Artistic Multiprojection Rendering
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Tamara Munzner Department of Computer Science University of British Columbia
Ch 3: Task Abstraction Paper: Design Study Methodology Tamara Munzner Department of Computer Science University of British Columbia CPSC 547, Information Visualization Day 4: 22 September 2015 http://www.cs.ubc.ca/~tmm/courses/547-15 News • headcount update: 29 registered; 24 Q2, 22 Q3 – signup sheet: anyone here for the first time? • marks for day 2 and day 3 questions/comments sent out by email – see me after class if you didn’t get them – order of marks matches order of questions in email • Q2: avg 83.9, min 26, max 98 • Q3: avg 84.3, min 22, max 98 – if you spot typo in book, let me know if it’s not already in errata list • http://www.cs.ubc.ca/~tmm/vadbook/errata.html • but don’t count it as a question • not useful to tell me about typos in published papers – three questions total required • not three questions per reading (6 total)! not just one! 2 VAD Ch 3: Task Abstraction Why? Actions Targets Analyze All Data Consume Trends Outliers Features Discover Present Enjoy Attributes Produce Annotate Record Derive One Many tag Distribution Dependency Correlation Similarity Extremes Search Target known Target unknown Location Lookup Browse Network Data known Location Locate Explore Topology unknown Query Paths Identify Compare Summarize What? Spatial Data Why? Shape How? [VAD Fig 3.1] 3 High-level actions: Analyze • consume Analyze –discover vs present Consume Discover Present Enjoy • classic split • aka explore vs explain –enjoy • newcomer Produce • aka casual, social Annotate Record Derive tag • produce –annotate, record –derive • crucial -

Tamara Munzner
The 2015 Visualization Technical Achievement Award Tamara Munzner The 2015 Visualization Technical Achievement Award goes to Tamara Munzner in recognition of foundational research that has produced a scientific basis for principles and design choices for visualization. The IEEE Visualization & Graphics Technical Community (VGTC) is pleased to award Tamara Munzner the 2015 Visualization Technical Achievement Award. Biography Tamara Munzner Tamara Munzner is a full professor at the University of University of British British Columbia Department of Computer Science, where Columbia she has been since 2002. She was a research scientist from Award Recipient 2015 2000 to 2002 at the Compaq Systems Research Center (the former DEC SRC). She earned her PhD from Stanford between 1995 and 2000, working with Pat Hanrahan. She and prescribe models and methods for visualization design holds a BS from Stanford from 1991, the year she first and the research process itself, including a nested model of attended VIS. design and validation and methodology for design studies. From 1991 to 1995, Tamara was a technical staff Her 2014 book Visualization Analysis and Design provides member at The Geometry Center, based at the University a systematic, comprehensive framework for thinking about of Minnesota. She was one of the architects and imple- visualization in terms of principles and design choices. It mentors of Geomview, the Center’s public domain interac- features a unified approach encompassing information visu- tive 3D visualization system that supported hyperbolic and alization techniques for the abstract data of tables and net- spherical geometry in addition to Euclidean geometry. She works, scientific visualization techniques for spatial data, was co-director and one of the animators of two videos and visual analytics techniques for interweaving data trans- that brought concepts from the cutting edge of geomet- formation and analysis with interactive visual exploration. -

Introduction to Information Visualization.Pdf
Introduction to Information Visualization Riccardo Mazza Introduction to Information Visualization 123 Riccardo Mazza University of Lugano Switzerland ISBN: 978-1-84800-218-0 e-ISBN: 978-1-84800-219-7 DOI: 10.1007/978-1-84800-219-7 British Library Cataloguing in Publication Data A catalogue record for this book is available from the British Library Library of Congress Control Number: 2008942431 c Springer-Verlag London Limited 2009 Apart from any fair dealing for the purposes of research or private study, or criticism or review, as permitted under the Copyright, Designs and Patents Act 1988, this publication may only be reproduced, stored or transmitted, in any form or by any means, with the prior permission in writing of the publish- ers, or in the case of reprographic reproduction in accordance with the terms of licences issued by the Copyright Licensing Agency. Enquiries concerning reproduction outside those terms should be sent to the publishers. The use of registered names, trademarks, etc., in this publication does not imply, even in the absence of a specific statement, that such names are exempt from the relevant laws and regulations and therefore free for general use. The publisher makes no representation, express or implied, with regard to the accuracy of the information contained in this book and cannot accept any legal responsibility or liability for any errors or omissions that may be made. Printed on acid-free paper Springer Science+Business Media springer.com To Vincenzo and Giulia Preface Imagine having to make a car journey. Perhaps you’re going to a holiday resort that you’re not familiar with. -

