Sample Report Final Report - 8/20/2020
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Cell Death Via Lipid Peroxidation and Protein Aggregation Diseases
biology Review Cell Death via Lipid Peroxidation and Protein Aggregation Diseases Katsuya Iuchi * , Tomoka Takai and Hisashi Hisatomi Department of Materials and Life Science, Faculty of Science and Technology, Seikei University, 3-3-1 Kichijojikitamachi, Musashino-shi, Tokyo 180-8633, Japan; [email protected] (T.T.); [email protected] (H.H.) * Correspondence: [email protected] or [email protected]; Tel.: +81-422-37-3523 Simple Summary: It is essential for cellular homeostasis that biomolecules, such as DNA, proteins, and lipids, function properly. Disturbance of redox homeostasis produces aberrant biomolecules, including oxidized lipids and misfolded proteins, which increase in cells. Aberrant biomolecules are removed by excellent cellular clearance systems. However, when excess aberrant biomolecules remain in the cell, they disrupt organelle and cellular functions, leading to cell death. These aberrant molecules aggregate and cause apoptotic and non-apoptotic cell death, leading to various protein aggregation diseases. Thus, we investigated the cell-death cross-linking between lipid peroxidation and protein aggregation. Abstract: Lipid peroxidation of cellular membranes is a complicated cellular event, and it is both the cause and result of various diseases, such as ischemia-reperfusion injury, neurodegenerative diseases, and atherosclerosis. Lipid peroxidation causes non-apoptotic cell death, which is associated with cell fate determination: survival or cell death. During the radical chain reaction of lipid peroxidation, Citation: Iuchi, K.; Takai, T.; various oxidized lipid products accumulate in cells, followed by organelle dysfunction and the Hisatomi, H. Cell Death via Lipid induction of non-apoptotic cell death. Highly reactive oxidized products from unsaturated fatty acids Peroxidation and Protein are detected under pathological conditions. -

Chr21 Protein-Protein Interactions: Enrichment in Products Involved in Intellectual Disabilities, Autism and Late Onset Alzheimer Disease
bioRxiv preprint doi: https://doi.org/10.1101/2019.12.11.872606; this version posted December 12, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. Chr21 protein-protein interactions: enrichment in products involved in intellectual disabilities, autism and Late Onset Alzheimer Disease Julia Viard1,2*, Yann Loe-Mie1*, Rachel Daudin1, Malik Khelfaoui1, Christine Plancon2, Anne Boland2, Francisco Tejedor3, Richard L. Huganir4, Eunjoon Kim5, Makoto Kinoshita6, Guofa Liu7, Volker Haucke8, Thomas Moncion9, Eugene Yu10, Valérie Hindie9, Henri Bléhaut11, Clotilde Mircher12, Yann Herault13,14,15,16,17, Jean-François Deleuze2, Jean- Christophe Rain9, Michel Simonneau1, 18, 19, 20** and Aude-Marie Lepagnol- Bestel1** 1 Centre Psychiatrie & Neurosciences, INSERM U894, 75014 Paris, France 2 Laboratoire de génomique fonctionnelle, CNG, CEA, Evry 3 Instituto de Neurociencias CSIC-UMH, Universidad Miguel Hernandez-Campus de San Juan 03550 San Juan (Alicante), Spain 4 Department of Neuroscience, The Johns Hopkins University School of Medicine, Baltimore, MD 21205 USA 5 Center for Synaptic Brain Dysfunctions, Institute for Basic Science, Daejeon 34141, Republic of Korea 6 Department of Molecular Biology, Division of Biological Science, Nagoya University Graduate School of Science, Furo, Chikusa, Nagoya, Japan 7 Department of Biological Sciences, University of Toledo, Toledo, OH, 43606, USA 8 Leibniz Forschungsinstitut für Molekulare Pharmakologie -

