Exploring Data Placement in Racetrack Memory Based Scratchpad Memory
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Analyzing the Benefits of Scratchpad Memories for Scientific Matrix
The Pennsylvania State University The Graduate School Department of Computer Science and Engineering ANALYZING THE BENEFITS OF SCRATCHPAD MEMORIES FOR SCIENTIFIC MATRIX COMPUTATIONS A Thesis in Computer Science and Engineering by Bryan Alan Cover c 2008 Bryan Alan Cover Submitted in Partial Fulfillment of the Requirements for the Degree of Master of Science May 2008 The thesis of Bryan Alan Cover was reviewed and approved* by the following: Mary Jane Irwin Evan Pugh Professor of Computer Science and Engineering Thesis Co-Advisor Padma Raghavan Professor of Computer Science and Engineering Thesis Co-Advisor Raj Acharya Professor of Computer Science and Engineering Head of the Department of Computer Science and Engineering *Signatures are on file in the Graduate School. iii Abstract Scratchpad memories (SPMs) have been shown to be more energy efficient, have faster access times, and take up less area than traditional hardware-managed caches. This, coupled with the predictability of data presence and reduced thermal properties, makes SPMs an attractive alternative to cache for many scientific applications. In this work, SPM based systems are considered for a variety of different functions. The first study performed is to analyze SPMs for their thermal and area properties on a conven- tional RISC processor. Six performance optimized variants of architecture are explored that evaluate the impact of having an SPM in the on-chip memory hierarchy. Increasing the performance and energy efficiency of both dense and sparse matrix-vector multipli- cation on a chip multi-processor are also looked at. The efficient utilization of the SPM is ensured by profiling the application for the data structures which do not perform well in traditional cache. -

Universal Memory
BRIEFING No.4 ICT UNIVERSAL MEMORY Memory is an integral part of information processing devices and is needed for short‐term stor‐ age such as when computer programs are being executed or text documents are processed. Currently, three main types of memory exist: SRAM offers very high speed at a high cost, DRAM is average in terms of speed and cost, and Flash memory is a low cost, low speed solution for applications that need to retain the data even when power is disconnected. A group of emerg‐ ing memory devices called universal memory aim to combine all these features in a single de‐ vice.1 Developments in universal memory devices may eventually lead to the introduction of novel October 2010 October memory architectures that offer increased performance, enable smaller mobile devices, and offer novel features in traditional products such as cars or domestic appliances. Nanotechnol‐ ogy is an integral part of emerging memory research as it is becoming increasingly difficult to enhance the performance of current devices by scaling the technology further. It is unlikely that a single technology will emerge as the universal memory technology; however, the develop‐ ments in this sector will enhance the energy efficiency and performance of memory devices. Currently, the Integrated Circuit (IC) market is dominated by US and Asia based companies. Uni‐ versal memory and nanotechnology based solutions could provide an opportunity for Europe to gain ground in the sector. Background volatility. Its disadvantage compared to SRAM and DRAM is speed. None of the existing memory technologies provide all of the required properties. -

