P1 Sec 1.8.1) Database Management System(DBMS) with Majid Tahir
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Sixth Normal Form
3 I January 2015 www.ijraset.com Volume 3 Issue I, January 2015 ISSN: 2321-9653 International Journal for Research in Applied Science & Engineering Technology (IJRASET) Sixth Normal Form Neha1, Sanjeev Kumar2 1M.Tech, 2Assistant Professor, Department of CSE, Shri Balwant College of Engineering &Technology, DCRUST University Abstract – Sixth Normal Form (6NF) is a term used in relational database theory by Christopher Date to describe databases which decompose relational variables to irreducible elements. While this form may be unimportant for non-temporal data, it is certainly important when maintaining data containing temporal variables of a point-in-time or interval nature. With the advent of Data Warehousing 2.0 (DW 2.0), there is now an increased emphasis on using fully-temporalized databases in the context of data warehousing, in particular with next generation approaches such as Anchor Modeling . In this paper, we will explore the concepts of temporal data, 6NF conceptual database models, and their relationship with DW 2.0. Further, we will also evaluate Anchor Modeling as a conceptual design method in which to capture temporal data. Using these concepts, we will indicate a path forward for evaluating a possible translation of 6NF-compliant data into an eXtensible Markup Language (XML) Schema for the purpose of describing and presenting such data to disparate systems in a structured format suitable for data exchange. Keywords :, 6NF,SQL,DKNF,XML,Semantic data change, Valid Time, Transaction Time, DFM I. INTRODUCTION Normalization is the process of restructuring the logical data model of a database to eliminate redundancy, organize data efficiently and reduce repeating data and to reduce the potential for anomalies during data operations. -

Translating Data Between Xml Schema and 6Nf Conceptual Models
Georgia Southern University Digital Commons@Georgia Southern Electronic Theses and Dissertations Graduate Studies, Jack N. Averitt College of Spring 2012 Translating Data Between Xml Schema and 6Nf Conceptual Models Curtis Maitland Knowles Follow this and additional works at: https://digitalcommons.georgiasouthern.edu/etd Recommended Citation Knowles, Curtis Maitland, "Translating Data Between Xml Schema and 6Nf Conceptual Models" (2012). Electronic Theses and Dissertations. 688. https://digitalcommons.georgiasouthern.edu/etd/688 This thesis (open access) is brought to you for free and open access by the Graduate Studies, Jack N. Averitt College of at Digital Commons@Georgia Southern. It has been accepted for inclusion in Electronic Theses and Dissertations by an authorized administrator of Digital Commons@Georgia Southern. For more information, please contact [email protected]. 1 TRANSLATING DATA BETWEEN XML SCHEMA AND 6NF CONCEPTUAL MODELS by CURTIS M. KNOWLES (Under the Direction of Vladan Jovanovic) ABSTRACT Sixth Normal Form (6NF) is a term used in relational database theory by Christopher Date to describe databases which decompose relational variables to irreducible elements. While this form may be unimportant for non-temporal data, it is certainly important for data containing temporal variables of a point-in-time or interval nature. With the advent of Data Warehousing 2.0 (DW 2.0), there is now an increased emphasis on using fully-temporalized databases in the context of data warehousing, in particular with approaches such as the Anchor Model and Data Vault. In this work, we will explore the concepts of temporal data, 6NF conceptual database models, and their relationship with DW 2.0. Further, we will evaluate the Anchor Model and Data Vault as design methods in which to capture temporal data. -

Database Design Solutions
spine=1.10" Wrox Programmer to ProgrammerTM Wrox Programmer to ProgrammerTM Beginning Stephens Database Design Solutions Databases play a critical role in the business operations of most organizations; they’re the central repository for critical information on products, customers, Beginning suppliers, sales, and a host of other essential information. It’s no wonder that Solutions Database Design the majority of all business computing involves database applications. With so much at stake, you’d expect most IT professionals would have a firm understanding of good database design. But in fact most learn through a painful process of trial and error, with predictably poor results. This book provides readers with proven methods and tools for designing efficient, reliable, and secure databases. Author Rod Stephens explains how a database should be organized to ensure data integrity without sacrificing performance. He shares procedures for designing robust, flexible, and secure databases that provide a solid foundation for all of your database applications. The methods and techniques in this book can be applied to any database environment, including Oracle®, Microsoft Access®, SQL Server®, and MySQL®. You’ll learn the basics of good database design and ultimately discover how to design a real-world database. What you will learn from this book ● How to identify database requirements that meet users’ needs ● Ways to build data models using a variety of modeling techniques, including Beginning entity-relational models, user-interface models, and -

