Deck 5 Conditional Probability and Expectation, Poisson Process, Multinomial and Multivariate Normal Distributions
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Lecture 22: Bivariate Normal Distribution Distribution
6.5 Conditional Distributions General Bivariate Normal Let Z1; Z2 ∼ N (0; 1), which we will use to build a general bivariate normal Lecture 22: Bivariate Normal Distribution distribution. 1 1 2 2 f (z1; z2) = exp − (z1 + z2 ) Statistics 104 2π 2 We want to transform these unit normal distributions to have the follow Colin Rundel arbitrary parameters: µX ; µY ; σX ; σY ; ρ April 11, 2012 X = σX Z1 + µX p 2 Y = σY [ρZ1 + 1 − ρ Z2] + µY Statistics 104 (Colin Rundel) Lecture 22 April 11, 2012 1 / 22 6.5 Conditional Distributions 6.5 Conditional Distributions General Bivariate Normal - Marginals General Bivariate Normal - Cov/Corr First, lets examine the marginal distributions of X and Y , Second, we can find Cov(X ; Y ) and ρ(X ; Y ) Cov(X ; Y ) = E [(X − E(X ))(Y − E(Y ))] X = σX Z1 + µX h p i = E (σ Z + µ − µ )(σ [ρZ + 1 − ρ2Z ] + µ − µ ) = σX N (0; 1) + µX X 1 X X Y 1 2 Y Y 2 h p 2 i = N (µX ; σX ) = E (σX Z1)(σY [ρZ1 + 1 − ρ Z2]) h 2 p 2 i = σX σY E ρZ1 + 1 − ρ Z1Z2 p 2 2 Y = σY [ρZ1 + 1 − ρ Z2] + µY = σX σY ρE[Z1 ] p 2 = σX σY ρ = σY [ρN (0; 1) + 1 − ρ N (0; 1)] + µY = σ [N (0; ρ2) + N (0; 1 − ρ2)] + µ Y Y Cov(X ; Y ) ρ(X ; Y ) = = ρ = σY N (0; 1) + µY σX σY 2 = N (µY ; σY ) Statistics 104 (Colin Rundel) Lecture 22 April 11, 2012 2 / 22 Statistics 104 (Colin Rundel) Lecture 22 April 11, 2012 3 / 22 6.5 Conditional Distributions 6.5 Conditional Distributions General Bivariate Normal - RNG Multivariate Change of Variables Consequently, if we want to generate a Bivariate Normal random variable Let X1;:::; Xn have a continuous joint distribution with pdf f defined of S. -

On Two-Echelon Inventory Systems with Poisson Demand and Lost Sales
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Universiteit Twente Repository On two-echelon inventory systems with Poisson demand and lost sales Elisa Alvarez, Matthieu van der Heijden Beta Working Paper series 366 BETA publicatie WP 366 (working paper) ISBN ISSN NUR 804 Eindhoven December 2011 On two-echelon inventory systems with Poisson demand and lost sales Elisa Alvarez Matthieu van der Heijden University of Twente University of Twente The Netherlands1 The Netherlands 2 Abstract We derive approximations for the service levels of two-echelon inventory systems with lost sales and Poisson demand. Our method is simple and accurate for a very broad range of problem instances, including cases with both high and low service levels. In contrast, existing methods only perform well for limited problem settings, or under restrictive assumptions. Key words: inventory, spare parts, lost sales. 1 Introduction We consider a two-echelon inventory system for spare part supply chains, consisting of a single central depot and multiple local warehouses. Demand arrives at each local warehouse according to a Poisson process. Each location controls its stocks using a one-for-one replenishment policy. Demand that cannot be satisfied from stock is served using an emergency shipment from an external source with infinite supply and thus lost to the system. It is well-known that the analysis of such lost sales inventory systems is more complex than the equivalent with full backordering (Bijvank and Vis [3]). In particular, the analysis of the central depot is complex, since (i) the order process is not Poisson, and (ii) the order arrival rate depends on the inventory states of the local warehouses: Local warehouses only generate replenishment orders if they have stock on hand. -

