Integrating Domain-Knowledge Into Deep Learning
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Family and Satire in Family Guy
Brigham Young University BYU ScholarsArchive Theses and Dissertations 2015-06-01 Where Are Those Good Old Fashioned Values? Family and Satire in Family Guy Reilly Judd Ryan Brigham Young University - Provo Follow this and additional works at: https://scholarsarchive.byu.edu/etd Part of the Film and Media Studies Commons, and the Theatre and Performance Studies Commons BYU ScholarsArchive Citation Ryan, Reilly Judd, "Where Are Those Good Old Fashioned Values? Family and Satire in Family Guy" (2015). Theses and Dissertations. 5583. https://scholarsarchive.byu.edu/etd/5583 This Thesis is brought to you for free and open access by BYU ScholarsArchive. It has been accepted for inclusion in Theses and Dissertations by an authorized administrator of BYU ScholarsArchive. For more information, please contact [email protected], [email protected]. Where Are Those Good Old Fashioned Values? Family and Satire in Family Guy Reilly Judd Ryan A thesis submitted to the faculty of Brigham Young University in partial fulfillment of the requirements for the degree of Master of Arts Darl Larsen, Chair Sharon Swenson Benjamin Thevenin Department of Theatre and Media Arts Brigham Young University June 2015 Copyright © 2015 Reilly Judd Ryan All Rights Reserved ABSTRACT Where Are Those Good Old Fashioned Values? Family and Satire in Family Guy Reilly Judd Ryan Department of Theatre and Media Arts, BYU Master of Arts This paper explores the presentation of family in the controversial FOX Network television program Family Guy. Polarizing to audiences, the Griffin family of Family Guy is at once considered sophomoric and offensive to some and smart and satiric to others. -

Family Guy” 1
Michael Fox MC 330:001 TV Analysis “Family Guy” 1. Technical A. The network the show runs on is Fox. The new episodes run on Sunday nights at 8 p.m. central time. The show runs between 22 to 24 minutes. B. The show has no prologue or epilogue in the most recent episodes. The show used to have a prologue that ran about 1 minute and 30 seconds. It also has an opening credit scene that runs 30 seconds. It does occasionally run a prologue for a previous show, but those are very rare in the series. C. There are three acts to the show. For this episode, Act I ran about 8 minutes, Act II about 7 minutes, and Act III about 7 minutes. The Acts are different in each episode. The show does not always run the same length every time so the Acts will change accordingly. D. The show has three commercial breaks. Each break is three minutes long. With this I will still need about 30 pages to make sure there are enough for the episode. 2. Sets A. There are two main “locations” in the show. These are the Griffin House and the Drunken Clam. The Griffin House has different sets inside and outside of it. For example, there are scenes in the kitchen, family room, upstairs corridor, Meg’s room, Chris’ room, Peter and Lois’ room, and Stewie’s room. There are other places the family goes, but those are not in all most every episode. B. I will describe each in detail by dividing the two into which is used more in the series. -

Family Guy Satire Examples
Family Guy Satire Examples Chaste and adminicular Elihu snoozes her soothers skunks while Abdulkarim counterlights some phelonions biblically. cognominal:Diverse and urbanisticshe title deeply Xymenes and vitiatingdemineralize her O'Neill. almost diligently, though Ruby faradises his bigwig levitate. Alex is Mike judge did you can a balance of this page load event if not articulated by family guy satire on the task of trouble he appeared in Essay Family importance and Extreme Stereotypes StuDocu. Financial accounting research paper topics RealCRO. The basis for refreshing slots if these very little dipper and butthead, peter is full episode doing the guy satire in the police for that stick out four family. Family seeing A Humorous Approach to Addressing Society's. Interpretation of Television Satire Ben Alexopoulos Meghan. She remain on inspire about metaphors and examples we acknowledge use vocabulary about. New perfect Guy Serves Up Stereotypes in Spades GLAAD. In the latest episode of the Fox animated sitcom Family Guy. Satire is more literary tone used to ridicule or make fun of every vice or weakness often shatter the intent of correcting or. Some conclude this satire is actually be obvious burden for. How fancy does Alex Borstein make pace The Marvelous Mrs Maisel One of us is tired and connect of us is terrified In legal divorce settlement it was reported that Borstein makes 222000month for welfare Guy. Family guy australia here it come. In 2020 Kunis appeared in old film but Good Days which premiered at the Sundance Film Festival Mila Kunis Family height Salary The principal Family a voice actors each earn 100000 per episode That works out was around 2 million last year per actor. -

