Icmc 2021 List of Accepted Papers
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Pdfs/Ent Malaysia.Pdf Bagozzi, R., Baumgartner, H., and Yi, Y
Editorial Board Balakrishnan Parasuraman Universiti Malaysia Sabah, Malaysia Benjamin James. Inyang University of Calabar, Nigeria Cyril Foropon University of Manitoba, Canada David H. Kent Golden Gate University, USA Donald Henry Ah Pak Xi’an Jiaotong-Liverpool University, China Fulford Richard Edith Cowan University, Australia Goi Chai Lee Curtin University of Technology, Malaysia Hafizi Muhamad Ali Universiti Utara Malaysia, Malaysia Kevin James Daly University of Western Sydney, Australia K. G. Viswanadhan NSS College of Engineering, India Lisa Wang Canadian Center of Science and Education, Canada Mahdi Salehi Zanjan University, Iran Matthew M.Chew Hong Kong Baptist University, Hong Kong Muhammad Aslam Khan HITEC University Taxila, Pakistan Muhammad Madi Bin Abdullah Universiti Teknologi Malaysia, Malaysia Roberto Bergami Vitoria University, Australia Sam C. Okoroafo University of Toledo, USA Sathya Swaroop Debasish Fakir Mohan University, India Tobias Basse University of Applied Sciences, Germany Wen-Hsien Tsai National Central University, TAIWAN International Journal of Business and Management October, 2009 Contents The Impact of the Marketing Activities of Family Owned Businesses on Consumer Purchase Intentions 3 Sam C. Okoroafo & Anthony Koh The Review of Empirical Researches on IT Investment Announcements on the Market Value of Firms 14 Lu Zhang & Jinghua Huang The Value Relevance of Book Values, Earnings and Cash Flows: Evidence from Korea 28 Gee-Jung, Kwon The Distinguishing Background, the Path and the Pattern--Analysis on -
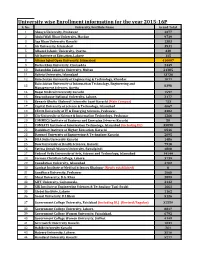
University Wise Enrollment Information for the Year 2015-16P S
University wise Enrollment information for the year 2015-16P S. No. University/Institute Name Grand Total 1 Abasyn University, Peshawar 4377 2 Abdul Wali Khan University, Mardan 9739 3 Aga Khan University Karachi 1383 4 Air University, Islamabad 3531 5 Alhamd Islamic University, Quetta. 338 6 Ali Institute of Education, Lahore 115 8 Allama Iqbal Open University, Islamabad 416607 9 Bacha Khan University, Charsadda 2449 10 Bahauddin Zakariya University, Multan 21385 11 Bahria University, Islamabad 13736 12 Balochistan University of Engineering & Technology, Khuzdar 1071 Balochistan University of Information Technology, Engineering and 13 8398 Management Sciences, Quetta 14 Baqai Medical University Karachi 1597 15 Beaconhouse National University, Lahore. 2177 16 Benazir Bhutto Shaheed University Lyari Karachi (Main Campus) 753 17 Capital University of Science & Technology, Islamabad 4067 18 CECOS University of IT & Emerging Sciences, Peshawar. 3382 19 City University of Science & Information Technology, Peshawar 1266 20 COMMECS Institute of Business and Emerging Sciences Karachi 50 21 COMSATS Institute of Information Technology, Islamabad (including DL) 35890 22 Dadabhoy Institute of Higher Education, Karachi 6546 23 Dawood University of Engineering & Technology Karachi 2095 24 DHA Suffa University Karachi 1486 25 Dow University of Health Sciences, Karachi 7918 26 Fatima Jinnah Women University, Rawalpindi 4808 27 Federal Urdu University of Arts, Science and Technology, Islamabad 14144 28 Forman Christian College, Lahore. 3739 29 Foundation University, Islamabad 4702 30 Gambat Institute of Medical Sciences Khairpur (Newly established) 0 31 Gandhara University, Peshawar 1068 32 Ghazi University, D.G. Khan 2899 33 GIFT University, Gujranwala. 2132 34 GIK Institute of Engineering Sciences & Technology Topi-Swabi 1661 35 Global Institute, Lahore 1162 36 Gomal University, D.I.Khan 5126 37 Government College University, Faislabad (including DL) (Revised/Regular) 32559 38 Government College University, Lahore. -

