St0 SORTING TECHNIQUES Hanan Samet Computer Science
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Coursenotes 4 Non-Adaptive Sorting Batcher's Algorithm
4. Non Adaptive Sorting Batcher’s Algorithm 4.1 Introduction to Batcher’s Algorithm Sorting has many important applications in daily life and in particular, computer science. Within computer science several sorting algorithms exist such as the “bubble sort,” “shell sort,” “comb sort,” “heap sort,” “bucket sort,” “merge sort,” etc. We have actually encountered these before in section 2 of the course notes. Many different sorting algorithms exist and are implemented differently in each programming language. These sorting algorithms are relevant because they are used in every single computer program you run ranging from the unimportant computer solitaire you play to the online checking account you own. Indeed without sorting algorithms, many of the services we enjoy today would simply not be available. Batcher’s algorithm is a way to sort individual disorganized elements called “keys” into some desired order using a set number of comparisons. The keys that will be sorted for our purposes will be numbers and the order that we will want them to be in will be from greatest to least or vice a versa (whichever way you want it). The Batcher algorithm is non-adaptive in that it takes a fixed set of comparisons in order to sort the unsorted keys. In other words, there is no change made in the process during the sorting. Unlike other methods of sorting where you need to remember comparisons (tournament sort), Batcher’s algorithm is useful because it requires less thinking. Non-adaptive sorting is easy because outcomes of comparisons made at one point of the process do not affect which comparisons will be made in the future. -

An Evolutionary Approach for Sorting Algorithms
ORIENTAL JOURNAL OF ISSN: 0974-6471 COMPUTER SCIENCE & TECHNOLOGY December 2014, An International Open Free Access, Peer Reviewed Research Journal Vol. 7, No. (3): Published By: Oriental Scientific Publishing Co., India. Pgs. 369-376 www.computerscijournal.org Root to Fruit (2): An Evolutionary Approach for Sorting Algorithms PRAMOD KADAM AND Sachin KADAM BVDU, IMED, Pune, India. (Received: November 10, 2014; Accepted: December 20, 2014) ABstract This paper continues the earlier thought of evolutionary study of sorting problem and sorting algorithms (Root to Fruit (1): An Evolutionary Study of Sorting Problem) [1]and concluded with the chronological list of early pioneers of sorting problem or algorithms. Latter in the study graphical method has been used to present an evolution of sorting problem and sorting algorithm on the time line. Key words: Evolutionary study of sorting, History of sorting Early Sorting algorithms, list of inventors for sorting. IntroDUCTION name and their contribution may skipped from the study. Therefore readers have all the rights to In spite of plentiful literature and research extent this study with the valid proofs. Ultimately in sorting algorithmic domain there is mess our objective behind this research is very much found in documentation as far as credential clear, that to provide strength to the evolutionary concern2. Perhaps this problem found due to lack study of sorting algorithms and shift towards a good of coordination and unavailability of common knowledge base to preserve work of our forebear platform or knowledge base in the same domain. for upcoming generation. Otherwise coming Evolutionary study of sorting algorithm or sorting generation could receive hardly information about problem is foundation of futuristic knowledge sorting problems and syllabi may restrict with some base for sorting problem domain1. -

Evaluation of Sorting Algorithms, Mathematical and Empirical Analysis of Sorting Algorithms
International Journal of Scientific & Engineering Research Volume 8, Issue 5, May-2017 86 ISSN 2229-5518 Evaluation of Sorting Algorithms, Mathematical and Empirical Analysis of sorting Algorithms Sapram Choudaiah P Chandu Chowdary M Kavitha ABSTRACT:Sorting is an important data structure in many real life applications. A number of sorting algorithms are in existence till date. This paper continues the earlier thought of evolutionary study of sorting problem and sorting algorithms concluded with the chronological list of early pioneers of sorting problem or algorithms. Latter in the study graphical method has been used to present an evolution of sorting problem and sorting algorithm on the time line. An extensive analysis has been done compared with the traditional mathematical methods of ―Bubble Sort, Selection Sort, Insertion Sort, Merge Sort, Quick Sort. Observations have been obtained on comparing with the existing approaches of All Sorts. An “Empirical Analysis” consists of rigorous complexity analysis by various sorting algorithms, in which comparison and real swapping of all the variables are calculatedAll algorithms were tested on random data of various ranges from small to large. It is an attempt to compare the performance of various sorting algorithm, with the aim of comparing their speed when sorting an integer inputs.The empirical data obtained by using the program reveals that Quick sort algorithm is fastest and Bubble sort is slowest. Keywords: Bubble Sort, Insertion sort, Quick Sort, Merge Sort, Selection Sort, Heap Sort,CPU Time. Introduction In spite of plentiful literature and research in more dimension to student for thinking4. Whereas, sorting algorithmic domain there is mess found in this thinking become a mark of respect to all our documentation as far as credential concern2. -

