Prospectus for the Next LAPACK and Scalapack Libraries
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Recursive Approach in Sparse Matrix LU Factorization
51 Recursive approach in sparse matrix LU factorization Jack Dongarra, Victor Eijkhout and the resulting matrix is often guaranteed to be positive Piotr Łuszczek∗ definite or close to it. However, when the linear sys- University of Tennessee, Department of Computer tem matrix is strongly unsymmetric or indefinite, as Science, Knoxville, TN 37996-3450, USA is the case with matrices originating from systems of Tel.: +865 974 8295; Fax: +865 974 8296 ordinary differential equations or the indefinite matri- ces arising from shift-invert techniques in eigenvalue methods, one has to revert to direct methods which are This paper describes a recursive method for the LU factoriza- the focus of this paper. tion of sparse matrices. The recursive formulation of com- In direct methods, Gaussian elimination with partial mon linear algebra codes has been proven very successful in pivoting is performed to find a solution of Eq. (1). Most dense matrix computations. An extension of the recursive commonly, the factored form of A is given by means technique for sparse matrices is presented. Performance re- L U P Q sults given here show that the recursive approach may per- of matrices , , and such that: form comparable to leading software packages for sparse ma- LU = PAQ, (2) trix factorization in terms of execution time, memory usage, and error estimates of the solution. where: – L is a lower triangular matrix with unitary diago- nal, 1. Introduction – U is an upper triangular matrix with arbitrary di- agonal, Typically, a system of linear equations has the form: – P and Q are row and column permutation matri- Ax = b, (1) ces, respectively (each row and column of these matrices contains single a non-zero entry which is A n n A ∈ n×n x where is by real matrix ( R ), and 1, and the following holds: PPT = QQT = I, b n b, x ∈ n and are -dimensional real vectors ( R ). -

Abstract 1 Introduction
Implementation in ScaLAPACK of Divide-and-Conquer Algorithms for Banded and Tridiagonal Linear Systems A. Cleary Department of Computer Science University of Tennessee J. Dongarra Department of Computer Science University of Tennessee Mathematical Sciences Section Oak Ridge National Laboratory Abstract Described hereare the design and implementation of a family of algorithms for a variety of classes of narrow ly banded linear systems. The classes of matrices include symmetric and positive de - nite, nonsymmetric but diagonal ly dominant, and general nonsymmetric; and, al l these types are addressed for both general band and tridiagonal matrices. The family of algorithms captures the general avor of existing divide-and-conquer algorithms for banded matrices in that they have three distinct phases, the rst and last of which arecompletely paral lel, and the second of which is the par- al lel bottleneck. The algorithms have been modi ed so that they have the desirable property that they are the same mathematical ly as existing factorizations Cholesky, Gaussian elimination of suitably reordered matrices. This approach represents a departure in the nonsymmetric case from existing methods, but has the practical bene ts of a smal ler and more easily hand led reduced system. All codes implement a block odd-even reduction for the reduced system that al lows the algorithm to scale far better than existing codes that use variants of sequential solution methods for the reduced system. A cross section of results is displayed that supports the predicted performance results for the algo- rithms. Comparison with existing dense-type methods shows that for areas of the problem parameter space with low bandwidth and/or high number of processors, the family of algorithms described here is superior. -

Overview of Iterative Linear System Solver Packages
Overview of Iterative Linear System Solver Packages Victor Eijkhout July, 1998 Abstract Description and comparison of several packages for the iterative solu- tion of linear systems of equations. 1 1 Intro duction There are several freely available packages for the iterative solution of linear systems of equations, typically derived from partial di erential equation prob- lems. In this rep ort I will give a brief description of a numberofpackages, and giveaninventory of their features and de ning characteristics. The most imp ortant features of the packages are which iterative metho ds and preconditioners supply; the most relevant de ning characteristics are the interface they present to the user's data structures, and their implementation language. 2 2 Discussion Iterative metho ds are sub ject to several design decisions that a ect ease of use of the software and the resulting p erformance. In this section I will give a global discussion of the issues involved, and how certain p oints are addressed in the packages under review. 2.1 Preconditioners A go o d preconditioner is necessary for the convergence of iterative metho ds as the problem to b e solved b ecomes more dicult. Go o d preconditioners are hard to design, and this esp ecially holds true in the case of parallel pro cessing. Here is a short inventory of the various kinds of preconditioners found in the packages reviewed. 2.1.1 Ab out incomplete factorisation preconditioners Incomplete factorisations are among the most successful preconditioners devel- op ed for single-pro cessor computers. Unfortunately, since they are implicit in nature, they cannot immediately b e used on parallel architectures. -

