Codegear™ Rad Studio 2007
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

SIMD Vectorization
How to Write Fast Numerical Code Spring 2015 Lecture: SIMD extensions, SSE, compiler vectorization Instructor: Markus Püschel TA: Gagandeep Singh, Daniele Spampinato, Alen Stojanov Planning Currently: work on project (submit update 2.4.) No class on Sechseläuten (13.4.) Exam 15.4. First one-on-one meetings: late April 2 © Markus Püschel How to write fast numerical code Computer Science Spring 2015 Flynn’s Taxonomy Single instruction Multiple instruction Single data SISD MISD Uniprocessor Multiple data SIMD MIMD Vector computer Multiprocessors Short vector extensions VLIW 3 SIMD Extensions and SSE Overview: SSE family SSE intrinsics Compiler vectorization This lecture and material was created together with Franz Franchetti (ECE, Carnegie Mellon) 4 © Markus Püschel How to write fast numerical code Computer Science Spring 2015 SIMD Vector Extensions + x 4-way What is it? . Extension of the ISA . Data types and instructions for the parallel computation on short (length 2, 4, 8, …) vectors of integers or floats . Names: MMX, SSE, SSE2, … Why do they exist? . Useful: Many applications have the necessary fine-grain parallelism Then: speedup by a factor close to vector length . Doable: Relative easy to design; chip designers have enough transistors to play with 5 © Markus Püschel MMX: Computer Science Multimedia extension SSE: Intel x86 Processors Streaming SIMD extension x86-16 8086 AVX: Advanced vector extensions 286 x86-32 386 register 486 width Pentium MMX Pentium MMX 64 bit (only int) SSE Pentium III time SSE2 Pentium 4 SSE3 Pentium -

Floating Point Peak Performance? © Markus Püschel Computer Science Floating Point Peak Performance?
How to Write Fast Numerical Code Spring 2012 Lecture 3 Instructor: Markus Püschel TA: Georg Ofenbeck © Markus Püschel Computer Science Technicalities Research project: Let me know . if you know with whom you will work . if you have already a project idea . current status: on the web . Deadline: March 7th Finding partner: [email protected] . Recipients: TA Georg + all students that have no partner yet Email for questions: [email protected] . use for all technical questions . received by me and the TAs = ensures timely answer © Markus Püschel Computer Science Last Time Asymptotic analysis versus cost analysis /* Multiply n x n matrices a and b */ void mmm(double *a, double *b, double *c, int n) { int i, j, k; for (i = 0; i < n; i++) for (j = 0; j < n; j++) for (k = 0; k < n; k++) c[i*n+j] += a[i*n + k]*b[k*n + j]; } Asymptotic runtime: O(n3) Cost: (adds, mults) = (n3, n3) Cost: flops = 2n3 Cost analysis enables performance plots © Markus Püschel Computer Science Today Architecture/Microarchitecture Crucial microarchitectural parameters Peak performance © Markus Püschel Computer Science Definitions Architecture: (also instruction set architecture = ISA) The parts of a processor design that one needs to understand to write assembly code. Examples: instruction set specification, registers Counterexamples: cache sizes and core frequency Example ISAs . x86 . ia . MIPS . POWER . SPARC . ARM © Markus Püschel MMX: Computer Science Multimedia extension SSE: Intel x86 Processors Streaming SIMD extension x86-16 8086 AVX: Advanced vector extensions 286 x86-32 386 486 Pentium MMX Pentium MMX SSE Pentium III time SSE2 Pentium 4 SSE3 Pentium 4E x86-64 / em64t Pentium 4F Core 2 Duo SSE4 Penryn Core i7 (Nehalem) AVX Sandybridge © Markus Püschel Computer Science ISA SIMD (Single Instruction Multiple Data) Vector Extensions What is it? . -