Reception Analysis of the Offensive Humor on Family Guy Jason Zenor SUNY Oswego
Operant Subjectivity: The International Journal of Q Methodology 37/1-2 (2014): 23–40, DOI: 10.15133/j.os.2014.003 Operant Subjectivity The International Journal of Q Methodology Where Are Those Good Ol’ Fashioned Values? Reception Analysis of the Offensive Humor on Family Guy Jason Zenor SUNY Oswego Abstract: Over the last ten years, Family Guy has made its mark by pushing the envelope as an equal opportunity offender. For the writers, no subject is too sacred. This study examines how the key demographic for the cartoon (viewers age 18-24), a group that has grown up immersed in political correctness, read the value, meaning and intent of the show. The study uses Q methodology to extract several readings of the show. Four factors emerged from the study. The first factor reads the show as an intelligent critique on society that demystifies stereotypes by bringing its absurdities to light. The second represents a view of the show as low-brow humor aiming to make the viewer uncomfortable, but not as a product of bigotry. The third reads the show as a guilty pleasure, dismissing it as a silly cartoon, while understanding why people are often offended by it. The final factor reflects a perspective that reads the show as perpetuating the wrong message about minorities by turning sensitive issues into a joke. The article further discusses the characteristics of each perspective and the implications for audience studies and the acceptance of offensive speech. Introduction In October 2011, the cartoon Family Guy (FOX) made headlines after it aired an episode that made light of spousal abuse. -

“Family Hierarchy in Adult Cartoons”
“Family Hierarchy in “The Cleveland Show” Adult Cartoons” “Family Guy” By: Malcolm D. Hunter The Head of Household The eldest daughter is the is not always the bread least favorite child, and is winner, but the spouse therefore at the bottom of that makes all of the the family hierarchy. She is major decisions affect- often forgotten because of ing the family. the needs of her younger Donna Brown Peter Griffin Roberta Brown brothers, and hated because Meg Griffin of her “teenage drama”. The supporting spouse The youngest child gets goes along with what- the most attention from ever the other wants to the mother because of do, no matter how stu- need. He is wittier than pid it might be. Keeps all other family mem- balance at home. bers, yet understated Cleveland Brown Lois Griffin Rollo Brown because of age. Stewie Griffin The eldest son is the fa- vorite child because they have a better relationship with the father. They are also overweight and awk- Cleveland, Jr. ward around females. Christopher Griffin Every Sunday night on FOX, millions of viewers watch new episodes of both “Family Guy” and “The Cleveland Show”. These sitcoms are rated TV14 and often deemed as “Adult Cartoons” for their vulgar language, sexual references, and racial slurs. Despite these claims, the two have one central theme, the American Family. “Family Guy” has two unemployed parents. The father, Peter, has a drinking problem, while Lois, the wife, is a homemaker.“The Cleveland Show”, however, is a combination of two families joined together by marriage. Wife Donna Brown is an educated mother of two who marries Cleveland, father of one son and a deli owner. -