Memory Architectures 13 Preeti Ranjan Panda
Memory Architectures 13 Preeti Ranjan Panda Abstract In this chapter we discuss the topic of memory organization in embedded systems and Systems-on-Chips (SoCs). We start with the simplest hardware- based systems needing registers for storage and proceed to hardware/software codesigned systems with several standard structures such as Static Random- Access Memory (SRAM) and Dynamic Random-Access Memory (DRAM). In the process, we touch upon concepts such as caches and Scratchpad Memories (SPMs). In general, the emphasis is on concepts that are more generally found in SoCs and less on general-purpose computing systems, although this distinction is not very clearly defined with respect to the memory subsystem. We touch upon implementations of these ideas in modern research and commercial scenarios. In this chapter, we also point out issues arising in the context of the memory architectures that become exported as problems to be addressed by the compiler and system designer. Acronyms ALU Arithmetic-Logic Unit ARM Advanced Risc Machines CGRA Coarse Grained Reconfigurable Architecture CPU Central Processing Unit DMA Direct Memory Access DRAM Dynamic Random-Access Memory GPGPU General-Purpose computing on Graphics Processing Units GPU Graphics Processing Unit HDL Hardware Description Language PCM Phase Change Memory P.R. Panda () Department of Computer Science and Engineering, Indian Institute of Technology Delhi, New Delhi, India e-mail: [email protected] © Springer Science+Business Media Dordrecht 2017 411 S. Ha, J. Teich (eds.), Handbook of Hardware/Software Codesign, DOI 10.1007/978-94-017-7267-9_14 412 P.R. Panda SoC System-on-Chip SPM Scratchpad Memory SRAM Static Random-Access Memory STT-RAM Spin-Transfer Torque Random-Access Memory SWC Software Cache Contents 13.1 Motivating the Significance of Memory.................................... -

Nanotechnology Trends in Nonvolatile Memory Devices
IBM Research Nanotechnology Trends in Nonvolatile Memory Devices Gian-Luca Bona [email protected] IBM Research, Almaden Research Center © 2008 IBM Corporation IBM Research The Elusive Universal Memory © 2008 IBM Corporation IBM Research Incumbent Semiconductor Memories SRAM Cost NOR FLASH DRAM NAND FLASH Attributes for universal memories: –Highest performance –Lowest active and standby power –Unlimited Read/Write endurance –Non-Volatility –Compatible to existing technologies –Continuously scalable –Lowest cost per bit Performance © 2008 IBM Corporation IBM Research Incumbent Semiconductor Memories SRAM Cost NOR FLASH DRAM NAND FLASH m+1 SLm SLm-1 WLn-1 WLn WLn+1 A new class of universal storage device : – a fast solid-state, nonvolatile RAM – enables compact, robust storage systems with solid state reliability and significantly improved cost- performance Performance © 2008 IBM Corporation IBM Research Non-volatile, universal semiconductor memory SL m+1 SL m SL m-1 WL n-1 WL n WL n+1 Everyone is looking for a dense (cheap) crosspoint memory. It is relatively easy to identify materials that show bistable hysteretic behavior (easily distinguishable, stable on/off states). IBM © 2006 IBM Corporation IBM Research The Memory Landscape © 2008 IBM Corporation IBM Research IBM Research Histogram of Memory Papers Papers presented at Symposium on VLSI Technology and IEDM; Ref.: G. Burr et al., IBM Journal of R&D, Vol.52, No.4/5, July 2008 © 2008 IBM Corporation IBM Research IBM Research Emerging Memory Technologies Memory technology remains an -

Gpgpus: Overview Pedagogically Precursor Concepts UNIVERSITY of ILLINOIS at URBANA-CHAMPAIGN
GPGPUs: Overview Pedagogically precursor concepts UNIVERSITY OF ILLINOIS AT URBANA-CHAMPAIGN © 2018 L. V. Kale at the University of Illinois Urbana-Champaign Precursor Concepts: Pedagogical • Architectural elements that, at least pedagogically, are precursors to understanding GPGPUs • SIMD and vector units. • We have already seen those • Large scale “Hyperthreading” for latency tolerance • Scratchpad memories • High BandWidth memory L.V.Kale 2 Tera MTA, Sun UltraSPARC T1 (Niagara) • Tera computers, With Burton Smith as a co-founder (1987) • Precursor: HEP processor (Denelcor Inc.), 1982 • First machine Was MTA • MTA-1, MTA-2, MTA-3 • Basic idea: • Support a huge number of hardWare threads (128) • Each With its oWn registers • No Cache! • Switch among threads on every cycle, thus tolerating DRAM latency • These threads could be running different processes • Such processors are called “barrel processors” in literature • But they sWitched to the “next thread” alWays.. So your turn is 127 clocks aWay, always • Was especially good for highly irregular accesses L.V.Kale 3 Scratchpad memory • Caches are complex and can cause unpredictable impact on performance • Scratchpad memories are made from SRAM on chip • Separate part of the address space • As fast or faster than caches, because no tag-matching or associative search • Need explicit instructions to bring data into scratchpad from memory • Load/store instructions exist betWeen registers and scratchpad • Example: IBM/Toshiba/Sony cell processor used in PS/3 • 1 PPE, and 8 SPE cores • Each SPE core has 256 KiB scratchpad • DMA is mechanism for moving data betWeen scratchpad and external DRAM L.V.Kale 4 High BandWidth Memory • As you increase compute capacity of processor chips, the bandWidth to DRAM comes under pressure • Many past improvements (e.g. -