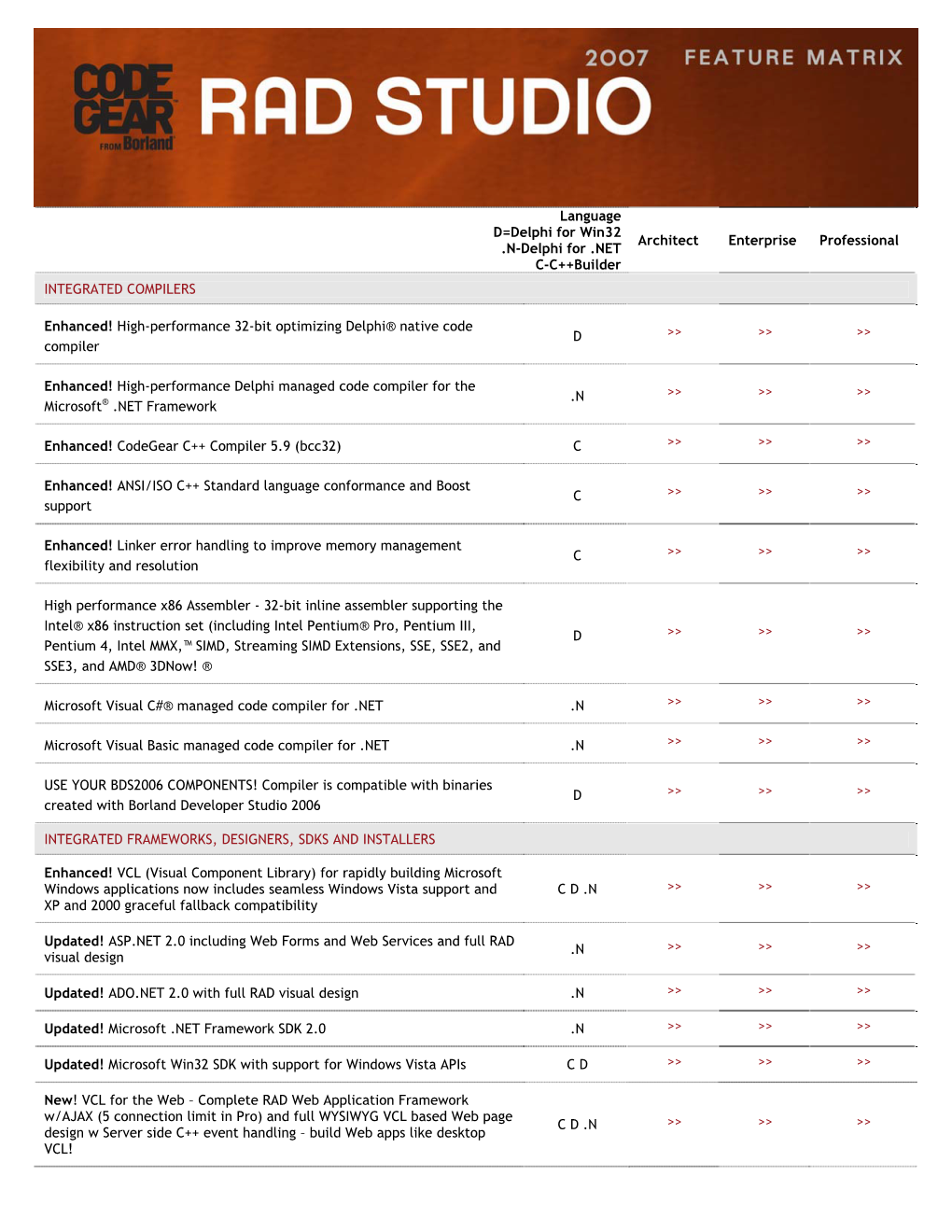
Delphi 2007 for Win32
Delphi 2007 for Win32 FEATURE MATRIX Ent Pro INTEGRATED COMPILERS ENHANCED! High-performance 32-bit optimizing Delphi® native code compiler 9 9 32-bit inline assembler with support for the full Intel® x86 instruction set (including Intel Pentium® Pro, Pentium III, Pentium 4, Intel MMX,™ SIMD, Streaming SIMD 9 9 Extensions, SSE, SSE2, and SSE3, and AMD® 3DNow! ® USE YOUR BDS2006 COMPONENTS! Compiler is compatible with binaries 9 9 created with Borland Developer Studio 2006 Ent Pro FRAMEWORKS, DESIGNERS, SDKS AND INSTALLERS VCL for rapidly building applications for Microsoft Win32® -- with full RAD Visual 9 9 design UPDATED! Microsoft Win32 SDK with support for Windows Vista 9 9 NEW! VCL for the Web - complete WYSIWYG RAD Web application development with AJAX using standalone executables, ISAPI for IIS, or DSO for 9 Apache, including SSL support NEW! VCL for the Web – application mode for standalone servers with maximum 9 of five connections ENHANCED! VCL forms designer 9 9 Together® powered Unified Modeling Language™ (UML®) designer 9 9 NEW! InstallAware installer technology allows for on the fly updating. IDE can 9 9 automatically check for updates Ent Pro LANGUAGE AND RUNTIME LIBRARY FEATURES “for in” loop iteration, Function in-lining for increased application performance, Delphi multi-unit namespaces, Operator overloading, Class variables/class static 9 9 data, Nested types, Records with methods (value types) Expression evaluation in compiler directives 9 9 Create reusable native 32-bit dynamically linked libraries (.DLL), COM controls -

