A Modular Graphical Editing Architecture for Flexible Modeling
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Sysml Distilled: a Brief Guide to the Systems Modeling Language
ptg11539604 Praise for SysML Distilled “In keeping with the outstanding tradition of Addison-Wesley’s techni- cal publications, Lenny Delligatti’s SysML Distilled does not disappoint. Lenny has done a masterful job of capturing the spirit of OMG SysML as a practical, standards-based modeling language to help systems engi- neers address growing system complexity. This book is loaded with matter-of-fact insights, starting with basic MBSE concepts to distin- guishing the subtle differences between use cases and scenarios to illu- mination on namespaces and SysML packages, and even speaks to some of the more esoteric SysML semantics such as token flows.” — Jeff Estefan, Principal Engineer, NASA’s Jet Propulsion Laboratory “The power of a modeling language, such as SysML, is that it facilitates communication not only within systems engineering but across disci- plines and across the development life cycle. Many languages have the ptg11539604 potential to increase communication, but without an effective guide, they can fall short of that objective. In SysML Distilled, Lenny Delligatti combines just the right amount of technology with a common-sense approach to utilizing SysML toward achieving that communication. Having worked in systems and software engineering across many do- mains for the last 30 years, and having taught computer languages, UML, and SysML to many organizations and within the college setting, I find Lenny’s book an invaluable resource. He presents the concepts clearly and provides useful and pragmatic examples to get you off the ground quickly and enables you to be an effective modeler.” — Thomas W. Fargnoli, Lead Member of the Engineering Staff, Lockheed Martin “This book provides an excellent introduction to SysML. -

VPUML Data Sheet
Datasheet Visual Paradigm for UML 7.0 Model-Code-Deploy Platform Boost Productivity with Innovative and Intuitive Technologies – From Requirements to Code Datasheet Visual Paradigm for UML 7.0 What VP-UML Provides? UML Modeling Business Process Modeling Visualize, design, communicate and Visualize, understand, analyze and document UML 2.2 diagrams with improve business process with BPMN, intuitive and sophisticated visual Process Map, Data Flow Diagram and modeling environment. Organization Chart. Database Modeling Requirement Modeling Design, generate, reverse and synchronize Capture, organize, manage and realize database with sophisticated ERD. requirements with SysML Requirement Generate professional documentation and Diagram. Build or customize your own Java Object-Relational Mapping layer requirement types. (Hibernate). Mind Mapping Diagramming Toolset Brainstorm, outline, share and discuss Create and maintain business and concepts and idea with mind mapping engineering diagrams with Visual tool. Mind Mapping diagram nodes can Paradigm cutting edge visual modeling link to any BPMN or UML elements to toolset such as resource-centric interface, keep the traceability. mouse gesture, sweeper, magnet, styles and layer. Page 2 of 6 Datasheet Visual Paradigm for UML 7.0 What VP-UML Provides? Modeling Toolset Documentation Generation Beyond diagramming there are various Design and generate professional toolsets to improve the quality of visual documentation in PDF, MS Word 2007 modeling. Nicknamer helps maintain and HTML formats. Keeping database, single element with multiple names for program and technical specification multi-national team. Visual Diff shows up-to-date with minimal effort. differences between diagrams and revisions visually. Animating UML diagram with Animacian. Team Collaboration Interoperability & Integration Modeling collaboratively and Export, import and merge with XML, simultaneously with VP Teamwork XMI, MS Excel formats. -

Teaching UML in Moodle Environment
Teaching UML in Moodle environment Zbigniew MROZEK#1 #Malopolska Higher Vocational School in Cracow (Małopolska Wyższa Szkoła Zawodowa w Krakowie) PL 31-532 Kraków, ul W. Pola 4 1 [email protected] Abstract— This paper describes author's experience in teaching object oriented programming with UML in a After one semester of using Moodle and Blackboard for Moodle environment. different groups of students, Moodle was chosen as more suitable and more effective environment. It is less complicated and more user friendly for the teacher. I. INTRODUCTION Moreover Moodle is a public domain software and this Author is teaching object oriented programming with means that possible lack of founds will not stop using it. UML from year 1999. Moodle and Blackboard were used by author to manage educational process. After one III. UML LANGUAGE semester, Moodle was chosen as more suitable environment. UML (unified modelling language) is derived from three other products: OMT (object modelling technique) by James Rumbaugh, Booch method by Grady Booch and II. THE TEACHING ENVIRONMENT OOSE (object oriented software engineering) by Ivar The teaching environment may be called virtual learning Jacobson. From version 1.1, UML language is non- environment (VLE), Learning Management System proprietary and open to all. It is maintained by the (LMS), Course Management System (CMS), Learning standards organisation: Object Management Group Content Management System (LCMS), Managed (www.omg.org) Learning Environment (MLE), Learning Support System (LSS) or Learning Platform (LP). The actual name new product idea depends on software package used to support the process d e s i g n c o n c e p t u a l and on services offered by that package. -

