A Novel MOGA-SVM Multinomial Classification for Organ
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Print This Article
International Surgery Journal Lew D et al. Int Surg J. 2021 May;8(5):1575-1578 http://www.ijsurgery.com pISSN 2349-3305 | eISSN 2349-2902 DOI: https://dx.doi.org/10.18203/2349-2902.isj20211831 Case Report Acute gangrenous appendicitis and acute gangrenous cholecystitis in a pregnant patient, a difficult diagnosis: a case report David Lew, Jane Tian*, Martine A. Louis, Darshak Shah Department of Surgery, Flushing Hospital Medical Center, Flushing, New York, USA Received: 26 February 2021 Accepted: 02 April 2021 *Correspondence: Dr. Jane Tian, E-mail: [email protected] Copyright: © the author(s), publisher and licensee Medip Academy. This is an open-access article distributed under the terms of the Creative Commons Attribution Non-Commercial License, which permits unrestricted non-commercial use, distribution, and reproduction in any medium, provided the original work is properly cited. ABSTRACT Abdominal pain is a common complaint in pregnancy, especially given the physiological and anatomical changes that occur as the pregnancy progresses. The diagnosis and treatment of common surgical pathologies can therefore be difficult and limited by the special considerations for the fetus. While uncommon in the general population, concurrent or subsequent disease processes should be considered in the pregnant patient. We present the case of a 36 year old, 13 weeks pregnant female who presented with both acute appendicitis and acute cholecystitis. Keywords: Appendicitis, Cholecystitis, Pregnancy, Pregnant INTRODUCTION population is rare.5 Here we report a case of concurrent appendicitis and cholecystitis in a pregnant woman. General surgeons are often called to evaluate patients with abdominal pain. The differential diagnosis list must CASE REPORT be expanded in pregnant woman and the approach to diagnosing and treating certain diseases must also be A 36 year old, 13 weeks pregnant female (G2P1001) adjusted to prevent harm to the fetus. -

ACUTE Yellow Atrophy Ofthe Liver Is a Rare Disease; Ac
ACUTE YELLOW ATROPHY OF THE LIVER AS A SEQUELA TO APPENDECTOMY.' BY MAX BALLIN, M.D., OF DETROIT, MICHIGAN. ACUTE yellow atrophy of the liver is a rare disease; ac- cording to Osler about 250 cases are on record. This affection is also called Icterus gravis, Fatal icterus, Pernicious jaundice, Acute diffuse hepatitis, Hepatic insufficiency, etc. Acute yellow atrophy of the liver is characterized by a more or less sudden onset of icterus increasing to the severest form, headaches. insomnia, violent delirium, spasms, and coma. There are often cutaneous and mucous hiemorrhages. The temperature is usually high and irregular. The pulse, first normal, later rapid; urine contains bile pigments, albumen, casts, and products of incomplete metabolism of albumen, leucin, and tyrosin, the pres- ence of which is considered pathognomonic. The affection ends mostly fatally, but there are recoveries on record. The findings of the post-mortem are: liver reduced in size; cut surface mot- tled yellow, sometimes with red spots (red atrophy), the paren- chyma softened and friable; microscopically the liver shows biliary infiltration, cells in all stages of degeneration. Further, we find parenchymatous nephritis, large spleen, degeneration of muscles, haemorrhages in mucous and serous membranes. The etiology of this affection is not quite clear. We find the same changes in phosphorus poisoning; many believe it to be of toxic origin, but others consider it to be of an infectious nature; and we have even findings of specific germs (Klebs, Tomkins), of streptococci (Nepveu), staphylococci (Bourdil- lier), and also the Bacillus coli is found (Mintz) in the affected organs. The disease seems to occur always secondary to some other ailment, and is observed mostly during pregnancy (about one-third of all cases, hence the predominance in women), after Read before the Wayne County Medical Society, January 5, I903. -