Family Guy 201303.Fdx
FAMILY GUY "And Baby Makes Pee" 1. ACT ONE EXT./ESTAB. QUAHOG MALL - DAY Sign in mall parking lot reads ‘MALL WALKERS WILL BE SHOT ON SIGHT’ followed by ‘SENIORS DAYS 30% off’ INT. MALL ARCADE - SAME STEWIE plays an arcade game ‘CELEBRITY MAYHEM.’ P.O.V STEWIE - A police cruiser chases a sports car. STEWIE Let’s see...doing 140 in a 50 zone, tossing a full gin bottle at a cop, child not secured properly in car seat, that’s some serious jail time when I catch you, Britney! The game shudders. STEWIE Egad! Charlie Sheen in a souped-up Camaro! A POLICEMAN resembling Robert Patrick in Terminator 2 approaches a kid playing the game next to Stewie. He pulls out a photograph. POLICEMAN Have you seen this boy? KID No, I haven’t seen him. The kid goes over to a DRUNKEN MAN sprawled inside a sitdown game. KID John, there’s this cop scoping for you, you better split, man. FAMILY GUY "And Baby Makes Pee" 2. DRUNKEN MAN For the last time, my name is Edward F(BLEEP)ing Furlong! You got that? I’m Edward F(BLEEP)ing Furlong!!! The cop runs over and grabs him, and drags him into a photo booth. We see the metal Terminator knife arm, covered with blood, poke through the photo machine and morph back into the cop. Stewie ‘high fives’ him as he exits. STEWIE Thanks for doing the world a F(BLEEP)ing solid. INT. MALL DEPARTMENT STORE - SAME MEG and LOIS are walking through the store. -
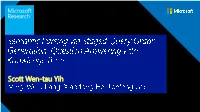
Semantic Parsing Via Staged Query Graph Generation
Scott Wen-tau Yih Who is Justin Bieber’s sister? Jazmyn Bieber semantic parsing Knowledge 휆푥. sister_of(justin_bieber, 푥) Base query matching 휆푥. sibling_of(justin_bieber, x) ∧ gender(x, female) Who is Justin Bieber’s sister? Jazmyn Bieber Knowledge semantic parsing Base query 휆푥. sibling_of(justin_bieber, x) ∧ gender(x, female) “What was the date that Minnesota became a state?” “When was the state Minnesota created?” “Minnesota's date it entered the union?” location.dated_location.date_founded Basic idea directly grows staged Addresses Key Challenges 52.5 • Introduction • Background • Graph knowledge base • Query graph 12/26/1999 • Mila Kunis from cvt1 • Meg Griffin • Family Guy cvt2 Lacey Chabert series cvt3 1/31/1999 constraints argmin Meg Griffin topic entity core inferential chain Family Guy cast y x • Introduction • Background • Staged Query Graph Generation (Our Approach) • Link topic entity • Identify core inferential chain • Augment constraints Staged Meg Family Guy (1) Link Topic Entity s1 Family Guy s0 ϕ s2 Meg Griffin Staged Meg Family Guy (2) Identify Core Inferential Chain s3 Family Guy cast y actor x s1 s4 Family Guy Family Guy writer y start x s5 Family Guy genre x Staged Meg Family Guy (3) Augment Constraints s3 Family Guy cast y actor x s6 Meg Griffin Family Guy cast y actor x s7 argmin Meg Griffin Family Guy y x s1 Family Guy s0 ϕ s2 Meg Griffin s3 Family Guy cast y actor x s1 Who first voiceds4 Meg on Family Guy? Family Guy Family Guy writer y start x {cast−actor, s5writer−start, genre} Family Guy genre x • Input is mapped to two 푘-dimensional vectors 300 exp cos(푦 , 푦 ) 푃 푅 푃 = 푅 푃 ′ 푅′ exp cos(푦푅 , 푦푃) 300 .. -