UML Modelleme Araçlarının Pratik Kullanım Için Analizi
UML Modelleme Araçlarının Pratik Kullanım için Analizi Mert Ozkaya1 and Ferhat Erata2 1 Yeditepe Üniversitesi , Ataşehir, İstanbul [email protected] 2 UNIT Bilgi Teknolojileri R&D Ltd., Bornova, Izmir [email protected] Özet. Günümüzde, Unified Modeling Language(UML) pratisyenler tarafından en sık tercih edilen yazılım sistemi modelleme ve tasarlama notasyonu olarak kabul edilmektedir. UML, aynı zamanda, birçok yazılım modelleme aracı tarafın- dan desteklenmektedir, ve bu araçlar sayesinde, pratisyenler yazılım sistem- lerini kolayca UML notasyonunu kullanarak modelleyebilir ve analiz, yazılım kodu üretme, ve işbirliği gibi birçok faydalı değişik işlemler gerçekleştirebilirler. Bu çalışmada, tanınan 11 farklı UML modelleme aracını pratisyenlerin UML’i benimsemeleri açısından önemli olduğunu düşündüğümüz bir grup gereksinim bakımından analiz ettik. Bu gereksinimler başlıca, modellerin tasarımı, model analizi, modelden kod üretme, iş-birliği halinde modelleme, ve genişletilebilir- lik olmaktadır. Model tasarımı gereksinimi, modelleme araçlarının UML diya- gramlarına olan destekleri, yazılım modelleme bakış-açılarına olan destekleri, ve büyük ve karmaşık yazılım modellerinin tasarımına olan destekleri açıların- dan ele alınmaktadır. Model analizi gereksinimi, simülasyon ve doğrulama (hem önceden tanımlanmış doğrulama hem de kullanıcı tanımlı doğrulama) gereksin- imlerine olan destek bakımından incelenmektedir. İş-birliği halinde modelleme gereksinimi ise, senkron ve asenkron olarak çoklu kullanıcı desteği, görev yöne- -

Plugin for Visual Paradigm for Generating and Intelligent Optimization of a Component Diagram Based on Attributes in the Class Diagram
Journal of Software Plugin for Visual Paradigm for Generating and Intelligent Optimization of a Component Diagram Based on Attributes in the Class Diagram Carsten Mueller1, Anton Pohl2* 1 University of Economics, Informatics Department, Prague, Czech Republic 2 Baden-Wuerttemberg Cooperative State University, Mosbach, Germany * Corresponding author. Email: [email protected] Manuscript submitted January December 30, 2014; accepted February 16, 2015. doi: 10.17706/jsw.10.3. 355 -365 Abstract: In today’s software development process (SDP) it is necessary to do much preparatory work to achieve a good quality of the software. Besides the requirements engineering the design process is very important. The designer can describe all aspects of the software to be built. Excellent designing skills and the question “What makes a ‘good’ software?” are essential to create a competent “cookbook”. The plugin presented in this paper shall support designer using Visual Paradigm (VP) as a modeling-tool during their modeling process. Based on given attributes in the Class Diagram the plugin can generate and optimize intelligently a Component Diagram. Key words: Software modeling, plugin for visual paradigm, software design, software component. 1. Introduction We live in an information age where data processing becomes more important and difficult. To manage the growing amount of information the complexity of today’s software systems increases steadily. Every human that takes pictures with a camera, every sensor that for example gauges the physical condition of an electronic part, and the communication over the internet produces data. The EMC Digital Universe study estimates the amount of data growing by 40% per year [1]. -

DESKTOP INTERACTIVE ACTIVITY DIAGRAM TUTORIAL a Paper Submitted to the Graduate Faculty of the North Dakota State University
DESKTOP INTERACTIVE ACTIVITY DIAGRAM TUTORIAL A Paper Submitted to the Graduate Faculty of the North Dakota State University of Agriculture and Applied Science By AnuEvelyn Sathiaseelan In Partial Fulfillment of the Requirements for the Degree of MASTER OF SCIENCE Major Department: Software Engineering May 2015 Fargo, North Dakota North Dakota State University Graduate School Title Desktop Interactive Activity Diagram Tutorial By AnuEvelyn Sathiaseelan The Supervisory Committee certifies that this disquisition complies with North Dakota State University’s regulations and meets the accepted standards for the degree of MASTER OF SCIENCE SUPERVISORY COMMITTEE: Kenneth Magel Chair Kendall Nygard Hyunsook Do Wendy Troop Approved: 07/08/2015 Dr. Brian Slator Date Department Chair ABSTRACT Activity diagram plays a vital role in Business Process Modeling as well as System modeling. In this paper, I have proposed a desktop interactive activity diagram tutorial that has been designed for educational purposes to help someone to construct activity diagram with the following features: (1) There is continuous interaction between the user and the system; (2) It provides ongoing feedback and performance updates to the user after every topic within the chapter; (3) the tutorial will generate a “Certificate of excellence” with the percentage scored if only the user has scored above 90 percentages and the certificate will be send to the user’s given email address; (4) This interactive tutorial is extensible and acts like framework in the sense that, the database is designed in such a way that new tutorials can be added to the existing application without any modification to the front end. iii ACKNOWLEDGMENTS The author wishes to express her deep appreciation and gratitude to her advisor, Dr. -