Acute Pancreatitis Associated with Rotavirus Infection and Review Of
Case Report/Olgu Sunumu İstanbul Med J 2020; 21(1): 78-81 DO I: 10.4274/imj.galenos.2020.88319 Acute Pancreatitis Associated with Rotavirus Infection and Review of The Literature Rotavirüs Enfeksiyonuna Bağlı Akut Pankreatit Olguları ve Literatürün Gözden Geçirilmesi Kamil Şahin, Güzide Doğan University of Health Sciences, Haseki Training and Research Hospital, Department of Pediatrics, İstanbul, Turkey ABSTRACT ÖZ Agents causing acute gastroenteritis are not common causes of Çocuklarda pankreatit etiyolojisinde akut gastroenterit etkenleri pancreatitis etiology in children. Pancreatitis associated with sık görülen sebeplerden değildir. Rotavirüs enfeksiyonuna rotavirus infection is very rare. Cases with acute pancreatitis bağlı görülen pankreatit ise oldukça nadirdir. Rotavirüs during rotavirus gastroenteritis are reported due to rare gastroenteriti sırasında akut pankreatit gelişen olgular, associations. In this article, the causes of acute pancreatitis rotavirüs enfeksiyonuna bağlı akut pankreatitin nadir olması and cases of acute pancreatitis due to rotavirus infection were nedeniyle sunulmuştur. Bu yazıda, akut pankreatit sebepleri ve investigated. Clinical findings were mild, and complications rotavirüse bağlı gelişen akut pankreatit olguları incelenmiştir. were not observed in both of our patients, including a two- İki yaş kız ve üç yaşındaki erkek iki olgumuzda ve literatürde year-old female and a three-year-old male, and other cases değerlendirilen diğer olgularda klinik bulgular hafif seyretmiş, evaluated in the literature. The -

Treatment Recommendations for Feline Pancreatitis
Treatment recommendations for feline pancreatitis Background is recommended. Fentanyl transdermal patches have become Pancreatitis is an elusive disease in cats and consequently has popular for pain relief because they provide a longer duration of been underdiagnosed. This is owing to several factors. Cats with analgesia. It takes at least 6 hours to achieve adequate fentanyl pancreatitis present with vague signs of illness, including lethargy, levels for pain control; therefore, one recommended protocol is to decreased appetite, dehydration, and weight loss. Physical administer another analgesic, such as intravenous buprenorphine, examination and routine laboratory findings are nonspecific, and at the time the fentanyl patch is placed. The cat is then monitored until recently, there have been limited diagnostic tools available closely to see if additional pain medication is required. Cats with to the practitioner for noninvasively diagnosing pancreatitis. As a chronic pancreatitis may also benefit from pain management, and consequence of the difficulty in diagnosing the disease, therapy options for outpatient treatment include a fentanyl patch, sublingual options are not well understood. buprenorphine, oral butorphanol, or tramadol. Now available, the SNAP® fPL™ and Spec fPL® tests can help rule Antiemetic therapy in or rule out pancreatitis in cats presenting with nonspecific signs Vomiting, a hallmark of pancreatitis in dogs, may be absent or of illness. As our understanding of this disease improves, new intermittent in cats. When present, vomiting should be controlled; specific treatment modalities may emerge. For now, the focus is and if absent, treatment with an antiemetic should still be on managing cats with this disease, and we now have the tools considered to treat nausea. -
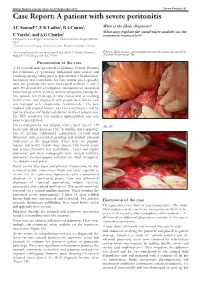
Case Report: a Patient with Severe Peritonitis
Malawi Medical Journal; 25(3): 86-87 September 2013 Severe Peritonitis 86 Case Report: A patient with severe peritonitis J C Samuel1*, E K Ludzu2, B A Cairns1, What is the likely diagnosis? 2 1 What may explain the small white nodules on the C Varela , and A G Charles transverse mesocolon? 1 Department of Surgery, University of North Carolina, Chapel Hill NC USA 2 Department of Surgery, Kamuzu Central Hospital, Lilongwe Malawi Corresponding author: [email protected] 4011 Burnett Womack Figure1. Intraoperative photograph showing the transverse mesolon Bldg CB 7228, Chapel Hill NC 27599 (1a) and the pancreas (1b). Presentation of the case A 42 year-old male presented to Kamuzu Central Hospital for evaluation of worsening abdominal pain, nausea and vomiting starting 3 days prior to presentation. On admission, his history was remarkable for four similar prior episodes over the previous five years that lasted between 3 and 5 days. He denied any constipation, obstipation or associated hematemesis, fevers, chills or urinary symptoms. During the first episode five years ago, he was evaluated at an outlying health centre and diagnosed with peptic ulcer disease and was managed with omeprazole intermittently . His past medical and surgical history was non contributory and he had no allergies and he denied alcohol intake or tobacco use. His HIV serostatus was negative approximately one year prior to presentation. On examination he was afebrile, with a heart rate of 120 (Fig 1B) beats/min, blood pressure 135/78 mmHg and respiratory rate of 22/min. Abdominal examination revealed mild distension with generalized guarding and marked rebound tenderness in the epigastrium. -

