The Hiphop Virtual Machine
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-
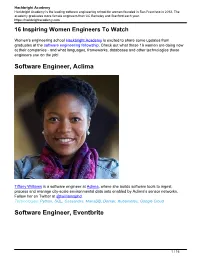
16 Inspiring Women Engineers to Watch
Hackbright Academy Hackbright Academy is the leading software engineering school for women founded in San Francisco in 2012. The academy graduates more female engineers than UC Berkeley and Stanford each year. https://hackbrightacademy.com 16 Inspiring Women Engineers To Watch Women's engineering school Hackbright Academy is excited to share some updates from graduates of the software engineering fellowship. Check out what these 16 women are doing now at their companies - and what languages, frameworks, databases and other technologies these engineers use on the job! Software Engineer, Aclima Tiffany Williams is a software engineer at Aclima, where she builds software tools to ingest, process and manage city-scale environmental data sets enabled by Aclima’s sensor networks. Follow her on Twitter at @twilliamsphd. Technologies: Python, SQL, Cassandra, MariaDB, Docker, Kubernetes, Google Cloud Software Engineer, Eventbrite 1 / 16 Hackbright Academy Hackbright Academy is the leading software engineering school for women founded in San Francisco in 2012. The academy graduates more female engineers than UC Berkeley and Stanford each year. https://hackbrightacademy.com Maggie Shine works on backend and frontend application development to make buying a ticket on Eventbrite a great experience. In 2014, she helped build a WiFi-enabled basal body temperature fertility tracking device at a hardware hackathon. Follow her on Twitter at @magksh. Technologies: Python, Django, Celery, MySQL, Redis, Backbone, Marionette, React, Sass User Experience Engineer, GoDaddy 2 / 16 Hackbright Academy Hackbright Academy is the leading software engineering school for women founded in San Francisco in 2012. The academy graduates more female engineers than UC Berkeley and Stanford each year. -

Memory Diagrams and Memory Debugging
CSCI-1200 Data Structures | Spring 2020 Lab 4 | Memory Diagrams and Memory Debugging Checkpoint 1 (focusing on Memory Diagrams) will be available at the start of Wednesday's lab. Checkpoints 2 and 3 focus on using a memory debugger. It is highly recommended that you thoroughly read the instructions for Checkpoint 2 and Checkpoint 3 before starting. Memory debuggers will be a useful tool in many of the assignments this semester, and in C++ development if you work with the language outside of this course. While a traditional debugger lets you step through your code and examine variables, a memory debugger instead reports memory-related errors during execution and can help find memory leaks after your program has terminated. The next time you see a \segmentation fault", or it works on your machine but not on Submitty, try running a memory debugger! Please download the following 4 files needed for this lab: http://www.cs.rpi.edu/academics/courses/spring20/csci1200/labs/04_memory_debugging/buggy_lab4. cpp http://www.cs.rpi.edu/academics/courses/spring20/csci1200/labs/04_memory_debugging/first.txt http://www.cs.rpi.edu/academics/courses/spring20/csci1200/labs/04_memory_debugging/middle. txt http://www.cs.rpi.edu/academics/courses/spring20/csci1200/labs/04_memory_debugging/last.txt Checkpoint 2 estimate: 20-40 minutes For Checkpoint 2 of this lab, we will revisit the final checkpoint of the first lab of this course; only this time, we will heavily rely on dynamic memory to find the average and smallest number for a set of data from an input file. You will use a memory debugging tool such as DrMemory or Valgrind to fix memory errors and leaks in buggy lab4.cpp. -

Automatic Detection of Uninitialized Variables
Automatic Detection of Uninitialized Variables Thi Viet Nga Nguyen, Fran¸cois Irigoin, Corinne Ancourt, and Fabien Coelho Ecole des Mines de Paris, 77305 Fontainebleau, France {nguyen,irigoin,ancourt,coelho}@cri.ensmp.fr Abstract. One of the most common programming errors is the use of a variable before its definition. This undefined value may produce incorrect results, memory violations, unpredictable behaviors and program failure. To detect this kind of error, two approaches can be used: compile-time analysis and run-time checking. However, compile-time analysis is far from perfect because of complicated data and control flows as well as arrays with non-linear, indirection subscripts, etc. On the other hand, dynamic checking, although supported by hardware and compiler tech- niques, is costly due to heavy code instrumentation while information available at compile-time is not taken into account. This paper presents a combination of an efficient compile-time analysis and a source code instrumentation for run-time checking. All kinds of variables are checked by PIPS, a Fortran research compiler for program analyses, transformation, parallelization and verification. Uninitialized array elements are detected by using imported array region, an efficient inter-procedural array data flow analysis. If exact array regions cannot be computed and compile-time information is not sufficient, array elements are initialized to a special value and their utilization is accompanied by a value test to assert the legality of the access. In comparison to the dynamic instrumentation, our method greatly reduces the number of variables to be initialized and to be checked. Code instrumentation is only needed for some array sections, not for the whole array. -

