Sketch-Based Facial Modeling and Animation: an Approach Based on Mobile Devices
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

CRU DANCE Friday March 12Th - Sunday March 14Th, 2021 MASON, OH
CRU DANCE Friday March 12th - Sunday March 14th, 2021 MASON, OH th Friday March 12 , 2021 Start Time: 5:00pm Studio Check in- Studio B, F, Q 4:30 PM Jadden Hahn, Shaylee Knott, Heidi Schleidt, 1 Q Coffee Anyone? Teen Tap Small Group Intermediate 5:00 PM Eliana Tipton Anna Armold, Olivia Ashmore, Lana Baker, Gabrielle Barbosa, Lilliana Barbosa, Quinnlyn Musical Blaisdell, Annabel Blake, Ava Constable, 2 F Little Girls Junior Large Group Novice 5:03 PM Theater Morgan Flick, Bella Hughes, Madelyn Hughes, Abigail Larson, Teagan Manley, Andromeda Search, Jackie Wright, Pammy Wright 3 Q I Can Be Anything Petite Jazz Solo Novice Arianna Liggett 5:07 PM 4 Q Miss Invisible Petite Lyrical Solo Novice Makenzie Berling 5:09 PM Piper Hays, Brooklyn Homan, Franky Jellison, 5 B Booty Swing Junior Jazz Small Group Intermediate Janessa Smuts, Sophie Steinbrunner, 5:12 PM Madison Wendeln 6 F Meant Senior Contemporary Solo Intermediate Pammy Wright 5:15 PM 7 B Womanizer Senior Jazz Solo Intermediate Shelby Ranly 5:18 PM 8 Q Just Mime'en My Business Junior Acrobat Solo Novice Alexis Burke 5:21 PM I Just Died in Your Arms 9 F Junior Open Solo Elite Jackie Wright 5:24 PM Tonight Anna Armold, Quinnlyn Blaisdell, Morgan 10 F Shadows of the Night Junior Jazz Small Group Intermediate 5:26 PM Flick, Madelyn Hughes Jadden Hahn, Gabrielle Helton, Shaylee 11 Q Amazing Grace Teen Contemporary Small Group Intermediate Knott, Reese Lynch, Heidi Schleidt, Eliana 5:29 PM Tipton 12 F Speechless Mini Jazz Solo Novice Teagan Manley 5:32 PM 13 B Dynamite Junior Jazz Solo Intermediate -

Skins Uk Download Season 1 Episode 1: Frankie
skins uk download season 1 Episode 1: Frankie. Howard Jones - New Song Scene: Frankie in her room animating Strange Boys - You Can't Only Love When You Want Scene: Frankie turns up at college with a new look Aeroplane - We Cant Fly Scene: Frankie decides to go to the party anyway. Fergie - Glamorous Scene: Music playing from inside the club. Blondie - Heart of Glass Scene: Frankie tries to appeal to Grace and Liv but Mini chucks her out, then she gets kidnapped by Alo & Rich. British Sea Power - Waving Flags Scene: At the swimming pool. Skins Series 1 Complete Skins Series 2 Complete Skins Series 3 Complete Skins Series 4 Complete Skins Series 5 Complete Skins Series 6 Complete Skins - Effy's Favourite Moments Skins: The Novel. Watch Skins. Skins in an award-winning British teen drama that originally aired in January of 2007 and continues to run new seasons today. This show follows the lives of teenage friends that are living in Bristol, South West England. There are many controversial story lines that set this television show apart from others of it's kind. The cast is replaced every two seasons to bring viewers brand new story lines with entertaining and unique characters. The first generation of Skins follows teens Tony, Sid, Michelle, Chris, Cassie, Jal, Maxxie and Anwar. Tony is one of the most popular boys in sixth form and can be quite manipulative and sarcastic. Michelle is Tony's girlfriend, who works hard at her studies, is very mature, but always puts up with Tony's behavior. -