Distance Between Multinomial and Multivariate Normal Models
Chapter 9 Distance between multinomial and multivariate normal models SECTION 1 introduces Andrew Carter’s recursive procedure for bounding the Le Cam distance between a multinomialmodelandits approximating multivariatenormal model. SECTION 2 develops notation to describe the recursive construction of randomizations via conditioning arguments, then proves a simple Lemma that serves to combine the conditional bounds into a single recursive inequality. SECTION 3 applies the results from Section 2 to establish the bound involving randomization of the multinomial distribution in Carter’s inequality. SECTION 4 sketches the argument for the bound involving randomization of the multivariate normalin Carter’s inequality. SECTION 5 outlines the calculation for bounding the Hellinger distance between a smoothed Binomialand its approximating normaldistribution. 1. Introduction The multinomial distribution M(n,θ), where θ := (θ1,...,θm ), is the probability m measure on Z+ defined by the joint distribution of the vector of counts in m cells obtained by distributing n balls independently amongst the cells, with each ball assigned to a cell chosen from the distribution θ. The variance matrix nVθ corresponding to M(n,θ) has (i, j)th element nθi {i = j}−nθi θj . The central limit theorem ensures that M(n,θ) is close to the N(nθ,nVθ ), in the sense of weak convergence, for fixed m when n is large. In his doctoral dissertation, Andrew Carter (2000a) considered the deeper problem of bounding the Le Cam distance (M, N) between models M :={M(n,θ) : θ ∈ } and N :={N(nθ,nVθ ) : θ ∈ }, under mild regularity assumptions on . For example, he proved that m log m maxi θi <1>(M, N) ≤ C √ provided sup ≤ C < ∞, n θ∈ mini θi for a constant C that depends only on C. -

The Exciting Guide to Probability Distributions – Part 2
The Exciting Guide To Probability Distributions – Part 2 Jamie Frost – v1.1 Contents Part 2 A revisit of the multinomial distribution The Dirichlet Distribution The Beta Distribution Conjugate Priors The Gamma Distribution We saw in the last part that the multinomial distribution was over counts of outcomes, given the probability of each outcome and the total number of outcomes. xi f(x1, ... , xk | n, p1, ... , pk)= [n! / ∏xi!] ∏pi The count of The probability of each outcome. each outcome. That’s all smashing, but suppose we wanted to know the reverse, i.e. the probability that the distribution underlying our random variable has outcome probabilities of p1, ... , pk, given that we observed each outcome x1, ... , xk times. In other words, we are considering all the possible probability distributions (p1, ... , pk) that could have generated these counts, rather than all the possible counts given a fixed distribution. Initial attempt at a probability mass function: Just swap the domain and the parameters: The RHS is exactly the same. xi f(p1, ... , pk | n, x1, ... , xk )= [n! / ∏xi!] ∏pi Notational convention is that we define the support as a vector x, so let’s relabel p as x, and the counts x as α... αi f(x1, ... , xk | n, α1, ... , αk )= [n! / ∏ αi!] ∏xi We can define n just as the sum of the counts: αi f(x1, ... , xk | α1, ... , αk )= [(∑αi)! / ∏ αi!] ∏xi But wait, we’re not quite there yet. We know that probabilities have to sum to 1, so we need to restrict the domain we can draw from: s.t. -