The LLVM Instruction Set and Compilation Strategy
The LLVM Instruction Set and Compilation Strategy Chris Lattner Vikram Adve University of Illinois at Urbana-Champaign lattner,vadve ¡ @cs.uiuc.edu Abstract This document introduces the LLVM compiler infrastructure and instruction set, a simple approach that enables sophisticated code transformations at link time, runtime, and in the field. It is a pragmatic approach to compilation, interfering with programmers and tools as little as possible, while still retaining extensive high-level information from source-level compilers for later stages of an application’s lifetime. We describe the LLVM instruction set, the design of the LLVM system, and some of its key components. 1 Introduction Modern programming languages and software practices aim to support more reliable, flexible, and powerful software applications, increase programmer productivity, and provide higher level semantic information to the compiler. Un- fortunately, traditional approaches to compilation either fail to extract sufficient performance from the program (by not using interprocedural analysis or profile information) or interfere with the build process substantially (by requiring build scripts to be modified for either profiling or interprocedural optimization). Furthermore, they do not support optimization either at runtime or after an application has been installed at an end-user’s site, when the most relevant information about actual usage patterns would be available. The LLVM Compilation Strategy is designed to enable effective multi-stage optimization (at compile-time, link-time, runtime, and offline) and more effective profile-driven optimization, and to do so without changes to the traditional build process or programmer intervention. LLVM (Low Level Virtual Machine) is a compilation strategy that uses a low-level virtual instruction set with rich type information as a common code representation for all phases of compilation. -

The Interplay of Compile-Time and Run-Time Options for Performance Prediction Luc Lesoil, Mathieu Acher, Xhevahire Tërnava, Arnaud Blouin, Jean-Marc Jézéquel
The Interplay of Compile-time and Run-time Options for Performance Prediction Luc Lesoil, Mathieu Acher, Xhevahire Tërnava, Arnaud Blouin, Jean-Marc Jézéquel To cite this version: Luc Lesoil, Mathieu Acher, Xhevahire Tërnava, Arnaud Blouin, Jean-Marc Jézéquel. The Interplay of Compile-time and Run-time Options for Performance Prediction. SPLC 2021 - 25th ACM Inter- national Systems and Software Product Line Conference - Volume A, Sep 2021, Leicester, United Kingdom. pp.1-12, 10.1145/3461001.3471149. hal-03286127 HAL Id: hal-03286127 https://hal.archives-ouvertes.fr/hal-03286127 Submitted on 15 Jul 2021 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. The Interplay of Compile-time and Run-time Options for Performance Prediction Luc Lesoil, Mathieu Acher, Xhevahire Tërnava, Arnaud Blouin, Jean-Marc Jézéquel Univ Rennes, INSA Rennes, CNRS, Inria, IRISA Rennes, France [email protected] ABSTRACT Both compile-time and run-time options can be configured to reach Many software projects are configurable through compile-time op- specific functional and performance goals. tions (e.g., using ./configure) and also through run-time options (e.g., Existing studies consider either compile-time or run-time op- command-line parameters, fed to the software at execution time). -

Clangjit: Enhancing C++ with Just-In-Time Compilation
ClangJIT: Enhancing C++ with Just-in-Time Compilation Hal Finkel David Poliakoff David F. Richards Lead, Compiler Technology and Lawrence Livermore National Lawrence Livermore National Programming Languages Laboratory Laboratory Leadership Computing Facility Livermore, CA, USA Livermore, CA, USA Argonne National Laboratory [email protected] [email protected] Lemont, IL, USA [email protected] ABSTRACT body of C++ code, but critically, defer the generation and optimiza- The C++ programming language is not only a keystone of the tion of template specializations until runtime using a relatively- high-performance-computing ecosystem but has proven to be a natural extension to the core C++ programming language. successful base for portable parallel-programming frameworks. As A significant design requirement for ClangJIT is that the runtime- is well known, C++ programmers use templates to specialize al- compilation process not explicitly access the file system - only gorithms, thus allowing the compiler to generate highly-efficient loading data from the running binary is permitted - which allows code for specific parameters, data structures, and so on. This capa- for deployment within environments where file-system access is bility has been limited to those specializations that can be identi- either unavailable or prohibitively expensive. In addition, this re- fied when the application is compiled, and in many critical cases, quirement maintains the redistributibility of the binaries using the compiling all potentially-relevant specializations is not practical. JIT-compilation features (i.e., they can run on systems where the ClangJIT provides a well-integrated C++ language extension allow- source code is unavailable). For example, on large HPC deploy- ing template-based specialization to occur during program execu- ments, especially on supercomputers with distributed file systems, tion. -

