Web Application for Voice Operated E-Mail Exchange
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Tips for Receiving Email Yahoo! Mail Hotmail, Windows Live Or
Tips for receiving Email An email has been sent to [email address] containing instructions on how to confirm your registration or how to reset your password. To make sure you receive this email, please: 1. Check your spam filter 2. Add [email protected] to your address book or ‘safe’ list. 3. Read the instructions below for your email provider. Yahoo! Mail There are two options to help ensure you receive our emails. • Bulk or Spam mail folder (does not guarantee delivery, but will help) 1. Check your Yahoo! Bulk mail or Spam folder 2. Click on the email from International Scholarship and Tuition Services and click the button marked ‘not Spam’. 3. The email will move to your inbox. • Create a mail filter (almost guarantees delivery) 1. Click on ‘Options’ in the top right. 2. Choose ‘Mail Options’ 3. Locate and choose ‘Filters’ 4. Click ‘Add’ 5. Name the filter ‘ISTS’ 6. Beside ‘From header’, select ‘contains’ and type International Scholarship and Tuition Services, Inc. 7. Beside ‘Move the message to’, select Inbox Hotmail, Windows Live or MSN There are two options to help ensure you receive our emails. • Junk Folder 1. In the left hand menu, select ‘Junk’ 2. Select the email from International Scholarship and Tuition Services, Inc. 3. Inside the email message, there will be an exclamation mark and a message saying ‘You may not know this sender.’ 4. Beside this, click the link ‘Mark as safe.’ 5. The email will move into your inbox. • Add ISTS to your ‘Safe List’ 1. In the top right corner, Click ‘Options’ 2. -

Getting Started with Exchange Unified Messaging
Getting Started with Exchange Unified Messaging Welcome to Exchange Unified Messaging. This system will replace MCC’s existing Audix voice mail system and provide additional functionality. Microsoft® Exchange Server is the engine that powers Outlook but it also provides new and convenient ways to access voice mail. Now your e‐mail and voice mail messages are placed into one mailbox that can be accessed through many different devices such as a telephone, mobile phone, or computer. 1 Table of Contents INTRODUCING UNIFIED MESSAGING VOICEMAIL ................................................................................................................... 3 TYPES OF VOICEMAIL BOXES ................................................................................................................................................... 4 Individual Voicemail Users ................................................................................................................................................. 4 Shared Departmental Voicemail Users ............................................................................................................................. 4 Departmental Voicemail Users .......................................................................................................................................... 4 HOW TO ACCESS YOUR VOICEMAIL ........................................................................................................................................ 5 First Time Set Up From A Phone ........................................................................................................................................... -

Getting Started with Windows Speech Recognition
Getting Started with Windows™ Speech Recognition (WSR) A. OVERVIEW After reading Part One, the first time user will dictate an E-mail or document quickly with high accuracy. The instructions allow you to create, dictate, and send an E-mail without touching the keyboard. The second part discusses steps to attain highest accuracy. The final part has suggestions for increasing productivity when using Windows™ Speech Recognition. II. PART ONE A. WHY USE SPEECH RECOGNITION? Most people will be able to dictate faster and more accurately than they type. My experience with Windows™ Speech Recognition is the ability to dictate over 80 words a minute with accuracy of about 99%. If you truly can type at 80 words a minute with accuracy approaching 99%, you do not need speech recognition. However, even a good keyboarder will benefit from reduced strain on the hands and arms by using Windows™ Speech Recognition. It takes time to become comfortable with dictation into a computer. There will be moments of frustration as you go through the learning curve. If you are impatient or are a perfectionist, DO NOT read on and do not use Windows™ Speech Recognition. If you have reasonable patience, you will learn to dictate accurately and comfortably. The best strategy is to keep things simple for first several days of using Windows™ Speech Recognition. When you are comfortable with the basics, move to part two of this document. B. THE MICROPHONE A good microphone makes dictation into a computer a pleasure instead of a battle. Good microphones reproduce your voice accurately and block out background noise that distorts the audio signal. -

How to Join a Skype Meeting Via E-Mail Invitation
HOW TO JOIN A SKYPE MEETING VIA E-MAIL INVITATION Important note before you start! It is best practice to install the Skype app before joining your first meeting. To do so please refer to the TC Toolbox note Install the Skype software for a Computer or Install the Skype app for an Apple or Android Mobile device. 1 Visit your inbox and open the 2 email invitation sent from the meeting host. While viewing the message, look for and click/tap on the hyperlink provided under Join Skype Meeting. [email protected] 3 On a computer, you may be promoted to open the Skype app, click Open Skype or Allow. Note On a mobile device, you may be prompted to select a browser to proceed. Tap on any button that says Open, then Join Conversation, then tap Open again. You’re all set. Time to learn how to use the Skype App! PAGE 1 of 2 Tools to help boost your digital literacy WWW.TECHCOACHES.CA Copyright © 2020 Tech Coaches Inc. 4 On a computer, if prompted, sign in with your existing Microsoft Account, or click Join as guest if you do not have a Microsoft account. 5 Set your microphone and video settings, by clicking the switches on/off. On a mobile device, if prompted tap Let’s go. Then, sign in with your existing Microsoft Account, or tap Join as guest if you do not have a Microsoft account. 6 Note Note: If a Join Meeting button is not Click/tap the green Join Meeting present but a Start Meeting button is button. -