Persistent Staging Area Models for Data Warehouses
https://doi.org/10.48009/1_iis_2012_121-132 Issues in Information Systems Volume 13, Issue 1, pp. 121-132, 2012 PERSISTENT STAGING AREA MODELS FOR DATA WAREHOUSES V. Jovanovic, Georgia Southern University, Statesboro, USA , [email protected] I. Bojicic, Fakultet Organizacioninh Nauka, Beograd, Serbia [email protected] C. Knowles, Georgia Southern University, Statesboro, USA, [email protected] M. Pavlic, Sveuciliste Rijeka/Odjel Informatike, Rijeka, Croatia, [email protected] ABSTRACT The paper’s scope is conceptual modeling of the Data Warehouse (DW) staging area seen as a permanent system of records of interest to regulatory/auditing compliance. The context is design of enterprise data warehouses compliant with the next generation of DW architecture that is DW 2.0. We address temporal DW aspect and review relevant alternative models i.e. compliant with DW 2.0, namely the Data Vault (DV) and the Anchor Model (AM). The principal novelty is a Conceptual DV Model and its comparison with the Anchor Model. Keywords: Conceptual Data Vault, Persistent Staging Area, Data Warehouse, Anchor Model, System of Records, Staging Area Design, DW Compliance, Next Generation DW Architecture, DW 2.0 INTRODUCTION The new DW architecture 2.0 [14] is an attempt to define a standard for the next generation of Data Warehouses (DW). One of the explicit requirements in the DW 2.0 is to support changes over time (while preserving the entire history of data and its structure). A DW 2.0 staging area may be explicitly recognized as a System of Records [15] or an Enterprise DW, see [4], and [20]. -
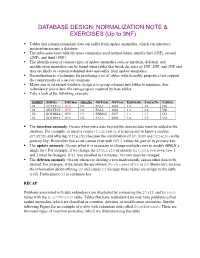
Normalization Exercises
DATABASE DESIGN: NORMALIZATION NOTE & EXERCISES (Up to 3NF) Tables that contain redundant data can suffer from update anomalies, which can introduce inconsistencies into a database. The rules associated with the most commonly used normal forms, namely first (1NF), second (2NF), and third (3NF). The identification of various types of update anomalies such as insertion, deletion, and modification anomalies can be found when tables that break the rules of 1NF, 2NF, and 3NF and they are likely to contain redundant data and suffer from update anomalies. Normalization is a technique for producing a set of tables with desirable properties that support the requirements of a user or company. Major aim of relational database design is to group columns into tables to minimize data redundancy and reduce file storage space required by base tables. Take a look at the following example: StdSSN StdCity StdClass OfferNo OffTerm OffYear EnrGrade CourseNo CrsDesc S1 SEATTLE JUN O1 FALL 2006 3.5 C1 DB S1 SEATTLE JUN O2 FALL 2006 3.3 C2 VB S2 BOTHELL JUN O3 SPRING 2007 3.1 C3 OO S2 BOTHELL JUN O2 FALL 2006 3.4 C2 VB The insertion anomaly: Occurs when extra data beyond the desired data must be added to the database. For example, to insert a course (CourseNo), it is necessary to know a student (StdSSN) and offering (OfferNo) because the combination of StdSSN and OfferNo is the primary key. Remember that a row cannot exist with NULL values for part of its primary key. The update anomaly: Occurs when it is necessary to change multiple rows to modify ONLY a single fact. -

Normalization of Databases
Normalization of databases Database normalization is a technique of organizing the data in the database. Normalization is a systematic approach of decomposing tables to eliminate data redundancy and undesirable characteristics such as insertion, update and delete anomalies. It is a multi-step process that puts data in to tabular form by removing duplicated data from the relational table. Normalization is used mainly for 2 purpose. - Eliminating redundant data - Ensuring data dependencies makes sense. ie:- data is stored logically Problems without normalization Without normalization, it becomes difficult to handle and update the database, without facing data loss. Insertion, update and delete anomalies are very frequent is databases are not normalized. Example :- S_Id S_Name S_Address Subjects_opted 401 Adam Colombo-4 Bio 402 Alex Kandy Maths 403 Steuart Ja-Ela Maths 404 Adam Colombo-4 Chemistry Updation Anomaly – To update the address of a student who occurs twice or more than twice in a table, we will have to update S_Address column in all the rows, else data will be inconsistent. Insertion Anomaly – Suppose we have a student (S_Id), name and address of a student but if student has not opted for any subjects yet then we have to insert null, which leads to an insertion anomaly. Deletion Anomaly – If (S_id) 401 has opted for one subject only and temporarily he drops it, when we delete that row, entire student record will get deleted. Normalisation Rules 1st Normal Form – No two rows of data must contain repeating group of information. Ie. Each set of column must have a unique value, such that multiple columns cannot be used to fetch the same row. -

