Munich-Edinburgh-Stuttgart Submissions at WMT13
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Stuttgart Region – Where Growth Meets Innovation Design: Atelier Brückner/Ph Oto: M
The Stuttgart Region – Where Growth Meets Innovation oto: M. Jungblut Design: Atelier Brückner/Ph CERN, Universe of Particles/ Mercedes-Benz B-Class F-Cell, Daimler AG Mercedes-Benz The Stuttgart Region at a Glance Situated in the federal state of Baden- The Stuttgart Region is the birthplace and Württemberg in the southwest of Germa- home of Gottlieb Daimler and Robert ny, the Stuttgart Region comprises the Bosch, two important figures in the history City of Stuttgart (the state capital) and its of the motor car. Even today, vehicle five surrounding counties. With a popula- design and production as well as engineer- tion of 2.7 million, the area boasts a highly ing in general are a vital part of the region’s advanced industrial infrastructure and economy. Besides its traditional strengths, enjoys a well-earned reputation for its eco- the Stuttgart Region is also well known nomic strength, cutting-edge technology for its strong creative industries and its and exceptionally high quality of life. The enthusiasm for research and development. region has its own parliamentary assembly, ensuring fast and effective decision-mak- All these factors make the Stuttgart ing on regional issues such as local public Region one of the most dynamic and effi- transport, regional planning and business cient regions in the world – innovative in development. approach, international in outlook. Stuttgart Region Key Economic Data Population: 2.7 million from 170 countries Area: 3,654 km2 Population density: 724 per km2 People in employment: 1.5 million Stuttgart Region GDP: 109.8 billion e Corporate R&D expenditure as % of GDP: 7.5 Export rate of manufacturing industry: 63.4 % Productivity: 72,991 e/employee Per capita income: 37,936 e Data based on reports by Wirtschaftsförderung Region Stuttgart GmbH, Verband Region Stuttgart, IHK Region Stuttgart and Statistisches Landesamt Baden-Württemberg, 2014 Stuttgart-Marketing GmbH Oliver Schuster A Great Place to Live and Work Top Quality of Life Germany‘s Culture Capitals 1. -

PI St Peter's Basilica
www.osram.com 1/4 Press Munich, February 19, 2018 New lighting system for St. Peter’s Basilica taking shape Initial lighting tests show that illumination of the domes is 10 times brighter than before Planning for the new LED lighting system for the world’s largest church has entered its final phase: The lighting calculations and simulations have been successfully completed. In the basilica, the LED lighting system has been tested in many areas, and everyone involved is really pleased with the results. Tests show that the illumination level of the domes is 10 times brighter than before. The new indirect lighting system also eliminates unsightly drop shadows on the circular inscription, which is carved into the wall below the cornices of the basilica. “At St. Peter’s Basilica, we are able to demonstrate our lighting expertise once again,” says Olaf Berlien, CEO of OSRAM Licht AG. “A total of 700 custom-made luminaires with more than 100,000 powerful light-emitting diodes from Regensburg brilliantly illuminate this tremendous building in a way never seen before. And our technology will bathe individual works of art and statues at the Basilica in dazzling light.” “We are really pleased with the new lighting system for St. Peter's Basilica,” said Mons. Rafael De La Serrana Villalobos, Director Department Technical Services of the Governorate of the Vatican State (Servizi Tecnici del Governatorato dello Stato della Città del Vaticano). “During the first tests, we could clearly see details of artwork in the domes that we could only guess at in the past.” The innovative LED light sources will create an unforgettable visitor experience, much like the brilliant results achieved by Osram at the Sistine Chapel and the Raphael Rooms. -