Case Report Perforated Acute Appendicitis Misdiagnosed As Colonic Perforation in Colon Cancer Patients After Colonoscopy: a Report of Two Cases and Literature Reviews
Int J Clin Exp Pathol 2017;10(6):7256-7260 www.ijcep.com /ISSN:1936-2625/IJCEP0050313 Case Report Perforated acute appendicitis misdiagnosed as colonic perforation in colon cancer patients after colonoscopy: a report of two cases and literature reviews Kaiyuan Zheng, Ji Wang, Wenhao Lv, Yongjia Yan, Zhicheng Zhao, Weidong Li, Weihua Fu Department of General Surgery, Tianjin Medical University General Hospital, Tianjin 300052, China Received January 23, 2017; Accepted May 9, 2017; Epub June 1, 2017; Published June 15, 2017 Abstract: Free gas in the abdominal cavity usually indicates that the perforation of the gastrointestinal tract from many factors including perforated ulcer, tumor perforation and severe infection, etc. But the pneumoperitoneum in perforated acute appendix secondary to the colonoscopy was rare relative. We reported two colon cancer patients with signs of abdominal free air after the operation of colonoscopy, considered the diagnosis of colon perforation at first, but eventually they were confirmed as perforated appendicitis. This report highlights that purulent perforated appendicitis should be considered especially for elderly patients with colon tumor presenting as signs of pneumo- peritoneum after the endoscopic operation. Keywords: Pneumoperitoneum, perforated appendicitis, colon cancer perforation, colonoscopy Introduction Acute perforated appendicitis is one of the common causes of acute abdomen and is Pneumoperitoneum is defined as free gas ap- needed emergency surgery. Its incidence was pears in the abdominal cavity, is usually caused higher in elderly population [6]. However, acute by the perforation of the alimentary tract sec- appendicitis following the operation of colonos- ondary to pathological or iatrogenic factors, but copy as a rare complication, with a consider- caused by purulent perforated appendix was ed incidence of 0.038%, and the appendix is rare relative. -

Research Article Nonalcoholic Fatty Liver Disease Aggravated the Severity of Acute Pancreatitis in Patients
Hindawi BioMed Research International Volume 2019, Article ID 9583790, 7 pages https://doi.org/10.1155/2019/9583790 Research Article Nonalcoholic Fatty Liver Disease Aggravated the Severity of Acute Pancreatitis in Patients Dacheng Wu,1 Min Zhang,1 Songxin Xu,1 Keyan Wu,1 Ningzhi Wang,1 Yuanzhi Wang,1 Jian Wu,1 Guotao Lu ,1 Weijuan Gong,1,2 Yanbing Ding ,1 and Weiming Xiao 1 Department of Gastroenterology, Affiliated Hospital of Yangzhou University, Yangzhou University, No. Hanjiang Media Road, Yangzhou ,Jiangsu,China Department of Immunology, School of Medicine, Yangzhou University, Yangzhou, China Correspondence should be addressed to Yanbing Ding; [email protected] and Weiming Xiao; [email protected] Received 17 October 2018; Accepted 3 January 2019; Published 22 January 2019 Guest Editor: Marina Berenguer Copyright © 2019 Dacheng Wu et al. Tis is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. Background and Aim. Te incidence of nonalcoholic fatty liver disease (NAFLD) as a metabolic disease is increasing annually. In the present study, we aimed to explore the infuence of NAFLD on the severity of acute pancreatitis (AP). Methods.Teseverity of AP was diagnosed and analyzed according to the 2012 revised Atlanta Classifcation. Outcome variables, including the severity of AP, organ failure (all types of organ failure), and systemic infammatory response syndrome (SIRS), were compared for patients with and without NAFLD. Results. Six hundred and ffy-six patients were enrolled in the study and were divided into two groups according to the presence or absence of NAFLD. -