556: MATHEMATICAL STATISTICS I 1 the Multinomial Distribution the Multinomial Distribution Is a Multivariate Generalization of T
556: MATHEMATICAL STATISTICS I MULTIVARIATE PROBABILITY DISTRIBUTIONS 1 The Multinomial Distribution The multinomial distribution is a multivariate generalization of the binomial distribution. The binomial distribution can be derived from an “infinite urn” model with two types of objects being sampled without replacement. Suppose that the proportion of “Type 1” objects in the urn is θ (so 0 · θ · 1) and hence the proportion of “Type 2” objects in the urn is 1 ¡ θ. Suppose that n objects are sampled, and X is the random variable corresponding to the number of “Type 1” objects in the sample. Then X » Bin(n; θ). Now consider a generalization; suppose that the urn contains k + 1 types of objects (k = 1; 2; :::), with θi being the proportion of Type i objects, for i = 1; :::; k + 1. Let Xi be the random variable corresponding to the number of type i objects in a sample of size n, for i = 1; :::; k. Then the joint T pmf of vector X = (X1; :::; Xk) is given by e n! n! kY+1 f (x ; :::; x ) = θx1 ....θxk θxk+1 = θxi X1;:::;Xk 1 k x !:::x !x ! 1 k k+1 x !:::x !x ! i 1 k k+1 1 k k+1 i=1 where 0 · θi · 1 for all i, and θ1 + ::: + θk + θk+1 = 1, and where xk+1 is defined by xk+1 = n ¡ (x1 + ::: + xk): This is the mass function for the multinomial distribution which reduces to the binomial if k = 1. 2 The Dirichlet Distribution The Dirichlet distribution is a multivariate generalization of the Beta distribution. -

Probability Distributions and Related Mathematical Constructs
Appendix B More probability distributions and related mathematical constructs This chapter covers probability distributions and related mathematical constructs that are referenced elsewhere in the book but aren’t covered in detail. One of the best places for more detailed information about these and many other important probability distributions is Wikipedia. B.1 The gamma and beta functions The gamma function Γ(x), defined for x> 0, can be thought of as a generalization of the factorial x!. It is defined as ∞ x 1 u Γ(x)= u − e− du Z0 and is available as a function in most statistical software packages such as R. The behavior of the gamma function is simpler than its form may suggest: Γ(1) = 1, and if x > 1, Γ(x)=(x 1)Γ(x 1). This means that if x is a positive integer, then Γ(x)=(x 1)!. − − − The beta function B(α1,α2) is defined as a combination of gamma functions: Γ(α1)Γ(α2) B(α ,α ) def= 1 2 Γ(α1+ α2) The beta function comes up as a normalizing constant for beta distributions (Section 4.4.2). It’s often useful to recognize the following identity: 1 α1 1 α2 1 B(α ,α )= x − (1 x) − dx 1 2 − Z0 239 B.2 The Poisson distribution The Poisson distribution is a generalization of the binomial distribution in which the number of trials n grows arbitrarily large while the mean number of successes πn is held constant. It is traditional to write the mean number of successes as λ; the Poisson probability density function is λy P (y; λ)= eλ (y =0, 1,.. -
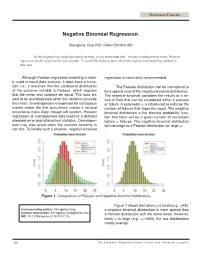
Negative Binomial Regression
STATISTICS COLUMN Negative Binomial Regression Shengping Yang PhD ,Gilbert Berdine MD In the hospital stay study discussed recently, it was mentioned that “in case overdispersion exists, Poisson regression model might not be appropriate.” I would like to know more about the appropriate modeling method in that case. Although Poisson regression modeling is wide- regression is commonly recommended. ly used in count data analysis, it does have a limita- tion, i.e., it assumes that the conditional distribution The Poisson distribution can be considered to of the outcome variable is Poisson, which requires be a special case of the negative binomial distribution. that the mean and variance be equal. The data are The negative binomial considers the results of a se- said to be overdispersed when the variance exceeds ries of trials that can be considered either a success the mean. Overdispersion is expected for contagious or failure. A parameter ψ is introduced to indicate the events where the first occurrence makes a second number of failures that stops the count. The negative occurrence more likely, though still random. Poisson binomial distribution is the discrete probability func- regression of overdispersed data leads to a deflated tion that there will be a given number of successes standard error and inflated test statistics. Overdisper- before ψ failures. The negative binomial distribution sion may also result when the success outcome is will converge to a Poisson distribution for large ψ. not rare. To handle such a situation, negative binomial 0 5 10 15 20 25 0 5 10 15 20 25 Figure 1. Comparison of Poisson and negative binomial distributions. -