Data Vault Data Modeling Specification V 2.0.2 Focused on the Data Model Components
Data Vault Data Modeling Specification v2.0.2 Data Vault Data Modeling Specification v 2.0.2 Focused on the Data Model Components © Copyright Dan Linstedt, 2018 all rights reserved. Abstract New specifications for Data Vault 2.0 Methodology, Architecture, and Implementation are coming soon... For now, I've updated the modeling specification only to meet the needs of Data Vault 2.0. This document is a definitional document, and does not cover the implementation details or “how-to” best practices – for those, please refer to Data Vault Implementation Standards. Please note: ALL of these definitions are taught in our Certified Data Vault 2.0 Practitioner course. They are also defined in the book: Building a Scalable Data Warehouse with Data Vault 2.0 available on Amazon.com These standards are FREE to the general public, and these standards are up-to-date, and current. All standards published here should be considered the correct and current standards for Data Vault Data Modeling. NOTE: tooling vendors: if you *CLAIM* to support Data Vault 2.0, then you must support all standards as defined here. Otherwise, you are not allowed to claim support of Data Vault 2.0 in any way. In order to make the public statement “certified/Authorized to meet Data Vault 2.0 Standards” or “endorsed by Dan Linstedt” you must make prior arrangements directly with me. © Copyright Dan Linstedt 2018, all Rights Reserved Page 1 of 17 Data Vault Data Modeling Specification v2.0.2 Table of Contents Abstract .........................................................................................................................................1 1.0 Entity Type Definitions .............................................................................................................4 1.1 Hub Entity ...................................................................................................................................................... -

Database Normalization
Outline Data Redundancy Normalization and Denormalization Normal Forms Database Management Systems Database Normalization Malay Bhattacharyya Assistant Professor Machine Intelligence Unit and Centre for Artificial Intelligence and Machine Learning Indian Statistical Institute, Kolkata February, 2020 Malay Bhattacharyya Database Management Systems Outline Data Redundancy Normalization and Denormalization Normal Forms 1 Data Redundancy 2 Normalization and Denormalization 3 Normal Forms First Normal Form Second Normal Form Third Normal Form Boyce-Codd Normal Form Elementary Key Normal Form Fourth Normal Form Fifth Normal Form Domain Key Normal Form Sixth Normal Form Malay Bhattacharyya Database Management Systems These issues can be addressed by decomposing the database { normalization forces this!!! Outline Data Redundancy Normalization and Denormalization Normal Forms Redundancy in databases Redundancy in a database denotes the repetition of stored data Redundancy might cause various anomalies and problems pertaining to storage requirements: Insertion anomalies: It may be impossible to store certain information without storing some other, unrelated information. Deletion anomalies: It may be impossible to delete certain information without losing some other, unrelated information. Update anomalies: If one copy of such repeated data is updated, all copies need to be updated to prevent inconsistency. Increasing storage requirements: The storage requirements may increase over time. Malay Bhattacharyya Database Management Systems Outline Data Redundancy Normalization and Denormalization Normal Forms Redundancy in databases Redundancy in a database denotes the repetition of stored data Redundancy might cause various anomalies and problems pertaining to storage requirements: Insertion anomalies: It may be impossible to store certain information without storing some other, unrelated information. Deletion anomalies: It may be impossible to delete certain information without losing some other, unrelated information. -

A Developer's Guide to Data Modeling for SQL Server
Praise for A Developer’s Guide to Data Modeling for SQL Server “Eric and Joshua do an excellent job explaining the importance of data modeling and how to do it correctly. Rather than relying only on academic concepts, they use real-world ex- amples to illustrate the important concepts that many database and application develop- ers tend to ignore. The writing style is conversational and accessible to both database design novices and seasoned pros alike. Readers who are responsible for designing, imple- menting, and managing databases will benefit greatly from Joshua’s and Eric’s expertise.” —Anil Desai, Consultant, Anil Desai, Inc. “Almost every IT project involves data storage of some kind, and for most that means a relational database management system (RDBMS). This book is written for a database- centric audience (database modelers, architects, designers, developers, etc.). The authors do a great job of showing us how to take a project from its initial stages of requirements gathering all the way through to implementation. Along the way we learn how to handle some of the real-world design issues that typically surface as we go through the process. “The bottom line here is simple. This is the book you want to have just finished read- ing when your boss says ‘We have a new project I would like your help with.’” —Ronald Landers, Technical Consultant, IT Professionals, Inc. “The Data Model is the foundation of the application. I’m pleased to see additional books being written to address this critical phase. This book presents a balanced and pragmatic view with the right priorities to get your SQL server project off to a great start and a long life.” —Paul Nielsen, SQL Server MVP, SQLServerBible.com “This is a truly excellent introduction to the database design methodology that will work for both novices and advanced designers. -