Qualitycentral Reported Bugs Fixed in Delphi 2010
QC #: Date Reported: Area: 584 4/9/2002 IDE\Structure Pane Description: Steps: [QC Short Description] 1. Create a new application 2. Drop quite a few buttons etc. on the form and a PageControl. 3. Open the Object Strcuture View (formerly Object TreeView) doesn't automatically scroll when in Drag&Drop TreeView (Alt+Shift+F11) 4. Resize the Object TreeView window so that not all nodes are visible and the scrollbars appear 5. Now try to drag one of the buttons TreeNodes to the edges of the TreeView exp: TreeView [QC Description] should automatically scroll act: Nothing When designing complex forms the content of Structure View doesn't fit on the screen. If you then try to move components in the Structure TreeView by Drag&Drop you can't drop it onto a TreeView node which is currently not visible because the TreeView doesn't scroll when you're pointing your mouse near the edges of the TreeView. That way Object TreeView loses it's most important feature (IMO) ! QC Entry 584 QC #: Date Reported: Area: 739 4/12/2002 IDE\Code Editor\Keymapping Description: Steps: [QC Short Description] Tab key should indent block [QC Description] The tab key should indent a block of text when it is highlighted. This is the behaviour of most other IDEs and makes more sense than the current key combination. Shift+tab should unindent a block of text when it is highlighted. This suggestion costs nothing to implement, has no negatives, makes life easier for people changing from VB, is intuitive for new users, and makes it easier for everyone who has ever had to indent text. -

SIMD Vector Extensions
How to Write Fast Numerical Code Spring 2016 Lecture: SIMD extensions, SSE, compiler vectorization Instructor: Markus Püschel TA: Gagandeep Singh, Daniele Spampinato, Alen Stojanov Flynn’s Taxonomy Single instruction Multiple instruction Single data SISD MISD Uniprocessor Multiple data SIMD MIMD Vector computer Multiprocessors Short vector extensions VLIW 2 © Markus Püschel How to write fast numerical code Computer Science Spring 2016 SIMD Extensions and SSE Overview: SSE family SSE intrinsics Compiler vectorization This lecture and material was created together with Franz Franchetti (ECE, Carnegie Mellon) 3 SIMD Vector Extensions + x 4-way What is it? . Extension of the ISA . Data types and instructions for the parallel computation on short (length 2, 4, 8, …) vectors of integers or floats . Names: MMX, SSE, SSE2, … Why do they exist? . Useful: Many applications have the necessary fine-grain parallelism Then: speedup by a factor close to vector length . Doable: Relative easy to design; chip designers have enough transistors to play with 4 © Markus Püschel How to write fast numerical code Computer Science Spring 2016 © Markus Püschel MMX: Computer Science Multimedia extension SSE: Intel x86 Processors Streaming SIMD extension x86-16 8086 AVX: Advanced vector extensions 286 x86-32 386 register 486 width Pentium MMX Pentium MMX 64 bit (only int) SSE Pentium III time SSE2 Pentium 4 SSE3 Pentium 4E 128 bit x86-64 / em64t Pentium 4F Core 2 Duo SSE4 Penryn Core i7 (Nehalem) AVX Sandy Bridge 256 bit AVX2 Haswell SSE Family: Floating Point -

