Tree: a Dynamic Index for Multi-Dimensional Objects²
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Tree-Combined Trie: a Compressed Data Structure for Fast IP Address Lookup
(IJACSA) International Journal of Advanced Computer Science and Applications, Vol. 6, No. 12, 2015 Tree-Combined Trie: A Compressed Data Structure for Fast IP Address Lookup Muhammad Tahir Shakil Ahmed Department of Computer Engineering, Department of Computer Engineering, Sir Syed University of Engineering and Technology, Sir Syed University of Engineering and Technology, Karachi Karachi Abstract—For meeting the requirements of the high-speed impact their forwarding capacity. In order to resolve two main Internet and satisfying the Internet users, building fast routers issues there are two possible solutions one is IPv6 IP with high-speed IP address lookup engine is inevitable. addressing scheme and second is Classless Inter-domain Regarding the unpredictable variations occurred in the Routing or CIDR. forwarding information during the time and space, the IP lookup algorithm should be able to customize itself with temporal and Finding a high-speed, memory-efficient and scalable IP spatial conditions. This paper proposes a new dynamic data address lookup method has been a great challenge especially structure for fast IP address lookup. This novel data structure is in the last decade (i.e. after introducing Classless Inter- a dynamic mixture of trees and tries which is called Tree- Domain Routing, CIDR, in 1994). In this paper, we will Combined Trie or simply TC-Trie. Binary sorted trees are more discuss only CIDR. In addition to these desirable features, advantageous than tries for representing a sparse population reconfigurability is also of great importance; true because while multibit tries have better performance than trees when a different points of this huge heterogeneous structure of population is dense. -

Heaps a Heap Is a Complete Binary Tree. a Max-Heap Is A
Heaps Heaps 1 A heap is a complete binary tree. A max-heap is a complete binary tree in which the value in each internal node is greater than or equal to the values in the children of that node. A min-heap is defined similarly. 97 Mapping the elements of 93 84 a heap into an array is trivial: if a node is stored at 90 79 83 81 index k, then its left child is stored at index 42 55 73 21 83 2k+1 and its right child at index 2k+2 01234567891011 97 93 84 90 79 83 81 42 55 73 21 83 CS@VT Data Structures & Algorithms ©2000-2009 McQuain Building a Heap Heaps 2 The fact that a heap is a complete binary tree allows it to be efficiently represented using a simple array. Given an array of N values, a heap containing those values can be built, in situ, by simply “sifting” each internal node down to its proper location: - start with the last 73 73 internal node * - swap the current 74 81 74 * 93 internal node with its larger child, if 79 90 93 79 90 81 necessary - then follow the swapped node down 73 * 93 - continue until all * internal nodes are 90 93 90 73 done 79 74 81 79 74 81 CS@VT Data Structures & Algorithms ©2000-2009 McQuain Heap Class Interface Heaps 3 We will consider a somewhat minimal maxheap class: public class BinaryHeap<T extends Comparable<? super T>> { private static final int DEFCAP = 10; // default array size private int size; // # elems in array private T [] elems; // array of elems public BinaryHeap() { . -

Binary Search Tree
ADT Binary Search Tree! Ellen Walker! CPSC 201 Data Structures! Hiram College! Binary Search Tree! •" Value-based storage of information! –" Data is stored in order! –" Data can be retrieved by value efficiently! •" Is a binary tree! –" Everything in left subtree is < root! –" Everything in right subtree is >root! –" Both left and right subtrees are also BST#s! Operations on BST! •" Some can be inherited from binary tree! –" Constructor (for empty tree)! –" Inorder, Preorder, and Postorder traversal! •" Some must be defined ! –" Insert item! –" Delete item! –" Retrieve item! The Node<E> Class! •" Just as for a linked list, a node consists of a data part and links to successor nodes! •" The data part is a reference to type E! •" A binary tree node must have links to both its left and right subtrees! The BinaryTree<E> Class! The BinaryTree<E> Class (continued)! Overview of a Binary Search Tree! •" Binary search tree definition! –" A set of nodes T is a binary search tree if either of the following is true! •" T is empty! •" Its root has two subtrees such that each is a binary search tree and the value in the root is greater than all values of the left subtree but less than all values in the right subtree! Overview of a Binary Search Tree (continued)! Searching a Binary Tree! Class TreeSet and Interface Search Tree! BinarySearchTree Class! BST Algorithms! •" Search! •" Insert! •" Delete! •" Print values in order! –" We already know this, it#s inorder traversal! –" That#s why it#s called “in order”! Searching the Binary Tree! •" If the tree is -