How to Set up HP Lefthand Email Alerts Using Third Party Email
How to Set Up Email Relaying to Offsite Email Provider The approach found most effective for customers is to relay SMTP messages from the HP LeftHand nodes off of the management server which has a NIC on the SAN VLAN. Microsoft’s ISS is used to handle the SMTP relay. An email account is set up on a third party email server (Gmail, etc.) to prevent loss of alert communication if the internal server is part of the outage. This management server can be running the Centralized Management Console as well as the HealthCheck and Failover Manager utilities. Critical messages are sent to an externally controlled email account (Gmail, etc.) that can be monitored at all times by the system administrator. This is done via an email distribution list. Non-critical messages are sent to internal mailboxes. A diagram is included below. SMTP Server Setup (IIS 6.0) The Simple Mail Transfer Protocol (SMTP) service provided by IIS is a simple component for delivering outgoing e-mail messages. Delivery of a message is initiated by transferring the message to a designated SMTP server. Based on the domain name of the recipient e-mail address, the SMTP server initiates communications with a Domain Name System (DNS) server, which looks up and then returns the host name of the destination SMTP server for that domain. Next, the originating SMTP server communicates with the destination SMTP server directly through Transmission Control Protocol/Internet Protocol (TCP/IP) on port 25. If the user name of the recipient e-mail address matches one of the authorized user accounts on the destination server, the original e-mail message is transferred to that server, waiting for the recipient to pick up the message through a client program. -

E-Mailing a Large Amount of Recipients
E-mailing a large amount of recipients DO NOT use the “TO” or “CC” field! If you have a large list of recipients you need to send an email you, you should never try sending one large email with all of the recipients listed in the “TO” and/or “CC” field. First of all, the message will likely not be delivered to everyone. Even if the message makes it past our local header size limit, every mail server you are attempting to send it to has it’s own header size limit and can reject your message for exceeding this limit. There are other reasons you would not want to send it that way as well. For instance, by including everyone you are sending the message to, you are displaying that publicly to everyone on the list. Anyone who received the message can easy perform a reply-all and send an unwanted message to everyone. This usually begins when someone replies-all and says “Remove me from your list”. It won’t be long before you get someone emailing the entire list saying “You didn’t have to email that request to all of us”, etc... Basically, it could create a large amont of unwanted email for everyone involved. So what are your options? DO use the “BCC” field! The first option is to include your list of recipients in the BCC field. This prevents the header size from getting too large and also prevents people from purposely or accidentally replying-to-all. The problem with this method is the recipient does not see their email address in the TO header. -

CYBONET's Product Pineapp Mail Secure Is Fully Available For
CYBONET’s product PineApp Mail Secure is fully available for installation on Hyper-V platform. The following manual provides assistance in installing PineApp Mail Secure Virtual Machine on the Microsoft Hyper-V platform. Hyper V Quick Installation Guide Step 1: Installing PineApp Mail Secure over virtual machine. 1. Please choose New Virtual Hard Wizard and click on Next > button. 2. Under Choose Disk Format menu, please select VHDX option as mentioned below and click Next. 3. Under Choose Disk Type, please select Fixed Size and continue wizard. 4. Under Specify Name and Location, assign name for virtual disk and specify location. 5. Under Configure Disk, please specify disk size. For standalone unit is 300GB, for scanner unit in cluster enough – 120GB and click on Next > button. 6. Under Summary window, please verify your virtual machine description and click on Finish. 7. Continue with wizard, by clicking Next button. 8. Under Specify Name and Location menu, assign name for PineApp Mail Secure installation (for example – PineApp) and click on Next button. 9. Under Generation menu, please specify Generation 1 as mentioned on a screenshot below and click Next >. 10. Under Memory menu, assign RAM size. Minimum recommended value is – 4GB RAM (4096MB) 11. Under Networking menu, please choose network connection. 12. Under Virtual Hard Disk menu, please connect previously created virtual disk from instruction number 4 and click on Next. 13. Under Summary menu, please verify that virtual machine settings are to your expectations and click on Finish button. 14. Enter Settings of newly created machine, choose SCSI Controller and select DVD Drive and click on Add button. -

