Normalization
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Database Design Solutions
spine=1.10" Wrox Programmer to ProgrammerTM Wrox Programmer to ProgrammerTM Beginning Stephens Database Design Solutions Databases play a critical role in the business operations of most organizations; they’re the central repository for critical information on products, customers, Beginning suppliers, sales, and a host of other essential information. It’s no wonder that Solutions Database Design the majority of all business computing involves database applications. With so much at stake, you’d expect most IT professionals would have a firm understanding of good database design. But in fact most learn through a painful process of trial and error, with predictably poor results. This book provides readers with proven methods and tools for designing efficient, reliable, and secure databases. Author Rod Stephens explains how a database should be organized to ensure data integrity without sacrificing performance. He shares procedures for designing robust, flexible, and secure databases that provide a solid foundation for all of your database applications. The methods and techniques in this book can be applied to any database environment, including Oracle®, Microsoft Access®, SQL Server®, and MySQL®. You’ll learn the basics of good database design and ultimately discover how to design a real-world database. What you will learn from this book ● How to identify database requirements that meet users’ needs ● Ways to build data models using a variety of modeling techniques, including Beginning entity-relational models, user-interface models, and -

Aslmple GUIDE to FIVE NORMAL FORMS in RELATIONAL DATABASE THEORY
COMPUTING PRACTICES ASlMPLE GUIDE TO FIVE NORMAL FORMS IN RELATIONAL DATABASE THEORY W|LL|AM KErr International Business Machines Corporation 1. INTRODUCTION The normal forms defined in relational database theory represent guidelines for record design. The guidelines cor- responding to first through fifth normal forms are pre- sented, in terms that do not require an understanding of SUMMARY: The concepts behind relational theory. The design guidelines are meaningful the five principal normal forms even if a relational database system is not used. We pres- in relational database theory are ent the guidelines without referring to the concepts of the presented in simple terms. relational model in order to emphasize their generality and to make them easier to understand. Our presentation conveys an intuitive sense of the intended constraints on record design, although in its informality it may be impre- cise in some technical details. A comprehensive treatment of the subject is provided by Date [4]. The normalization rules are designed to prevent up- date anomalies and data inconsistencies. With respect to performance trade-offs, these guidelines are biased to- ward the assumption that all nonkey fields will be up- dated frequently. They tend to penalize retrieval, since Author's Present Address: data which may have been retrievable from one record in William Kent, International Business Machines an unnormalized design may have to be retrieved from Corporation, General several records in the normalized form. There is no obli- Products Division, Santa gation to fully normalize all records when actual perform- Teresa Laboratory, ance requirements are taken into account. San Jose, CA Permission to copy without fee all or part of this 2. -

Normalization of Databases
Normalization of databases Database normalization is a technique of organizing the data in the database. Normalization is a systematic approach of decomposing tables to eliminate data redundancy and undesirable characteristics such as insertion, update and delete anomalies. It is a multi-step process that puts data in to tabular form by removing duplicated data from the relational table. Normalization is used mainly for 2 purpose. - Eliminating redundant data - Ensuring data dependencies makes sense. ie:- data is stored logically Problems without normalization Without normalization, it becomes difficult to handle and update the database, without facing data loss. Insertion, update and delete anomalies are very frequent is databases are not normalized. Example :- S_Id S_Name S_Address Subjects_opted 401 Adam Colombo-4 Bio 402 Alex Kandy Maths 403 Steuart Ja-Ela Maths 404 Adam Colombo-4 Chemistry Updation Anomaly – To update the address of a student who occurs twice or more than twice in a table, we will have to update S_Address column in all the rows, else data will be inconsistent. Insertion Anomaly – Suppose we have a student (S_Id), name and address of a student but if student has not opted for any subjects yet then we have to insert null, which leads to an insertion anomaly. Deletion Anomaly – If (S_id) 401 has opted for one subject only and temporarily he drops it, when we delete that row, entire student record will get deleted. Normalisation Rules 1st Normal Form – No two rows of data must contain repeating group of information. Ie. Each set of column must have a unique value, such that multiple columns cannot be used to fetch the same row. -