Association Between Obsessive-Compulsive Disorder and Glutamate N-Methyl-D-Aspartate 2B Subunit Receptor Gene
Association between obsessive-compulsive disorder and glutamate n-methyl-d-aspartate 2b subunit receptor gene Syung Shick Hwang The Graduate School Yonsei University Department of Medicine Association between obsessive-compulsive disorder and glutamate n-methyl-d-aspartate 2b subunit receptor gene A Master’s Thesis submitted to the Department of Medicine and the Graduate School of Yonsei University in partial fulfillment of the requirements for the degree of Master of Medicine Syung Shick Hwang December 2006 This certifies that the Master’s Thesis of Syung Shick Hwang is approved . ----------------------------------------------------------------------------------------------------------------------------------------- Thesis Supervisor: Chan-Hyung Kim ----------------------------------------------------------------------------------------------------------------------------------------- [ Jin-Sung Lee : Thesis Committee Member#1] ----------------------------------------------------------------------------------------------------------------------------------------- [ Se Joo Kim : Thesis Committee Member#2] The Graduate School Yonsei University December 2006 Acknowledgements I am very fortunate to complete this master’s dissertation. I have prospered from the critical feedback, support, and assistance from supervisors, teachers, friends, colleagues, and family members. In this regard, I am most grateful to Professor Chan-Hyung Kim who has provided unwavering intellectual and moral support. He has helped and encouraged my academic and ethical -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -
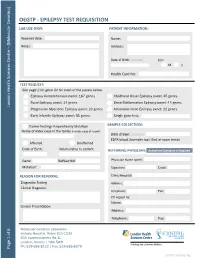
Oegtp - Epilepsy Test Requisition Lab Use Only: Patient Information
OEGTP - EPILEPSY TEST REQUISITION LAB USE ONLY: PATIENT INFORMATION: Received date: Name: Notes: Address: Date of Birth: YY/MM/DD Sex: M F Health Card No: TEST REQUEST: See page 2 for gene list for each of the panels below Epilepsy Comprehensive panel: 167 genes Childhood Onset Epilepsy panel: 45 genes Focal Epilepsy panel: 14 genes Brain Malformation Epilepsy panel: 44 genes London Health Sciences Centre – (Molecular Genetics) London Health Sciences Centre Progressive Myoclonic Epilepsy panel: 20 genes Actionable Gene Epilepsy panel: 22 genes Early Infantile Epilepsy panel: 51 genes Single gene test: Carrier Testing/ KnownFamily Mutation SAMPLE COLLECTION: Name of index case in the family (include copy of report) Date drawn: YY/MM/DD EDTA blood (lavender top) (5ml at room temp) Affected Unaffected Date of Birth: Relationship to patient: REFERRING PHYSICIAN: Authorized Signature is Required Gene: RefSeq:NM Physician Name (print): Mutation: Signature: Email: REASON FOR REFERRAL: Clinic/Hospital: Diagnostic Testing Address: Clinical Diagnosis: Telephone: Fax: CC report to: Name: Clinical Presentation: Address: Telephone: Fax: Molecular Genetics Laboratory Victoria Hospital, Room B10-123A 800 Commissioners Rd. E. London, Ontario | N6A 5W9 Pathology and Laboratory Medicine Ph: 519-685-8122 | Fax: 519-685-8279 Page 1 of 6 Page OEGTP (2021/05/28) OEGTP - EPILEPSY TEST PANELS Patient Identifier: COMPREHENSIVE EPILEPSY PANEL: 167 Genes ACTB, ACTG1, ADSL, AKT3, ALDH7A1, AMT, AP3B2, ARFGEF2, ARHGEF9, ARV1, ARX, ASAH1, ASNS, ATP1A3, ATP6V0A2, ATP7A, -

