Python: the Most Advanced Programming Language for Computer Science Applications
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

An Efficient Way for Statistical Review Using the Rshiny Application
PhUSE EU Connect 2018 Paper AD03 An Efficient Way for Statistical Review Using the RShiny Application Adarsh Nagare, Cytel, Pune, India Sameer Bamnote, Cytel, Pune, India ABSTRACT Statisticians often need to review critical reports before study submissions. Many reports include outputs based on statistical testing or model-based analysis. To ensure the accuracy of these reports, most of the time the Statistician needs to writes independent code. In case of tight timelines, it may not be feasible and quality of review can be impacted. To address this we describe use of an application that can save time for the Statistician. This application was created using open-source software R and Shiny, providing an efficient, time saving solution for review of critical statistical outputs without the need for extensive code writing. The aim is to review results for t-tests, AN(C)OVA, their non-parametric alternatives and model-based analysis which are performed in SAS®. User has flexibility to provide input data in excel, csv or SAS format. User can select the statistical test (or specify the model) as per requirement and statistical outputs will be just a click away. This paper demonstrates the application with a variety of illustrations. INTRODUCTION The authors work with clients from clinical research and FMCG field as Statisticians. As a part of the role we have to deal with programmers routinely to do the desired work (i.e. Tables, Listings and Figures) required for various reports. Most of the time, as a Statistician we need to validate the results for modelling or statistical tests or cross check them by writing independent code to ensure accuracy of the results, prior to the submissions. -

Build It with Nitrogen the Fast-Off-The-Block Erlang Web Framework
Build it with Nitrogen The fast-off-the-block Erlang web framework Lloyd R. Prentice & Jesse Gumm dedicated to: Laurie, love of my life— Lloyd Jackie, my best half — Jesse and to: Rusty Klophaus and other giants of Open Source— LRP & JG Contents I. Frying Pan to Fire5 1. You want me to build what?7 2. Enter the lion’s den9 2.1. The big picture........................ 10 2.2. Install Nitrogen........................ 11 2.3. Lay of the land........................ 13 II. Projects 19 3. nitroBoard I 21 3.1. Plan of attack......................... 21 3.2. Create a new project..................... 23 3.3. Prototype welcome page................... 27 3.4. Anatomy of a page...................... 30 3.5. Anatomy of a route...................... 33 3.6. Anatomy of a template.................... 34 3.7. Elements............................ 35 3.8. Actions............................. 38 3.9. Triggers and Targets..................... 39 3.10. Enough theory........................ 40 i 3.11. Visitors............................ 44 3.12. Styling............................. 64 3.13. Debugging........................... 66 3.14. What you’ve learned..................... 66 3.15. Think and do......................... 68 4. nitroBoard II 69 4.1. Plan of attack......................... 69 4.2. Associates........................... 70 4.3. I am in/I am out....................... 78 4.4. Styling............................. 81 4.5. What you’ve learned..................... 82 4.6. Think and do......................... 82 5. A Simple Login System 83 5.1. Getting Started........................ 83 5.2. Dependencies......................... 84 5.2.1. Rebar Dependency: erlpass ............. 84 5.3. The index page........................ 85 5.4. Creating an account..................... 87 5.4.1. db_login module................... 89 5.5. The login form........................ 91 5.5.1. -

Pexpect Documentation Release 4.8
Pexpect Documentation Release 4.8 Noah Spurrier and contributors Apr 17, 2021 Contents 1 Installation 3 1.1 Requirements...............................................3 2 API Overview 5 2.1 Special EOF and TIMEOUT patterns..................................6 2.2 Find the end of line – CR/LF conventions................................6 2.3 Beware of + and * at the end of patterns.................................7 2.4 Debugging................................................8 2.5 Exceptions................................................8 2.6 Pexpect on Windows...........................................9 3 API documentation 11 3.1 Core pexpect components........................................ 11 3.2 fdpexpect - use pexpect with a file descriptor.............................. 23 3.3 popen_spawn - use pexpect with a piped subprocess.......................... 23 3.4 replwrap - Control read-eval-print-loops................................. 24 3.5 pxssh - control an SSH session...................................... 25 4 Examples 33 5 FAQ 35 6 Common problems 39 6.1 Threads.................................................. 39 6.2 Timing issue with send() and sendline()................................. 39 6.3 Truncated output just before child exits................................. 40 6.4 Controlling SSH on Solaris....................................... 40 6.5 child does not receive full input, emits BEL............................... 40 7 History 41 7.1 Releases................................................. 41 7.2 Moves and forks............................................ -