Tamara Munzner Department of Computer Science University of British Columbia
Ch 1/2/3: Intro, Data, Tasks Paper: Design Study Methodology Tamara Munzner Department of Computer Science University of British Columbia CPSC 547, Information Visualization Week 2: 17 September 2019 http://www.cs.ubc.ca/~tmm/courses/547-19 News • Signup sheet round 2: check column (or add yourself) • Canvas comments/question discussion –one question/comment per reading required • everybody got this right, great! –responses to others required • a few of you did not do this • original requirement of 2, considering cutback to just 1: discuss • decision: cut back to just 1 –if you spot typo in book, let me know if it’s not already in errata list • http://www.cs.ubc.ca/~tmm/vadbook/errata.html • (but don’t count it as a question) • not useful to tell me about typos in published papers 2 Ch 1. What’s Vis, and Why Do It? 3 Why have a human in the loop? Computer-based visualization systems provide visual representations of datasets designed to help people carry out tasks more effectively. Visualization is suitable when there is a need to augment human capabilities rather than replace people with computational decision-making methods. • don’t need vis when fully automatic solution exists and is trusted • many analysis problems ill-specified – don’t know exactly what questions to ask in advance • possibilities – long-term use for end users (e.g. exploratory analysis of scientific data) – presentation of known results – stepping stone to better understanding of requirements before developing models – help developers of automatic solution refine/debug, determine parameters – help end users of automatic solutions verify, build trust 4 Why use an external representation? Computer-based visualization systems provide visual representations of datasets designed to help people carry out tasks more effectively. -

3. Graphical Perception Tomorrow
Graphical Perception Nam Wook Kim Mini-Courses — January @ GSAS 2018 What is graphical perception? The visual decoding of information encoded on graphs Why important? “Graphical excellence is that which gives to the viewer the greatest number of ideas in the shortest time with the least ink in the smallest space” — Edward Tufte Goal Understand the role of perception in visualization design Topics • Signal Detection • Magnitude Estimation • Pre-Attentive Processing • Using Multiple Visual Encodings • Gestalt Grouping • Change Blindness Signal Detection Detecting Brightness A Which is brighter? B Detecting Brightness (128,128,128) (144,144,144) A B Detecting Brightness A Which is brighter? B Detecting Brightness (134,134,134) (138,138,138) A B Weber’s Law Just Noticeable Difference (JND) dS dp = k S Weber’s Law Just Noticeable Difference (JND) dS Change of Intensity dp = k S Physical Intensity Weber’s Law Just Noticeable Difference (JND) dS Change of Intensity Perceived Change dp = k S Physical Intensity Weber’s Law Just Noticeable Difference (JND) dS Change of Intensity Perceived Change dp = k S Physical Intensity Most continuous variation in stimuli are perceived in discrete steps Ranking correlation visualizations [Harrison et al 2014] Ranking correlation visualizations Which of the two appeared to be more highly correlated? A B [Harrison et al 2014] Ranking correlation visualizations Which of the two appeared to be more highly correlated? r = 0.7 r = 0.6 Ranking correlation visualizations Which of the two appeared to be more highly correlated? A B Ranking correlation visualizations Which of the two appeared to be more highly correlated? r = 0.7 r = 0.65 Ranking visualizations for depicting correlation Overall, scatterplots are the best for both positive and negative correlations. -

Session 2 Tamara Munzner Department of Computer Science University of British Columbia
Visualization Analysis & Design Full-Day Tutorial Session 2 Tamara Munzner Department of Computer Science University of British Columbia Sanger Institute / European Bioinformatics Institute June 2014, Cambridge UK http://www.cs.ubc.ca/~tmm/talks.html#minicourse14 Outline • Visualization Analysis Framework • Idiom Design Choices Session 1 9:30-10:45am Session 2 11:00am-12:15pm – Introduction: Definitions – Arrange Tables – Analysis: What, Why, How – Arrange Spatial Data – Marks and Channels – Arrange Networks and Trees – Map Color • Idiom Design Choices, Part 2 • Guidelines and Examples Session 3 1:15pm-2:45pm Session 4 3-4:30pm – Manipulate: Change, Select, Navigate – Rules of Thumb – Facet: Juxtapose, Partition, Superimpose – Validation – Reduce: Filter, Aggregate, Embed – BioVis Analysis Example http://www.cs.ubc.ca/~tmm/talks.html#minicourse14 2 How? EncodeEncode Manipulate Manipulate Facet Facet ReduReducece Arrange Map Change Juxtapose Filter Express Separate from categorical and ordered attributes Color Hue Saturation Order Align Luminance Select Partition Aggregate Size, Angle, Curvature, ... Use Navigate Superimpose Embed Shape Motion Direction, Rate, Frequency, ... 3 Arrange space Encode Arrange Express Separate Order Align Use 4 Arrange tables Express Values Axis Orientation Rectilinear Parallel Radial Separate, Order, Align Regions Separate Order Layout Density Dense Space-Filling Align 1 Key 2 Keys 3 Keys Many Keys List Matrix Volume Recursive Subdivision 5 Keys and values Tables • key Attributes (columns) Items – independent -