Comparison Sorts Name Best Average Worst Memory Stable Method Other Notes Quicksort Is Usually Done in Place with O(Log N) Stack Space
Comparison sorts Name Best Average Worst Memory Stable Method Other notes Quicksort is usually done in place with O(log n) stack space. Most implementations on typical in- are unstable, as stable average, worst place sort in-place partitioning is case is ; is not more complex. Naïve Quicksort Sedgewick stable; Partitioning variants use an O(n) variation is stable space array to store the worst versions partition. Quicksort case exist variant using three-way (fat) partitioning takes O(n) comparisons when sorting an array of equal keys. Highly parallelizable (up to O(log n) using the Three Hungarian's Algorithmor, more Merge sort worst case Yes Merging practically, Cole's parallel merge sort) for processing large amounts of data. Can be implemented as In-place merge sort — — Yes Merging a stable sort based on stable in-place merging. Heapsort No Selection O(n + d) where d is the Insertion sort Yes Insertion number of inversions. Introsort No Partitioning Used in several STL Comparison sorts Name Best Average Worst Memory Stable Method Other notes & Selection implementations. Stable with O(n) extra Selection sort No Selection space, for example using lists. Makes n comparisons Insertion & Timsort Yes when the data is already Merging sorted or reverse sorted. Makes n comparisons Cubesort Yes Insertion when the data is already sorted or reverse sorted. Small code size, no use Depends on gap of call stack, reasonably sequence; fast, useful where Shell sort or best known is No Insertion memory is at a premium such as embedded and older mainframe applications. Bubble sort Yes Exchanging Tiny code size. -

External Sorting Why Sort? Sorting a File in RAM 2-Way Sort of N Pages
Why Sort? A classic problem in computer science! Data requested in sorted order – e.g., find students in increasing gpa order Sorting is the first step in bulk loading of B+ tree External Sorting index. Sorting is useful for eliminating duplicate copies in a collection of records (Why?) Chapter 13 Sort-merge join algorithm involves sorting. Problem: sort 100Gb of data with 1Gb of RAM. – why not virtual memory? Take a look at sortbenchmark.com Take a look at main memory sort algos at www.sorting-algorithms.com Database Management Systems, R. Ramakrishnan and J. Gehrke 1 Database Management Systems, R. Ramakrishnan and J. Gehrke 2 Sorting a file in RAM 2-Way Sort of N pages Requires Minimum of 3 Buffers Three steps: – Read the entire file from disk into RAM Pass 0: Read a page, sort it, write it. – Sort the records using a standard sorting procedure, such – only one buffer page is used as Shell sort, heap sort, bubble sort, … (100’s of algos) – How many I/O’s does it take? – Write the file back to disk Pass 1, 2, 3, …, etc.: How can we do the above when the data size is 100 – Minimum three buffer pages are needed! (Why?) or 1000 times that of available RAM size? – How many i/o’s are needed in each pass? (Why?) And keep I/O to a minimum! – How many passes are needed? (Why?) – Effective use of buffers INPUT 1 – Merge as a way of sorting – Overlap processing and I/O (e.g., heapsort) OUTPUT INPUT 2 Main memory buffers Disk Disk Database Management Systems, R. -