Sports Directory for Public and Private Universities Public Sector Universities Federal
Sports Directory for Public and Private Universities Public Sector Universities Federal: 1. Allama Iqbal Open University, Islamabad Name of Sports Officer: there is no sports officer in said university as per information received from university. Designation: Office Phone No: Celll No: E-mail: Mailing Address: 2. Bahria University, Islamabad Name of Sports Officer: Malik Bashir Ahmad Designation: Dy. Director Sports Office Phone No: 051-9261279 Cell No: 0331-2221333 E-mail: [email protected] Mailing Address: Bahria University, Naval Complex, E-8, Shangrila Road, Islamabad Name of Sports Officer: Mirza Tasleem Designation: Sports Officer Office Phone No: 051-9261279 Cell No: E-mail: [email protected] Mailing Address: as above 3. International Islamic University, Islamabad Name of Sports Officer: Muhammad Khalid Chaudhry Designation: Sports Officer Office Phone No: 051-9019656 Cell No: 0333-5120533 E-mail: [email protected] Mailing Address: Sports Officer, IIUI, H-12, Islamabad 4. National University of Modern Languages (NUML), Islamabad Name of Sports Officer: No Sports Officer Designation: Office Phone No: 051-9257646 Cell No: E-mail: Mailing Address: Sector H-9, Islamabad Name of Sports Officer: Saeed Ahmed Designation: Demonstrator Office Phone No: 051-9257646 Cell No: 0335-5794434 E-mail: [email protected] Mailing Address: as above 5. Quaid-e-Azam University, Islamabad Name of Sports Officer: M. Safdar Ali Designation: Dy. Director Sports Office Phone No: 051-90642173 Cell No: 0333-6359863 E-mail: [email protected] Mailing Address: Quaid-e-Azam University, Islamabad 6. National University of Sciences and Technology, Islamabad Name of Sports Officer: Mrs. -

Erik Cambria Dipankar Das Sivaji Bandyopadhyay Antonio Feraco Editors a Practical Guide to Sentiment Analysis Socio-Affective Computing
Socio-Affective Computing 5 Erik Cambria Dipankar Das Sivaji Bandyopadhyay Antonio Feraco Editors A Practical Guide to Sentiment Analysis Socio-Affective Computing Volume 5 Series Editor Amir Hussain, University of Stirling, Stirling, UK Co-Editor Erik Cambria, Nanyang Technological University, Singapore This exciting Book Series aims to publish state-of-the-art research on socially intelligent, affective and multimodal human-machine interaction and systems. It will emphasize the role of affect in social interactions and the humanistic side of affective computing by promoting publications at the cross-roads between engineering and human sciences (including biological, social and cultural aspects of human life). Three broad domains of social and affective computing will be covered by the book series: (1) social computing, (2) affective computing, and (3) interplay of the first two domains (for example, augmenting social interaction through affective computing). Examples of the first domain will include but not limited to: all types of social interactions that contribute to the meaning, interest and richness of our daily life, for example, information produced by a group of people used to provide or enhance the functioning of a system. Examples of the second domain will include, but not limited to: computational and psychological models of emotions, bodily manifestations of affect (facial expressions, posture, behavior, physiology), and affective interfaces and applications (dialogue systems, games, learning etc.). This series will publish -

