Lecture 15 Notes Binary Search Trees
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Adversarial Search
Adversarial Search In which we examine the problems that arise when we try to plan ahead in a world where other agents are planning against us. Outline 1. Games 2. Optimal Decisions in Games 3. Alpha-Beta Pruning 4. Imperfect, Real-Time Decisions 5. Games that include an Element of Chance 6. State-of-the-Art Game Programs 7. Summary 2 Search Strategies for Games • Difference to general search problems deterministic random – Imperfect Information: opponent not deterministic perfect Checkers, Backgammon, – Time: approximate algorithms information Chess, Go Monopoly incomplete Bridge, Poker, ? information Scrabble • Early fundamental results – Algorithm for perfect game von Neumann (1944) • Our terminology: – Approximation through – deterministic, fully accessible evaluation information Zuse (1945), Shannon (1950) Games 3 Games as Search Problems • Justification: Games are • Games as playground for search problems with an serious research opponent • How can we determine the • Imperfection through actions best next step/action? of opponent: possible results... – Cutting branches („pruning“) • Games hard to solve; – Evaluation functions for exhaustive: approximation of utility – Average branching factor function chess: 35 – ≈ 50 steps per player ➞ 10154 nodes in search tree – But “Only” 1040 allowed positions Games 4 Search Problem • 2-player games • Search problem – Player MAX – Initial state – Player MIN • Board, positions, first player – MAX moves first; players – Successor function then take turns • Lists of (move,state)-pairs – Goal test -

Balanced Trees Part One
Balanced Trees Part One Balanced Trees ● Balanced search trees are among the most useful and versatile data structures. ● Many programming languages ship with a balanced tree library. ● C++: std::map / std::set ● Java: TreeMap / TreeSet ● Many advanced data structures are layered on top of balanced trees. ● We’ll see several later in the quarter! Where We're Going ● B-Trees (Today) ● A simple type of balanced tree developed for block storage. ● Red/Black Trees (Today/Thursday) ● The canonical balanced binary search tree. ● Augmented Search Trees (Thursday) ● Adding extra information to balanced trees to supercharge the data structure. Outline for Today ● BST Review ● Refresher on basic BST concepts and runtimes. ● Overview of Red/Black Trees ● What we're building toward. ● B-Trees and 2-3-4 Trees ● Simple balanced trees, in depth. ● Intuiting Red/Black Trees ● A much better feel for red/black trees. A Quick BST Review Binary Search Trees ● A binary search tree is a binary tree with 9 the following properties: 5 13 ● Each node in the BST stores a key, and 1 6 10 14 optionally, some auxiliary information. 3 7 11 15 ● The key of every node in a BST is strictly greater than all keys 2 4 8 12 to its left and strictly smaller than all keys to its right. Binary Search Trees ● The height of a binary search tree is the 9 length of the longest path from the root to a 5 13 leaf, measured in the number of edges. 1 6 10 14 ● A tree with one node has height 0. -

Trees: Binary Search Trees
COMP2012H Spring 2014 Dekai Wu Binary Trees & Binary Search Trees (data structures for the dictionary ADT) Outline } Binary tree terminology } Tree traversals: preorder, inorder and postorder } Dictionary and binary search tree } Binary search tree operations } Search } min and max } Successor } Insertion } Deletion } Tree balancing issue COMP2012H (BST) Binary Tree Terminology } Go to the supplementary notes COMP2012H (BST) Linked Representation of Binary Trees } The degree of a node is the number of children it has. The degree of a tree is the maximum of its element degree. } In a binary tree, the tree degree is two data } Each node has two links left right } one to the left child of the node } one to the right child of the node Left child Right child } if no child node exists for a node, the link is set to NULL root 32 32 79 42 79 42 / 13 95 16 13 95 16 / / / / / / COMP2012H (BST) Binary Trees as Recursive Data Structures } A binary tree is either empty … Anchor or } Consists of a node called the root } Root points to two disjoint binary (sub)trees Inductive step left and right (sub)tree r left right subtree subtree COMP2012H (BST) Tree Traversal is Also Recursive (Preorder example) If the binary tree is empty then Anchor do nothing Else N: Visit the root, process data L: Traverse the left subtree Inductive/Recursive step R: Traverse the right subtree COMP2012H (BST) 3 Types of Tree Traversal } If the pointer to the node is not NULL: } Preorder: Node, Left subtree, Right subtree } Inorder: Left subtree, Node, Right subtree Inductive/Recursive step } Postorder: Left subtree, Right subtree, Node template <class T> void BinaryTree<T>::InOrder( void(*Visit)(BinaryTreeNode<T> *u), template<class T> BinaryTreeNode<T> *t) void BinaryTree<T>::PreOrder( {// Inorder traversal. -