Dynamic Algorithms for Partially-Sorted Lists Kostya Kamalah Ross
Dynamic Algorithms for Partially-Sorted Lists Kostya Kamalah Ross School of Computer and Mathematical Sciences November 3, 2015 A thesis submitted to Auckland University of Technology in fulfilment of the requirements for the degree of Master of Philosophy. 1 Abstract The dynamic partial sorting problem asks for an algorithm that maintains lists of numbers under the link, cut and change value operations, and queries the sorted sequence of the k least numbers in one of the lists. We examine naive solutions to the problem and demonstrate why they are not adequate. Then, we solve the problem in O(k · log(n)) time for queries and O(log(n)) time for updates using the tournament tree data structure, where n is the number of elements in the lists. We then introduce a layered tournament tree ∗ data structure and solve the same problem in O(log'(n) · k · log(k)) time for 2 ∗ queries and O(log (n)) for updates, where ' is the golden ratio and log'(n) is the iterated logarithmic function with base '. We then perform experiments to test the performance of both structures, and discover that the tournament tree has better practical performance than the layered tournament tree. We discuss the probable causes of this. Lastly, we suggest further work that can be undertaken in this area. Contents List of Figures 4 1 Introduction 7 1.1 Problem setup . 8 1.2 Contribution . 8 1.3 Related work . 9 1.4 Organization . 10 1.5 Preliminaries . 11 1.5.1 Trees . 11 1.5.2 Asymptotic and Amortized Complexity . -

Ijcseitr-Median First Tournament Sort
International Journal of Computer Science Engineering and Information Technology Research (IJCSEITR) ISSN(P): 2249-6831; ISSN(E): 2249-7943 Vol. 7, Issue 1, Feb 2017, 35-52 © TJPRC Pvt. Ltd. MEDIAN FIRST TOURNAMENT SORT MUKESH SONI & DHIRENDRA PRATAP SINGH Department of Computer Science & Engineering, Maulana Azad National Institute of Technology, Madhya Pradesh, India ABSTRACT Rearrangement of things for making it more usable needs a mechanism to do it with a practically possible time. Sorting techniques are most frequently used mechanism used for rearrangement. Selection of a procedure to sort something plays vital role when the amount to be sorted is large. So the procedure must be efficient in both time and space when it comes to the matter of implementation. Several sorting algorithms were proposed in past few decades and some of them like quick sort, merge sort, heap sort etc. widely using in real life scenarios since they found their way to be top on the list of sorting mechanisms ever proposed. This paper proposing a Median first Tournament Sort which practically beats quick, merge, and heap sorting mechanisms in terms of time and number of swaps required to sort. KEYWORDS: Sorting, Median, Tournament tree, Merge Sort & Heap Sort Article Original Received: Dec 07, 2016; Accepted: Jan 25, 2017; Published: Feb 01, 2017; Paper Id.: IJCSEITRFEB20175 I. INTRODUCTION To process data collections like integer list of elements or a list of string (names), computers are used widely and a great portion of its time is taken away by maintaining the data to be processed in sorted order in the first place. -

Using Tournament Trees to Sort
Polvtechnic ' lnsfitute USING TOURNAMENT TREES TO SORT ALEXANDER STEPANOV AND AARON KERSHENBAUM Polytechnic University 333 Jay Street Brooklyn, New York 11201 Center for Advanced Technology In Telecommunications C.A.T.T. Technical Report 86- 13 CENTER FOR ADVANCED TECHNOLOGY IN TELECOMMUNICATIONS Using Tournament Trees to Sort Alexander Stepanov and Aaron Kershenbaum Polytechnic University 333 Jay Street Brooklyn, New York 11201 stract We develop a new data structure, called a tournament tree, which is a generalization of binomial trees of Brown and Vuillemin and show that it can be used to efficiently implement a family of sorting algorithms in a uniform way. Some of these algorithms are similar to already known ones; others are original and have a unique set of properties. Complexity bounds on many of these algorithms are derived and some previously unknown facts about sets of comparisons performed by different sorting algorithms are shown. Sorting, and the data structures used for sorting, is one of the most extensively studied areas in computer science. Knuth [I] is an encyclopedic compendium of sorting techniques. Recent surveys have also been given by Sedgewick [2] and Gonnet [3]. The use of trees for sorting is well established. Floyd's original Treesort 183 was refined by Williams 193 to produce Heapsort. Both of these algorithms have the useful property that a partial sort can also be done efficiently: i.e., it is possible to obtain the k smallest of N elements in O[N+k*log(N)] steps. (Throughout this paper, we will use base 2 logarithms.) Recently, Brown [6] and Vuillemin [7] have developed a sorting algorithm using binomial queues, which are conceptually similar to tournament queues, but considerably more difficult to implement. -

