3®, all conform to the basic relational model first proposed by Dr. -

Jbase the Native Application Platform for Multivalue
The “Native” Application Platform for MultiValue Attract New Developers and Bring your Applications into the Future with jBASE More than 25 years of innovation and determination has led to the evolution of a truly native database that is now 100% owned and supported by Zumasys. What is jBASE? jBASE is a world-class database management system comprised of development tools, middleware and a proven multi-dimensional database. jBASE takes the best points of a relational database model and adds several significant benefits including extreme scalability, superb performance, a small footprint and all of the rich features MultiValue developers require. With jBASE, your programs run natively on the underlying operating system. This allows you to easily cross train new hires and mainstream developers to bring your application into the future. This highly flexible platform gives you the freedom to design your applications around your business needs, not the capabilities of your database. The adaptable architecture means you no longer need a crew of DBAs or an army of consultants to implement and keep your database running. Now that jBASE is under the ownership of Zumasys, the leader in Cloud Computing for MultiValue systems, the technology has been optimized for multi-tenancy and made 100% compatible with leading virtualization platforms VMware vSphere, Microsoft Hyper-V, and IBM PowerVM. Under the Hood The jBASE architecture is uniquely designed to integrate with all application program interfaces (APIs) and backend databases, which means you can store your data in SQL, Oracle or DB2 while still fully utilizing your MultiValue programs. Enhanced versatility allows you to program in BASIC or C, providing your applications full access to the underlying operating system.