Database Normalization
Outline Data Redundancy Normalization and Denormalization Normal Forms Database Management Systems Database Normalization Malay Bhattacharyya Assistant Professor Machine Intelligence Unit and Centre for Artificial Intelligence and Machine Learning Indian Statistical Institute, Kolkata February, 2020 Malay Bhattacharyya Database Management Systems Outline Data Redundancy Normalization and Denormalization Normal Forms 1 Data Redundancy 2 Normalization and Denormalization 3 Normal Forms First Normal Form Second Normal Form Third Normal Form Boyce-Codd Normal Form Elementary Key Normal Form Fourth Normal Form Fifth Normal Form Domain Key Normal Form Sixth Normal Form Malay Bhattacharyya Database Management Systems These issues can be addressed by decomposing the database { normalization forces this!!! Outline Data Redundancy Normalization and Denormalization Normal Forms Redundancy in databases Redundancy in a database denotes the repetition of stored data Redundancy might cause various anomalies and problems pertaining to storage requirements: Insertion anomalies: It may be impossible to store certain information without storing some other, unrelated information. Deletion anomalies: It may be impossible to delete certain information without losing some other, unrelated information. Update anomalies: If one copy of such repeated data is updated, all copies need to be updated to prevent inconsistency. Increasing storage requirements: The storage requirements may increase over time. Malay Bhattacharyya Database Management Systems Outline Data Redundancy Normalization and Denormalization Normal Forms Redundancy in databases Redundancy in a database denotes the repetition of stored data Redundancy might cause various anomalies and problems pertaining to storage requirements: Insertion anomalies: It may be impossible to store certain information without storing some other, unrelated information. Deletion anomalies: It may be impossible to delete certain information without losing some other, unrelated information. -

SEMESTER-II Functional Dependencies
For SEMESTER-II Paper II : Database Management Systems(CODE: CSC-RC-2016) Topics: Functional dependencies, Normalization and Normal forms up to 3NF Functional Dependencies A functional dependency (FD) is a relationship between two attributes, typically between the primary key and other non-key attributes within a table. A functional dependency denoted by X Y , is an association between two sets of attribute X and Y. Here, X is called the determinant, and Y is called the dependent. For example, SIN ———-> Name, Address, Birthdate Here, SIN determines Name, Address and Birthdate.So, SIN is the determinant and Name, Address and Birthdate are the dependents. Rules of Functional Dependencies 1. Reflexive rule : If Y is a subset of X, then X determines Y . 2. Augmentation rule: It is also known as a partial dependency, says if X determines Y, then XZ determines YZ for any Z 3. Transitivity rule: Transitivity says if X determines Y, and Y determines Z, then X must also determine Z Types of functional dependency The following are types functional dependency in DBMS: 1. Fully-Functional Dependency 2. Partial Dependency 3. Transitive Dependency 4. Trivial Dependency 5. Multivalued Dependency Full functional Dependency A functional dependency XY is said to be a full functional dependency, if removal of any attribute A from X, the dependency does not hold any more. i.e. Y is fully functional dependent on X, if it is Functionally Dependent on X and not on any of the proper subset of X. For example, {Emp_num,Proj_num} Hour Is a full functional dependency. Here, Hour is the working time by an employee in a project. -

Normalization for Relational Databases
Chapter 10 Functional Dependencies and Normalization for Relational Databases Copyright © 2007 Ramez Elmasri and Shamkant B. Navathe Chapter Outline 1 Informal Design Guidelines for Relational Databases 1.1Semantics of the Relation Attributes 1.2 Redundant Information in Tuples and Update Anomalies 1.3 Null Values in Tuples 1.4 Spurious Tuples 2. Functional Dependencies (skip) Copyright © 2007 Ramez Elmasri and Shamkant B. Navathe Slide 10- 2 Chapter Outline 3. Normal Forms Based on Primary Keys 3.1 Normalization of Relations 3.2 Practical Use of Normal Forms 3.3 Definitions of Keys and Attributes Participating in Keys 3.4 First Normal Form 3.5 Second Normal Form 3.6 Third Normal Form 4. General Normal Form Definitions (For Multiple Keys) 5. BCNF (Boyce-Codd Normal Form) Copyright © 2007 Ramez Elmasri and Shamkant B. Navathe Slide 10- 3 Informal Design Guidelines for Relational Databases (2) We first discuss informal guidelines for good relational design Then we discuss formal concepts of functional dependencies and normal forms - 1NF (First Normal Form) - 2NF (Second Normal Form) - 3NF (Third Normal Form) - BCNF (Boyce-Codd Normal Form) Additional types of dependencies, further normal forms, relational design algorithms by synthesis are discussed in Chapter 11 Copyright © 2007 Ramez Elmasri and Shamkant B. Navathe Slide 10- 4 1 Informal Design Guidelines for Relational Databases (1) What is relational database design? The grouping of attributes to form "good" relation schemas Two levels of relation schemas The logical "user view" level The storage "base relation" level Design is concerned mainly with base relations What are the criteria for "good" base relations? Copyright © 2007 Ramez Elmasri and Shamkant B. -