Wrinkling Prediction of Aluminum 5456-H116 Sheet Metals Under Uni-Axial and Bi-Axial Loading Through FE Simulations
INTERNATIONAL JOURNAL OF MULTIDISCIPLINARY SCIENCES AND ENGINEERING , VOL . 2, NO. 5, AUGUST 2011 ` Wrinkling Prediction of Aluminum 5456-H116 sheet Metals under Uni-Axial and Bi-Axial Loading through FE Simulations Amer Sattar 1 and Irfan A. Manarvi 2 1,2 Department of Mechanical Engineering, HITEC University, Taxila, Pakistan Abstract — Wrinkling is one of the most undesirable defects in properties of thin sheets are different from the bulk materials, forming processes, especially when dealing with thin sheets. the fact which has come to limelight due to better measuring Methods have to be devised to control the extent of damage. This tools now available to engineers. The miniaturization of the defect if left un-attended can cause irretrievable loss. Remedial forming geometry causes the so called “scaling effect”, which measures include proper constraining of the thin sheet as well as leads to a different material behaviour in the micro scale appropriate loading techniques.FEM software can be effectively used not only to predict the extent of damage, but damage control compared to the macro scale [8]. Thus it has become measures can also be simulated to suggest appropriate action to imperative to study material properties and their behavior be taken at forming stage. This would drastically cut the cost when small dimensions are encountered during manufacturing incurred to remove the “Wrinkles” at later stage. Removal of this processes. In this paper focus is on thin sheet of .2mm defect after the forming process may be not only expensive but thickness. There are likely chances that deformation would sometimes impossible, as has been observed in die making. -

Molybdenum and Cobalt Silicide Field Emitter Arrays
Experimental characterization of gasoline sprays under highly evaporating conditions Muhammad Mahabat Khan 1,2 ,3*, Nadeem Ahmed Sheikh 3, Azfar Khalid 1, Waqas Akbar Lughmani1 1 Department of Mechanical Engineering, Capital University of Science and Technology, Islamabad, Pakistan 2 Laboratoire de Mécanique des Fluides et d’Acoustique,, Ecole Centrale de Lyon, France 3 Department of Mechanical Engineering, HITEC University, Taxila, Pakistan * Corresponding Author email: [email protected] -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Abstract An experimental investigation of multistream gasoline sprays under highly evaporating condi- tions is carried out in this paper. Temperature increase of fuel and low engine pressure could lead to flash boiling. The spray shape is normally modified significantly under flash boiling conditions. The spray plumes expansion along with reduction in the axial momentum causes the jets to merge and creates a low-pressure area below the injector’s nozzle. These effects initiate the collapse of spray cone and lead to the formation of a single jet plume or a big cluster like structure. The collapsing sprays reduces exposed surface and therefore they last longer and subsequently penetrate more. Spray plume momentum increase, jet plume reduction and spray target widening could delay or prevent the closure condition and limit the penetration (delayed formation of the cluster promotes evaporation). These spray characteristics are investigated experimentally using shadowgraphy, for five and six hole injectors, under various boundary conditions. Six hole injectors produce more col- lapsing sprays in comparison to five hole injector due to enhanced jet to jet interactions. The spray collapse tendency reduces with increase in injection pressure due high axial momentum of spray plumes. -

Contemporary Issues Relating to Labour Relations and Human Resources Practices in the Lumber Industry in Quebec
Global Journal of Management And Business Research Volume 11 Issue 1 Version 1.0 February 2011 Type: Double Blind Peer Reviewed International Research Journal Publisher: Global Journals Inc. (USA) ISSN: 0975-5853 Analyzing the Terrorist Activities and Their Implications in Pakistan through Datamining By Shan Majeed Khan, Dr. Irfan Manarvi HITEC University, Taxila Abstract- the events of September 11, 2001 changed the global political scenario fundamentally. The U.S. traced the terrorist outrages in New York and Washington to the Al-Qaeda and the Taliban regime in Afghanistan. As a result, the U.S. declared war against international Terrorism, targeting Afghanistan, for which Pakistan's support was imperative. The cooperation with the U.S. required withdrawing support to the Taliban and start crackdown on the militant Jihadi and sectarian outfits, which had close links with the Taliban and Al-Qaeda, for which Pakistan had to pay a high price. In 2008, Suicide Attacks in Pakistan reached an unprecedented level in the history of modern terrorism. It has been the scene of horrific acts of terrorist violence, and suicide bombings in different areas of Pakistan most notably in NWFP and FATA. The deteriorating law and order situation in the NWFP and FATA resulted in many deaths and casualties of the security forces and civilians. Keywords: Pakistan, War on Terror, Terrorism, Civilian, Suicide Bombing, Federally Administered Tribal Areas. Classification: GJMBR-A FOR Classification: 080109 Contemporary Issues Relating to Labour Relations and Human Resources Practices in the Lumber Industry in Quebec Strictly as per the compliance and regulations of: © 2011 Shan Majeed Khan, Dr. -