Plug-In User Guide 0
Plug-in User Guide 0 - 1 Plug-in User Guide 0 - 2 Plug-in User Guide Plug-in User’s Guide The software and documentation are furnished under the Visual Paradigm license agreement and may be used only in accordance with the terms of the agreement. Copyright Information Copyright © 1999-2005 by Visual Paradigm. All rights reserved. The material made available by Visual Paradigm in this document is protected under the laws and various international laws and treaties. No portion of this document or the material contained on it may be reproduced in any form or by any means without prior written permission from Visual Paradigm. Every effort has been made to ensure the accuracy of this document. However, Visual Paradigm makes no warranties with respect to this documentation and disclaims any implied warranties of merchantability and fitness for a particular purpose. The information in this document is subject to change without notice. All examples with names, company names, or companies that appear in this document are imaginary and do not refer to, or portray, in name or substance, any actual names, companies, entities, or institutions. Any resemblance to any real person, company, entity, or institution is purely coincidental. Trademark Information Visual Paradigm for UML, Smart Development Environment is registered trademark of Visual Paradigm. Sun, Sun ONE, Java, Java2, J2EE and EJB, NetBeans are all registered trademarks of Sun Microsystems, Inc. Eclipse is registered trademark of Eclipse IBM, WebSphere are registered trademark of International Business Machines Corporation. JBuilder is registered trademark of Borland Corporation. IntelliJ and IntelliJ IDEA are registered trademarks of JetBrains. -