Interplay Between Gating and Block of Ligand-Gated Ion Channels
brain sciences Review Interplay between Gating and Block of Ligand-Gated Ion Channels Matthew B. Phillips 1,2, Aparna Nigam 1 and Jon W. Johnson 1,2,* 1 Department of Neuroscience, University of Pittsburgh, Pittsburgh, PA 15260, USA; [email protected] (M.B.P.); [email protected] (A.N.) 2 Center for Neuroscience, University of Pittsburgh, Pittsburgh, PA 15260, USA * Correspondence: [email protected]; Tel.: +1-(412)-624-4295 Received: 27 October 2020; Accepted: 26 November 2020; Published: 1 December 2020 Abstract: Drugs that inhibit ion channel function by binding in the channel and preventing current flow, known as channel blockers, can be used as powerful tools for analysis of channel properties. Channel blockers are used to probe both the sophisticated structure and basic biophysical properties of ion channels. Gating, the mechanism that controls the opening and closing of ion channels, can be profoundly influenced by channel blocking drugs. Channel block and gating are reciprocally connected; gating controls access of channel blockers to their binding sites, and channel-blocking drugs can have profound and diverse effects on the rates of gating transitions and on the stability of channel open and closed states. This review synthesizes knowledge of the inherent intertwining of block and gating of excitatory ligand-gated ion channels, with a focus on the utility of channel blockers as analytic probes of ionotropic glutamate receptor channel function. Keywords: ligand-gated ion channel; channel block; channel gating; nicotinic acetylcholine receptor; ionotropic glutamate receptor; AMPA receptor; kainate receptor; NMDA receptor 1. Introduction Neuronal information processing depends on the distribution and properties of the ion channels found in neuronal membranes. -

Coupling of Autism Genes to Tissue-Wide Expression and Dysfunction of Synapse, Calcium Signalling and Transcriptional Regulation
PLOS ONE RESEARCH ARTICLE Coupling of autism genes to tissue-wide expression and dysfunction of synapse, calcium signalling and transcriptional regulation 1 2,3 4 1,5 Jamie ReillyID *, Louise Gallagher , Geraldine Leader , Sanbing Shen * 1 Regenerative Medicine Institute, School of Medicine, Biomedical Science Building, National University of a1111111111 Ireland (NUI) Galway, Galway, Ireland, 2 Discipline of Psychiatry, School of Medicine, Trinity College Dublin, Dublin, Ireland, 3 Trinity Translational Medicine Institute, Trinity Centre for Health SciencesÐTrinity College a1111111111 Dublin, St. James's Hospital, Dublin, Ireland, 4 Irish Centre for Autism and Neurodevelopmental Research a1111111111 (ICAN), Department of Psychology, National University of Ireland (NUI) Galway, Galway, Ireland, a1111111111 5 FutureNeuro Research Centre, Royal College of Surgeons in Ireland (RCSI), Dublin, Ireland a1111111111 * [email protected] (JR); [email protected] (SS) Abstract OPEN ACCESS Citation: Reilly J, Gallagher L, Leader G, Shen S Autism Spectrum Disorder (ASD) is a heterogeneous disorder that is often accompanied (2020) Coupling of autism genes to tissue-wide with many co-morbidities. Recent genetic studies have identified various pathways from expression and dysfunction of synapse, calcium hundreds of candidate risk genes with varying levels of association to ASD. However, it is signalling and transcriptional regulation. PLoS ONE unknown which pathways are specific to the core symptoms or which are shared by the co- 15(12): e0242773. https://doi.org/10.1371/journal. pone.0242773 morbidities. We hypothesised that critical ASD candidates should appear widely across dif- ferent scoring systems, and that comorbidity pathways should be constituted by genes Editor: Nirakar Sahoo, The University of Texas Rio Grande Valley, UNITED STATES expressed in the relevant tissues. -

Mechanisms Underlying the EEG Biomarker in Dup15q Syndrome Joel Frohlich1,2,3* , Lawrence T
Frohlich et al. Molecular Autism (2019) 10:29 https://doi.org/10.1186/s13229-019-0280-6 RESEARCH Open Access Mechanisms underlying the EEG biomarker in Dup15q syndrome Joel Frohlich1,2,3* , Lawrence T. Reiter4, Vidya Saravanapandian2, Charlotte DiStefano2, Scott Huberty2,5, Carly Hyde2, Stormy Chamberlain6, Carrie E. Bearden7, Peyman Golshani8, Andrei Irimia9, Richard W. Olsen10, Joerg F. Hipp1† and Shafali S. Jeste2† Abstract Background: Duplications of 15q11.2-q13.1 (Dup15q syndrome), including the paternally imprinted gene UBE3A and three nonimprinted gamma-aminobutyric acid type-A (GABAA) receptor genes, are highly penetrant for neurodevelopmental disorders such as autism spectrum disorder (ASD). To guide targeted treatments of Dup15q syndrome and other forms of ASD, biomarkers are needed that reflect molecular mechanisms of pathology. We recently described a beta EEG phenotype of Dup15q syndrome, but it remains unknown which specific genes drive this phenotype. Methods: To test the hypothesis that UBE3A overexpression is not necessary for the beta EEG phenotype, we compared EEG from a reference cohort of children with Dup15q syndrome (n = 27) to (1) the pharmacological effects of the GABAA modulator midazolam (n = 12) on EEG from healthy adults, (2) EEG from typically developing (TD) children (n = 14), and (3) EEG from two children with duplications of paternal 15q (i.e., the UBE3A-silenced allele). Results: Peak beta power was significantly increased in the reference cohort relative to TD controls. Midazolam administration recapitulated the beta EEG phenotype in healthy adults with a similar peak frequency in central channels (f = 23.0 Hz) as Dup15q syndrome (f = 23.1 Hz). -