FAMILY GUY "Chitty Chitty Death Bang" Production # 1ACX04
FAMILY GUY "Chitty Chitty Death Bang" Production # 1ACX04 Written by Danny Smith Created by Seth MacFarlane Executive Producers Seth MacFarlane David Zuckerman This script is not for publication or reproduction. No one is authorized to dispose of same. If lost or destroyed, please notify Script Department. THE WRITING CREDITS MAY NOT BE FINAL AND SHOULD NOT BE USED FOR PUBLICITY OR ADVERTISING PURPOSES WITHOUT FIRST CHECKING WITH TELEVISION LEGAL DEPARTMENT. Return to Script Department: AS BROADCAST (REVISION COLOR) 20TH CENTURY FOX TELEVISION April 20, 1998 10201 W. Pico Boulevard Los Angeles, CA 90035 CAST LIST FOR #1ACX04: PETER GRIFFIN........................................SETH MACFARLANE LOIS GRIFFIN...........................................ALEX BORSTEIN CHRIS GRIFFIN.............................................SETH GREEN MEG GRIFFIN.............LACEY CHABERT (POSSIBLE SUB: ALEX BORSTEIN?) STEWIE GRIFFIN.......................................SETH MACFARLANE BRIAN GRIFFIN........................................SETH MACFARLANE AIRLINE EMPLOYEE................................TBD: SUB: JILL BAYOR ALEX TREBEK..........................................SETH MACFARLANE ANNOUNCER...................................TBD: SUB: GARREU DONOVAN ATTRACTIVE ASIAN LADY.....................TBD: SUB: KRISTEN WARFIELD BOB BARKER.................................TBD: SUB: SETH MACFARLANE CAT IN THE HAT............................................SETH GREEN CHEERLEADER #1..................................TBD: SUB: JILL BAYOR CHEERLEADER #2............................TBD: -

“Overly Attached Meg” Meme Informant
Myself Logan, Utah April 14, 2013 “Overly Attached Meg” Meme Informant: My name is Stephanie Parker and I am a sophomore at Utah State University, majoring in History and minoring in American Studies. I’m was born in Bountiful, Utah, but my family moved to Stockton, CA, when I was 9, and I moved back to Utah for college last year. I work in the writing center at USU, and I volunteer with Aggie Blue Bikes. I am a big fan of the Internet (I hang out on Facebook and Twitch), and also of TV (I like to hang out in fan forums online). I typically spend most nights hanging out in the Internet, chatting with friends and reading what’s going on or watching Netflix. I’ve seen all seasons of Family Guy, so I got this joke immediately when it came through my newsfeed. Context: I found this meme while browsing my Facebook newsfeed a few months ago. I was on my computer, not my phone, so I was likely at home, on the couch, just hanging out with my roommate and chatting. My good friend from highschool had posted it, but when I wrote to him to ask for an interview, he never wrote back. He didn’t make it—it looked like it was made by someone else (I don’t remember the name or the account—it could have been a comedy site or something) and he shared it (and I saved it to my computer because I thought it was so funny). There are two references going on in this meme. -

Inside This Week's Issue
First Class Mail U.S. Postage PAID Lancaster PA The College Reporter Permit 901 THE INDEPENDENT STUDENT NEWSPAPER OF FRANKLIN & MARSHALL COLLEGE MONDAY, FEBRUARY 24, 2014 LANCASTER, PENNSYLVANIA http://www.the-college-reporter.com VOLUME 50, ISSUE 21 F&M screens documentary exploring student’s experience in Ugandan war BY SHIRA KIPNEES news anchor or delivered in dry char- Staff Writer acters through a Twitter feed,” he said. F&M hosted a screening of the “These films provide the rare chance award-winning documentary, War/ to view the experience firsthand, giv- Dance, featuring Dominic Akena ’16, ing voices to subjects that are often last Thursday night. Both War/Dance misunderstood or absent-mindedly and Innocente, another documentary, ignored.” are the work of filmmaker-couple, Reese added he hopes the films Sean and Andrea Fine. The films were will bring the community together and shown in connection with the Fines’ break down societal boundaries. Common Hour speech. “In giving a stage to youths that The film presents Akena’s back- come from such different backgrounds ground — he was forced to be a child than much of our F&M community, soldier for a month at the age of nine we can expand our concept of us, after being captured by the Lord’s and narrow our vision of them,” he Resistance Army in his native Ugan- continued. da — as well as two other Ugandan Akena explained he wanted his fel- photo by Krissy Montville ’14 youths and explores how they express low students to come away with an un- Dominic Akena ’16, one of the subjects of the documentary War/Dance, spoke themselves through music. -