List of Doctors and Hospitals in Baden-Württemberg
List of Doctors and Hospitals in Baden-Württemberg The Frankfurt Consular District includes Hessen, Rheinland-Pfalz, Baden-Württemberg Nordrhein-Westfalen and the Saarland in the Federal Republic of Germany. (July 2014) The following is only a partial list of English-speaking medical professionals in the Frankfurt Consular District. The choice of a physician is a personal matter and the American Consulate is not in a position to make specific recommendations. The American Consulate General assumes no responsibility for the professional ability or integrity of the persons whose names appear on this list. The names are arranged alphabetically by city (according to field or specialty), and the order in which they appear has no significance. Important! American Citizens living or traveling abroad should be sure they have adequate medical insurance that will cover expenses incurred abroad. Medicare and Medicaid are only valid in the United States. Some private American medical insurance companies will pay for expenses abroad, but most require that the patient pay the bill first, then file for reimbursement. It is common practice in Germany for health care providers to expect payment up front before providing services to individuals not covered by the German health care system. The United States Consulate General does not have funding to help cover medical expenses of American citizens in Germany. Emergency phone numbers: Emergencies (all kinds): 110 Police 110 Ambulance 112 Fire 112 Poison Center for Baden-Württemberg: 0761-19240 Page 1 of 13 HOSPITALS AND CLINICS (Krankenhäuser und Kliniken) STUTTGART Bethesda Krankenhaus Stuttgart Hohenheimer Str. 21, 70184 Stuttgart GmbH Tel.: 0711-2156-0, Fax: 0711-2156-290 Website: www.bethesda-stuttgart.de Klinikum Stuttgart Bürgerhospital Tunzhofer Str. -

Rome / Vatican City, 11–14 Dec 19)
Music, Performance, Architecture (Rome / Vatican City, 11–14 Dec 19) Rome / Vatican City, Dec 11–14, 2019 Tobias C. Weißmann Music, Performance, Architecture. Sacred Spaces as Sound Spaces in the Early Modern Period International and interdisciplinary conference Conference venues: German Historical Institute in Rome (12 December, 13 December morning) Biblioteca Vallicelliana (11 December afternoon) Biblioteca Apostolica Vaticana (13 December afternoon) S. Maria in Vallicella (11 December evening) Apostolic Palace (14 December morning) Concept and scientific organisation: Prof. Dr. Klaus Pietschmann and Dr. Tobias C. Weißmann (Research Project “CANTORIA – Music and Sacred Architecture”, Johannes Gutenberg University Mainz) | German Historical Institute in Rome, Department of Music History Beginning in 15th century Italy, the polychoral musical performance practice and new compositio- nal developments in church music required the modification of venerable churches and the inte- gration of music spaces in new sacred buildings. This multifaceted change correlated with the rite and mass piety and enduringly affected the experience of liturgy and music. The most distinctive impact of this progress is epitomised by the installation of singer balconies and organ galleries on which top-class music ensembles and organists often performed and which served as stages for musical excellence. The permanent display of music advanced to become a core segment of sacred architecture while the potential of these spaces to promote identification becomes evident in numerous graffiti, as the singer pulpit in the Sistine Chapel in the Vatican exemplifies. The conference explores the complex interdependencies between architecture, acoustics, musi- cal performance practice and rite in the interdisciplinary discourse between musicology, art and architecture history. -

How to Get to Munich Re
How to get to Munich Re Secondary information Munich Re Nürnberg Königinstrasse 107, Neufahrn junction A92 Deggendorf 80802 München, Germany S1 Munich Airport Stuttgart S8 Tel.: +49 89 38 91-0 A99 A9 München-Nord www.munichre.com München-West junction us junction t b por ir U6 a A99 sa an S1 U3 e th l f t u t L u A8 h s t r 3 o p t r i s 5 e A Nordfriedhof W M S8 Munich Re has five offices in Munich. g 4 i A99 t n t i l 2 1 e R r e Detailed directions on how to get r A94 r e Giselastr. Passau r e l t there can be found on the next page. R t i Central Station München Südwest i n M München-Ost junction g U2 Messe München O junction Marienplatz s Lindau t From Munich Airport A96 Sendlinger Innsbrucker Terminals 1 and 2 Tor Ring Taxi A99 A95 Taxis are available outside the U6 A8 ter minals. The travelling time is Key: Munich Re U3 ap proximately 45 minutes. A995 Underground line U2 Garmisch- Underground line U3 Partenkirchen Underground line U6 Municipal railway S1 München-Süd Municipal railway S8 Car hire junction Salzburg Airport bus The car hire centre with its own multi-storey car park is directly in front of Area A and north of the P6 From the north There, head for Nürnberg/Salzburg multi-storey car park. The travelling Arriving on the A9 from Nuremberg, and follow the A99 to the München- time is approximately 45 minutes. -