GPU-Based Multiplatform Transcoding 1 Mahmut Ş
GPU-Based MultiPlatform Transcoding 1 Mahmut Ş. Sağıroğlu Founded in 2007, Erlab Software is a privately-held company based in Istanbul, Turkey. Erlab Software is a technology company that develops innovative and value added solutions for the customers with emerging technologies. Unique Position in the Market 2 Specialities: o Internet TV, o Content Management System (CMS), Market Position: o PlayReady DRM, o Video Transcoding, Video Streaming, o Covered 100% of Internet TV / Video market o Microsoft Smooth Streaming, in Turkey with his own solutions. o HTTP Live Streaming, o Windows 8, Windows Phone 8, o Serving to 80% of the subscribers with o Kinect, Xbox, Microsoft Pixelsense, Erlab’s Content Management Solutions o Enterprise Video Solutions, o OTT Video Solutions, o Smart TV Background 3 o Encoding is the most time consuming process in video processing. o Video decoding / encoding / processing is inherently parallellizable. o New generation NVIDIA GPU’s have an embedded hardware for video encoding. Motivation 4 o Video encoding is always on the agenda o %90 of the internet users watches video on any device o Lifelogging trend o Satellite Imagery o 2 trillion minutes (5 million years) of video content will cross the Internet each month in 2017 * * http://www.cisco.com/web/solutions/sp/vni/vni_forecast_highlights/index.html Challenges 5 Encoding and processing needs heavy mathematical operations Erlab’s Running CPU Based 6 Transcoding Solution For Adaptive Streaming Packetize Resize 1 Encode 1 Packetize Source 1 Decode Resize 2 Encode 2 Packetize Resize m Encode m Transmit Packetize Resize 1 Encode 1 Source n Decode Resize 2 Encode 2 Resize m Encode m Packetize Packetize CPU Based Solution 7 OPERATIONS DECODING F1 F2 F3 F4 F5 . -

Group Touch: Distinguishing Tabletop Users in Group Settings Via Statistical Modeling of Touch Pairs Abigail C
Group Touch: Distinguishing Tabletop Users in Group Settings via Statistical Modeling of Touch Pairs Abigail C. Evans,1 Katie Davis,1 James Fogarty,2 Jacob O. Wobbrock1 1The Information School, 2Computer Science & Engineering DUB Group | University of Washington Seattle, WA, USA 98195 {abievans, kdavis78, wobbrock}@uw.edu, [email protected] ABSTRACT We present Group Touch, a method for distinguishing among multiple users simultaneously interacting with a tabletop computer using only the touch information supplied by the device. Rather than tracking individual users for the duration of an activity, Group Touch distinguishes users from each other by modeling whether an interaction with the tabletop corresponds to either: (1) a new user, or (2) a change in users currently interacting with the tabletop. This reframing of the challenge as distinguishing users rather than tracking and identifying them allows Group Touch to support multi-user collaboration in real-world settings without custom instrumentation. Specifically, Group Touch examines pairs of touches and uses the difference in orientation, distance, and time between two touches to Figure 1. Group Touch can distinguish among users “in the wild” determine whether the same person performed both touches with a mean accuracy of 92.92% (SD=3.94%) using only touch in the pair. Validated with field data from high-school information. Pictured above are high school students in a classroom. students in a classroom setting, Group Touch distinguishes The challenge of distinguishing among users (i.e., knowing one among users “in the wild” with a mean accuracy of 92.92% user’s touches are different from another’s) is a different challenge than identifying them (i.e., knowing to whom each touch belongs). -

3 Tracking In-Air Gestures in Collaborative Environments Using Commodity Hard- Ware 17 3.1 Depth Cameras
Research Collection Doctoral Thesis A Framework for Optimal In-Air Gesture Recognition in Collaborative Environments Author(s): Alavi, Ali Seyed Publication Date: 2020 Permanent Link: https://doi.org/10.3929/ethz-b-000449030 Rights / License: In Copyright - Non-Commercial Use Permitted This page was generated automatically upon download from the ETH Zurich Research Collection. For more information please consult the Terms of use. ETH Library DISS. ETH NO. 26416 A Framework for Optimal In-Air Gesture Recognition in Collaborative Environments A thesis submitted to attain the degree of DOCTOR OF SCIENCES of ETH Zurich (Dr. sc. ETH Zurich) presented by SEYED ALI ALAVI Master of Science in Secure and Dependable Computer Systems born on 15.09.1984 citizen of Iran accepted on the recommendation of Prof. Dr. Konrad Wegener, examiner Prof. Dr. Andreas Kunz, co-examiner Prof. Dr. Morten Fjeld, co-examiner 2020 Abstract Hand gestures play an important role in communication between humans, and increasingly in the inter- action between humans and computers, where users can interact with a computer system to manipulate digital content, provide input, and give commands to a digital system. Thanks to advances in computer vision and camera technology, in-air hand gestures can be tracked without the need for instrumenting the hands. This allows for a wide variety of interesting and powerful use cases. First, hand gestures that happen naturally during human to human communication can be tracked and interpreted. This has been extensively used and researched, for example for communicating deictic ges- tures to remote participants. Most such solutions rely on communicating such gestures using extensive visual feedback, for example by showing remote participant’s hand, or even his or her full body, to their remote partners. -