Data Visualization by Nils Gehlenborg
Data Visualization Nils Gehlenborg ([email protected]) Center for Biomedical Informatics / Harvard Medical School Cancer Program / Broad Institute of MIT and Harvard ISMB/ECCB 2011 http://www.biovis.net Flyers at ISCB booth! Data Visualization / ISMB/ECCB 2011 / Nils Gehlenborg A good sketch is better than a long speech. Napoleon Bonaparte Data Visualization / ISMB/ECCB 2011 / Nils Gehlenborg Minard 1869 Napoleon’s March on Moscow Data Visualization / ISMB/ECCB 2011 / Nils Gehlenborg 4 I believe when I see it. Unknown Data Visualization / ISMB/ECCB 2011 / Nils Gehlenborg Anscombe 1973, The American Statistician Anscombe’s Quartet mean(X) = 9, var(X) = 11, mean(Y) = 7.5, var(Y) = 4.12, cor(X,Y) = 0.816, linear regression line Y = 3 + 0.5*X Data Visualization / ISMB/ECCB 2011 / Nils Gehlenborg 6 Anscombe 1973, The American Statistician Anscombe’s Quartet Data Visualization / ISMB/ECCB 2011 / Nils Gehlenborg 7 Exploration: Hypothesis Generation trends gaps outliers clusters - A large data set is given and the goal is to learn something about it. - Visualization is employed to perform pattern detection using the human visual system. - The goal is to generate hypotheses that can be tested with statistical methods or follow-up experiments. Data Visualization / ISMB/ECCB 2011 / Nils Gehlenborg 8 Visualization Use Cases Presentation Confirmation Exploration Data Visualization / ISMB/ECCB 2011 / Nils Gehlenborg 9 Definition The use of computer-supported, interactive, visual representations of data to amplify cognition. Stu Card, Jock Mackinlay & Ben Shneiderman Computer-based visualization systems provide visual representations of datasets intended to help people carry out some task more effectively.effectively. -

An Interview with Visualization Pioneer Ben Shneiderman
6/23/2020 The purpose of visualization is insight, not pictures: An interview with visualization pioneer Ben Shneiderman The purpose of visualization is insight, not pictures: An interview with visualization pioneer Ben Shneiderman Jessica Hullman Follow Mar 12, 2019 · 13 min read Few people in visualization research have had careers as long and as impactful as Ben Shneiderman. We caught up with Ben over email in between his travels to get his take on visualization research, what’s worked in his career, and his advice for practitioners and researchers. Enjoy! Multiple Views: One of the main purposes of this blog is to explain to people what visualization research is to practitioners and, possibly, laypeople. How would you answer the question “what is visualization research”? Ben S: First let me define information visualization and its goals, then I can describe visualization research. Information visualization is a powerful interactive strategy for exploring data, especially when combined with statistical methods. Analysts in every field can use interactive information visualization tools for: more effective detection of faulty data, missing data, unusual distributions, and anomalies deeper and more thorough data analyses that produce profounder insights, and richer understandings that enable researchers to ask bolder questions. Like a telescope or microscope that increases your perceptual abilities, information visualization amplifies your cognitive abilities to understand complex processes so as to support better decisions. In our best -