Intel Haswell Architecture and Microarchitecture, Memory
How to Write Fast Numerical Code Spring 2017 Lecture: Architecture/Microarchitecture and Intel Core Instructor: Markus Püschel TA: Alen Stojanov, Georg Ofenbeck, Gagandeep Singh Technicalities Class this Wednesday, no class this Thursday Midterm: Wed, April 26th (during recitation time) Research project: . Let us know once you have a partner . If you have a project idea, talk to me (break, after Wed class, email) . Deadline: March 6th Finding partner: [email protected] 2 © Markus Püschel How to write fast numerical code Computer Science Spring 2017 Today Architecture/Microarchitecture: What is the difference? In detail: Intel Haswell and Sandybridge Crucial microarchitectural parameters Peak performance Operational intensity 3 Definitions Architecture (also instruction set architecture = ISA): The parts of a processor design that one needs to understand to write assembly code Examples: instruction set specification, registers Some assembly code ipf: Counterexamples: cache sizes and core frequency xorps %xmm1, %xmm1 xorl %ecx, %ecx Example ISAs jmp .L8 .L10: . x86 movslq %ecx,%rax incl %ecx . ia movss (%rsi,%rax,4), %xmm0 mulss (%rdi,%rax,4), %xmm0 . MIPS addss %xmm0, %xmm1 . POWER .L8: cmpl %edx, %ecx . SPARC jl .L10 movaps %xmm1, %xmm0 . ARM ret 4 © Markus Püschel How to write fast numerical code Computer Science Spring 2017 MMX: Multimedia extension Intel x86 SSE: architectures Processors Streaming SIMD extension x86-16 8086 AVX: Advanced vector extensions 286 x86-32 386 486 Backward compatible: Pentium Old binary code (≥ 8086) MMX Pentium MMX runs on new processors. SSE Pentium III time New code to run on old SSE2 Pentium 4 processors? Depends on compiler flags. SSE3 Pentium 4E x86-64 / em64t Pentium 4F Core 2 Duo SSE4 Penryn Core i7 (Nehalem) AVX Sandy Bridge AVX2 Haswell 5 ISA SIMD (Single Instruction Multiple Data) Vector Extensions What is it? . -

Codegear™ Rad Studio 2007
Personality D=Delphi for Win32 Architect Enterprise Professional .N=Delphi for .NET C=C++Builder INTEGRATED COMPILERS Enhanced! High-performance 32-bit optimizing Delphi® native code D >> >> >> compiler Enhanced! High-performance Delphi managed code compiler for the .N >> >> >> Microsoft® .NET Framework Enhanced! CodeGear C++ Compiler 5.9 (bcc32) C >> >> >> Enhanced! ANSI/ISO C++ Standard language conformance and Boost C >> >> >> support Enhanced! Linker error handling to improve memory management C >> >> >> flexibility and resolution High performance x86 Assembler - 32-bit inline assembler supporting the Intel® x86 instruction set (including Intel Pentium® Pro, Pentium III, D >> >> >> Pentium 4, Intel MMX,™ SIMD, Streaming SIMD Extensions, SSE, SSE2, and SSE3, and AMD® 3DNow! ® Microsoft Visual C#® managed code compiler for .NET .N >> >> >> Microsoft Visual Basic managed code compiler for .NET .N >> >> >> USE YOUR BDS2006 COMPONENTS! Compiler is compatible with binaries D >> >> >> created with Borland Developer Studio 2006 INTEGRATED FRAMEWORKS, DESIGNERS, SDKS AND INSTALLERS Enhanced! VCL (Visual Component Library) for rapidly building Microsoft Windows applications now includes seamless Windows Vista support and C D .N >> >> >> XP and 2000 graceful fallback compatibility Updated! ASP.NET 2.0 including Web Forms and Web Services and full RAD .N >> >> >> visual design Updated! ADO.NET 2.0 with full RAD visual design .N >> >> >> Updated! Microsoft .NET Framework SDK 2.0 .N >> >> >> Updated! Microsoft Win32 SDK with support for Windows -