2011-2012 Annual Report to the Case Western Reserve Community: Ours Is a Campus Full of People Driven to Make a Difference
THINK AHEAD 2011-2012 Annual Report To the Case Western Reserve Community: Ours is a campus full of people driven to make a difference. Whether pursuing a cure for Alzheimer’s or prosecuting pirates on the high seas, our faculty, staff, and students strive for impact. They translate discoveries about nature into state-of- the-art technology. They turn insights about oral health into answers to orthopedic issues. They even use irritation about a common car problem as fuel for a promising product. Are we dreamers? Absolutely. But at Case Western Reserve, aspirations are only the start. Then come questions: How can we make this concept work? What tweaks will take it farther? What improvements can we add? As Gmail inventor Paul Buchheit (’98) told our 2012 graduates, the correct path may not be the one everyone else identifies. Sometimes the answer involves forging through unfamiliar trails. In such instances, the key is not only to listen to instincts, but follow them. In 2011-2012, that spirit spurred Celia Weatherhead to announce that she and her late husband, Albert, had committed $50 million to our university to advance management education and community health. It led an anonymous donor to commit $20 million for our programs in the natural sciences. And it prompted trustee Larry Sears and his wife, Sally Zlotnik Sears, to contribute $5 million to think[box], a campus initiative to encourage entrepreneurial innovation. Such support inspires us all. It also helps attract still more like-minded achievers. The undergraduate class we admitted this spring represents the largest, most diverse and most academically accomplished in our university’s history. -

SMAC: a Simplified Model of Attention and Capture in Multi-Device Desk-Centric Environments
SMAC: A Simplified Model of Attention and Capture in Multi-Device Desk-Centric Environments ZHEN LI, University of Toronto, Canada 2 MICHELLE ANNETT, MishMashMakers, Canada KEN HINCKLEY, Microsoft Research, United States DANIEL WIGDOR, University of Toronto, Canada Prior research has demonstrated that users are increasingly employing multiple devices during daily work. Currently, devices such as keyboards, cell phones, and tablets remain largely unaware of their role within a user’s workflow. As a result, transitioning between devices is tedious, often to the degree that users are discouraged from taking full advantage of the devices they have within reach. This work explores the device ecologies used in desk-centric environments and complies the insights observed into SMAC, a simplified model of attention and capture that emphasizes the role of user-device proxemics, as mediated by hand placement, gaze, and relative body orientation, as well as inter-device proxemics. SMAC illustrates the potential of harnessing the rich, proxemic diversity that exists between users and their device ecologies, while also helping to organize and synthesize the growing body of literature on distributed user interfaces. An evaluation study using SMAC demonstrated that users could easily understand the tenants of user- and inter-device proxemics and found them to be valuable within their workflows. CCS Concepts: • Human-centered computing → Interaction paradigms; Interaction techniques. Additional Key Words and Phrases: Proxemics, user proxemics, inter-device proxemics, cross-device interaction, distributed user interfaces ACM Reference Format: Zhen Li, Michelle Annett, Ken Hinckley, and Daniel Wigdor. 2019. SMAC: A Simplified Model of Attention and Capture in Multi-Device Desk-Centric Environments. -

Judson White
JUDSON WHITE Austin, TX (877) 316-7975 [email protected] https://github.com/judwhite BIO . 16 years professional experience . C# / .NET, Go (Golang) . Originally from a C and C++ background; open to learning other languages . Hands-on development and architecture/system design . Equally happy to contribute in a team member, technical lead, or architect position ACKNOWLEDGMENTS Rattz Jr., Joseph C. (2009). Pro LINQ: Language Integrated Query. New York, NY: Apress. TALKS . “Go: A Practical Start Guide”. Bleeding Edge Web at Capital Factory, 23 March 2016 o Slides: https://github.com/judwhite/talks-edgeatx (includes video) . “Go: A Practical Start Guide” Dell Developer User Group, 30 March 2016 o Slides: https://github.com/judwhite/talks-dell . “Performance Tuning in Go” North Austin Golang Meetup at Tech Ranch, 26 May 2016 o Slides: https://github.com/judwhite/talks-goperf TECHNICAL SKILLS . General: o Multithreaded / concurrent applications o Distributed systems (workloads, messaging, RPC, consensus) o HTTP API design / RESTful Services o CQRS / SOLID principles o Full-development lifecycle and agile methodologies o Performance and memory profiling/tuning . .NET: o ASP.NET MVC, Web API, WCF, Razor Views o WPF/XAML/MVVM, Windows Forms o StructureMap, Autofac, Dapper, Entity Framework o NUnit, MSTest, Moq . Databases / Datastores: o MS SQL Server, Postgres, MySQL, SQLite, BoltDB, Elasticsearch o Schema design and T-SQL . Distributed Messaging: o NSQ (contributor) . Source Control: o Git, TFS, Perforce, Subversion, ClearCase, Source Depot EXPERIENCE DELL – ROUND ROCK, TX 2/14 - PRESENT Software Dev Prin Engineer / Tech Lead . Responsible for a rewrite of the commercial side of Dell.com with a focus on improving performance, reliability, and scalability. -