Sex Differences in Glutamate Receptor Gene Expression in Major Depression and Suicide
Molecular Psychiatry (2015) 20, 1057–1068 © 2015 Macmillan Publishers Limited All rights reserved 1359-4184/15 www.nature.com/mp IMMEDIATE COMMUNICATION Sex differences in glutamate receptor gene expression in major depression and suicide AL Gray1, TM Hyde2,3, A Deep-Soboslay2, JE Kleinman2 and MS Sodhi1,4 Accumulating data indicate that the glutamate system is disrupted in major depressive disorder (MDD), and recent clinical research suggests that ketamine, an antagonist of the N-methyl-D-aspartate (NMDA) glutamate receptor (GluR), has rapid antidepressant efficacy. Here we report findings from gene expression studies of a large cohort of postmortem subjects, including subjects with MDD and controls. Our data reveal higher expression levels of the majority of glutamatergic genes tested in the dorsolateral prefrontal cortex (DLPFC) in MDD (F21,59 = 2.32, P = 0.006). Posthoc data indicate that these gene expression differences occurred mostly in the female subjects. Higher expression levels of GRIN1, GRIN2A-D, GRIA2-4, GRIK1-2, GRM1, GRM4, GRM5 and GRM7 were detected in the female patients with MDD. In contrast, GRM5 expression was lower in male MDD patients relative to male controls. When MDD suicides were compared with MDD non-suicides, GRIN2B, GRIK3 and GRM2 were expressed at higher levels in the suicides. Higher expression levels were detected for several additional genes, but these were not statistically significant after correction for multiple comparisons. In summary, our analyses indicate a generalized disruption of the regulation of the GluRs in the DLPFC of females with MDD, with more specific GluR alterations in the suicides and in the male groups. -

Regulation of Mitochondrial and Nonmitochondrial Protein Turnover by the PINK1-Parkin Pathway
Regulation of mitochondrial and nonmitochondrial protein turnover by the PINK1-Parkin pathway Evelyn S. Vincow A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy University of Washington 2013 Reading Committee: Leo J. Pallanck, Chair Sandra M. Bajjalieh Michael J. MacCoss Program Authorized to Offer Degree: Neurobiology and Behavior © Copyright 2013 Evelyn S. Vincow University of Washington Abstract Regulation of mitochondrial and nonmitochondrial protein turnover by the PINK1-Parkin pathway Evelyn Sandra Vincow Chair of the Supervisory Committee: Associate Professor Leo J. Pallanck Genome Sciences The accumulation of damaged mitochondria has been proposed as a key factor in aging and in the pathogenesis of many common age-related diseases, including Parkinson disease (PD). Recently, in vitro studies of the PD-related proteins Parkin and PINK1 have found that these factors act in a common pathway to promote the selective autophagic degradation of damaged mitochondria (mitophagy). However, whether PINK1 and Parkin promote mitophagy in vivo is unknown. To address this question, I used a proteomic approach in Drosophila to study the effects of null mutations in parkin or PINK1 on mitochondrial protein turnover. The parkin null mutants showed a significant overall slowing of mitochondrial protein turnover, similar to but less severe than the slowing seen in autophagy-deficient Atg7 mutants, consistent with the model that Parkin acts upstream of Atg7 to promote mitophagy. By contrast, the turnover of many mitochondrial respiratory chain (RC) subunits showed greater impairment in parkin than in Atg7 mutants, and RC turnover was also selectively impaired in PINK1 mutants. These findings demonstrate that the PINK1-Parkin pathway promotes mitophagy in vivo and, unexpectedly, also promotes selective turnover of mitochondrial RC components. -