Proceedings of the 46Th Annual Meeting of The
Coling 2010 23rd International Conference on Computational Linguistics Proceedings of the 1st Workshop on South and southeast Asian Natural Language Processing 24 August 2010 Beijing International Convention Center Produced by Chinese Information Processing Society of China All rights reserved for Coling 2010 CD production. To order the CD of Coling 2010 and its Workshop Proceedings, please contact: Chinese Information Processing Society of China No.4, Southern Fourth Street Haidian District, Beijing, 100190 China Tel: +86-010-62562916 Fax: +86-010-62562916 [email protected] ii Preface Welcome to the Coling Workshop on South and Southeast Asian Natural Language Processing (WSSANLP). South Asia comprises of the countries- Afghanistan, Bangladesh, Bhutan, India, Maldives, Nepal, Pakistan and Sri Lanka. Southeast Asia, on the other hand, consists of Brunei, Burma, Cambodia, East Timor, Indonesia, Laos, Malaysia, Philippines, Singapore, Thailand and Vietnam. There thousands of languages that belong to different language families like Indo-Aryan, Indo- Iranian, Dravidian, Sino-Tibetan, Austro-Asiatic, Kradai, Hmong-Mien, etc. In terms of population, South Asia and Southeast Asia represent 34.94 percent of the total population of the world. Some of the languages of these regions have a large number of native speakers: Hindi (5th largest according to number of its native speakers), Bengali (6th), Punjabi (12th), Tamil (18th), Urdu (20th), etc. A characteristic of these languages is that they are under-resourced. But the words of these languages show rich variations in morphology. Moreover they are often heavily agglutinated and synthetic, making segmentation an important issue. The intellectual motivation for this workshop comes from the need to explore ways of harnessing the morphology of these Source (Lewis, 2009) languages for higher level processing. -

University of Wah Annual Report 2015
UNIVERSITY OF WAH ANNUAL REPORT 2015 BISMILLAH IR-RaHMAN ir-RAHiM “(I START) IN THE NAME OF ALLAH, the most BENEFICENT, the most merciful” Table of Contents Message from the Chancellor..............................................................................01 Message from the Chairman Board of Governors...........................................02 Message from the Vice Chancellor.....................................................................03 Brief History of the University............................................................................04 Year in Review........................................................................................................05 University Management.......................................................................................07 Academic Activities...............................................................................................19 Academic Seminars / Conferences / Workshops.............................................31 Research and Development.................................................................................37 Quality Assurance.................................................................................................39 Faculty Development............................................................................................42 Students Enrolment...............................................................................................44 University Building Economies..........................................................................47 -

Distributed Intra and Inter Cluster Chaining Framework for Energy-Efficient, Delay Bounded and Scalable Data Gathering Applications in Large Scale Sensor Network
International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-9 Issue-2, December 2019 Distributed Intra and Inter Cluster Chaining Framework for Energy-Efficient, Delay Bounded and Scalable Data Gathering Applications in Large Scale Sensor Network Biswanath Dey, Navajyoti Nath, Sivaji Bandyopadhyay, Sukumar Nandi Abstract: This paper proposes a scalable, energy-efficient and The key idea behind the inclusion of hierarchical routing scalable, energy efficient, delay bounded intra and inter cluster protocols is that these protocols impart high energy routing framework viz. GIICCF (Generalized Intra and Inter efficiency, higher scalability, and have effective data cluster chaining framework) for efficient data gathering in large scale wireless sensor networks. This approach extricates the aggregation mechanism. In the proposed approach, chaining benefits of both pure chain-based as well as pure cluster-based is done within the cluster as well as between CHs of different data gathering schemes in large scale Wireless Sensor Network clusters within the system. In the intra-cluster chain is formed (WSNs) without undermining with the drawbacks. GIICCF between the cluster nodes and CH, whereas in inter-cluster defines a localized energy-efficient chaining scheme among the chaining is performed within the CHs. This helps in member nodes within the cluster with bounded data delivery delay improving the efficiency of the protocols and converts into a to the respective cluster-heads (CH) as well as enables the CH to deliver data to the Base station (BS) following an energy-efficient more energy-efficient protocols with higher network multi-hop fashion. Detailed experimental analysis and simulation longevity. -