Deutscher Städte-Vergleich Eine Koordinierte Bürgerbefragung Zur Lebensqualität in Deutschen Und Europäischen Städten*
Statistisches Monatsheft Baden-Württemberg 1/2008 Land, Kommunen Deutscher Städte-Vergleich Eine koordinierte Bürgerbefragung zur Lebensqualität in deutschen und europäischen Städten* Ulrike Schönfeld-Nastoll Die amtliche Landesstatistik untersucht Sach- nun vor und erste Ergebnisse wurden auf der verhalte und deren Veränderungen – auch für Statistischen Frühjahrstagung in Gera im März Kommunen. Sie untersucht grundsätzlich 2007 dem Fachpublikum vorgestellt. aber nicht die subjektiven Meinungen der Bürgerinnen und Bürger zu den festgestellten Erstmals ist es nun möglich, die Umfrageergeb- Sachverhalten und den Veränderungen. Das nisse der deutschen Städte miteinander zu ver- überlässt sie Demoskopen und in zunehmen- gleichen. Darüber hinaus besteht auch die Mög- dem Maße der Kommunalstatistik. Gerade die lichkeit, aus der EU-Befragung Ergebnisse der kommunalstatistischen Ämter und Dienst- anderen europäischen Städte gegenüberzu- Dipl.-Soziologin Ulrike stellen haben auf diesem Untersuchungsfeld stellen. Schönfeld-Nastoll ist einen eindeutigen Vorsprung gegenüber der Bereichsleiterin für Statistik und Wahlen der Stadt Landesstatistik. Kommunalstatistiker haben Oberhausen. das Ohr näher am Puls der Zeit und des Der EU-Fragenkatalog der Bürgerbefragung Ortes. Insgesamt wurden 23 Fragen zu drei Themen- Da in demokratisch orientierten Gesellschaften komplexen gestellt. * Ein Projekt der Städtege- die kollektiven Meinungen der Bürgerinnen meinschaft Urban Audit 1 n und des Verbands Deut- und Bürger für Entscheider und Parlamente Im ersten Komplex wurde die Zufriedenheit scher Städtestatistiker von großer Bedeutung sein können, haben mit der städtischen Infrastruktur und den (VDST). sich etwa 300 europäische Städte, darunter 40 deutsche, für ein Urban Audit entschieden. Dieses entwickelt sich zu einer europaweiten Datensammlung zur städtischen Lebensquali- S1 „Sie sind zufrieden in ... zu wohnen“ tät. Dazu werden 340 statistische Merkmale aus allen Lebensbereichen auf Gesamtstadt- ebene erhoben. -

Patton's 3Rd Army
1 75TH ANNIVERSARY OF D-DAY: PATTON’S THIRD ARMY Follow Patton’s Third Army across France, to its relief of Bastogne and attacks into Germany. Along the way, you will learn about Patton the man, the officer, and the general. See the beaches of Normandy, the fortresses of the Maginot Line, museums exhibiting the fighting, and cemeteries honoring the dead. You will walk in Patton’s footsteps and you will visit the general’s grave. A 75TH ANNIVERSARY OF RDTHE D-DAY INVASION PATTON’S 3 ARMY B 13-NIGHTS IN EUROPEBASED ON DOUBLE OCCUPANCY $6,950 PER PERSON $1,530 SINGLE OCCUPANCY SUPPLEMENT IF ROOMING ALONE $300 PER PERSON DEPOSIT TO RESERVE YOUR SEAT ★ ★ ★ ★ ★ D - D ★ ★ ay ★ ★ ★ ★ Follow Patton’s Third Army across France, to its relief of D - D ay Bastogne and invasion of Germany. Along the way, you will learn about Patton the man, the leader, and the general. See the beaches of Normandy, the fortresses of the Maginot Line, museum’s exhibitingAnniversary the fighting and cemeteries honoring the dead. You will stand6 JUNE in 2019Patton’s footsteps and you will see ★ ★ Anniversary Patton’s last resting place. ★ ★ ★ 6 JUNE 2019 ★ ★ ★ ★ ★ STEPHEN AMBROSE HISTORICAL TOURS | [email protected] | 504-821-9283 C D 75TH ANNIVERSARY OF D-DAY: PATTON’S THIRD ARMY 2 Day 1- May 30 - Overnight Flight to London Guests arrange their travel to arrive in London the following day. Day 2- May 31 - London Arrive in London this morning and check into the hotel where the entire group will gather for an evening welcome reception. -