Crohn's Disease Manifesting As Acute Appendicitis: Case Report and Review of the Literature
Case Report World Journal of Surgery and Surgical Research Published: 20 Jan, 2020 Crohn's Disease Manifesting as Acute Appendicitis: Case Report and Review of the Literature Terrazas-Espitia Francisco1*, Molina-Dávila David1, Pérez-Benítez Omar2, Espinosa-Dorado Rodrigo2 and Zárate-Osorno Alejandra3 1Division of Digestive Surgery, Hospital Español, Mexico 2Department of General Surgery Resident, Hospital Español, Mexico 3Department of Pathology, Hospital Español, Mexico Abstract Crohn’s Disease (CD) is one of the two clinical presentations of Inflammatory Bowel Disease (IBD) which involves the GI tract from the mouth to the anus, presenting a transmural pattern of inflammation. CD has been described as being a heterogenous disorder with multifactorial etiology. The diagnosis is based on anamnesis, physical examination, laboratory finding, imaging and endoscopic findings. There have been less than 200 cases of Crohn’s disease confined to the appendix since it was first described by Meyerding and Bertram in 1953. We present the case of a 24 year old male, who presented with acute onset, right lower quadrant pain, mimicking acute appendicitis with histopathological report of Crohn’s disease confined to the appendix. Introduction Crohn’s Disease (CD) is a chronic entity which clinical diagnosis represents one of the two main presentations of Inflammatory Bowel Disease (IBD), and it occurs throughout the gastrointestinal tract from the mouth to the anus, presenting a transmural pattern of inflammation of the gastrointestinal wall and non-caseating small granulomas. The exact origin of the disease remains OPEN ACCESS unknown, but it has been proposed as an interaction of genetic predisposition, environmental risk *Correspondence: factors and immune dysregulation of intestinal microbiota [1,2]. -

MANAGEMENT of ACUTE ABDOMINAL PAIN Patrick Mcgonagill, MD, FACS 4/7/21 DISCLOSURES
MANAGEMENT OF ACUTE ABDOMINAL PAIN Patrick McGonagill, MD, FACS 4/7/21 DISCLOSURES • I have no pertinent conflicts of interest to disclose OBJECTIVES • Define the pathophysiology of abdominal pain • Identify specific patterns of abdominal pain on history and physical examination that suggest common surgical problems • Explore indications for imaging and escalation of care ACKNOWLEDGEMENTS (1) HISTORICAL VIGNETTE (2) • “The general rule can be laid down that the majority of severe abdominal pains that ensue in patients who have been previously fairly well, and that last as long as six hours, are caused by conditions of surgical import.” ~Cope’s Early Diagnosis of the Acute Abdomen, 21st ed. BASIC PRINCIPLES OF THE DIAGNOSIS AND SURGICAL MANAGEMENT OF ABDOMINAL PAIN • Listen to your (and the patient’s) gut. A well honed “Spidey Sense” will get you far. • Management of intraabdominal surgical problems are time sensitive • Narcotics will not mask peritonitis • Urgent need for surgery often will depend on vitals and hemodynamics • If in doubt, reach out to your friendly neighborhood surgeon. Septic Pain Sepsis Death Shock PATHOPHYSIOLOGY OF ABDOMINAL PAIN VISCERAL PAIN • Severe distension or strong contraction of intraabdominal structure • Poorly localized • Typically occurs in the midline of the abdomen • Seems to follow an embryological pattern • Foregut – epigastrium • Midgut – periumbilical • Hindgut – suprapubic/pelvic/lower back PARIETAL/SOMATIC PAIN • Caused by direct stimulation/irritation of parietal peritoneum • Leads to localized -

Problems in Family Practice Acute Abdominal Pain in Children
dysuria. The older child may start bed wetting with or without dysuria. A problems in Family Practice drop of fresh, clean unspun urine will usually reveal pyuria, but in the early case relatively few white blood cells may be seen compared to gross bacillu- Acute Abdominal Pain ria. The infection may have underlying urinary tract abnormality, stone, in Children hydronephrosis, polycystic kidney or renal neoplasms. The IVP is important Hyman Shrand, M D in detecting these underlying prob lems. Cambridge, M assachusetts 4. Viral Hepatitis. Malaise, anorexia, abdominal pain, and tenderness over Acute abdominal pain in children is a common and challenging prob the liver occur with hepatitis A or B. lem for the family physician. The many causes of this problem require Later, patients who become jaundiced a systematic approach to making the diagnosis and planning specific have dark urine and pale stools. In therapy. A careful history and physical examination, together with a teenagers, “needle tracks” suggest sy ringe transmitted Type B (H.A.A.) small number of selected laboratory studies, provide a rational basis hepatitis. Youngsters with infectious for effective management in most cases. This paper reviews the more mononucleosis may present as hepati common causes of acute abdominal pain in children with special em tis. phasis on their clinical differentiation. 5. Upper Respiratory Tract. Strepto coccal pharyngitis, a common cause of Abdominal pain in a child is always followed by vomiting is more likely an vomiting and abdominal pain, can be an emergency. The primary physician intra-abdominal disorder. recognized by looking at the throat must identify a “medical” cause in or with confirmatory throat culture. -