Intel Haswell Architecture/Microarchitecture
Advanced Systems Lab Spring 2020 Lecture: Architecture/Microarchitecture and Intel Core Instructor: Markus Püschel, Ce Zhang TA: Joao Rivera, Bojan Karlas, several more Organization Research project: Deadline March 6th Finding team: [email protected] 2 © Markus Püschel Advanced Systems Lab Computer Science Spring 2020 Today Architecture/Microarchitecture: What is the difference? In detail: Intel Haswell and Sandybridge Crucial microarchitectural parameters Peak performance Operational intensity 3 Definitions Architecture (also instruction set architecture = ISA): The parts of a processor design that one needs to understand to write assembly code Examples: instruction set specification, registers Some assembly code Counterexamples: cache sizes and core frequency ipf: xorps %xmm1, %xmm1 Example ISAs xorl %ecx, %ecx . x86 jmp .L8 .L10: . ia movslq %ecx,%rax incl %ecx . MIPS movss (%rsi,%rax,4), %xmm0 mulss (%rdi,%rax,4), %xmm0 . POWER addss %xmm0, %xmm1 .L8: . SPARC cmpl %edx, %ecx . ARM jl .L10 movaps %xmm1, %xmm0 ret 4 © Markus Püschel Advanced Systems Lab Computer Science Spring 2020 MMX: Multimedia extension Intel x86 Processors (subset) x86-16 8086 SSE: Streaming SIMD extension 286 x86-32 386 AVX: 486 Advanced vector extensions Pentium MMX Pentium MMX SSE Pentium III Backward compatible: SSE2 Pentium 4 Old binary code (≥ 8086) SSE3 Pentium 4E runs on new processors. x86-64 Pentium 4F Core 2 time New code to run on old SSE4 Penryn processors? Core i3/5/7 Depends on compiler flags. AVX Sandy Bridge AVX2 Haswell AVX-512 Skylake-X 5 ISA SIMD (Single Instruction Multiple Data) Vector Extensions What is it? . Extension of the ISA. Data types and instructions for the parallel computation on short (length 2–8) vectors of integers or floats + x 4-way . -

Intel Haswell Architecture/Microarchitecture, Operational Intensity
Advanced Systems Lab Spring 2021 Lecture: Architecture/Microarchitecture and Intel Core Instructor: Markus Püschel, Ce Zhang TA: Joao Rivera, several more Organization Research project: Deadline March 12th Finding team: [email protected] 2 © Markus Püschel Advanced Systems Lab Computer Science Spring 2020 Today Architecture/Microarchitecture: What is the difference? In detail: Intel Haswell and Sandybridge Crucial microarchitectural parameters Peak performance Operational intensity 3 Definitions Architecture (also instruction set architecture = ISA): The parts of a processor design that one needs to understand to write assembly code Examples: instruction set specification, registers Some assembly code ipf: Counterexamples: cache sizes and core frequency xorps %xmm1, %xmm1 xorl %ecx, %ecx Example ISAs jmp .L8 .L10: . x86 movslq %ecx,%rax incl %ecx . ia movss (%rsi,%rax,4), %xmm0 mulss (%rdi,%rax,4), %xmm0 . MIPS addss %xmm0, %xmm1 .L8: . POWER cmpl %edx, %ecx . SPARC jl .L10 movaps %xmm1, %xmm0 . ARM ret 4 © Markus Püschel Advanced Systems Lab Computer Science Spring 2020 MMX: Multimedia extension Intel x86 Processors (subset) x86-16 8086 SSE: Streaming SIMD extension 286 x86-32 386 AVX: 486 Advanced vector extensions Pentium MMX Pentium MMX SSE Pentium III Backward compatible: SSE2 Pentium 4 Old binary code (≥ 8086) SSE3 Pentium 4E runs on newer processors. x86-64 Pentium 4F Core 2 time New code to run on old SSE4 Penryn processors? Core i3/5/7 Depends on compiler flags. AVX Sandy Bridge AVX2 Haswell AVX-512 Skylake-X 5 ISA SIMD (Single Instruction Multiple Data) Vector Extensions What is it? . Extension of the ISA. Data types and instructions for the parallel computation on short (length 2–8) vectors of integers or floats + x 4-way . -