UML-Tools 2.0 Intern
Software Systems E ngineering H. Eichelberger, Y. Eldogan, K. Schmid A Comprehensive Analysis of UML Tools, their Capabilities and their Compliance August 2011 Version 2.0 IfI Report Nr. 1/2012 Software Systems Engineering Institut für Informatik Universität Hildesheim Marienburger Platz 22 D-31134 Hildesheim A comprehensive survey of UML tool capabilities and compliance A comprehensive survey of UML tool capabilities and compliance Executive Summary The Unified Modeling Language (UML) has been widely adopted in software engineering prac- tice in industry over the last decade. A large range of different tools have been developed both from industrial providers as well as open source tools. However, due to the complexity of the UML specification it is very difficult for a single tool to support the full range of UML stand- ards faithfully. In practice tools differ significantly in terms of the parts of the UML specifica- tion they support. The decision of a development organization for a specific tool environment is a very significant one, which typically leads to a significant amount of costs (e.g., in terms of training), out of which the licensing costs, though significant, are often only a minor part. Thus, the tool needs to be chosen with very much care. As one aid towards a rational tool selection decision, this report provides the most comprehensive comparison of UML tools currently available. This study provides the most comprehensive assessment of the current tool support. It combines a detailed information collection effort for each individual tool, a broad range of tools analyzed and also analyzed UML compliance as defined by the OMG. -
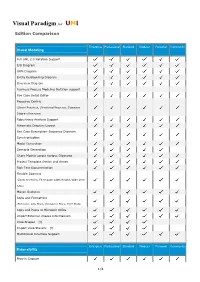
Visual Paradigm for UML
Visual Paradigm for UML Edition Comparison Enterprise Professional Standard Modeler Personal Community Visual Modeling Full UML 2.0 Notation Support EJB Diagram ORM Diagram Entity Relationship Diagram Overview Diagram Business Process Modeling Notation support Use Case Detail Editor Resource Centric (Smart Resource, Structured Resource, Sequence Diagram Resource) Robustness Analysis Support Automatic Diagram Layout Use Case Description-Sequence Diagram Synchronization Model Generation Scenario Generation Share Models across various Diagrams Project Template Design and Reuse Rich Text Documentation Flexible Zooming (Zoom to region, Fit to page width/height, Wide zoom ratio) Mouse Gestures Style and Formatting (Fill Color, Line Style, Connector Style, Font Style) Copy and Paste to Microsoft Office Import External Images into Diagram Visio Shapes [1] Import Visio Stencils [1] Multilingual Interface Support Enterprise Professional Standard Modeler Personal Community Extensibility Plug-in Support 1/4 Enterprise Professional Standard Modeler Personal Community Documentation Printing Export Diagrams to Image Files (JPG, PNG, SVG and EMF) HTML Documentation Generation PDF Documentation Generation Ad Hoc Document Generation with Customizable Style and Layout [2] Project Publisher Enterprise Professional Standard Modeler Personal Community Requirement Capturing Textual Analysis CRC Card Business Workflow Diagram Enterprise Professional Standard Modeler Personal Community Interoperability XMI Import (XMI 1.0/1.2/2.1 for UML 1.x or 2.0) Rose Project -
Introduction to UML and Sysml
ENES 489P Hands-On Systems Engineering Projects Introduction to UML and SysML Mark Austin E-mail: [email protected] Institute for Systems Research, University of Maryland, College Park – p. 1/75 Systems Engineering with UML and SysML Topics: 1. Motivation and Approach 2. What are UML and SysML? 3. System Development Processes 4. System Architecture View (new to UML 2.0) 5. Behavior Modeling with Activity and Sequence Diagrams 6. Finite State Machines and Statecharts 7. Case Study: Operation of a Museum 8. Case Study: Operation of a Traffic Intersection – p. 2/75 Need for Visual Modeling Languages Motivation – What’s wrong with the traditional way of doing things? TRADITIONAL MODEL −− Textual requirements can be ambiguous. WORKING WITH UML / SysML Source: Adapted from http://bulldozer00.wordpress.com/uml-and-sysml/ – p. 3/75 Need for Visual Modeling Languages Motivation – Looking Ahead Because future engineering systems will be more complex than today, designers will need to be more productive ... ... just to keep the duration and economics of design development in check. System Gaps in Capability Upper limit for complexity Complexity of systems that can be designed. Design Productivity Validation Productivity Time Future designs will also need to be more agile than in the past. – p. 4/75 Need for Visual Modeling Languages Finding a way to Move Forward The pathway forward can be found by looking to the past, where ... ... major increases in designer productivity have nearly always been accompanied by new methods for solving problems at higher levels of abstraction. Therefore, we seek ... ... new ways of working at higher levels of abstraction, and .. -
Visual Paradigm Quick Start
Visual Paradigm Quick Start Last update: Apr 15, 2014 © Copyright 2002-2014 Visual Paradigm International Ltd. Visual Paradigm Quick Start Table of Contents Table of Contents................................................................................................................................................... 2 Getting Started ...................................................................................................................................................... 3 Installing Visual Paradigm............................................................................................................................................................. 3 Starting Visual Paradigm .............................................................................................................................................................. 3 The Environment .......................................................................................................................................................................... 5 Saving and Opening Project.......................................................................................................................................................... 5 Basic Diagramming Techniques .............................................................................................................................. 6 Creating Diagram ......................................................................................................................................................................... -
Unified Modeling Language (UML) What Is UML? Object Management
Unified Modeling Language (UML) Object Management Group (OMG) ● An international, open membership, not-for-profit technology standards consortium that was founded in 1989. https://www.omg.org/ Péter Jeszenszky ● Standards: Faculty of Informatics, University of Debrecen – MetaObject Facility (MOF) https://www.omg.org/mof/ [email protected] – Model Driven Architecture (MDA) https://www.omg.org/mda/ – Systems Modeling Language (SysML) Last modified: April 11, 2021 https://www.omg.org/spec/SysML/ – Unified Modeling Language (UML) https://www.uml.org/ – XML Metadata Interchange (XMI) https://www.omg.org/spec/XMI/ – … 3 What is UML? History ● „The OMG's Unified Modeling Language (UML) ● UML is based on other object-oriented methodologies for helps you specify, visualize, and document software systems development: models of software systems, including their – Booch (Grady Booch) structure and design [...]. (You can use UML for – OMT (Object-Modeling Technique) (James E. Rumbaugh et al.) business modeling and modeling of other non- – OOSE (Object-Oriented Software Engineering) (Ivar Jacobson) software systems too.)” ● „Three Amigos”: Booch, Jacobson, and Rumbaugh – UML were developed under their leadership. – See: Introduction To OMG's Unified Modeling ● Language See also: https://www.omg.org/UML/what-is-uml.htm – The Unified Modeling Language – Versions of UML Versions of UML https://www.uml-diagrams.org/ 2 4 Current Standards XML Metadata Interchange (XMI) ● OMG Unified Modeling Language (OMG UML) Version 2.5.1. ● An XML format for metadata exchange between December 2017. https://www.omg.org/spec/UML/2.5.1/ applications. ● Diagram Definition (DD) Version 1.1. June 2015. https://www.omg.org/spec/DD/1.1/ ● Most often, it is used for the exchange of UML ● XML Metadata Interchange (XMI) Version 2.5.1.