Accelerating the LOBPCG Method on Gpus Using a Blocked Sparse Matrix Vector Product
Accelerating the LOBPCG method on GPUs using a blocked Sparse Matrix Vector Product Hartwig Anzt and Stanimire Tomov and Jack Dongarra Innovative Computing Lab University of Tennessee Knoxville, USA Email: [email protected], [email protected], [email protected] Abstract— the computing power of today’s supercomputers, often accel- erated by coprocessors like graphics processing units (GPUs), This paper presents a heterogeneous CPU-GPU algorithm design and optimized implementation for an entire sparse iter- becomes challenging. ative eigensolver – the Locally Optimal Block Preconditioned Conjugate Gradient (LOBPCG) – starting from low-level GPU While there exist numerous efforts to adapt iterative lin- data structures and kernels to the higher-level algorithmic choices ear solvers like Krylov subspace methods to coprocessor and overall heterogeneous design. Most notably, the eigensolver technology, sparse eigensolvers have so far remained out- leverages the high-performance of a new GPU kernel developed side the main focus. A possible explanation is that many for the simultaneous multiplication of a sparse matrix and a of those combine sparse and dense linear algebra routines, set of vectors (SpMM). This is a building block that serves which makes porting them to accelerators more difficult. Aside as a backbone for not only block-Krylov, but also for other from the power method, algorithms based on the Krylov methods relying on blocking for acceleration in general. The subspace idea are among the most commonly used general heterogeneous LOBPCG developed here reveals the potential of eigensolvers [1]. When targeting symmetric positive definite this type of eigensolver by highly optimizing all of its components, eigenvalue problems, the recently developed Locally Optimal and can be viewed as a benchmark for other SpMM-dependent applications. -

Over-Scalapack.Pdf
1 2 The Situation: Parallel scienti c applications are typically Overview of ScaLAPACK written from scratch, or manually adapted from sequen- tial programs Jack Dongarra using simple SPMD mo del in Fortran or C Computer Science Department UniversityofTennessee with explicit message passing primitives and Mathematical Sciences Section Which means Oak Ridge National Lab oratory similar comp onents are co ded over and over again, co des are dicult to develop and maintain http://w ww .ne tl ib. org /ut k/p e opl e/J ackDo ngarra.html debugging particularly unpleasant... dicult to reuse comp onents not really designed for long-term software solution 3 4 What should math software lo ok like? The NetSolve Client Many more p ossibilities than shared memory Virtual Software Library Multiplicityofinterfaces ! Ease of use Possible approaches { Minimum change to status quo Programming interfaces Message passing and ob ject oriented { Reusable templates { requires sophisticated user Cinterface FORTRAN interface { Problem solving environments Integrated systems a la Matlab, Mathematica use with heterogeneous platform Interactiveinterfaces { Computational server, like netlib/xnetlib f2c Non-graphic interfaces Some users want high p erf., access to details {MATLAB interface Others sacri ce sp eed to hide details { UNIX-Shell interface Not enough p enetration of libraries into hardest appli- Graphic interfaces cations on vector machines { TK/TCL interface Need to lo ok at applications and rethink mathematical software { HotJava Browser -