CSE 373: Data Structure & Algorithms Comparison Sor*Ng
CSE 373: Data Structure & Algorithms Comparison Sor:ng Riley Porter Winter 2017 CSE373: Data Structures & Algorithms 1 Course Logiscs • HW4 preliminary scripts out • HW5 out à more graphs! • Last main course topic this week: Sor:ng! • Final exam in 2 weeks! CSE373: Data Structures & Algorithms 2 Introduc:on to Sor:ng • Why study sor:ng? – It uses informaon theory and is good algorithm prac:ce! • Different sor:ng algorithms have different trade-offs – No single “best” sort for all scenarios – Knowing one way to sort just isn’t enough • Not usually asked about on tech interviews... – but if it comes up, you look bad if you can’t talk about it CSE373: Data Structures & Algorithms 3 More Reasons to Sort General technique in compu:ng: Preprocess data to make subsequent opera2ons faster Example: Sort the data so that you can – Find the kth largest in constant :me for any k – Perform binary search to find elements in logarithmic :me Whether the performance of the preprocessing maers depends on – How o`en the data will change (and how much it will change) – How much data there is CSE373: Data Structures & 4 Algorithms Defini:on: Comparison Sort A computaonal problem with the following input and output Input: An array A of length n comparable elements Output: The same array A, containing the same elements where: for any i and j where 0 ≤ i < j < n then A[i] ≤ A[j] CSE373: Data Structures & 5 Algorithms More Defini:ons In-Place Sort: A sor:ng algorithm is in-place if it requires only O(1) extra space to sort the array. -

CS 603 Notes.Pdf
A.A. Stepanov - CS 603 Notes ,,,. table(k) (O<=k<m) represents the primality ,. ,. ,. of 2k+3 (define (make-sieve-table m) (define (mark tab i step m) (cond ((> m i) (vector-set! tab i #!false) (mark tab (+ i step) step m) ) ) ) (define (scan tab $35,:) (cond ((> m s) (if (vector-ref tab k) (mark tab s p m)) (scan tab (+ k 1) (+ p 2) (+ s p p 2) m)) (else tab))) (scan {make-vector m #!true) 0 3 3 m)) (define (sieve n) (let ((m (quotient (- n 1) 2))) (define (loop tab k p result m) (if (<= m k) (reverse! result) (let ( (r (if (vector-ref tab k) (cons p result) result) ) ) (loop tab (+ k 1) (+ p 2) r m) ) )) (loop (make-sieve-table m) 0 3 (list 2) m) ) ) A.A. Stepanov - CS 603 Notes . and we can do a generic version of the same (syntax (bit-set! a b) (vector-set! a b # ! false) ) ' (syntax (bit-ref a b) (vector-ref a b) ) (syntax (make-bit-table a) (make-vector a #!true)) (define (make-sieve-table m) (define (mark tab i step m) (cond ((> m i) (bit-set! tab i) (mark tab (+ i step) step m) ) ) ) (define (scan tab k p s m) (cond ((> m s) (if (bit-ref tab k) (mark tab s p m) ) (scan tab (+ k 1) (+ p 2) (+ s p p 2) m)) (else tab) )) (scan (make-bit-table m) 0 3 3 m)) (define (sieve n) (let ( (m (quotient (- n 1) 2) ) ) (define (loop tab k p result m) (if (<= m k) (reverse! result) (let ((r (if (bit-ref tab k) (cons p result) result) ) ) (loop tab (+ k 1) (+ p 2) r m)))) (loop (make-sieve-table m) 0 3 (list 2) m))) A.A. -