Ajuba Solutions Version 1.4 COPYRIGHT Copyright © 1998-2000 Ajuba Solutions Inc
• • • • • • Ajuba Solutions Version 1.4 COPYRIGHT Copyright © 1998-2000 Ajuba Solutions Inc. All rights reserved. Information in this document is subject to change without notice. No part of this publication may be reproduced, stored in a retrieval system, or transmitted in any form or by any means electronic or mechanical, including but not limited to photocopying or recording, for any purpose other than the purchaser’s personal use, without the express written permission of Ajuba Solutions Inc. Ajuba Solutions Inc. 2593 Coast Avenue Mountain View, CA 94043 U.S.A http://www.ajubasolutions.com TRADEMARKS TclPro and Ajuba Solutions are trademarks of Ajuba Solutions Inc. Other products and company names not owned by Ajuba Solutions Inc. that appear in this manual may be trademarks of their respective owners. ACKNOWLEDGEMENTS Michael McLennan is the primary developer of [incr Tcl] and [incr Tk]. Jim Ingham and Lee Bernhard handled the Macintosh and Windows ports of [incr Tcl] and [incr Tk]. Mark Ulferts is the primary developer of [incr Widgets], with other contributions from Sue Yockey, John Sigler, Bill Scott, Alfredo Jahn, Bret Schuhmacher, Tako Schotanus, and Kris Raney. Mark Diekhans and Karl Lehenbauer are the primary developers of Extended Tcl (TclX). Don Libes is the primary developer of Expect. TclPro Wrapper incorporates compression code from the Info-ZIP group. There are no extra charges or costs in TclPro due to the use of this code, and the original compression sources are freely available from http://www.cdrom.com/pub/infozip or ftp://ftp.cdrom.com/pub/infozip. NOTE: TclPro is packaged on this CD using Info-ZIP’s compression utility. -

Functional Languages
Functional Programming Languages (FPL) 1. Definitions................................................................... 2 2. Applications ................................................................ 2 3. Examples..................................................................... 3 4. FPL Characteristics:.................................................... 3 5. Lambda calculus (LC)................................................. 4 6. Functions in FPLs ....................................................... 7 7. Modern functional languages...................................... 9 8. Scheme overview...................................................... 11 8.1. Get your own Scheme from MIT...................... 11 8.2. General overview.............................................. 11 8.3. Data Typing ...................................................... 12 8.4. Comments ......................................................... 12 8.5. Recursion Instead of Iteration........................... 13 8.6. Evaluation ......................................................... 14 8.7. Storing and using Scheme code ........................ 14 8.8. Variables ........................................................... 15 8.9. Data types.......................................................... 16 8.10. Arithmetic functions ......................................... 17 8.11. Selection functions............................................ 18 8.12. Iteration............................................................. 23 8.13. Defining functions ........................................... -
A Comprehensive Embedding Approach for Determining Repository Similarity
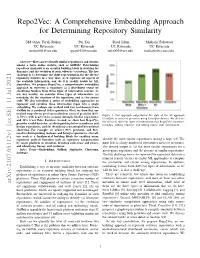
Repo2Vec: A Comprehensive Embedding Approach for Determining Repository Similarity Md Omar Faruk Rokon Pei Yan Risul Islam Michalis Faloutsos UC Riverside UC Riverside UC Riverside UC Riverside [email protected] [email protected] [email protected] [email protected] Abstract—How can we identify similar repositories and clusters among a large online archive, such as GitHub? Determining repository similarity is an essential building block in studying the dynamics and the evolution of such software ecosystems. The key challenge is to determine the right representation for the diverse repository features in a way that: (a) it captures all aspects of the available information, and (b) it is readily usable by ML algorithms. We propose Repo2Vec, a comprehensive embedding approach to represent a repository as a distributed vector by combining features from three types of information sources. As our key novelty, we consider three types of information: (a) metadata, (b) the structure of the repository, and (c) the source code. We also introduce a series of embedding approaches to represent and combine these information types into a single embedding. We evaluate our method with two real datasets from GitHub for a combined 1013 repositories. First, we show that our method outperforms previous methods in terms of precision (93% Figure 1: Our approach outperforms the state of the art approach vs 78%), with nearly twice as many Strongly Similar repositories CrossSim in terms of precision using CrossSim dataset. We also see and 30% fewer False Positives. Second, we show how Repo2Vec the effect of different types of information that Repo2Vec considers: provides a solid basis for: (a) distinguishing between malware and metadata, adding structure, and adding source code information. -
Ejercicio 2 Bottle: Python Web Framework
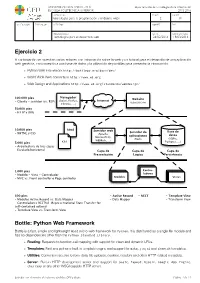
UNIVERSIDAD SAN PABLO - CEU departamento de tecnologías de la información ESCUELA POLITÉCNICA SUPERIOR 2015-2016 ASIGNATURA CURSO GRUPO tecnologías para la programación y el diseño web i 2 01 CALIFICACION EVALUACION APELLIDOS NOMBRE DNI OBSERVACIONES FECHA FECHA ENTREGA Tecnologías para el desarrollo web 24/02/2016 18/03/2016 Ejercicio 2 A continuación se muestran varios enlaces con información sobre la web y un tutorial para el desarrollo de una aplicación web genérica, con conexión a una base de datos y la utilización de plantillas para presentar la información. ‣ Python Web Framework http://bottlepy.org/docs/dev/ ‣ World Wide Web consortium http://www.w3.org ‣ Web Design and Applications http://www.w3.org/standards/webdesign/ Navegador 100.000 pies Website (Safari, Firefox, Internet - Cliente - servidor (vs. P2P) uspceu.com Chrome, ...) 50.000 pies - HTTP y URIs 10.000 pies html Servidor web Servidor de Base de - XHTML y CSS (Apache, aplicaciones datos Microsoft IIS, (Rack) (SQlite, WEBRick, ...) 5.000 pies css Postgres, ...) - Arquitectura de tres capas - Escalado horizontal Capa de Capa de Capa de Presentación Lógica Persistencia 1.000 pies Contro- - Modelo - Vista - Controlador ladores - MVC vs. Front controller o Page controller Modelos Vistas 500 pies - Active Record - REST - Template View - Modelos Active Record vs. Data Mapper - Data Mapper - Transform View - Controladores RESTful (Representational State Transfer for self-contained actions) - Template View vs. Transform View Bottle: Python Web Framework Bottle is a fast, simple and lightweight WSGI micro web-framework for Python. It is distributed as a single file module and has no dependencies other than the Python Standard Library. -