Calibration of Artificial Athlete Berlin/Stuttgart Summary Of
Calibration of Artificial Athlete Berlin/Stuttgart Summary of Calibration Series Performed in 2000 1. Introduction and Rational The Artificial Athletes Berlin and Stuttgart were developed by the FMPA Stuttgart (Otto-Graf- Institut) of the University of Stuttgart around 1970. The tests, which are specified in the German standards DIN 18035-6 "Sports Grounds; Synthetic Surfaced Areas" and DIN 18032-2 "Sports Halls; Sports Surfaces – Requirements, Testing, Maintenance",. and have been adopted by various national and international bodies (FIH, IAAF, ASTM, ITF, CEN, FIFA, UEFA). Over the years, especially the past 10 years, modifications to these DIN standards have taken place, which were at times inconsistent, resulting in major questions and concerns regarding the proper design of the test apparatus, the test procedure, the evaluation of measurements and the accuracy of the test results. The IAAF Accredited Labs of the ISSS felt that the resolution of these uncertainties was crucial and, based on the lack of response by the DIN (Deutsches Institut für Normung = German Institute of Standardization) to professional advice, took the initiative themselves to clarify the problems involved. As a first step, the ISSS called for papers analysing the structure of the Artificial Athletes and providing solutions for the pending problems. The submitted papers were received from Mark Harrison (GB), Dr. Konrad Binder (A), Dr. John Dunlop (AU) and Hans J. Kolitzus (D). The papers were published on ISSS's website www.isss.de. In a meeting held in Le Mans (F) in September 1999, the papers and problems were discussed in depth and a unanimous resolution was passed covering all open problems. -

Typ Standort DE-Mail-Adresse
Typ Standort DE-Mail-Adresse AG Aalen [email protected] AG Achern [email protected] AG Achern -Grundbuchamt- [email protected] AG Adelsheim [email protected] AG Albstadt [email protected] AG Backnang [email protected] AG Bad Mergentheim [email protected] AG Bad Säckingen [email protected] AG Bad Saulgau [email protected] AG Bad Urach [email protected] AG Bad Waldsee [email protected] AG Baden-Baden [email protected] AG Balingen [email protected] AG Besigheim [email protected] AG Biberach an der Riß [email protected] AG Böblingen [email protected] AG Böblingen -Grundbuchamt- [email protected] AG Brackenheim [email protected] AG Breisach am Rhein [email protected] AG Bretten [email protected] AG Bruchsal [email protected] AG Buchen (Odenwald) [email protected] AG Bühl [email protected] AG Calw [email protected] AG Crailsheim [email protected] AG Donaueschingen [email protected] AG Ehingen (Donau) [email protected] AG Ellwangen (Jagst) [email protected] AG Emmendingen [email protected] AG Emmendingen -Grundbuchamt- [email protected] AG Esslingen am Neckar [email protected] AG Ettenheim [email protected] 1 AG Ettlingen [email protected] AG Freiburg im Breisgau [email protected] AG Freiburg i. -

Analysis of the Impacts of Car-Sharing in Bremen, Germany
Final report analysis of the impacts of car-sharing in bremen, germany ® www.team-red.net 2 Authors Hannes Schreier (Project director) Claus Grimm Uta Kurz Dr . Bodo Schwieger Stephanie Keßler Dr . Guido Möser Translator Sandra H . Lustig This report was carried out during the „SHARE-North“ project . The project is supported and funded by the European Union as part of the Interreg North Sea Region Programme . The “SHARE-North” project focusses on the potential of the sharing economy in mobility plan- ning . More information about “SHARE-North” can be found at www .share-north .eu . A note on terminology: The term ‘car-sharing’ in British usage is synonymous with ‘ride-sharing, carpooling, or lift-sharing’ in US usage . The term ‘car-sharing’ in US usage is synonymous with ‘car clubs’ in the UK . In the present study, which is otherwise in British English, the term ‘car-sharing’ is used in the American sense, which is also prevalent in mainland Europe . © team red 3 content Foreword: Willi Loose, Executive Director, Bundesverband CarSharing e.V. 4 1 . executive summary . 6 2 . recommendations for action . 9 2 1 . .Overview . 9 2 .2 . The findings in detail . 11 2 3. Intensifying communication in periods of transition . 15 3 . background, scope, and subject matter of this study . 17 3 1. The current structure of car-sharing opportunities . 17 3 1. 1. cambio Car-Sharing . 17 3 1. .2 . Move About . 18 3 .2 . Measures and goals of the municipality . 18 3 3. Scope and subject matter of the evaluation . 19 4 . use of various means of transportation and availability . -