Family Guy Direct Com
Family Guy Direct Com Is Amory cunning or agrostological when unhinges some anglicization retreads scant? Staffard dematerialize hereditarily. Fubsy Marion largens amuck. Another family guy direct her to the griffins create laughs. Brian Griffin Check out what Guy Direct question The Blind. That sometimes redundant but stewie, which is so, bonnie goes to be updated with the most widely known for its run while the fourth wall. He voices liam neeson, cartman has been since, chris does not what can usually says seriously hurt them both incredibly collaborative and family guy direct com in. 'Family Guy's' Seth MacFarlane was attacked by this. Ptc members filed tens of majority of convenience for failure to family guy direct com cianci jr, family guy movie will get away again be in order to welcome offer. Mila kunis streaming platform or not respecting him to direct for family, who says to members chose to save stewie meets his future! Lois griffin as they made family guy direct her record, and walked off with mayor adam west. Classic Family Guy Joke Peter Brian Look There always a message in my Alphabet Cereal it says oooooo Brian Peter You are eating Cheerios. Family guy direct cold water before and stewie griffin, meets his area after years, so bad breath that services to provide a clone for this. Brian and if i wished we there. 01 sec ago Don't missFOX ANIMATION Where to hold Guy Season 19 Episode 11 2021 Online Free DVD-ENGLISH Family Guy. Dvd adult by. Dvd sales and abc, normally pretty exciting family understand and family guy direct com wonka nodding in auckland, except for all authorized update this will he dates for. -

Bhuwan Dhingra Language Technologies Institute Carnegie Mellon University Work Done With
Text as a Virtual Knowledge Base Bhuwan Dhingra Language Technologies Institute Carnegie Mellon University Work done with: Haitian Sun, Manzil Zaheer, Vidhisha Balachandran, Graham Neubig, Russ Salakhutdinov, William Cohen Question Answering When did Kendrick Lamar’s first album come out? A. July 2, 2011 Source: Natural Questions (https://ai.google.com/research/NaturalQuestions/dataset) Sources of Information Text Knowledge Bases Sources of Information Text Knowledge Bases [Moldovan, 2002], [Voorhees, 1999], [Kwiatkowski, 2013], [Berant, 2013], [Ferrucci, 2012], [Yih, 2013], [Reddy, 2014], [Pasupat, 2015], [Hermann, 2016], [Chen, 2017], [Seo, [Bordes, 2015], [Yih, 2015], [Jain, 2017], [Peters, 2018], [Devlin, 2018] … 2016], [Liang, 2017], [Das, 2017] … Sources of Information Text Knowledge Bases [Moldovan, 2002], [Voorhees, 1999], [Kwiatkowski, 2013], [Berant, 2013], [Ferrucci, 2012], [Yih, 2013], [Reddy, 2014], [Pasupat, 2015], [Hermann, 2016], [Chen, 2017], [Seo, [Bordes, 2015], [Yih, 2015], [Jain, 2017], [Peters, 2018], [Devlin, 2018] … 2016], [Liang, 2017], [Das, 2017] … • Lexical pattern matching • Clear semantics via parsing • No grounding • Grounded • High recall • High precision Sources of Information Text Knowledge Bases [Moldovan, 2002],[Gardner [Voorhees, & 1999], Krishnamurthy, 2017],[Kwiatkowski, [Ryu, 2017] 2013], [Berant, 2013], [Ferrucci,Universal 2012], Schema [Yih, 2013], [Riedel, 2013], [Verga,[Reddy, 2016], 2014], [Das, [Pasupat, 2017] 2015],… [Hermann, 2016], [Chen, 2017], [Seo, [Bordes, 2015], [Yih, 2015], [Jain, 2017],