Memory Debugging
Center for Information Services and High Performance Computing (ZIH) Memory Debugging HRSK Practical on Debugging, 03.04.2009 Zellescher Weg 12 Willers-Bau A106 Tel. +49 351 - 463 - 31945 Matthias Lieber ([email protected]) Tobias Hilbrich ([email protected]) Content Introduction Tools – Valgrind – DUMA Demo Exercise Memory Debugging 2 Memory Debugging Segmentation faults sometimes happen far behind the incorrect code Memory debuggers help to find the real cause of memory bugs Detect memory management bugs – Access non-allocated memory – Access memory out off allocated bounds – Memory leaks – when pointers to allocated areas get lost forever – etc. Different approaches – Valgrind: Simulation of the program run in a virtual machine which accurately observes memory operations – Libraries like ElectricFence, DMalloc, and DUMA: Replace memory management functions through own versions Memory Debugging 3 Memory Debugging with Valgrind Valgrind detects: – Use of uninitialized memory – Access free’d memory – Access memory out off allocated bounds – Access inappropriate areas on the stack – Memory leaks – Mismatched use of malloc and free (C, Fortran), new and delete (C++) – Wrong use of memcpy() and related functions Available on Deimos via – module load valgrind Simply run program under Valgrind: – valgrind ./myprog More Information: http://www.valgrind.org Memory Debugging 4 Memory Debugging with Valgrind Memory Debugging 5 Memory Debugging with DUMA DUMA detects: – Access memory out off allocated bounds – Using a -

Magento on HHVM Speeding up Your Webshop with a Drop-In PHP Replacement
Magento on HHVM Speeding up your webshop with a drop-in PHP replacement. Daniel Sloof [email protected] What is HHVM? ● HipHop Virtual Machine ● Created by engineers at Facebook ● Essentially a reimplementation of PHP ● Originally translated PHP to C++, now translates PHP to bytecode ● Just-in-time compiler, turning generated bytecode into machine code ● In some cases 5 to 10 times faster than regular PHP So what’s the problem? ● HHVM not entirely compatible with PHP ● Magento’s PHP triggering many of these incompatibilities ● Choosing between ○ Forking Magento to work around HHVM ○ Fixing issues within the extensive HHVM C++ codebase Resulted in... fixing HHVM ● Already over 100 commits fixing Magento related HHVM bugs; ○ SimpleXML (majority of bugfixes) ○ sessions ○ number_format ○ __get and __set ○ many more... ● Most of these fixes already merged back into the official (github) repository ● Community Edition running (relatively) stable! Benchmarks Before we go to the results... ● Magento 1.8 with sample data ● Standard Apache2 / php-fpm / MySQL stack (with APC opcode cache). ● Standard HHVM configuration (repo-authoritative mode disabled, JIT enabled) ● Repo-authoritative mode has potential to increase performance by a large margin ● Tool of choice: siege Benchmarks: Response time Average across 50 requests Benchmarks: Transaction rate While increasing siege concurrency until avg. response time ~2 seconds What about <insert caching mechanism here>? ● HHVM does not get in the way ● Dynamic content still needs to be generated ● Replaces PHP - not Varnish, Redis, FPC, Block Cache, etc. ● As long as you are burning CPU cycles (always), you will benefit from HHVM ● Think about speeding up indexing, order placement, routing, etc. -

Design and Implementation of Generics for the .NET Common Language Runtime
Design and Implementation of Generics for the .NET Common Language Runtime Andrew Kennedy Don Syme Microsoft Research, Cambridge, U.K. fakeÒÒ¸d×ÝÑeg@ÑicÖÓ×ÓfغcÓÑ Abstract cally through an interface definition language, or IDL) that is nec- essary for language interoperation. The Microsoft .NET Common Language Runtime provides a This paper describes the design and implementation of support shared type system, intermediate language and dynamic execution for parametric polymorphism in the CLR. In its initial release, the environment for the implementation and inter-operation of multiple CLR has no support for polymorphism, an omission shared by the source languages. In this paper we extend it with direct support for JVM. Of course, it is always possible to “compile away” polymor- parametric polymorphism (also known as generics), describing the phism by translation, as has been demonstrated in a number of ex- design through examples written in an extended version of the C# tensions to Java [14, 4, 6, 13, 2, 16] that require no change to the programming language, and explaining aspects of implementation JVM, and in compilers for polymorphic languages that target the by reference to a prototype extension to the runtime. JVM or CLR (MLj [3], Haskell, Eiffel, Mercury). However, such Our design is very expressive, supporting parameterized types, systems inevitably suffer drawbacks of some kind, whether through polymorphic static, instance and virtual methods, “F-bounded” source language restrictions (disallowing primitive type instanti- type parameters, instantiation at pointer and value types, polymor- ations to enable a simple erasure-based translation, as in GJ and phic recursion, and exact run-time types. -