6.172 Lecture 19 : Cache-Oblivious B-Tree (Tokudb)
How TokuDB Fractal TreeTM Indexes Work Bradley C. Kuszmaul Guest Lecture in MIT 6.172 Performance Engineering, 18 November 2010. 6.172 —How Fractal Trees Work 1 My Background • I’m an MIT alum: MIT Degrees = 2 × S.B + S.M. + Ph.D. • I was a principal architect of the Connection Machine CM-5 super computer at Thinking Machines. • I was Assistant Professor at Yale. • I was Akamai working on network mapping and billing. • I am research faculty in the SuperTech group, working with Charles. 6.172 —How Fractal Trees Work 2 Tokutek A few years ago I started collaborating with Michael Bender and Martin Farach-Colton on how to store data on disk to achieve high performance. We started Tokutek to commercialize the research. 6.172 —How Fractal Trees Work 3 I/O is a Big Bottleneck Sensor Query Systems include Sensor Disk Query sensors and Sensor storage, and Query want to perform Millions of data elements arrive queries on per second Query recently arrived data using indexes. recent data. Sensor 6.172 —How Fractal Trees Work 4 The Data Indexing Problem • Data arrives in one order (say, sorted by the time of the observation). • Data is queried in another order (say, by URL or location). Sensor Query Sensor Disk Query Sensor Query Millions of data elements arrive per second Query recently arrived data using indexes. Sensor 6.172 —How Fractal Trees Work 5 Why Not Simply Sort? • This is what data Data Sorted by Time warehouses do. • The problem is that you Sort must wait to sort the data before querying it: Data Sorted by URL typically an overnight delay. -
B-Trees M-Ary Search Tree Solution
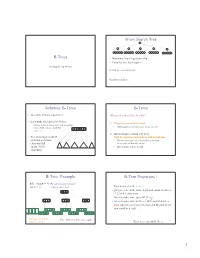
M-ary Search Tree B-Trees • Maximum branching factor of M • Complete tree has height = Section 4.7 in Weiss # disk accesses for find : Runtime of find : 2 Solution: B-Trees B-Trees • specialized M-ary search trees What makes them disk-friendly? • Each node has (up to) M-1 keys: 1. Many keys stored in a node – subtree between two keys x and y contains leaves with values v such that • All brought to memory/cache in one access! 3 7 12 21 x ≤ v < y 2. Internal nodes contain only keys; • Pick branching factor M Only leaf nodes contain keys and actual data such that each node • The tree structure can be loaded into memory takes one full irrespective of data object size {page, block } x<3 3≤x<7 7≤x<12 12 ≤x<21 21 ≤x • Data actually resides in disk of memory 3 4 B-Tree: Example B-Tree Properties ‡ B-Tree with M = 4 (# pointers in internal node) and L = 4 (# data items in leaf) – Data is stored at the leaves – All leaves are at the same depth and contain between 10 40 L/2 and L data items – Internal nodes store up to M-1 keys 3 15 20 30 50 – Internal nodes have between M/2 and M children – Root (special case) has between 2 and M children (or root could be a leaf) 1 2 10 11 12 20 25 26 40 42 AB xG 3 5 6 9 15 17 30 32 33 36 50 60 70 Data objects, that I’ll Note: All leaves at the same depth! ignore in slides 5 ‡These are technically B +-Trees 6 1 Example, Again B-trees vs. -

AVL Trees and Rotations
/ AVL trees and rotations Q1 Operations (insert, delete, search) are O(height) Tree height is O(log n) if perfectly balanced ◦ But maintaining perfect balance is O(n) Height-balanced trees are still O(log n) ◦ For T with height h, N(T) ≤ Fib(h+3) – 1 ◦ So H < 1.44 log (N+2) – 1.328 * AVL (Adelson-Velskii and Landis) trees maintain height-balance using rotations Are rotations O(log n)? We’ll see… / or = or \ Different representations for / = \ : Just two bits in a low-level language Enum in a higher-level language / Assume tree is height-balanced before insertion Insert as usual for a BST Move up from the newly inserted node to the lowest “unbalanced” node (if any) ◦ Use the balance code to detect unbalance - how? Do an appropriate rotation to balance the sub-tree rooted at this unbalanced node For example, a single left rotation: Two basic cases ◦ “See saw” case: Too-tall sub-tree is on the outside So tip the see saw so it’s level ◦ “Suck in your gut” case: Too-tall sub-tree is in the middle Pull its root up a level Q2-3 Unbalanced node Middle sub-tree attaches to lower node of the “see saw” Diagrams are from Data Structures by E.M. Reingold and W.J. Hansen Q4-5 Unbalanced node Pulled up Split between the nodes pushed down Weiss calls this “right-left double rotation” Q6 Write the method: static BalancedBinaryNode singleRotateLeft ( BalancedBinaryNode parent, /* A */ BalancedBinaryNode child /* B */ ) { } Returns a reference to the new root of this subtree. -