Introduction to Ggplot2
Introduction to ggplot2 Dawn Koffman Office of Population Research Princeton University January 2014 1 Part 1: Concepts and Terminology 2 R Package: ggplot2 Used to produce statistical graphics, author = Hadley Wickham "attempt to take the good things about base and lattice graphics and improve on them with a strong, underlying model " based on The Grammar of Graphics by Leland Wilkinson, 2005 "... describes the meaning of what we do when we construct statistical graphics ... More than a taxonomy ... Computational system based on the underlying mathematics of representing statistical functions of data." - does not limit developer to a set of pre-specified graphics adds some concepts to grammar which allow it to work well with R 3 qplot() ggplot2 provides two ways to produce plot objects: qplot() # quick plot – not covered in this workshop uses some concepts of The Grammar of Graphics, but doesn’t provide full capability and designed to be very similar to plot() and simple to use may make it easy to produce basic graphs but may delay understanding philosophy of ggplot2 ggplot() # grammar of graphics plot – focus of this workshop provides fuller implementation of The Grammar of Graphics may have steeper learning curve but allows much more flexibility when building graphs 4 Grammar Defines Components of Graphics data: in ggplot2, data must be stored as an R data frame coordinate system: describes 2-D space that data is projected onto - for example, Cartesian coordinates, polar coordinates, map projections, ... geoms: describe type of geometric objects that represent data - for example, points, lines, polygons, ... aesthetics: describe visual characteristics that represent data - for example, position, size, color, shape, transparency, fill scales: for each aesthetic, describe how visual characteristic is converted to display values - for example, log scales, color scales, size scales, shape scales, .. -

How to Access Python for Doing Scientific Computing
How to access Python for doing scientific computing1 Hans Petter Langtangen1,2 1Center for Biomedical Computing, Simula Research Laboratory 2Department of Informatics, University of Oslo Mar 23, 2015 A comprehensive eco system for scientific computing with Python used to be quite a challenge to install on a computer, especially for newcomers. This problem is more or less solved today. There are several options for getting easy access to Python and the most important packages for scientific computations, so the biggest issue for a newcomer is to make a proper choice. An overview of the possibilities together with my own recommendations appears next. Contents 1 Required software2 2 Installing software on your laptop: Mac OS X and Windows3 3 Anaconda and Spyder4 3.1 Spyder on Mac............................4 3.2 Installation of additional packages.................5 3.3 Installing SciTools on Mac......................5 3.4 Installing SciTools on Windows...................5 4 VMWare Fusion virtual machine5 4.1 Installing Ubuntu...........................6 4.2 Installing software on Ubuntu....................7 4.3 File sharing..............................7 5 Dual boot on Windows8 6 Vagrant virtual machine9 1The material in this document is taken from a chapter in the book A Primer on Scientific Programming with Python, 4th edition, by the same author, published by Springer, 2014. 7 How to write and run a Python program9 7.1 The need for a text editor......................9 7.2 Spyder................................. 10 7.3 Text editors.............................. 10 7.4 Terminal windows.......................... 11 7.5 Using a plain text editor and a terminal window......... 12 8 The SageMathCloud and Wakari web services 12 8.1 Basic intro to SageMathCloud................... -