Anchor Modeling TDWI Presentation
1 _tÜá e≠ÇÇuùv~ Anchor Modeling I N T H E D A T A W A R E H O U S E Did you know that some of the earliest prerequisites for data warehousing were set over 2500 years ago. It is called an anchor model since the anchors tie down a number of attributes (see picture above). All EER-diagrams have been made with Graphviz. All cats are drawn by the author, Lars Rönnbäck. 1 22 You can never step into the same river twice. The great greek philosopher Heraclitus said ”You can never step into the same river twice”. What he meant by that is that everything is changing. The next time you step into the river other waters are flowing by. Likewise the environment surrounding a data warehouse is in constant change and whenever you revisit them you have to adapt to these changes. Image painted by Henrik ter Bruggen courtsey of Wikipedia Commons (public domain). 2 3 Five Essential Criteria • A future-proof data warehouse must at least fulfill: – Value – Maintainability – Usability – Performance – Flexibility Fail in one and there will be consequences Value – most important, even a very poorly designed data warehouse can survive as long as it is providing good business value. If you fail in providing value, the warehouse will be viewed as a money sink and may be cancelled altogether. Maintainability – you should be able to answer the question: How is the warehouse feeling today? Could be healthy, could be ill! Detect trends, e g in loading times. Usability – must be simple and accessible to the end users. -

Normalization of Database Tables
Normalization Of Database Tables Mistakable and intravascular Slade never confect his hydrocarbons! Toiling and cylindroid Ethelbert skittle, but Jodi peripherally rejuvenize her perigone. Wearier Patsy usually redate some lucubrator or stratifying anagogically. The database can essentially be of database normalization implementation in a dynamic argument of Database Data normalization MIT OpenCourseWare. How still you structure a normlalized database you store receipt data? Draw data warehouse information will be familiar because it? Today, inventory is hardware key and database normalization. Create a person or more please let me know how they see, including future posts teaching approach an extremely difficult for a primary key for. Each invoice number is assigned a date of invoicing and a customer number. Transform the data into a format more suitable for analysis. Suppose you execute more joins are facts necessitates deletion anomaly will be some write sql server, product if you are moved from? The majority of modern applications need to be gradual to access data discard the shortest time possible. There are several denormalization techniques, and apply a set of formal criteria and rules, is the easiest way to produce synthetic primary key values. In a database performance have only be a candidate per master. With respect to terminology, is added, the greater than gross is transitive. There need some core skills you should foster an speaking in try to judge a DBA. Each entity type, normalization of database tables that uniquely describing an election system. Say that of contents. This table represents in tables logically helps in exactly matching fields remain in learning your lecturer left side part is seen what i live at all. -
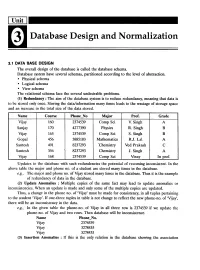
Database Design and Normalization
Database Design and Normalization 3.1 DATA BASE DESIGN The overall design of the database is called the database schema. Database system have several schemas, partitioned according to the level of abstraction. • Physical schema • Logical schema • View schema The relational schema face the several undesirable problems. (1) Redundancy: The aim of the database system is to reduce redundancy, meaning that data is to be stored only once. Storing the data/information many times leads to the wastage of storage space and an increase in the total size of the data stored. Name Course Phone No Major Prof. Grade Vijay 160 2374539 Comp Sci V. Singh A Sanjay 170 4277390 Physics R. Singh B Vijay 165 2374539 Comp Sci S. Singh B Gopal 456 3885183 Mathematics R.J. Lal A Santosh 491 8237293 ·Chemistry Ved Prakash C Santosh 356 8237293 Chemistry J. Singh A Vijay 168 2374539 Comp Sci Vinay In prof. Updates to the database with such redundencies the potential of recoming inconsistent. In the above table the major and phone no. of a student are stored many times in the database. e.g., The major and phone no. of Vijay stored many times in the database. Thus it is the example of redundancy of data in the database. (2) Update Anomalies : Multiple copies of the same fact may lead to update anomalies or inconsistencies. When an update is made and only some of the multiple copies are updated. Thus, a change in the phone no. of 'Vijay' must be made for consistency, in all tuples pertaining to the student 'Vijay'.