Tries and String Matching
Tries and String Matching Where We've Been ● Fundamental Data Structures ● Red/black trees, B-trees, RMQ, etc. ● Isometries ● Red/black trees ≡ 2-3-4 trees, binomial heaps ≡ binary numbers, etc. ● Amortized Analysis ● Aggregate, banker's, and potential methods. Where We're Going ● String Data Structures ● Data structures for storing and manipulating text. ● Randomized Data Structures ● Using randomness as a building block. ● Integer Data Structures ● Breaking the Ω(n log n) sorting barrier. ● Dynamic Connectivity ● Maintaining connectivity in an changing world. String Data Structures Text Processing ● String processing shows up everywhere: ● Computational biology: Manipulating DNA sequences. ● NLP: Storing and organizing huge text databases. ● Computer security: Building antivirus databases. ● Many problems have polynomial-time solutions. ● Goal: Design theoretically and practically efficient algorithms that outperform brute-force approaches. Outline for Today ● Tries ● A fundamental building block in string processing algorithms. ● Aho-Corasick String Matching ● A fast and elegant algorithm for searching large texts for known substrings. Tries Ordered Dictionaries ● Suppose we want to store a set of elements supporting the following operations: ● Insertion of new elements. ● Deletion of old elements. ● Membership queries. ● Successor queries. ● Predecessor queries. ● Min/max queries. ● Can use a standard red/black tree or splay tree to get (worst-case or expected) O(log n) implementations of each. A Catch ● Suppose we want to store a set of strings. ● Comparing two strings of lengths r and s takes time O(min{r, s}). ● Operations on a balanced BST or splay tree now take time O(M log n), where M is the length of the longest string in the tree. -

Binary Tree Fall 2017 Stony Brook University Instructor: Shebuti Rayana [email protected] Introduction to Tree
CSE 230 Intermediate Programming in C and C++ Binary Tree Fall 2017 Stony Brook University Instructor: Shebuti Rayana [email protected] Introduction to Tree ■ Tree is a non-linear data structure which is a collection of data (Node) organized in hierarchical structure. ■ In tree data structure, every individual element is called as Node. Node stores – the actual data of that particular element and – link to next element in hierarchical structure. Tree with 11 nodes and 10 edges Shebuti Rayana (CS, Stony Brook University) 2 Tree Terminology ■ Root ■ In a tree data structure, the first node is called as Root Node. Every tree must have root node. In any tree, there must be only one root node. Root node does not have any parent. (same as head in a LinkedList). Here, A is the Root node Shebuti Rayana (CS, Stony Brook University) 3 Tree Terminology ■ Edge ■ The connecting link between any two nodes is called an Edge. In a tree with 'N' number of nodes there will be a maximum of 'N-1' number of edges. Edge is the connecting link between the two nodes Shebuti Rayana (CS, Stony Brook University) 4 Tree Terminology ■ Parent ■ The node which is predecessor of any node is called as Parent Node. The node which has branch from it to any other node is called as parent node. Parent node can also be defined as "The node which has child / children". Here, A is Parent of B and C B is Parent of D, E and F C is the Parent of G and H Shebuti Rayana (CS, Stony Brook University) 5 Tree Terminology ■ Child ■ The node which is descendant of any node is called as CHILD Node. -

Red-Black Trees
Red-Black Trees 1 Red-Black Trees balancing binary search trees relation with 2-3-4 trees 2 Insertion into a Red-Black Tree algorithm for insertion an elaborate example of an insert inserting a sequence of numbers 3 Recursive Insert Function pseudo code MCS 360 Lecture 36 Introduction to Data Structures Jan Verschelde, 20 April 2020 Introduction to Data Structures (MCS 360) Red-Black Trees L-36 20 April 2020 1 / 36 Red-Black Trees 1 Red-Black Trees balancing binary search trees relation with 2-3-4 trees 2 Insertion into a Red-Black Tree algorithm for insertion an elaborate example of an insert inserting a sequence of numbers 3 Recursive Insert Function pseudo code Introduction to Data Structures (MCS 360) Red-Black Trees L-36 20 April 2020 2 / 36 Binary Search Trees Binary search trees store ordered data. Rules to insert x at node N: if N is empty, then put x in N if x < N, insert x to the left of N if x ≥ N, insert x to the right of N Balanced tree of n elements has depth is log2(n) ) retrieval is O(log2(n)), almost constant. With rotation we make a tree balanced. Alternative to AVL tree: nodes with > 2 children. Every node in a binary tree has at most 2 children. A 2-3-4 tree has nodes with 2, 3, and 4 children. A red-black tree is a binary tree equivalent to a 2-3-4 tree. Introduction to Data Structures (MCS 360) Red-Black Trees L-36 20 April 2020 3 / 36 a red-black tree red nodes have hollow rings 11 @ 2 14 @ 1 7 @ 5 8 Four invariants: 1 A node is either red or black. -