CSE373: Data Structure & Algorithms Comparison Sorting
Sorting Riley Porter CSE373: Data Structures & Algorithms 1 Introduction to Sorting • Why study sorting? – Good algorithm practice! • Different sorting algorithms have different trade-offs – No single “best” sort for all scenarios – Knowing one way to sort just isn’t enough • Not usually asked about on tech interviews... – but if it comes up, you look bad if you can’t talk about it CSE373: Data Structures2 & Algorithms More Reasons to Sort General technique in computing: Preprocess data to make subsequent operations faster Example: Sort the data so that you can – Find the kth largest in constant time for any k – Perform binary search to find elements in logarithmic time Whether the performance of the preprocessing matters depends on – How often the data will change (and how much it will change) – How much data there is CSE373: Data Structures & 3 Algorithms Definition: Comparison Sort A computational problem with the following input and output Input: An array A of length n comparable elements Output: The same array A, containing the same elements where: for any i and j where 0 i < j < n then A[i] A[j] CSE373: Data Structures & 4 Algorithms More Definitions In-Place Sort: A sorting algorithm is in-place if it requires only O(1) extra space to sort the array. – Usually modifies input array – Can be useful: lets us minimize memory Stable Sort: A sorting algorithm is stable if any equal items remain in the same relative order before and after the sort. – Items that ’compare’ the same might not be exact duplicates – Might want to sort on some, but not all attributes of an item – Can be useful to sort on one attribute first, then another one CSE373: Data Structures & 5 Algorithms Stable Sort Example Input: [(8, "fox"), (9, "dog"), (4, "wolf"), (8, "cow")] Compare function: compare pairs by number only Output (stable sort): [(4, "wolf"), (8, "fox"), (8, "cow"), (9, "dog")] Output (unstable sort): [(4, "wolf"), (8, "cow"), (8, "fox"), (9, "dog")] CSE373: Data Structures & 6 Algorithms Lots of algorithms for sorting.. -
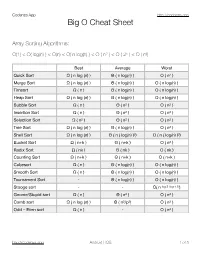
Big O Cheat Sheet
Codenza App http://codenza.app Big O Cheat Sheet Array Sorting Algorithms: O(1) < O( log(n) ) < O(n) < O( n log(n) ) < O ( n2 ) < O ( 2n ) < O ( n!) Best Average Worst Quick Sort Ω ( n log (n) ) Θ ( n log(n) ) O ( n2 ) Merge Sort Ω ( n log (n) ) Θ ( n log(n) ) O ( n log(n) ) Timsort Ω ( n ) Θ ( n log(n) ) O ( n log(n) ) Heap Sort Ω ( n log (n) ) Θ ( n log(n) ) O ( n log(n) ) Bubble Sort Ω ( n ) Θ ( n2 ) O ( n2 ) Insertion Sort Ω ( n ) Θ ( n2 ) O ( n2 ) Selection Sort Ω ( n2 ) Θ ( n2 ) O ( n2 ) Tree Sort Ω ( n log (n) ) Θ ( n log(n) ) O ( n2 ) Shell Sort Ω ( n log (n) ) Θ ( n ( log(n) )2) O ( n ( log(n) )2) Bucket Sort Ω ( n+k ) Θ ( n+k ) O ( n2 ) Radix Sort Ω ( nk ) Θ ( nk ) O ( nk ) Counting Sort Ω ( n+k ) Θ ( n+k ) O ( n+k ) Cubesort Ω ( n ) Θ ( n log(n) ) O ( n log(n) ) Smooth Sort Ω ( n ) Θ ( n log(n) ) O ( n log(n) ) Tournament Sort - Θ ( n log(n) ) O ( n log(n) ) Stooge sort - - O( n log 3 /log 1.5 ) Gnome/Stupid sort Ω ( n ) Θ ( n2 ) O ( n2 ) Comb sort Ω ( n log (n) ) Θ ( n2/p2) O ( n2 ) Odd – Even sort Ω ( n ) - O ( n2 ) http://codenza.app Android | IOS !1 of !5 Codenza App http://codenza.app Data Structures : Having same average and worst case: Access Search Insertion Deletion Array Θ(1) Θ(n) Θ(n) Θ(n) Stack Θ(n) Θ(n) Θ(1) Θ(1) Queue Θ(n) Θ(n) Θ(1) Θ(1) Singly-Linked List Θ(n) Θ(n) Θ(1) Θ(1) Doubly-Linked List Θ(n) Θ(n) Θ(1) Θ(1) B-Tree Θ(log(n)) Θ(log(n)) Θ(log(n)) Θ(log(n)) Red-Black Tree Θ(log(n)) Θ(log(n)) Θ(log(n)) Θ(log(n)) Splay Tree - Θ(log(n)) Θ(log(n)) Θ(log(n)) AVL Tree Θ(log(n)) Θ(log(n)) Θ(log(n)) Θ(log(n)) Having