Jack Dongarra: Supercomputing Expert and Mathematical Software Specialist
Biographies Jack Dongarra: Supercomputing Expert and Mathematical Software Specialist Thomas Haigh University of Wisconsin Editor: Thomas Haigh Jack J. Dongarra was born in Chicago in 1950 to a he applied for an internship at nearby Argonne National family of Sicilian immigrants. He remembers himself as Laboratory as part of a program that rewarded a small an undistinguished student during his time at a local group of undergraduates with college credit. Dongarra Catholic elementary school, burdened by undiagnosed credits his success here, against strong competition from dyslexia.Onlylater,inhighschool,didhebeginto students attending far more prestigious schools, to Leff’s connect material from science classes with his love of friendship with Jim Pool who was then associate director taking machines apart and tinkering with them. Inspired of the Applied Mathematics Division at Argonne.2 by his science teacher, he attended Chicago State University and majored in mathematics, thinking that EISPACK this would combine well with education courses to equip Dongarra was supervised by Brian Smith, a young him for a high school teaching career. The first person in researcher whose primary concern at the time was the his family to go to college, he lived at home and worked lab’s EISPACK project. Although budget cuts forced Pool to in a pizza restaurant to cover the cost of his education.1 make substantial layoffs during his time as acting In 1972, during his senior year, a series of chance director of the Applied Mathematics Division in 1970– events reshaped Dongarra’s planned career. On the 1971, he had made a special effort to find funds to suggestion of Harvey Leff, one of his physics professors, protect the project and hire Smith. -

Distibuted Dense Numerical Linear Algebra Algorithms on Massively Parallel Architectures: DPLASMA
Distibuted Dense Numerical Linear Algebra Algorithms on massively parallel architectures: DPLASMA † George Bosilca∗, Aurelien Bouteiller∗, Anthony Danalis∗ , Mathieu Faverge∗, Azzam Haidar∗, ‡ §¶ Thomas Herault∗ , Jakub Kurzak∗, Julien Langou , Pierre Lemarinier∗, Hatem Ltaief∗, † Piotr Luszczek∗, Asim YarKhan∗ and Jack Dongarra∗ ∗University of Tennessee Innovative Computing Laboratory †Oak Ridge National Laboratory ‡University Paris-XI §University of Colorado Denver ¶Research was supported by the National Science Foundation grant no. NSF CCF-811520 Abstract—We present DPLASMA, a new project related first two, combined with the economic necessity of using to PLASMA, that operates in the distributed memory many thousands of CPUs to scale up to petascale and regime. It uses a new generic distributed Direct Acyclic larger systems. Graph engine for high performance computing (DAGuE). Our work also takes advantage of some of the features of More transistors and slower clocks means multicore DAGuE, such as DAG representation that is independent of designs and more parallelism required. The modus problem-size, overlapping of communication and computa- operandi of traditional processor design, increase the tion, task prioritization, architecture-aware scheduling and transistor density, speed up the clock rate, raise the management of micro-tasks on distributed architectures voltage has now been blocked by a stubborn set of that feature heterogeneous many-core nodes. The origi- nality of this engine is that it is capable of translating physical barriers: excess heat produced, too much power a sequential nested-loop code into a concise and synthetic consumed, too much voltage leaked. Multicore designs format which it can be interpret and then execute in a are a natural response to this situation. -