Hardware and Software Optimizations for GPU Resource Management
Hardware and Software Optimizations for GPU Resource Management A Thesis Submitted in Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy by Vishwesh Jatala to the DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING INDIAN INSTITUTE OF TECHNOLOGY KANPUR, INDIA December, 2018 ii Scanned by CamScanner Abstract Graphics Processing Units (GPUs) are widely adopted across various domains due to their massive thread level parallelism (TLP). The TLP that is present in the GPUs is limited by the number of resident threads, which in turn depends on the available resources in the GPUs { such as registers and scratchpad memory. Recent GPUs aim to improve the TLP, and consequently the throughput, by increasing the number of resources. Further, the improvements in semiconductor fabrication enable smaller feature sizes. However, for smaller feature sizes, the leakage power is a significant part of the total power consumption. In this thesis, we provide hardware and software solutions that aim towards the two problems of GPU design: improving throughput and reducing leakage energy. In the first work of the thesis, we focus on improving the performance of GPUs by effective resource management. In GPUs, resources (registers and scratchpad memory) are allocated at thread block level granularity, as a result, some of the resources may not be used up completely and hence will be wasted. We propose an approach that shares the resources of SM to utilize the wasted resources by launching more thread blocks in each SM. We show the effectiveness of our approach for two resources: registers and scratchpad memory (shared memory). On evaluating our approach experimentally with 19 kernels from several benchmark suites, we observed that kernels that underutilize register resource show an average improvement of 11% with register sharing. -