Report on Biodiversity and Tropical Forests in Indonesia
Report on Biodiversity and Tropical Forests in Indonesia Submitted in accordance with Foreign Assistance Act Sections 118/119 February 20, 2004 Prepared for USAID/Indonesia Jl. Medan Merdeka Selatan No. 3-5 Jakarta 10110 Indonesia Prepared by Steve Rhee, M.E.Sc. Darrell Kitchener, Ph.D. Tim Brown, Ph.D. Reed Merrill, M.Sc. Russ Dilts, Ph.D. Stacey Tighe, Ph.D. Table of Contents Table of Contents............................................................................................................................. i List of Tables .................................................................................................................................. v List of Figures............................................................................................................................... vii Acronyms....................................................................................................................................... ix Executive Summary.................................................................................................................... xvii 1. Introduction............................................................................................................................1- 1 2. Legislative and Institutional Structure Affecting Biological Resources...............................2 - 1 2.1 Government of Indonesia................................................................................................2 - 2 2.1.1 Legislative Basis for Protection and Management of Biodiversity and -

Automated Program Transformation for Improving Software Quality
Automated Program Transformation for Improving Software Quality Rijnard van Tonder CMU-ISR-19-101 October 2019 Institute for Software Research School of Computer Science Carnegie Mellon University Pittsburgh, PA 15213 Thesis Committee: Claire Le Goues, Chair Christian Kästner Jan Hoffmann Manuel Fähndrich, Facebook, Inc. Submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Software Engineering. Copyright 2019 Rijnard van Tonder This work is partially supported under National Science Foundation grant numbers CCF-1750116 and CCF-1563797, and a Facebook Testing and Verification research award. The views and conclusions contained in this document are those of the author and should not be interpreted as representing the official policies, either expressed or implied, of any sponsoring corporation, institution, the U.S. government, or any other entity. Keywords: syntax, transformation, parsers, rewriting, crash bucketing, fuzzing, bug triage, program transformation, automated bug fixing, automated program repair, separation logic, static analysis, program analysis Abstract Software bugs are not going away. Millions of dollars and thousands of developer-hours are spent finding bugs, debugging the root cause, writing a patch, and reviewing fixes. Automated techniques like static analysis and dynamic fuzz testing have a proven track record for cutting costs and improving software quality. More recently, advances in automated program repair have matured and see nascent adoption in industry. Despite the value of these approaches, automated techniques do not come for free: they must approximate, both theoretically and in the interest of practicality. For example, static analyzers suffer false positives, and automatically produced patches may be insufficiently precise to fix a bug. -

Overview of LLVM Architecture of LLVM
Overview of LLVM Architecture of LLVM Front-end: high-level programming language => LLVM IR Optimizer: optimize/analyze/secure the program in the IR form Back-end: LLVM IR => machine code Optimizer The optimizer’s job: analyze/optimize/secure programs. Optimizations are implemented as passes that traverse some portion of a program to either collect information or transform the program. A pass is an operation on a unit of IR code. Pass is an important concept in LLVM. LLVM IR - A low-level strongly-typed language-independent, SSA-based representation. - Tailored for static analyses and optimization purposes. Part 1 Part 1 has two kinds of passes: - Analysis pass (section 1): only analyze code statically - Transformation pass (section 2 & 3): insert code into the program Analysis pass (Section 1) Void foo (uint32_t int, uint32_t * p) { LLVM IR ... Clang opt } test.c test.bc stderr mypass.so Transformation pass (Section 2 & 3) mypass.so Void foo (uint32_t int, uint32_t * p) { ... LLVM IR opt LLVM IR } test.cpp Int main () { test.bc test-ins.bc ... Clang++ foo () ... LLVM IR } Clang++ main.cpp main.bc LLVM IR lib.cpp Executable lib.bc Section 1 Challenges: - How to traverse instructions in a function http://releases.llvm.org/3.9.1/docs/ProgrammersManual.html#iterating-over-the-instruction-in-a-function - How to print to stderr Section 2 & 3 Challenges: 1. How to traverse basic blocks in a function and instructions in a basic block 2. How to insert function calls to the runtime library a. Add the function signature to the symbol table of the module Section 2 & 3 Challenges: 1.