Research Article Microarray-Based Comparisons of Ion Channel Expression Patterns: Human Keratinocytes to Reprogrammed Hipscs To
Hindawi Publishing Corporation Stem Cells International Volume 2013, Article ID 784629, 25 pages http://dx.doi.org/10.1155/2013/784629 Research Article Microarray-Based Comparisons of Ion Channel Expression Patterns: Human Keratinocytes to Reprogrammed hiPSCs to Differentiated Neuronal and Cardiac Progeny Leonhard Linta,1 Marianne Stockmann,1 Qiong Lin,2 André Lechel,3 Christian Proepper,1 Tobias M. Boeckers,1 Alexander Kleger,3 and Stefan Liebau1 1 InstituteforAnatomyCellBiology,UlmUniversity,Albert-EinsteinAllee11,89081Ulm,Germany 2 Institute for Biomedical Engineering, Department of Cell Biology, RWTH Aachen, Pauwelstrasse 30, 52074 Aachen, Germany 3 Department of Internal Medicine I, Ulm University, Albert-Einstein Allee 11, 89081 Ulm, Germany Correspondence should be addressed to Alexander Kleger; [email protected] and Stefan Liebau; [email protected] Received 31 January 2013; Accepted 6 March 2013 Academic Editor: Michael Levin Copyright © 2013 Leonhard Linta et al. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. Ion channels are involved in a large variety of cellular processes including stem cell differentiation. Numerous families of ion channels are present in the organism which can be distinguished by means of, for example, ion selectivity, gating mechanism, composition, or cell biological function. To characterize the distinct expression of this group of ion channels we have compared the mRNA expression levels of ion channel genes between human keratinocyte-derived induced pluripotent stem cells (hiPSCs) and their somatic cell source, keratinocytes from plucked human hair. This comparison revealed that 26% of the analyzed probes showed an upregulation of ion channels in hiPSCs while just 6% were downregulated. -

Identification of Key Genes and Pathways Involved in Response To
Deng et al. Biol Res (2018) 51:25 https://doi.org/10.1186/s40659-018-0174-7 Biological Research RESEARCH ARTICLE Open Access Identifcation of key genes and pathways involved in response to pain in goat and sheep by transcriptome sequencing Xiuling Deng1,2†, Dong Wang3†, Shenyuan Wang1, Haisheng Wang2 and Huanmin Zhou1* Abstract Purpose: This aim of this study was to investigate the key genes and pathways involved in the response to pain in goat and sheep by transcriptome sequencing. Methods: Chronic pain was induced with the injection of the complete Freund’s adjuvant (CFA) in sheep and goats. The animals were divided into four groups: CFA-treated sheep, control sheep, CFA-treated goat, and control goat groups (n 3 in each group). The dorsal root ganglions of these animals were isolated and used for the construction of a cDNA= library and transcriptome sequencing. Diferentially expressed genes (DEGs) were identifed in CFA-induced sheep and goats and gene ontology (GO) enrichment analysis was performed. Results: In total, 1748 and 2441 DEGs were identifed in CFA-treated goat and sheep, respectively. The DEGs identi- fed in CFA-treated goats, such as C-C motif chemokine ligand 27 (CCL27), glutamate receptor 2 (GRIA2), and sodium voltage-gated channel alpha subunit 3 (SCN3A), were mainly enriched in GO functions associated with N-methyl- D-aspartate (NMDA) receptor, infammatory response, and immune response. The DEGs identifed in CFA-treated sheep, such as gamma-aminobutyric acid (GABA)-related DEGs (gamma-aminobutyric acid type A receptor gamma 3 subunit [GABRG3], GABRB2, and GABRB1), SCN9A, and transient receptor potential cation channel subfamily V member 1 (TRPV1), were mainly enriched in GO functions related to neuroactive ligand-receptor interaction, NMDA receptor, and defense response.