Improving Memory Subsystem Performance Using Viva: Virtual Vector Architecture
Improving Memory Subsystem Performance using ViVA: Virtual Vector Architecture Joseph Gebis12,Leonid Oliker12, John Shalf1, Samuel Williams12,Katherine Yelick12 1 CRD/NERSC, Lawrence Berkeley National Laboratory Berkeley, CA 94720 2 CS Division, University of California at Berkeley, Berkeley, CA 94720 fJGebis, LOliker, JShalf, SWWilliams, [email protected] Abstract. The disparity between microprocessor clock frequencies and memory latency is a primary reason why many demanding applications run well below peak achievable performance. Software controlled scratchpad memories, such as the Cell local store, attempt to ameliorate this discrepancy by enabling precise control over memory movement; however, scratchpad technology confronts the programmer and compiler with an unfamiliar and difficult programming model. In this work, we present the Virtual Vector Architecture (ViVA), which combines the memory semantics of vector computers with a software-controlled scratchpad memory in order to provide a more effective and practical approach to latency hiding. ViVA requires minimal changes to the core design and could thus be eas- ily integrated with conventional processor cores. To validate our approach, we implemented ViVA on the Mambo cycle-accurate full system simulator, which was carefully calibrated to match the performance on our underlying PowerPC Apple G5 architecture. Results show that ViVA is able to deliver significant per- formance benefits over scalar techniques for a variety of memory access pat- terns as well as two important memory-bound compact kernels, corner turn and sparse matrix-vector multiplication — achieving 2x–13x improvement compared the scalar version. Overall, our preliminary ViVA exploration points to a promis- ing approach for improving application performance on leading microprocessors with minimal design and complexity costs, in a power efficient manner. -
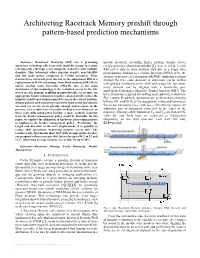
Architecting Racetrack Memory Preshift Through Pattern-Based Prediction Mechanisms
Architecting Racetrack Memory preshift through pattern-based prediction mechanisms Abstract— Racetrack Memories (RM) are a promising metalic racetrack, providing higher package density, lower spintronic technology able to provide multi-bit storage in a single energy and more robust data stability [5]. As seen in Fig. 1, each cell (tape-like) through a ferromagnetic nanowire with multiple RM cell is able to store multiple data bits in a single wire domains. This technology offers superior density, non-volatility programming domains to a certain direction (DWM) or by the and low static power compared to CMOS memories. These absence or presence of a skyrmion (SK-RM). Applying a current features have attracted great interest in the adoption of RM as a through the wire ends, domains or skyrmions can be shifted replacement of RAM technology, from Main memory (DRAM) to left/right at a constant velocity. With such a tape-like operation, maybe on-chip cache hierarchy (SRAM). One of the main every domain can be aligned with a read/write port, drawbacks of this technology is the serialized access to the bits implemented through a Magnetic Tunnel Junction (MTJ). The stored in each domain, resulting in unpredictable access time. An bit-cell structure required for shifting and read/write is shown in appropriate header management policy can potentially reduce the number of shift operations required to access the correct position. Fig. 1.down. Read/write operations are performed precharging Simple policies such as leaving read/write head on the last domain bitlines (BL and BLB) to the appropriate values and turning on accessed (or on the next) provide enough improvement in the the access transistors (TRW1 and TRW2). -

Racetrack Memory Based Logic Design for In‑Memory Computing
This document is downloaded from DR‑NTU (https://dr.ntu.edu.sg) Nanyang Technological University, Singapore. Racetrack memory based logic design for in‑memory computing Luo, Tao 2018 Luo, T. (2018). Racetrack memory based logic design for in‑memory computing. Doctoral thesis, Nanyang Technological University, Singapore. http://hdl.handle.net/10356/73359 https://doi.org/10.32657/10356/73359 Downloaded on 27 Sep 2021 05:57:42 SGT RACETRACK MEMORY BASED LOGIC DESIGN FOR IN-MEMORY COMPUTING School of Computer Science and Engineering A thesis submitted to the Nanyang Technological University in partial fulfilment of the requirement for the degree of Doctor of Philosophy LUO TAO August 2017 Abstract In-memory computing has been demonstrated to be an efficient computing in- frastructure in the big data era for many applications such as graph processing and encryption. The area and power overhead of CMOS technology based mem- ory design is growing rapidly because of the increasing data capacity and leak- age power along with the shrinking technology node. Thus, a newly introduced emerging memory technology, racetrack memory, is proposed to increase the data capacity and power efficiency of modern memory systems. As the design require- ments of the conventional logic are different from that of the emerging memory based logic for in-memory computing, the conventional well-developed CMOS technology based logic designs are less relevant to the emerging memory based in-memory computing. Therefore, novel logic designs for racetrack memory are required. Traditional logic design with separate chips is focusing on high speed, which causes large area and power consumption. -