Full Competitor List
Competitor List Argentina Entries: 2 Height Handler Dog Breed 300 Fernando Estevez Costas Arya Mini Poodle 600 Jorge Esteban Ramos Trice Border Collie Salinas Australia Entries: 6 Height Handler Dog Breed 400 Reserve Dog Casper Dutch Smoushond 500 Maria Thiry Tebbie Border Collie 500 Maria Thiry Beat Pumi 600 Emily Abrahams Loki Border Collie 600 Reserve Dog Ferno Border Collie 600 Gillian Self Showtime Border Collie Austria Entries: 12 Height Handler Dog Breed 300 Helgar Blum Tim Parson Russell Ter 300 Markus Fuska Cerry Lee Shetland Sheepdog 300 Markus Fuska Nala Crossbreed 300 Petra Reichetzer Pixxel Shetland Sheepdog 400 Gabriele Breitenseher Aileen Shetland Sheepdog 400 Gregor Lindtner Asrael Shetland Sheepdog 400 Daniela Lubei Ebby Shetland Sheepdog 500 Petra Reichetzer Paisley Border Collie 500 Hermann Schauhuber Haily Border Collie 600 Michaela Melcher Treat Border Collie 600 Sonja Mladek Flynn Border Collie 600 Sonja Mladek Trigger Border Collie Belgium Entries: 17 Height Handler Dog Breed 300 Dorothy Capeta Mauricio Ben Jack Russell Terrier 300 Ann Herreman Lance Shetland Sheepdog 300 Brechje Pots Dille Jack Russell Terrier 300 Kristel Van Den Eynde Mini Jack Russell Terrier 400 Ann Herreman Qiell Shetland Sheepdog 400 Anneleen Holluyn Hjatho Mini Australian Shep 400 Anneleen Holluyn Ippy Mini Australian Shep 26-Apr-19 19:05 World Agility Open 2019 Page 1 of 14 500 Franky De Witte Laser Border Collie 500 Franky De Witte Idol Border Collie 500 Erik Denecker Tara Border Collie 500 Philippe Dubois Jessy Border Collie 600 Kevin Baert -