Section 1: Regression Review
Section 1: Regression review Yotam Shem-Tov Fall 2015 Yotam Shem-Tov STAT 239A/ PS 236A September 3, 2015 1 / 58 Contact information Yotam Shem-Tov, PhD student in economics. E-mail: [email protected]. Office: Evans hall room 650 Office hours: To be announced - any preferences or constraints? Feel free to e-mail me. Yotam Shem-Tov STAT 239A/ PS 236A September 3, 2015 2 / 58 R resources - Prior knowledge in R is assumed In the link here is an excellent introduction to statistics in R . There is a free online course in coursera on programming in R. Here is a link to the course. An excellent book for implementing econometric models and method in R is Applied Econometrics with R. This is my favourite for starting to learn R for someone who has some background in statistic methods in the social science. The book Regression Models for Data Science in R has a nice online version. It covers the implementation of regression models using R . A great link to R resources and other cool programming and econometric tools is here. Yotam Shem-Tov STAT 239A/ PS 236A September 3, 2015 3 / 58 Outline There are two general approaches to regression 1 Regression as a model: a data generating process (DGP) 2 Regression as an algorithm (i.e., an estimator without assuming an underlying structural model). Overview of this slides: 1 The conditional expectation function - a motivation for using OLS. 2 OLS as the minimum mean squared error linear approximation (projections). 3 Regression as a structural model (i.e., assuming the conditional expectation is linear). -

(Introduction to Probability at an Advanced Level) - All Lecture Notes
Fall 2018 Statistics 201A (Introduction to Probability at an advanced level) - All Lecture Notes Aditya Guntuboyina August 15, 2020 Contents 0.1 Sample spaces, Events, Probability.................................5 0.2 Conditional Probability and Independence.............................6 0.3 Random Variables..........................................7 1 Random Variables, Expectation and Variance8 1.1 Expectations of Random Variables.................................9 1.2 Variance................................................ 10 2 Independence of Random Variables 11 3 Common Distributions 11 3.1 Ber(p) Distribution......................................... 11 3.2 Bin(n; p) Distribution........................................ 11 3.3 Poisson Distribution......................................... 12 4 Covariance, Correlation and Regression 14 5 Correlation and Regression 16 6 Back to Common Distributions 16 6.1 Geometric Distribution........................................ 16 6.2 Negative Binomial Distribution................................... 17 7 Continuous Distributions 17 7.1 Normal or Gaussian Distribution.................................. 17 1 7.2 Uniform Distribution......................................... 18 7.3 The Exponential Density...................................... 18 7.4 The Gamma Density......................................... 18 8 Variable Transformations 19 9 Distribution Functions and the Quantile Transform 20 10 Joint Densities 22 11 Joint Densities under Transformations 23 11.1 Detour to Convolutions...................................... -

Binomial and Multinomial Distributions
Binomial and multinomial distributions Kevin P. Murphy Last updated October 24, 2006 * Denotes more advanced sections 1 Introduction In this chapter, we study probability distributions that are suitable for modelling discrete data, like letters and words. This will be useful later when we consider such tasks as classifying and clustering documents, recognizing and segmenting languages and DNA sequences, data compression, etc. Formally, we will be concerned with density models for X ∈{1,...,K}, where K is the number of possible values for X; we can think of this as the number of symbols/ letters in our alphabet/ language. We assume that K is known, and that the values of X are unordered: this is called categorical data, as opposed to ordinal data, in which the discrete states can be ranked (e.g., low, medium and high). If K = 2 (e.g., X represents heads or tails), we will use a binomial distribution. If K > 2, we will use a multinomial distribution. 2 Bernoullis and Binomials Let X ∈{0, 1} be a binary random variable (e.g., a coin toss). Suppose p(X =1)= θ. Then − p(X|θ) = Be(X|θ)= θX (1 − θ)1 X (1) is called a Bernoulli distribution. It is easy to show that E[X] = p(X =1)= θ (2) Var [X] = θ(1 − θ) (3) The likelihood for a sequence D = (x1,...,xN ) of coin tosses is N − p(D|θ)= θxn (1 − θ)1 xn = θN1 (1 − θ)N0 (4) n=1 Y N N where N1 = n=1 xn is the number of heads (X = 1) and N0 = n=1(1 − xn)= N − N1 is the number of tails (X = 0). -