How to Write Fast Numerical Code Spring 2019 Lecture: SIMD Extensions, SSE, Compiler Vectorization
How to Write Fast Numerical Code Spring 2019 Lecture: SIMD extensions, SSE, compiler vectorization Instructor: Markus Püschel TA: Tyler Smith, Gagandeep Singh, Alen Stojanov Flynn’s Taxonomy Single instruction Multiple instruction Single data SISD MISD Uniprocessor Multiple data SIMD MIMD Vector computer Multiprocessors Short vector extensions VLIW 2 © Markus Püschel How to write fast numerical code Computer Science Spring 2019 SIMD Extensions and SSE SSE intrinsics Compiler vectorization This lecture and material was created together with Franz Franchetti (ECE, Carnegie Mellon) 3 SIMD Vector Extensions + x 4-way What is it? . Extension of the ISA . Data types and instructions for the parallel computation on short (length 2, 4, 8, …) vectors of integers or floats . Names: MMX, SSE, SSE2, … Why do they exist? . Useful: Many applications have the necessary fine-grain parallelism Then: speedup by a factor close to vector length . Doable: Relatively easy to design by replicating functional units 4 © Markus Püschel How to write fast numerical code Computer Science Spring 2019 © Markus Püschel MMX: Computer Science Multimedia extension Intel x86 Processors SSE: x86-16 8086 Streaming SIMD extension AVX: 286 Advanced vector extensions x86-32 386 486 Pentium MMX Pentium MMX register 64 bit width (only int) SSE Pentium III SSE2 Pentium 4 time SSE3 Pentium 4E 2 doubles = 128 bit x86-64 Pentium 4F Core 2 Duo SSE4 Penryn Core i7 (Nehalem) AVX Sandy Bridge 4 doubles = 256 bit AVX2 Haswell 8 doubles = 512 bit AVX-512 Skylake-X Example SSE Family: Floating Point SSE4 SSSE3 SSE3 SSE2: 2-way double SSE: 4-way single Not drawn to scale From SSE3: Only additional instructions Every Core 2 has SSE3 6 © Markus Püschel How to write fast numerical code Computer Science Spring 2019 Core 2 Has SSE3 16 SSE registers 128 bit = 2 doubles = 4 singles %xmm0 %xmm8 %xmm1 %xmm9 %xmm2 %xmm10 %xmm3 %xmm11 %xmm4 %xmm12 %xmm5 %xmm13 %xmm6 %xmm14 %xmm7 %xmm15 7 SSE3 Registers Used for different data types and instructions 128 bit LSB Integer vectors: . -

Architecture/Microarchitecture, Operational Intensity, Core 2/Core I7
How to Write Fast Numerical Code Spring 2015 Lecture: Architecture/Microarchitecture and Intel Core Instructor: Markus Püschel TA: Gagandeep Singh, Daniele Spampinato, Alen Stojanov Technicalities Midterm: April 15th (during recitation time) Research project: . Let us know once you have a partner . If you have a project idea, talk to me (break, after Wed class, email) . Deadline: March 6th Finding partner: [email protected] . Recipients: TA + all students that have no partner yet We will be using Moodle for homeworks (online submission and more) 2 © Markus Püschel How to write fast numerical code Computer Science Spring 2015 Today Architecture/Microarchitecture: What is the difference? In detail: Core 2/Core i7 Crucial microarchitectural parameters Peak performance Operational intensity 3 Definitions Architecture (also instruction set architecture = ISA): The parts of a processor design that one needs to understand to write assembly code Examples: instruction set specification, registers Some assembly code ipf: Counterexamples: cache sizes and core frequency xorps %xmm1, %xmm1 xorl %ecx, %ecx Example ISAs jmp .L8 .L10: . x86 movslq %ecx,%rax incl %ecx . ia movss (%rsi,%rax,4), %xmm0 mulss (%rdi,%rax,4), %xmm0 . MIPS addss %xmm0, %xmm1 . POWER .L8: cmpl %edx, %ecx . SPARC jl .L10 movaps %xmm1, %xmm0 . ARM ret 4 © Markus Püschel How to write fast numerical code Computer Science Spring 2015 MMX: Multimedia extension SSE: Intel x86 Processors Streaming SIMD extension x86-16 8086 AVX: Advanced vector extensions 286 x86-32 386 486 Backward compatible: Pentium Old binary code (≥ 8086) MMX Pentium MMX runs on new processors. SSE Pentium III time New code to run on old SSE2 Pentium 4 processors? SSE3 Pentium 4E Depends on compiler flags.