Data in the Fast Lanes of Racetrack Memory
INFOTECH Data in the Fast Lanes of RACETRACK MEMORY A device that slides magnetic bits back and forth along nanowire “racetracks” could pack data in a three-dimensional microchip and may replace nearly all forms of conventional data storage By Stuart S. P. Parkin he world today is very different from that when the computer powers down—or crashes. of just a decade ago, thanks to our ability A few computers use nonvolatile chips, which T to readily access enormous quantities of retain data when the power is off, as a solid-state information. Tools that we take for granted— drive in place of an HDD. The now ubiquitous social networks, Internet search engines, online smart cell phones and other handheld devices maps with point-to-point directions, and online also use nonvolatile memory, but there is a trade- libraries of songs, movies, books and photo- off between cost and performance. The cheapest KEY CONCEPTS graphs—were unavailable just a few years ago. nonvolatile memory is a kind called flash memo- ■ A radical new design for We owe the arrival of this information age to the ry, which, among other uses, is the basis of the computer data storage rapid development of remarkable technologies little flash drives that some people have hanging called racetrack memory in high-speed communications, data processing from their key rings. Flash memory, however, is (RM) moves magnetic and—perhaps most important of all but least ap- slow and unreliable in comparison with other bits along nanoscopic preciated—digital data storage. memory chips. Each time the high-voltage pulse “racetracks.” Each type of data storage has its Achilles’ heel, (the “flash” of the name) writes a memory cell, ■ RM would be nonvola- however, which is why computers use several the cell is damaged; it becomes unusable after tile—retaining its data types for different purposes. -

A Dynamic Scratchpad Memory Unit for Predictable Real-Time Embedded Systems
A Dynamic Scratchpad Memory Unit for Predictable Real-Time Embedded Systems by Saud Wasly A thesis presented to the University of Waterloo in fulfillment of the thesis requirement for the degree of Master of Applied Science in Electrical and Computer Engineering Waterloo, Ontario, Canada, 2012 c Saud Wasly 2012 I hereby declare that I am the sole author of this thesis. This is a true copy of the thesis, including any required final revisions, as accepted by my examiners. I understand that my thesis may be made electronically available to the public. ii Abstract Scratch-pad memory is a popular alternative to caches in real-time embedded systems due to its advantages in terms of timing predictability and power consumption. However, dynamic management of scratch-pad content is challenging in multitasking environments. To address this issue, this thesis proposes the design of a novel Real-Time Scratchpad Memory Unit (RSMU). The RSMU can be integrated into existing systems with minimal architectural modifications. Furthermore, scratchpad management is performed at the OS level, requiring no application changes. In conjunction with a two-level scheduling scheme, the RSMU provides strong timing guarantees to critical tasks. Demonstration and evaluation of the system design is provided on an embedded FPGA platform. iii Acknowledgements My great gratitude is to Allah the only god, the Almighty who guided me in every step of this work with his infinite graciousness and bounties. I would like to thank all the kind people around me who made this possible, to only some of whom it is possible to give particular mention here. -

A Survey of Architectural Approaches for Managing Embedded DRAM and Non-Volatile On-Chip Caches Sparsh Mittal, Jeffrey S
A Survey Of Architectural Approaches for Managing Embedded DRAM and Non-volatile On-chip Caches Sparsh Mittal, Jeffrey S. Vetter, Dong Li To cite this version: Sparsh Mittal, Jeffrey S. Vetter, Dong Li. A Survey Of Architectural Approaches for Managing Embedded DRAM and Non-volatile On-chip Caches. IEEE Transactions on Parallel and Distributed Systems, Institute of Electrical and Electronics Engineers, 2015, pp.14. 10.1109/TPDS.2014.2324563. hal-01102387 HAL Id: hal-01102387 https://hal.archives-ouvertes.fr/hal-01102387 Submitted on 12 Jan 2015 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. This is the author's version of an article that has been published in this journal. Changes were made to this version by the publisher prior to publication. The final version of record is available at http://dx.doi.org/10.1109/TPDS.2014.2324563 IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTING SYSTEMS 1 A Survey Of Architectural Approaches for Managing Embedded DRAM and Non-volatile On-chip Caches Sparsh Mittal, Member, IEEE, Jeffrey S. Vetter, Senior Member, IEEE, and Dong Li Abstract—Recent trends of CMOS scaling and increasing number of on-chip cores have led to a large increase in the size of on- chip caches.