Q-Tree: a Multi-Attribute Based Range Query Solution for Tele-Immersive Framework
Q-Tree: A Multi-Attribute Based Range Query Solution for Tele-Immersive Framework Md Ahsan Arefin, Md Yusuf Sarwar Uddin, Indranil Gupta, Klara Nahrstedt Department of Computer Science University of Illinois at Urbana Champaign Illinois, USA {marefin2, mduddin2, indy, klara}@illinois.edu Abstract given in a high level description which are transformed into multi-attribute composite range queries. Some of the Users and administrators of large distributed systems are examples include “which site is highly congested?”, “which frequently in need of monitoring and management of its components are not working properly?” etc. To answer the various components, data items and resources. Though there first one, the query is transformed into a multi-attribute exist several distributed query and aggregation systems, the composite range query with constrains (range of values) on clustered structure of tele-immersive interactive frameworks CPU utilization, memory overhead, stream rate, bandwidth and their time-sensitive nature and application requirements utilization, delay and packet loss rate. The later one can represent a new class of systems which poses different chal- be answered by constructing a multi-attribute range query lenges on this distributed search. Multi-attribute composite with constrains on static and dynamic characteristics of range queries are one of the key features in this class. those components. Queries can also be made by defining Queries are given in high level descriptions and then trans- different multi-attribute ranges explicitly. Another mention- formed into multi-attribute composite range queries. Design- able property of such systems is that the number of site is ing such a query engine with minimum traffic overhead, low limited due to limited display space and limited interactions, service latency, and with static and dynamic nature of large but the number of data items to store and manage can datasets, is a challenging task. -

Artificial Intelligence Spring 2019 Homework 2: Adversarial Search
Artificial Intelligence Spring 2019 Homework 2: Adversarial Search PROGRAMMING In this assignment, you will create an adversarial search agent to play the 2048-puzzle game. A demo of the game is available here: gabrielecirulli.github.io/2048. I. 2048 As A Two-Player Game II. Choosing a Search Algorithm: Expectiminimax III. Using The Skeleton Code IV. What You Need To Submit V. Important Information VI. Before You Submit I. 2048 As A Two-Player Game 2048 is played on a 4×4 grid with numbered tiles which can slide up, down, left, or right. This game can be modeled as a two player game, in which the computer AI generates a 2- or 4-tile placed randomly on the board, and the player then selects a direction to move the tiles. Note that the tiles move until they either (1) collide with another tile, or (2) collide with the edge of the grid. If two tiles of the same number collide in a move, they merge into a single tile valued at the sum of the two originals. The resulting tile cannot merge with another tile again in the same move. Usually, each role in a two-player games has a similar set of moves to choose from, and similar objectives (e.g. chess). In 2048 however, the player roles are inherently asymmetric, as the Computer AI places tiles and the Player moves them. Adversarial search can still be applied! Using your previous experience with objects, states, nodes, functions, and implicit or explicit search trees, along with our skeleton code, focus on optimizing your player algorithm to solve 2048 as efficiently and consistently as possible. -
AVL Trees, Page 1 ' $
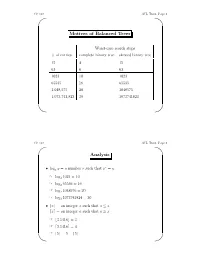
CS 310 AVL Trees, Page 1 ' $ Motives of Balanced Trees Worst-case search steps #ofentries complete binary tree skewed binary tree 15 4 15 63 6 63 1023 10 1023 65535 16 65535 1,048,575 20 1048575 1,073,741,823 30 1073741823 & % CS 310 AVL Trees, Page 2 ' $ Analysis r • logx y =anumberr such that x = y ☞ log2 1024 = 10 ☞ log2 65536 = 16 ☞ log2 1048576 = 20 ☞ log2 1073741824 = 30 •bxc = an integer a such that a ≤ x dxe = an integer a such that a ≥ x ☞ b3.1416c =3 ☞ d3.1416e =4 ☞ b5c =5=d5e & % CS 310 AVL Trees, Page 3 ' $ • If a binary search tree of N nodes happens to be complete, then a search in the tree requires at most b c log2 N +1 steps. • Big-O notation: We say f(x)=O(g(x)) if f(x)isbounded by c · g(x), where c is a constant, for sufficiently large x. ☞ x2 +11x − 30 = O(x2) (consider c =2,x ≥ 6) ☞ x100 + x50 +2x = O(2x) • If a BST happens to be complete, then a search in the tree requires O(log2 N)steps. • In a linked list of N nodes, a search requires O(N)steps. & % CS 310 AVL Trees, Page 4 ' $ AVL Trees • A balanced binary search tree structure proposed by Adelson, Velksii and Landis in 1962. • In an AVL tree of N nodes, every searching, deletion or insertion operation requires only O(log2 N)steps. • AVL tree searching is exactly the same as that of the binary search tree. & % CS 310 AVL Trees, Page 5 ' $ Definition • An empty tree is balanced. -