Tamara Munzner Department of Computer Science University of British Columbia
Visualization Analysis & Design Tamara Munzner Department of Computer Science University of British Columbia D3 Unconference Keynote November 21 2015, San Francisco CA http://www.cs.ubc.ca/~tmm/talks.html#vad15d3 @tamaramunzner Defining visualization (vis) Computer-based visualization systems provide visual representations of datasets designed to help people carry out tasks more effectively. 2 Why have a human in the loop? Computer-based visualization systems provide visual representations of datasets designed to help people carry out tasks more effectively. Visualization is suitable when there is a need to augment human capabilities rather than replace people with computational decision-making methods. • don’t need vis when fully automatic solution exists and is trusted • many analysis problems ill-specified – don’t know exactly what questions to ask in advance • possibilities – long-term use for end users (e.g. exploratory analysis of scientific data) – presentation of known results – stepping stone to better understanding of requirements before developing models – help developers of automatic solution refine/debug, determine parameters – help end users of automatic solutions verify, build trust 3 Why use an external representation? Computer-based visualization systems provide visual representations of datasets designed to help people carry out tasks more effectively. • external representation: replace cognition with perception [Cerebral: Visualizing Multiple Experimental Conditions on a Graph with Biological Context. Barsky, Munzner, Gardy, -
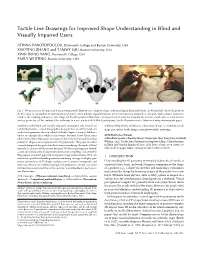
Tactile Line Drawings for Improved Shape Understanding in Blind and Visually Impaired Users
Tactile Line Drawings for Improved Shape Understanding in Blind and Visually Impaired Users ATHINA PANOTOPOULOU, Dartmouth College and Boston University, USA XIAOTING ZHANG and TAMMY QIU, Boston University, USA XING-DONG YANG, Dartmouth College, USA EMILY WHITING, Boston University, USA Fig. 1. We present a novel approach for generating tactile illustrations to improve shape understanding in blind individuals. (a) Physical 3D object (3D printed). (b) The input to our pipeline is a pre-partitioned object, colors indicate segmented parts. (c) A local camera is assigned to each part, with a master camera to combine the resulting multi-projection image. (d) Resulting stylized illustration. Cross-sections are used for texturing the interior of each part to communicate surface geometry. (e) We evaluated the technique in a user study with 20 blind participants. Tactile illustrations were fabricated using microcapsule paper. Members of the blind and visually impaired community rely heavily on Additional Key Words and Phrases: fabrication, design, accessibility, tactile tactile illustrations – raised line graphics on paper that are felt by hand – to shape perception, tactile images, non-photorealistic rendering understand geometric ideas in school textbooks, depict a story in children’s books, or conceptualize exhibits in museums. However, these illustrations ACM Reference Format: often fail to achieve their goals, in large part due to the lack of understanding Athina Panotopoulou, Xiaoting Zhang, Tammy Qiu, Xing-Dong Yang, and Emily in how 3D shapes can be represented in 2D projections. This paper describes Whiting. 2020. Tactile Line Drawings for Improved Shape Understanding a new technique to design tactile illustrations considering the needs of blind in Blind and Visually Impaired Users. -

Projections in Context
Projections in Context Kaye Mason and Sheelagh Carpendale and Brian Wyvill Department of Computer Science, University of Calgary Calgary, Alberta, Canada g g ffkatherim—sheelagh—blob @cpsc.ucalgary.ca Abstract sentation is the technical difficulty in the more mathematical as- pects of projection. This is exactly where computers can be of great This examination considers projections from three space into two assistance to the authors of representations. It is difficult enough to space, and in particular their application in the visual arts and in get all of the angles right in a planar geometric projection. Get- computer graphics, for the creation of image representations of the ting the curves right in a non-planar projection requires a great deal real world. A consideration of the history of projections both in the of skill. An algorithm, however, could provide a great deal of as- visual arts, and in computer graphics gives the background for a sistance. A few computer scientists have realised this, and begun discussion of possible extensions to allow for more author control, work on developing a broader conceptual framework for the imple- and a broader range of stylistic support. Consideration is given mentation of projections, and projection-aiding tools in computer to supporting user access to these extensions and to the potential graphics. utility. This examination considers this problem of projecting a three dimensional phenomenon onto a two dimensional media, be it a Keywords: Computer Graphics, Perspective, Projective Geome- canvas, a tapestry or a computer screen. It begins by examining try, NPR the nature of the problem (Section 2) and then look at solutions that have been developed both by artists (Section 3) and by com- puter scientists (Section 4). -

Visualization
Tamara Munzner 2 7 Visualization A major application area of computer graphics is visualization, where computer- generated images are used to help people understand both spatial and non-spatial data. Visualization is used when the goal is to augment human capabilities in situations where the problem is not sufficiently well defined for a computer to handle algorithmically. If a totally automatic solution can completely replace hu- man judgement, then visualization is not typically required. Visualization can be used to generate new hypotheses when exploring a completely unfamiliar dataset, to confirm existing hypotheses in a partially understood dataset, or to present in- formation about a known dataset to another audience. Visualization allows people to offload cognition to the perceptual system, us- ing carefully designed images as a form of external memory. The human visual system is a very high-bandwidth channel to the brain, with a significant amount of processing occurring in parallel and at the pre-conscious level. We can thus use external images as a substitute for keeping track of things inside our own heads. For an example, let us consider the task of understanding the relationships between a subset of the topics in the splendid book Godel,¨ Escher, Bach: The Eternal Golden Braid (Hofstadter, 1979); see Figure 27.1. When we see the dataset as a text list, at the low level we must read words and compare them to memories of previously read words. It is hard to keep track of just these dozen topics using cognition and memory alone, let alone the hun- dreds of topics in the full book.