Discrete Probability Distributions
Machine Learning Srihari Discrete Probability Distributions Sargur N. Srihari 1 Machine Learning Srihari Binary Variables Bernoulli, Binomial and Beta 2 Machine Learning Srihari Bernoulli Distribution • Expresses distribution of Single binary-valued random variable x ε {0,1} • Probability of x=1 is denoted by parameter µ, i.e., p(x=1|µ)=µ – Therefore p(x=0|µ)=1-µ • Probability distribution has the form Bern(x|µ)=µ x (1-µ) 1-x • Mean is shown to be E[x]=µ Jacob Bernoulli • Variance is var[x]=µ (1-µ) 1654-1705 • Likelihood of n observations independently drawn from p(x|µ) is N N x 1−x p(D | ) = p(x | ) = n (1− ) n µ ∏ n µ ∏µ µ n=1 n=1 – Log-likelihood is N N ln p(D | ) = ln p(x | ) = {x ln +(1−x )ln(1− )} µ ∑ n µ ∑ n µ n µ n=1 n=1 • Maximum likelihood estimator 1 N – obtained by setting derivative of ln p(D|µ) wrt m equal to zero is = x µML ∑ n N n=1 • If no of observations of x=1 is m then µML=m/N 3 Machine Learning Srihari Binomial Distribution • Related to Bernoulli distribution • Expresses Distribution of m – No of observations for which x=1 • It is proportional to Bern(x|µ) Histogram of Binomial for • Add up all ways of obtaining heads N=10 and ⎛ ⎞ m=0.25 ⎜ N ⎟ m N−m Bin(m | N,µ) = ⎜ ⎟µ (1− µ) ⎝⎜ m ⎠⎟ Binomial Coefficients: ⎛ ⎞ N ! ⎜ N ⎟ • Mean and Variance are ⎜ ⎟ = ⎝⎜ m ⎠⎟ m!(N −m)! N E[m] = ∑mBin(m | N,µ) = Nµ m=0 Var[m] = N (1− ) 4 µ µ Machine Learning Srihari Beta Distribution • Beta distribution a=0.1, b=0.1 a=1, b=1 Γ(a + b) Beta(µ |a,b) = µa−1(1 − µ)b−1 Γ(a)Γ(b) • Where the Gamma function is defined as ∞ Γ(x) = ∫u x−1e−u du -

Statistical Distributions
CHAPTER 10 Statistical Distributions In this chapter, we shall present some probability distributions that play a central role in econometric theory. First, we shall present the distributions of some discrete random variables that have either a finite set of values or that take values that can be indexed by the entire set of positive integers. We shall also present the multivariate generalisations of one of these distributions. Next, we shall present the distributions of some continuous random variables that take values in intervals of the real line or over the entirety of the real line. Amongst these is the normal distribution, which is of prime importance and for which we shall consider, in detail, the multivariate extensions. Associated with the multivariate normal distribution are the so-called sam- pling distributions that are important in the theory of statistical inference. We shall consider these distributions in the final section of the chapter, where it will transpire that they are special cases of the univariate distributions described in the preceding section. Discrete Distributions Suppose that there is a population of N elements, Np of which belong to class and N(1 p) to class c. When we select n elements at random from the populationA in n −successive trials,A we wish to know the probability of the event that x of them will be in and that n x of them will be in c. The probability will Abe affected b−y the way in which theA n elements are selected; and there are two ways of doing this. Either they can be put aside after they have been sampled, or else they can be restored to the population.