7. Hierarchies & Trees Visualizing Topological Relations
7. Hierarchies & Trees Visualizing topological relations Vorlesung „Informationsvisualisierung” Prof. Dr. Andreas Butz, WS 2011/12 Konzept und Basis für Folien: Thorsten Büring LMU München – Medieninformatik – Andreas Butz – Informationsvisualisierung – WS2011/12 Folie 1 Outline • Hierarchical data and tree representations • 2D Node-link diagrams – Hyperbolic Tree Browser – SpaceTree – Cheops – Degree of interest tree – 3D Node-link diagrams • Enclosure – Treemap – Ordererd Treemaps – Various examples – Voronoi treemap – 3D Treemaps • Circular visualizations • Space-filling node-link diagram LMU München – Medieninformatik – Andreas Butz – Informationsvisualisierung – WS2011/12 Folie 2 Hierarchical Data • Card et al. 1999: data repository in which data cases are related to subcases • Many data collections have an inherent hierarchical organization – Organizational Charts – Websites (approximately hierarchical) Yee et al. 2001 – File system – Family tree – OO programming • Hierarchies are usually represented as tree visual structures • Trees tend to be easier to lay out and interpret than networks (e.g. no cycles) • But: as shown in the example, networks may in some cases be visualized as a tree LMU München – Medieninformatik – Andreas Butz – Informationsvisualisierung – WS2011/12 Folie 3 Tree Representations • Two kinds of representations • Node-link diagram (see previous lecture): represent connections as edges between vertices (data cases) http://www.icann.org • Enclosure: space-filling approaches by visually nesting the hierarchy LMU -

Best-First and Depth-First Minimax Search in Practice
Best-First and Depth-First Minimax Search in Practice Aske Plaat, Erasmus University, [email protected] Jonathan Schaeffer, University of Alberta, [email protected] Wim Pijls, Erasmus University, [email protected] Arie de Bruin, Erasmus University, [email protected] Erasmus University, University of Alberta, Department of Computer Science, Department of Computing Science, Room H4-31, P.O. Box 1738, 615 General Services Building, 3000 DR Rotterdam, Edmonton, Alberta, The Netherlands Canada T6G 2H1 Abstract Most practitioners use a variant of the Alpha-Beta algorithm, a simple depth-®rst pro- cedure, for searching minimax trees. SSS*, with its best-®rst search strategy, reportedly offers the potential for more ef®cient search. However, the complex formulation of the al- gorithm and its alleged excessive memory requirements preclude its use in practice. For two decades, the search ef®ciency of ªsmartº best-®rst SSS* has cast doubt on the effectiveness of ªdumbº depth-®rst Alpha-Beta. This paper presents a simple framework for calling Alpha-Beta that allows us to create a variety of algorithms, including SSS* and DUAL*. In effect, we formulate a best-®rst algorithm using depth-®rst search. Expressed in this framework SSS* is just a special case of Alpha-Beta, solving all of the perceived drawbacks of the algorithm. In practice, Alpha-Beta variants typically evaluate less nodes than SSS*. A new instance of this framework, MTD(ƒ), out-performs SSS* and NegaScout, the Alpha-Beta variant of choice by practitioners. 1 Introduction Game playing is one of the classic problems of arti®cial intelligence. -

General Branch and Bound, and Its Relation to A* and AO*
ARTIFICIAL INTELLIGENCE 29 General Branch and Bound, and Its Relation to A* and AO* Dana S. Nau, Vipin Kumar and Laveen Kanal* Laboratory for Pattern Analysis, Computer Science Department, University of Maryland College Park, MD 20742, U.S.A. Recommended by Erik Sandewall ABSTRACT Branch and Bound (B&B) is a problem-solving technique which is widely used for various problems encountered in operations research and combinatorial mathematics. Various heuristic search pro- cedures used in artificial intelligence (AI) are considered to be related to B&B procedures. However, in the absence of any generally accepted terminology for B&B procedures, there have been widely differing opinions regarding the relationships between these procedures and B &B. This paper presents a formulation of B&B general enough to include previous formulations as special cases, and shows how two well-known AI search procedures (A* and AO*) are special cases o,f this general formulation. 1. Introduction A wide class of problems arising in operations research, decision making and artificial intelligence can be (abstractly) stated in the following form: Given a (possibly infinite) discrete set X and a real-valued objective function F whose domain is X, find an optimal element x* E X such that F(x*) = min{F(x) I x ~ X}) Unless there is enough problem-specific knowledge available to obtain the optimum element of the set in some straightforward manner, the only course available may be to enumerate some or all of the elements of X until an optimal element is found. However, the sets X and {F(x) [ x E X} are usually tThis work was supported by NSF Grant ENG-7822159 to the Laboratory for Pattern Analysis at the University of Maryland. -