LAPACK WORKING NOTE 195: SCALAPACK's MRRR ALGORITHM 1. Introduction. Since 2005, the National Science Foundation Has Been Fund
LAPACK WORKING NOTE 195: SCALAPACK’S MRRR ALGORITHM CHRISTOF VOMEL¨ ∗ Abstract. The sequential algorithm of Multiple Relatively Robust Representations, MRRR, can compute numerically orthogonal eigenvectors of an unreduced symmetric tridiagonal matrix T ∈ Rn×n with O(n2) cost. This paper describes the design of ScaLAPACK’s parallel MRRR algorithm. One emphasis is on the critical role of the representation tree in achieving both numerical accuracy and parallel scalability. A second point concerns the favorable properties of this code: subset computation, the use of static memory, and scalability. Unlike ScaLAPACK’s Divide & Conquer and QR, MRRR can compute subsets of eigenpairs at reduced cost. And in contrast to inverse iteration which can fail, it is guaranteed to produce a numerically satisfactory answer while maintaining memory scalability. ParEig, the parallel MRRR algorithm for PLAPACK, uses dynamic memory allocation. This is avoided by our code at marginal additional cost. We also use a different representation tree criterion that allows for more accurate computation of the eigenvectors but can make parallelization more difficult. AMS subject classifications. 65F15, 65Y15. Key words. Symmetric eigenproblem, multiple relatively robust representations, ScaLAPACK, numerical software. 1. Introduction. Since 2005, the National Science Foundation has been funding an initiative [19] to improve the LAPACK [3] and ScaLAPACK [14] libraries for Numerical Linear Algebra computations. One of the ambitious goals of this initiative is to put more of LAPACK into ScaLAPACK, recognizing the gap between available sequential and parallel software support. In particular, parallelization of the MRRR algorithm [24, 50, 51, 26, 27, 28, 29], the topic of this paper, is identified as one key improvement to ScaLAPACK. -
Reciprocity Relations
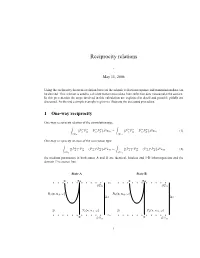
Reciprocity relations - May 11, 2006 Using the reciprocity theorem a relation between the seismic reflection response and transmission data can be derived. This relation is used to calculate transmission data from reflection data measured at the surface. In this presentation the steps involved in this calculation are explained in detail and possible pitfalls are discussed. At the end a simple example is given to illustrate the discussed procedure. 1 One-way reciprocity One-way reciprocity relation of the convolution type: + − − + 2x + − − + 2x {PA PB − PA PB }d H = {PA PB − PA PB }d H (1) Z∂D0 Z∂Dm One-way reciprocity relation of the correlation type: + ∗ + − ∗ − 2x + ∗ + − ∗ − 2x {(PA ) PB − (PA ) PB }d H = {(PA ) PB − (PA ) PB }d H (2) Z∂D0 Z∂Dm the medium parameters in both states A and B are identical, lossless and 3-D inhomogeneous and the domain D is source free. State A State B x xA x xB z0 ∂D0 ∂D0 R0(x, xA,ω) R0(x, xB ,ω) ∆z ∆z D T0(x, xA,ω) D T0(x, xB ,ω) x zm x ∂Dm ∂Dm 1 Surface ∂D0 Field State A State B + P δ(xH − xH,A)sA(ω) δ(xH − xH,B )sB(ω) − P R0(x, xA,ω)sA(ω) R0(x, xB ,ω)sB(ω) Surface ∂Dm + P T0(x, xA,ω)sA(ω) T0(x, xB ,ω)sB(ω) P − 0 0 One-way reciprocity relation of the convolution type: 2 sAsB {δ(xH − xH,A)R0(x, xB ) − R0(x, xA)δ(xH − xH,B )}d xH =0 (3a) Z∂D0 R0(xA, xB )= R0(xB , xA) (3b) One-way reciprocity relation of the correlation type: x x ∗ x x x x 2x ∗ x x x x 2x δ( H,A − H,B) − R0( , A)R0( , B )d H = T0 ( , A)T0( , B )d H (4) Z∂D0 Z∂Dm Equation (4) can be used to estimate transmission effects on wave propagation (coda) from reflection data at the surface. -

C++ API for BLAS and LAPACK
2 C++ API for BLAS and LAPACK Mark Gates ICL1 Piotr Luszczek ICL Ahmad Abdelfattah ICL Jakub Kurzak ICL Jack Dongarra ICL Konstantin Arturov Intel2 Cris Cecka NVIDIA3 Chip Freitag AMD4 1Innovative Computing Laboratory 2Intel Corporation 3NVIDIA Corporation 4Advanced Micro Devices, Inc. February 21, 2018 This research was supported by the Exascale Computing Project (17-SC-20-SC), a collaborative effort of two U.S. Department of Energy organizations (Office of Science and the National Nuclear Security Administration) responsible for the planning and preparation of a capable exascale ecosystem, including software, applications, hardware, advanced system engineering and early testbed platforms, in support of the nation's exascale computing imperative. Revision Notes 06-2017 first publication 02-2018 • copy editing, • new cover. 03-2018 • adding a section about GPU support, • adding Ahmad Abdelfattah as an author. @techreport{gates2017cpp, author={Gates, Mark and Luszczek, Piotr and Abdelfattah, Ahmad and Kurzak, Jakub and Dongarra, Jack and Arturov, Konstantin and Cecka, Cris and Freitag, Chip}, title={{SLATE} Working Note 2: C++ {API} for {BLAS} and {LAPACK}}, institution={Innovative Computing Laboratory, University of Tennessee}, year={2017}, month={June}, number={ICL-UT-17-03}, note={revision 03-2018} } i Contents 1 Introduction and Motivation1 2 Standards and Trends2 2.1 Programming Language Fortran............................ 2 2.1.1 FORTRAN 77.................................. 2 2.1.2 BLAST XBLAS................................. 4 2.1.3 Fortran 90.................................... 4 2.2 Programming Language C................................ 5 2.2.1 Netlib CBLAS.................................. 5 2.2.2 Intel MKL CBLAS................................ 6 2.2.3 Netlib lapack cwrapper............................. 6 2.2.4 LAPACKE.................................... 7 2.2.5 Next-Generation BLAS: \BLAS G2"..................... -