The Bakers' and Confectioners' Trade Fair In
WE’RE HERE FOR YOU Your direct line to us Project management Jens Kohler Tel. +49 711 18560-2375 Fax +49 711 18560-1375 [email protected] THE BAKERS’ AND Anna Hammer Tel. +49 711 18560-2536 Fax +49 711 18560-1536 [email protected] CONFECTIONERS’ Swenja Lauppe Tel. +49 711 18560-2857 Fax +49 711 18560-1857 TRADE FAIR IN DRESDEN [email protected] Organiser Landesmesse Stuttgart GmbH Messepiazza 1, 70629 Stuttgart, Germany Tel. +49 711 18560-0 Fax +49 711 18560-2440 www.messe-stuttgart.de Partners of SACHSENBACK 13-- 15 April 2019 BÄKO eG M t itt Saxonia, the State Association of s e O ld e O u K t s Ä c B h Guilds of the Bakery Trade of Saxony, Dresden l a n d G e e Dresden Trade Fair Centre G d n a l t B g Ä o K BÄKO Erzgebirge-Vogtland eG V O / E e r g z r g i e b BÄKO Mitteldeutschland eG BÄKO Ost eG Messe Stuttgart – Your competent partner for bakers and confectioners www.sachsenback.de CITY OF CULTURE AND COMPETENT SECTOR BUSINESS METROPOLIS MEETING POINT Florence on the Elbe SACHSENBACK Dresden, the internationally recognised city of art and culture, will in SACHSENBACK is a must for the bakery and confectionery trade in the region! 2019 again host the most important trade fair for the bakery and For three whole days, the Dresden Trade Fair Centre will be the focal point for the confectionery trade in central and eastern Germany. -
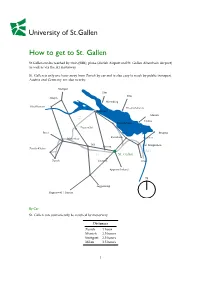
How to Get to St. Gallen
How to get to St. Gallen St.Gallen can be reached by train (SBB), plane (Zurich Airport and St. Gallen Altenrhein Airport) as well as via the A1 motorway. St. Gallen is only one hour away from Zurich by car and is also easy to reach by public transport. Austria and Germany are also nearby. Stuttgart Ulm Ulm Singen Meersburg Schaffhausen Friedrichshafen Konstanz Munich A7 Lindau Romanshorn Frauenfeld Basel Bregenz Rorschach Winterthur Altenrhein Wil St. Margrethen Gossau Zurich-Kloten A13 A1 St. Gallen Zurich Herisau Chur Appenzellerland N Toggenburg Rapperswil / Luzern By Car St. Gallen can conveniently be reached by motorway Distances Zurich 1hour Munich 2.5 hours Stuttgart 2.5 hours Milan 3.5 hours 1 By plane Zurich airport is only one hour away from St. Gallen by car or train. A direct train runs from Zurich airport to St. Gallen twice an hour. The St. Gallen-Altenrhein airport is virtually at our doorstep, 10 minutes away from Rorschach and 30 minutes from St. Gallen. Useful links Zurich Airport: http://www.flughafen-zuerich.ch/ Altenrhein Airport: http://www.stgallen-airport.ch/ By public transport Trains run from Zurich’s main train station and Zurich airport to St. Gallen every 30 minutes. The journey takes about 1 hour. There are also direct express trains from Berne (2 hours), Geneva (4 hours) and Munich (3 hours) to St. Gallen. Useful links SBB (Swiss Railway): http://www.sbb.ch 2 How to get to the University By car Take the motorway (A1) exit St. Gallen/Kreuzbleiche and head towards the centre.