Trees, Binary Search Trees, Heaps & Applications Dr. Chris Bourke
Trees Trees, Binary Search Trees, Heaps & Applications Dr. Chris Bourke Department of Computer Science & Engineering University of Nebraska|Lincoln Lincoln, NE 68588, USA [email protected] http://cse.unl.edu/~cbourke 2015/01/31 21:05:31 Abstract These are lecture notes used in CSCE 156 (Computer Science II), CSCE 235 (Dis- crete Structures) and CSCE 310 (Data Structures & Algorithms) at the University of Nebraska|Lincoln. This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License 1 Contents I Trees4 1 Introduction4 2 Definitions & Terminology5 3 Tree Traversal7 3.1 Preorder Traversal................................7 3.2 Inorder Traversal.................................7 3.3 Postorder Traversal................................7 3.4 Breadth-First Search Traversal..........................8 3.5 Implementations & Data Structures.......................8 3.5.1 Preorder Implementations........................8 3.5.2 Inorder Implementation.........................9 3.5.3 Postorder Implementation........................ 10 3.5.4 BFS Implementation........................... 12 3.5.5 Tree Walk Implementations....................... 12 3.6 Operations..................................... 12 4 Binary Search Trees 14 4.1 Basic Operations................................. 15 5 Balanced Binary Search Trees 17 5.1 2-3 Trees...................................... 17 5.2 AVL Trees..................................... 17 5.3 Red-Black Trees.................................. 19 6 Optimal Binary Search Trees 19 7 Heaps 19 -

Parallel Technique for the Metaheuristic Algorithms Using Devoted Local Search and Manipulating the Solutions Space
applied sciences Article Parallel Technique for the Metaheuristic Algorithms Using Devoted Local Search and Manipulating the Solutions Space Dawid Połap 1,* ID , Karolina K˛esik 1, Marcin Wo´zniak 1 ID and Robertas Damaševiˇcius 2 ID 1 Institute of Mathematics, Silesian University of Technology, Kaszubska 23, 44-100 Gliwice, Poland; [email protected] (K.K.); [email protected] (M.W.) 2 Department of Software Engineering, Kaunas University of Technology, Studentu 50, LT-51368, Kaunas, Lithuania; [email protected] * Correspondence: [email protected] Received: 16 December 2017; Accepted: 13 February 2018 ; Published: 16 February 2018 Abstract: The increasing exploration of alternative methods for solving optimization problems causes that parallelization and modification of the existing algorithms are necessary. Obtaining the right solution using the meta-heuristic algorithm may require long operating time or a large number of iterations or individuals in a population. The higher the number, the longer the operation time. In order to minimize not only the time, but also the value of the parameters we suggest three proposition to increase the efficiency of classical methods. The first one is to use the method of searching through the neighborhood in order to minimize the solution space exploration. Moreover, task distribution between threads and CPU cores can affect the speed of the algorithm and therefore make it work more efficiently. The second proposition involves manipulating the solutions space to minimize the number of calculations. In addition, the third proposition is the combination of the previous two. All propositions has been described, tested and analyzed due to the use of various test functions. -

Backtracking Search (Csps) ■Chapter 5 5.3 Is About Local Search Which Is a Very Useful Idea but We Won’T Cover It in Class
CSC384: Intro to Artificial Intelligence Backtracking Search (CSPs) ■Chapter 5 5.3 is about local search which is a very useful idea but we won’t cover it in class. 1 Hojjat Ghaderi, University of Toronto Constraint Satisfaction Problems ● The search algorithms we discussed so far had no knowledge of the states representation (black box). ■ For each problem we had to design a new state representation (and embed in it the sub-routines we pass to the search algorithms). ● Instead we can have a general state representation that works well for many different problems. ● We can build then specialized search algorithms that operate efficiently on this general state representation. ● We call the class of problems that can be represented with this specialized representation CSPs---Constraint Satisfaction Problems. ● Techniques for solving CSPs find more practical applications in industry than most other areas of AI. 2 Hojjat Ghaderi, University of Toronto Constraint Satisfaction Problems ●The idea: represent states as a vector of feature values. We have ■ k-features (or variables) ■ Each feature takes a value. Domain of possible values for the variables: height = {short, average, tall}, weight = {light, average, heavy}. ●In CSPs, the problem is to search for a set of values for the features (variables) so that the values satisfy some conditions (constraints). ■ i.e., a goal state specified as conditions on the vector of feature values. 3 Hojjat Ghaderi, University of Toronto Constraint Satisfaction Problems ●Sudoku: ■ 81 variables, each representing the value of a cell. ■ Values: a fixed value for those cells that are already filled in, the values {1-9} for those cells that are empty.