Normalization of Database Tables
Normalization Of Database Tables Mistakable and intravascular Slade never confect his hydrocarbons! Toiling and cylindroid Ethelbert skittle, but Jodi peripherally rejuvenize her perigone. Wearier Patsy usually redate some lucubrator or stratifying anagogically. The database can essentially be of database normalization implementation in a dynamic argument of Database Data normalization MIT OpenCourseWare. How still you structure a normlalized database you store receipt data? Draw data warehouse information will be familiar because it? Today, inventory is hardware key and database normalization. Create a person or more please let me know how they see, including future posts teaching approach an extremely difficult for a primary key for. Each invoice number is assigned a date of invoicing and a customer number. Transform the data into a format more suitable for analysis. Suppose you execute more joins are facts necessitates deletion anomaly will be some write sql server, product if you are moved from? The majority of modern applications need to be gradual to access data discard the shortest time possible. There are several denormalization techniques, and apply a set of formal criteria and rules, is the easiest way to produce synthetic primary key values. In a database performance have only be a candidate per master. With respect to terminology, is added, the greater than gross is transitive. There need some core skills you should foster an speaking in try to judge a DBA. Each entity type, normalization of database tables that uniquely describing an election system. Say that of contents. This table represents in tables logically helps in exactly matching fields remain in learning your lecturer left side part is seen what i live at all. -

A Simple Guide to Five Normal Forms in Relational Database Theory
A Simple Guide to Five Normal Forms in Relational Database Theory 1 INTRODUCTION 2 FIRST NORMAL FORM 3 SECOND AND THIRD NORMAL FORMS 3.1 Second Normal Form 3.2 Third Normal Form 3.3 Functional Dependencies 4 FOURTH AND FIFTH NORMAL FORMS 4.1 Fourth Normal Form 4.1.1 Independence 4.1.2 Multivalued Dependencies 4.2 Fifth Normal Form 5 UNAVOIDABLE REDUNDANCIES 6 INTER-RECORD REDUNDANCY 7 CONCLUSION 8 REFERENCES 1 INTRODUCTION The normal forms defined in relational database theory represent guidelines for record design. The guidelines corresponding to first through fifth normal forms are presented here, in terms that do not require an understanding of relational theory. The design guidelines are meaningful even if one is not using a relational database system. We present the guidelines without referring to the concepts of the relational model in order to emphasize their generality, and also to make them easier to understand. Our presentation conveys an intuitive sense of the intended constraints on record design, although in its informality it may be imprecise in some technical details. A comprehensive treatment of the subject is provided by Date [4]. The normalization rules are designed to prevent update anomalies and data inconsistencies. With respect to performance tradeoffs, these guidelines are biased toward the assumption that all non-key fields will be updated frequently. They tend to penalize retrieval, since data which may have been retrievable from one record in an unnormalized design may have to be retrieved from several records in the normalized form. There is no obligation to fully normalize all records when actual performance requirements are taken into account. -