WEB2PY Enterprise Web Framework (2Nd Edition)
WEB2PY Enterprise Web Framework / 2nd Ed. Massimo Di Pierro Copyright ©2009 by Massimo Di Pierro. All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, electronic, mechanical, photocopying, recording, scanning, or otherwise, except as permitted under Section 107 or 108 of the 1976 United States Copyright Act, without either the prior written permission of the Publisher, or authorization through payment of the appropriate per-copy fee to the Copyright Clearance Center, Inc., 222 Rosewood Drive, Danvers, MA 01923, (978) 750-8400, fax (978) 646-8600, or on the web at www.copyright.com. Requests to the Copyright owner for permission should be addressed to: Massimo Di Pierro School of Computing DePaul University 243 S Wabash Ave Chicago, IL 60604 (USA) Email: [email protected] Limit of Liability/Disclaimer of Warranty: While the publisher and author have used their best efforts in preparing this book, they make no representations or warranties with respect to the accuracy or completeness of the contents of this book and specifically disclaim any implied warranties of merchantability or fitness for a particular purpose. No warranty may be created ore extended by sales representatives or written sales materials. The advice and strategies contained herein may not be suitable for your situation. You should consult with a professional where appropriate. Neither the publisher nor author shall be liable for any loss of profit or any other commercial damages, including but not limited to special, incidental, consequential, or other damages. Library of Congress Cataloging-in-Publication Data: WEB2PY: Enterprise Web Framework Printed in the United States of America. -

Making Story from System Logs with Elastic Stack
SANOG36 18 - 21 January, 2021 Making story from system logs with stack [email protected] https://imtiazrahman.com https://github.com/imtiazrahman Logs syslog Audit SNMP NETFLOW http METRIC DNS ids What is Elastic Stack ? Store, Analyze Ingest User Interface a full-text based, distributed NoSQL database. Written in Java, built on Apache Lucene Commonly used for log analytics, full-text search, security intelligence, business analytics, and operational intelligence use cases. Use REST API (GET, PUT, POST, and DELETE ) for storing and searching data Data is stored as documents (rows in relational database) Data is separated into fields (columns in relational database) Relational Database Elasticsearch Database Index Table Type Row/Record Document Column Name Field Terminology Cluster: A cluster consists of one or more nodes which share the same cluster name. Node: A node is a running instance of elasticsearch which belongs to a cluster. Terminology Index: Collection of documents Shard: An index is split into elements known as shards that are distributed across multiple nodes. There are two types of shard, Primary and replica. By default elasticsearch creates 1 primary shard and 1 replica shard for each index. Terminology Shard 1 Replica 1 Replica 2 Shard 2 Node 1 Node 2 cluster Terminology Documents { • Indices hold documents in "_index": "netflow-2020.10.08", "_type": "_doc", serialized JSON objects "_id": "ZwkiB3UBULotwSOX3Bdb", "_version": 1, • 1 document = 1 log entry "_score": null, "_source": { • Contains "field : value" pairs -

Regression Models by Gretl and R Statistical Packages for Data Analysis in Marine Geology Polina Lemenkova
Regression Models by Gretl and R Statistical Packages for Data Analysis in Marine Geology Polina Lemenkova To cite this version: Polina Lemenkova. Regression Models by Gretl and R Statistical Packages for Data Analysis in Marine Geology. International Journal of Environmental Trends (IJENT), 2019, 3 (1), pp.39 - 59. hal-02163671 HAL Id: hal-02163671 https://hal.archives-ouvertes.fr/hal-02163671 Submitted on 3 Jul 2019 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Distributed under a Creative Commons Attribution| 4.0 International License International Journal of Environmental Trends (IJENT) 2019: 3 (1),39-59 ISSN: 2602-4160 Research Article REGRESSION MODELS BY GRETL AND R STATISTICAL PACKAGES FOR DATA ANALYSIS IN MARINE GEOLOGY Polina Lemenkova 1* 1 ORCID ID number: 0000-0002-5759-1089. Ocean University of China, College of Marine Geo-sciences. 238 Songling Rd., 266100, Qingdao, Shandong, P. R. C. Tel.: +86-1768-554-1605. Abstract Received 3 May 2018 Gretl and R statistical libraries enables to perform data analysis using various algorithms, modules and functions. The case study of this research consists in geospatial analysis of Accepted the Mariana Trench, a hadal trench located in the Pacific Ocean.