Balanced Binary Search Trees – AVL Trees, 2-3 Trees, B-Trees
Balanced binary search trees – AVL trees, 2‐3 trees, B‐trees Professor Clark F. Olson (with edits by Carol Zander) AVL trees One potential problem with an ordinary binary search tree is that it can have a height that is O(n), where n is the number of items stored in the tree. This occurs when the items are inserted in (nearly) sorted order. We can fix this problem if we can enforce that the tree remains balanced while still inserting and deleting items in O(log n) time. The first (and simplest) data structure to be discovered for which this could be achieved is the AVL tree, which is names after the two Russians who discovered them, Georgy Adelson‐Velskii and Yevgeniy Landis. It takes longer (on average) to insert and delete in an AVL tree, since the tree must remain balanced, but it is faster (on average) to retrieve. An AVL tree must have the following properties: • It is a binary search tree. • For each node in the tree, the height of the left subtree and the height of the right subtree differ by at most one (the balance property). The height of each node is stored in the node to facilitate determining whether this is the case. The height of an AVL tree is logarithmic in the number of nodes. This allows insert/delete/retrieve to all be performed in O(log n) time. Here is an example of an AVL tree: 18 3 37 2 11 25 40 1 8 13 42 6 10 15 Inserting 0 or 5 or 16 or 43 would result in an unbalanced tree. -

Tree-To-Tree Neural Networks for Program Translation
Tree-to-tree Neural Networks for Program Translation Xinyun Chen Chang Liu UC Berkeley UC Berkeley [email protected] [email protected] Dawn Song UC Berkeley [email protected] Abstract Program translation is an important tool to migrate legacy code in one language into an ecosystem built in a different language. In this work, we are the first to employ deep neural networks toward tackling this problem. We observe that program translation is a modular procedure, in which a sub-tree of the source tree is translated into the corresponding target sub-tree at each step. To capture this intuition, we design a tree-to-tree neural network to translate a source tree into a target one. Meanwhile, we develop an attention mechanism for the tree-to-tree model, so that when the decoder expands one non-terminal in the target tree, the attention mechanism locates the corresponding sub-tree in the source tree to guide the expansion of the decoder. We evaluate the program translation capability of our tree-to-tree model against several state-of-the-art approaches. Compared against other neural translation models, we observe that our approach is consistently better than the baselines with a margin of up to 15 points. Further, our approach can improve the previous state-of-the-art program translation approaches by a margin of 20 points on the translation of real-world projects. 1 Introduction Programs are the main tool for building computer applications, the IT industry, and the digital world. Various programming languages have been invented to facilitate programmers to develop programs for different applications. -

Algorithm for Character Recognition Based on the Trie Structure
University of Montana ScholarWorks at University of Montana Graduate Student Theses, Dissertations, & Professional Papers Graduate School 1987 Algorithm for character recognition based on the trie structure Mohammad N. Paryavi The University of Montana Follow this and additional works at: https://scholarworks.umt.edu/etd Let us know how access to this document benefits ou.y Recommended Citation Paryavi, Mohammad N., "Algorithm for character recognition based on the trie structure" (1987). Graduate Student Theses, Dissertations, & Professional Papers. 5091. https://scholarworks.umt.edu/etd/5091 This Thesis is brought to you for free and open access by the Graduate School at ScholarWorks at University of Montana. It has been accepted for inclusion in Graduate Student Theses, Dissertations, & Professional Papers by an authorized administrator of ScholarWorks at University of Montana. For more information, please contact [email protected]. COPYRIGHT ACT OF 1 9 7 6 Th is is an unpublished manuscript in which copyright sub s i s t s , Any further r e p r in t in g of its contents must be approved BY THE AUTHOR, Ma n sfield L ibrary U n iv e r s it y of Montana Date : 1 987__ AN ALGORITHM FOR CHARACTER RECOGNITION BASED ON THE TRIE STRUCTURE By Mohammad N. Paryavi B. A., University of Washington, 1983 Presented in partial fulfillment of the requirements for the degree of Master of Science University of Montana 1987 Approved by lairman, Board of Examiners iean, Graduate School UMI Number: EP40555 All rights reserved INFORMATION TO ALL USERS The quality of this reproduction is dependent upon the quality of the copy submitted.