Assessment of Small Bowel Obstruction in Patients Following Appendicitis: an Institutional Based Study
Original Research Article. Assessment of Small Bowel Obstruction in Patients Following Appendicitis: An Institutional Based Study Atahussain Poonawala1, Nilofer Poonawala2* 1Assistant Professor, Department of General Surgery, Vedantaa Institute of Medical Sciences, Palghar, Maharashtra, India. 2Assistant Professor, Department of Obstetrics and Gynaecology, Vedantaa Institute of Medical Sciences, Palghar, Maharashtra, India. ABSTRACT Background: Small bowel obstruction (SBO) is a pathological may be seen in few cases of appendectomy. condition which occurs when the intestinal contents are prevented from moving along the length of the intestine. The Key words: Appendectomy, Phlegmonous, Small Bowel present study was conducted to assess the cases of small Obstruction. bowel obstruction following appendectomy. *Correspondence to: Materials & Methods: The present study was conducted on Dr. Nilofer Poonawala, 42 cases of appendicitis of both genders. In all patients, Assistant Professor, laparoscopic appendectomy was planned. Patients were Department of Obstetrics and Gynaecology, recalled to note any kind of complication arising from the Vedantaa Institute of Medical Sciences, procedure. Palghar, Maharashtra, India. Results: Out of 42 patients, males were 26 and females were Article History: 16. Age group 20-30 years had 5 males and 3 females, 30-40 Received: 28-11-2019, Revised: 25-12-2019, Accepted: 21-01-2020 years had 9 males and 5 females and 40-50 years had 12 Access this article online males and 8 females. The difference was significant (P< 0.05). Website: Quick Response code Macroscopic feature of appendix during procedure was www.ijmrp.com phlegmonous in 12 and gangrenous in 30 cases. The DOI: difference was significant (P< 0.05). 10.21276/ijmrp.2020.6.1.016 Conclusion: Small bowel obstruction is a complication which INTRODUCTION Appendectomy is one of the most common procedures performed Intestinal obstruction is most commonly caused by intra- which may be due to appendicitis or frequent pain in appendix. -

Mid-Epigastric Pain: the Pancreas
Epigastric Pain: the Pancreas Howard J. Sachs, MD www.12DaysinMarch.com Epigastric Pain Epigastric Pain Gastro-duodenal Pancreas Honorable Mention: Hepatobiliary Vascular Esophageal Epigastric Pain Gastro-duodenal Pancreas Gastritis Pancreatitis, acute Ulcer Pancreatitis, chronic Neoplasm Neoplasm (adenocarcinoma, neuroendocrine) Epigastric Pain Gastro-duodenal Pancreas Gastritis Pancreatitis, acute Ulcer Pancreatitis, chronic Neoplasm Neoplasm (adenocarcinoma, neuroendocrine) What are the modifiers? • Demographics/Risk Factors • Clinical Presentation/Diagnostic Features • Complications/Paraneoplastic syndromes • Pathology Epigastric Pain: Demographics/Risk Factors Gastro-duodenal Pancreas Gastritis Pancreatitis, acute Ulcer Pancreatitis, chronic Neoplasm Neoplasm (adenocarcinoma, neuroendocrine) NSAIDs H. pylori Epigastric Pain: Demographics/Risk Factors Pancreas Pancreatitis, acute Pancreatitis, chronic Neoplasm AdenoCa Etoh, Stone, Neuroendocrine Hypertriglyceridemia Epigastric Pain: Demographics/Risk Factors Pancreas Pancreatitis, acute Pancreatitis, chronic Neoplasm AdenoCa Etoh, Stone, Neuroendocrine Hypertriglyceridemia Etoh: AST:ALT ratio (2:1); MCV ; GGTP Epigastric Pain: Demographics/Risk Factors Pancreas Pancreatitis, acute Pancreatitis, chronic Neoplasm AdenoCa Etoh, Stone, Neuroendocrine Hypertriglyceridemia Etoh: AST:ALT ratio (2:1); MCV ; GGTP Stone: symptoms after fatty meal Epigastric Pain: Demographics/Risk Factors Pancreas Pancreatitis, acute Pancreatitis, chronic Neoplasm AdenoCa Etoh, Stone, Neuroendocrine Hypertriglyceridemia