Kashif Imdad Electrical Engineer
IJENS-RPG [IJENS Researchers Promotion Group] ID: IJENS-1125-Kashif Kashif Imdad Electrical Engineer Address: House # 13-B, Street # 4, Rehber Coloney Mohallah Awanabad HMC Taxila, Pakistan Phone: +92-314-5320579 Cell: +92-314-5320579 Email: [email protected] SUMMARY: Engineer with experience in Power Systems, High voltage Engineering, Electrical drives. Sustainable energy devices, Ability to formulate and implement new ideas. AWARD: Won Best Technical Design Award with cash prize of Rs. 20,000 worth 695 Euro in National Power Engineering Contest 2005 Won Presentation skill Award from NWFP University of Engineering Peshawar EDUCATION: Start Finish Awarding Qualification Institution Year Year Date PhD (Experience Based) 2012 Corllins University USA MS Electrical Engineering University of Engineering & 2007 2010 2011 Specialization in Power Technology Taxila NWFP University of Engineering BE Electrical Engineering 2002 2006 2007 &Technology HSSC (Pre Engineering) 2000 2002 2002 Gandhara college, Wah Cantt SSC (Science) 1998 2000 2000 FG School NO-7 , Wah Cantt FIELD EXPERIENCE Executive Engineer Construction Electricity (Sep 2011-March 2012) (A senior engineer slot) i. To design and construct new 11KV and low voltage lines ii. To prepare annual budget, arrange stores and manage logistics for the entire division iii. Electrical estimations, valuations and its specifications for Electrical overhead and under Ground system Assistant Manager, HMC, Taxila (July 2009 – Aug 2010) . In charge Electrical Power Systems, High Voltage engineering etc . Instructional material preparation and delivery Sale’s Manager, Akhtar solars Pakistan www.akhtersolar.com (June 2006/08) . Marketing, and delivery . Labs preparation and supervision International Journals of Engineering & Sciences IJENS www.ijens.org IJENS-RPG [IJENS Researchers Promotion Group] ID: IJENS-1125-Kashif CERTIFICATIONS . -

Table of Contents
Table of Contents International Journal of Manufacturing, Materials, and Mechanical Engineering Volume 6 • Issue 1 • January-March-2016 • ISSN: 2156-1680 • eISSN: 2156-1672 An official publication of the Information Resources Management Association Research Articles 1 Cutting Speed in Nano-Cutting as MD Modelling Parameter Nikolaos E. Karkalos, National Technical University of Athens, Athens, Greece Angelos P. Markopoulos, National Technical University of Athens, Athens, Greece Dimitrios E. Manolakos, National Technical University of Athens, Athens, Greece 14 Electroless Nickel-Phosphorus Composite Coatings: A Review Prasanna Gadhari, Jadavpur University, Kolkata, India Prasanta Sahoo, Jadavpur University, Kolkata, India 51 FEA Simulation Based Performance Study of Multi Speed Transmission Gearbox Ashwani Kumar, Graphic Era University, Dehradun, India Pravin P Patil, Graphic Era University, Dehradun, India 62 Improvement in Power Efficiency of Injection Molding Machine by Reduction in Plasticization Losses Muhammad Khan, Mechanical Engineering Department, HITEC University, Taxila, Pakistan Nizar Ullah Khan, Department of Mechanical Engineering, Oakland University, Rochester, MI, USA Muhammad Junaid Aziz, Mechanical Engineering Department, University of Engineering & Technology, Taxila, Pakistan Hafiz Kaleem Ullah, Mechanical Engineering Department, HITEC University, Taxila, Pakistan Muhammad Ali Shahid, Ripah International University, Islamabad, Pakistan CopyRight The International Journal of Manufacturing, Materials, and Mechanical Engineering (IJMMME) (ISSN 2156-1680; eISSN 2156-1672), Copyright © 2016 IGI Global. All rights, including translation into other languages reserved by the publisher. No part of this journal may be reproduced or used in any form or by any means without written permission from the publisher, except for noncommercial, educational use including classroom teaching purposes. Product or company names used in this journal are for identification purposes only.