On the Performance and Energy Efficiency of Sparse Linear Algebra on Gpus
Original Article The International Journal of High Performance Computing Applications 1–16 On the performance and energy efficiency Ó The Author(s) 2016 Reprints and permissions: sagepub.co.uk/journalsPermissions.nav of sparse linear algebra on GPUs DOI: 10.1177/1094342016672081 hpc.sagepub.com Hartwig Anzt1, Stanimire Tomov1 and Jack Dongarra1,2,3 Abstract In this paper we unveil some performance and energy efficiency frontiers for sparse computations on GPU-based super- computers. We compare the resource efficiency of different sparse matrix–vector products (SpMV) taken from libraries such as cuSPARSE and MAGMA for GPU and Intel’s MKL for multicore CPUs, and develop a GPU sparse matrix–matrix product (SpMM) implementation that handles the simultaneous multiplication of a sparse matrix with a set of vectors in block-wise fashion. While a typical sparse computation such as the SpMV reaches only a fraction of the peak of current GPUs, we show that the SpMM succeeds in exceeding the memory-bound limitations of the SpMV. We integrate this kernel into a GPU-accelerated Locally Optimal Block Preconditioned Conjugate Gradient (LOBPCG) eigensolver. LOBPCG is chosen as a benchmark algorithm for this study as it combines an interesting mix of sparse and dense linear algebra operations that is typical for complex simulation applications, and allows for hardware-aware optimizations. In a detailed analysis we compare the performance and energy efficiency against a multi-threaded CPU counterpart. The reported performance and energy efficiency results are indicative of sparse computations on supercomputers. Keywords sparse eigensolver, LOBPCG, GPU supercomputer, energy efficiency, blocked sparse matrix–vector product 1Introduction GPU-based supercomputers. -

Evolving Software Repositories
1 Evolving Software Rep ositories http://www.netli b.org/utk/pro ject s/esr/ Jack Dongarra UniversityofTennessee and Oak Ridge National Lab oratory Ron Boisvert National Institute of Standards and Technology Eric Grosse AT&T Bell Lab oratories 2 Pro ject Fo cus Areas NHSE Overview Resource Cataloging and Distribution System RCDS Safe execution environments for mobile co de Application-l evel and content-oriented to ols Rep ository interop erabili ty Distributed, semantic-based searching 3 NHSE National HPCC Software Exchange NASA plus other agencies funded CRPC pro ject Center for ResearchonParallel Computation CRPC { Argonne National Lab oratory { California Institute of Technology { Rice University { Syracuse University { UniversityofTennessee Uniform interface to distributed HPCC software rep ositories Facilitation of cross-agency and interdisciplinary software reuse Material from ASTA, HPCS, and I ITA comp onents of the HPCC program http://www.netlib.org/nhse/ 4 Goals: Capture, preserve and makeavailable all software and software- related artifacts pro duced by the federal HPCC program. Soft- ware related artifacts include algorithms, sp eci cations, designs, do cumentation, rep ort, ... Promote formation, growth, and interop eration of discipline-oriented rep ositories that organize, evaluate, and add value to individual contributions. Employ and develop where necessary state-of-the-art technologies for assisting users in nding, understanding, and using HPCC software and technologies. 5 Bene ts: 1. Faster development of high-quality software so that scientists can sp end less time writing and debugging programs and more time on research problems. 2. Less duplication of software development e ort by sharing of soft- ware mo dules.