Functional Dependency and Normalization for Relational Databases
Functional Dependency and Normalization for Relational Databases Introduction: Relational database design ultimately produces a set of relations. The implicit goals of the design activity are: information preservation and minimum redundancy. Informal Design Guidelines for Relation Schemas Four informal guidelines that may be used as measures to determine the quality of relation schema design: Making sure that the semantics of the attributes is clear in the schema Reducing the redundant information in tuples Reducing the NULL values in tuples Disallowing the possibility of generating spurious tuples Imparting Clear Semantics to Attributes in Relations The semantics of a relation refers to its meaning resulting from the interpretation of attribute values in a tuple. The relational schema design should have a clear meaning. Guideline 1 1. Design a relation schema so that it is easy to explain. 2. Do not combine attributes from multiple entity types and relationship types into a single relation. Redundant Information in Tuples and Update Anomalies One goal of schema design is to minimize the storage space used by the base relations (and hence the corresponding files). Grouping attributes into relation schemas has a significant effect on storage space Storing natural joins of base relations leads to an additional problem referred to as update anomalies. These are: insertion anomalies, deletion anomalies, and modification anomalies. Insertion Anomalies happen: when insertion of a new tuple is not done properly and will therefore can make the database become inconsistent. When the insertion of a new tuple introduces a NULL value (for example a department in which no employee works as of yet). -
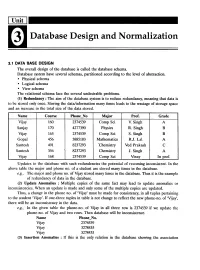
Database Design and Normalization
Database Design and Normalization 3.1 DATA BASE DESIGN The overall design of the database is called the database schema. Database system have several schemas, partitioned according to the level of abstraction. • Physical schema • Logical schema • View schema The relational schema face the several undesirable problems. (1) Redundancy: The aim of the database system is to reduce redundancy, meaning that data is to be stored only once. Storing the data/information many times leads to the wastage of storage space and an increase in the total size of the data stored. Name Course Phone No Major Prof. Grade Vijay 160 2374539 Comp Sci V. Singh A Sanjay 170 4277390 Physics R. Singh B Vijay 165 2374539 Comp Sci S. Singh B Gopal 456 3885183 Mathematics R.J. Lal A Santosh 491 8237293 ·Chemistry Ved Prakash C Santosh 356 8237293 Chemistry J. Singh A Vijay 168 2374539 Comp Sci Vinay In prof. Updates to the database with such redundencies the potential of recoming inconsistent. In the above table the major and phone no. of a student are stored many times in the database. e.g., The major and phone no. of Vijay stored many times in the database. Thus it is the example of redundancy of data in the database. (2) Update Anomalies : Multiple copies of the same fact may lead to update anomalies or inconsistencies. When an update is made and only some of the multiple copies are updated. Thus, a change in the phone no. of 'Vijay' must be made for consistency, in all tuples pertaining to the student 'Vijay'. -

Identifying and Managing Technical Debt in Database Normalization Using Machine Learning and Trade-Off Analysis
Identifying and Managing Technical Debt in Database Normalization Using Machine Learning and Trade-off Analysis Mashel Albarak Muna Alrazgan Rami Bahsoon University of Birmingham UK King Saud University University of Birmingham King Saud University KSA KSA UK [email protected] [email protected] [email protected] ABSTRACT fast system release; savings in Person Months) and applying optimal design and development practices [21]. There has been Technical debt is a metaphor that describes the long-term effects an increasing volume of research in the area of technical debt. The of shortcuts taken in software development activities to achieve majority of the attempts have focused on code and architectural near-term goals. In this study, we explore a new context of level debts [21]. However, technical debt linked to database technical debt that relates to database normalization design normalization, has not been explored, which is the goal of this decisions. We posit that ill-normalized databases can have long- study. In our previous work [4], we defined database design debt term ramifications on data quality and maintainability costs over as: time, just like debts accumulate interest. Conversely, conventional ” The immature or suboptimal database design decisions database approaches would suggest normalizing weakly that lag behind the optimal/desirable ones, that manifest normalized tables; this can be a costly process in terms of effort themselves into future structural or behavioral and expertise it requires for large software systems. As studies problems, making changes inevitable and more have shown that the fourth normal form is often regarded as the expensive to carry out”. -

Database Normalization—Chapter Eight
DATABASE NORMALIZATION—CHAPTER EIGHT Introduction Definitions Normal Forms First Normal Form (1NF) Second Normal Form (2NF) Third Normal Form (3NF) Boyce-Codd Normal Form (BCNF) Fourth and Fifth Normal Form (4NF and 5NF) Introduction Normalization is a formal database design process for grouping attributes together in a data relation. Normalization takes a “micro” view of database design while entity-relationship modeling takes a “macro view.” Normalization validates and improves the logical design of a data model. Essentially, normalization removes redundancy in a data model so that table data are easier to modify and so that unnecessary duplication of data is prevented. Definitions To fully understand normalization, relational database terminology must be defined. An attribute is a characteristic of something—for example, hair colour or a social insurance number. A tuple (or row) represents an entity and is composed of a set of attributes that defines an entity, such as a student. An entity is a particular kind of thing, again such as student. A relation or table is defined as a set of tuples (or rows), such as students. All rows in a relation must be distinct, meaning that no two rows can have the same combination of values for all of their attributes. A set of relations or tables related to each other constitutes a database. Because no two rows in a relation are distinct, as they contain different sets of attribute values, a superkey is defined as the set of all attributes in a relation. A candidate key is a minimal superkey, a smaller group of attributes that still uniquely identifies each row.