An Improved Modular Framework for Developing Multi-Surface Interaction
AN IMPROVED MODULAR FRAMEWORK FOR DEVELOPING MULTI-SURFACE INTERACTION A Paper Submitted to the Graduate Faculty of the North Dakota State University of Agriculture and Applied Science By Jed Patrick Limke In Partial Fulfillment of the Requirements for the Degree of MASTER OF SCIENCE Major Program: Software Engineering December 2015 Fargo, North Dakota North Dakota State University Graduate School Title AN IMPROVED MODULAR FRAMEWORK FOR DEVELOPING MULTI-SURFACE INTERACTION By Jed Patrick Limke The Supervisory Committee certifies that this disquisition complies with North Dakota State University’s regulations and meets the accepted standards for the degree of MASTER OF SCIENCE SUPERVISORY COMMITTEE: Dr. Jun Kong Chair Dr. Juan Li Dr. Jin Li Approved: 12/21/2015 Dr. Brian Slator Date Department Chair ABSTRACT Advances in multi-touch capabilities have led to their use in a vast array of devices, but usable interactions that span across devices are less frequently encountered. To address this con- cern, a framework was created for the development of interaction spaces which gave developers the tools to write applications which united tabletop and handheld devices, allowing each device to utilize its inherent interaction style yet still communicate effectively. However, while this framework provided proof that such interactions were possible, it failed to prove itself as easily reusable by subsequent developers. To address this concern, we have created an improved framework to both fulfill the goals of the original framework and confront its shortcomings. Our improved framework features a new intra-component communication system, mobile device independence, configurable user interfaces, and automatic exposure of available interac- tions. -
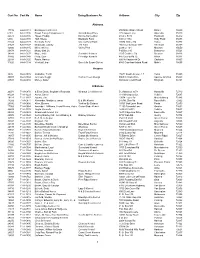
Cert No Name Doing Business As Address City Zip 1 Cust No
Cust No Cert No Name Doing Business As Address City Zip Alabama 17732 64-A-0118 Barking Acres Kennel 250 Naftel Ramer Road Ramer 36069 6181 64-A-0136 Brown Family Enterprises Llc Grandbabies Place 125 Aspen Lane Odenville 35120 22373 64-A-0146 Hayes, Freddy Kanine Konnection 6160 C R 19 Piedmont 36272 6394 64-A-0138 Huff, Shelia Blackjack Farm 630 Cr 1754 Holly Pond 35083 22343 64-A-0128 Kennedy, Terry Creeks Bend Farm 29874 Mckee Rd Toney 35773 21527 64-A-0127 Mcdonald, Johnny J M Farm 166 County Road 1073 Vinemont 35179 42800 64-A-0145 Miller, Shirley Valley Pets 2338 Cr 164 Moulton 35650 20878 64-A-0121 Mossy Oak Llc P O Box 310 Bessemer 35021 34248 64-A-0137 Moye, Anita Sunshine Kennels 1515 Crabtree Rd Brewton 36426 37802 64-A-0140 Portz, Stan Pineridge Kennels 445 County Rd 72 Ariton 36311 22398 64-A-0125 Rawls, Harvey 600 Hollingsworth Dr Gadsden 35905 31826 64-A-0134 Verstuyft, Inge Sweet As Sugar Gliders 4580 Copeland Island Road Mobile 36695 Arizona 3826 86-A-0076 Al-Saihati, Terrill 15672 South Avenue 1 E Yuma 85365 36807 86-A-0082 Johnson, Peggi Cactus Creek Design 5065 N. Main Drive Apache Junction 85220 23591 86-A-0080 Morley, Arden 860 Quail Crest Road Kingman 86401 Arkansas 20074 71-A-0870 & Ellen Davis, Stephanie Reynolds Wharton Creek Kennel 512 Madison 3373 Huntsville 72740 43224 71-A-1229 Aaron, Cheryl 118 Windspeak Ln. Yellville 72687 19128 71-A-1187 Adams, Jim 13034 Laure Rd Mountainburg 72946 14282 71-A-0871 Alexander, Marilyn & James B & M's Kennel 245 Mt. -

Projectable Interactive Surface Using Microsoft Kinect V2
2015 IEEE/SICE International Symposium on System Integration (SII) December 11-13, 2015. Meijo University, Nagoya, Japan ����������������������������������������������������������� ������������������������������������������������������� P. Sharma, R. P. Joshi, R. A. Boby, S. K. Saha, Member, IEEE and T. Matsumaru, Member, IEEE � Abstract�An Image-projective Desktop Varnamala Trainer Indian �.3,00,000 or US $5000) and not easily transportable. (IDVT) called SAKSHAR has been designed to improve the These are important requirements for a system to be used in learning by children through an interactive audio visual fields like education in developing and underdeveloped feedback system. This device uses a projector to render a countries. With this purpose in mind "SAKSHAR: Image- virtual display, which permits production of large interactive projective Desktop Varnamala Trainer (IDVT)" has been ��������������������������������������������is recognized with the help of a Microsoft Kinect Version 2. The entire system is designed. The device has been named SAKSHAR which portable, i.e., it can be projected on any planar surface. Since means "Literacy" in Hindi (an Indian language). the Kinect does not give precise 3D coordinates of points for "Varnamala" is also a Hindi word which stands for complete detecting a touch, a model of recognition of a touch purely set of alphabets. We feel that devices like SAKSHAR will ��������������������������������������������������������������� give a boost to reading skills and improve literacy. not yield accurate results. We have instead modeled the touch SAKSHAR is based on SOI (step-on interface) concept, action by using multiple points along the trajectory of the ��������������������������������������������������������� with which uses the projected screen as a bidirectional interface. the surface. Fitting a curve through these points and analyzing Through this the information is transferred from a robot to the errors is used to make the detection of touch accurate.