How to Use Rules in Outlook and Outlook Express to Forward Email
How to use rules in Outlook and Outlook Express to forward email. In Outlook Express (6) 1. Click on the Tools menu and select Options. 2. In options select the Send tab. 3. Make sure the settings for Mail Sending Format has the Plain Text radio button selected. 4. Then click the Plain Text Settings button. 5. Leave the Message format on “MIME”. 6. Uncheck the box at the bottom that says “Indent the original text with…”. 7. Click OK. 8. Now click on the Signatures tab. 9. Make sure if you have a signature(s) listed that the box labeled “Don’t add signatures to Replies and Forwards” is checked. Then click OK. 10. Click on the Tools menu and select Message Rules, and then select Mail. 11. Click on the Mail Rules tab. 12. Click the New Button. 13. In the area labeled 1. Select the Conditions for your rule: Select the box next to Where the Subject line contains specific words (in this example we will use the subject but you could use account or email address if desired). 14. Then in the area labeled 2. Select the Actions for your rule: Select the box next to Forward it to people. 15. In the area labeled 3. Rule Description… click on the blue link that says “contains specific words” then type your member code in the box and click on the Add Button and then click OK. 16. Then in the same area click on the blue link that says “people”, then type in the email address of where you want the email to automatically forward to and then click OK. -

Getting Started with Outlook Express for Windows 2000/XP Author Marcie Matsuo Revised by Darren Kato
WIN9X015 November 2005 Getting Started With Outlook Express For Windows 2000/XP Author Marcie Matsuo Revised by Darren Kato Introduction.................................................................................................................................1 What is Outlook Express ............................................................................................................1 Requirements ..............................................................................................................................2 Where do I get Outlook Express.................................................................................................2 Issues...........................................................................................................................................2 POP and IMAP ...........................................................................................................................2 Installing Outlook Express..........................................................................................................3 Configuring Outlook Express .....................................................................................................3 Using Outlook Express ...............................................................................................................9 Importing Messages From Other Mail Programs .....................................................................12 Using the Address Book ...........................................................................................................14 -
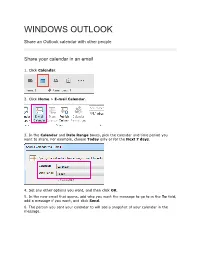
Windows Outlook Calendar Sharing How To
WINDOWS OUTLOOK Share an Outlook calendar with other people Share your calendar in an email 1. Click Calendar. 2. Click Home > E-mail Calendar. 3. In the Calendar and Date Range boxes, pick the calendar and time period you want to share. For example, choose Today only or for the Next 7 days. 4. Set any other options you want, and then click OK. 5. In the new email that opens, add who you want the message to go to in the To field, add a message if you want, and click Send. 6. The person you sent your calendar to will see a snapshot of your calendar in the message. The message also includes an attached iCalendar (.ics) file that they can open in Outlook or another calendar program. When the recipient clicks the iCalendar file, Outlook displays the file as a new calendar that they can view side-by-side with their calendar. They can drag appointments or meetings between the two calendars, and find a time that works for both of you. Change permissions after you have shared your calendar with other people You can change calendar sharing permissions. 1. Click Calendar. 2. Click Home > Calendar Permissions. 3. On the Permissions tab, make any changes to the calendar sharing permissions. 4. Click OK. Permission Settings: Owner Create, read, modify, and delete all items, and create subfolders. Can change the permission levels that other people have for the folder. Publishing Editor Create, read, modify, and delete all items and create subfolders. Editor Create, read, modify, and delete all items. -

Accessing Voice Messages Via Email
Accessing voice messages via email Download a digital media player Play a message using Windows Media Player (if you do not already have one): (when WMP is your default media player): 1. Windows Media Player: 1. Open the email message. http://www.microsoft.com/windows/windowsmedia/player/ (NOTE: There is no previewer available for Windows Media 2. Apple’s iTunes: Player. Therefore, you cannot play the voice message by http://www.apple.com/itunes/overview/ clicking on the media player from the Preview pane.) 3. RealNetworks RealPlayer: 2. Double‐click on the .wav file attachment. The Windows http://www.real.com/realplayer Media Player application will launch automatically. What will happen if I open a voicemail message before I have downloaded a media player? 1. When you try to open the voice mail in Outlook, the following message will appear on your screen before the message is opened…. 2. When you click on the OK button, the message will open in a separate window….. 3. Follow the standard Windows Media Player procedures to play, rewind, save, or delete the voice mail message(s). To play a voice mail message from iTunes (when iTunes is your default media player): 1. Right‐click on the voice mail message in your email 3. If you double‐click on the attached .wav file, the following message Inbox. will appear…. 2. From the drop‐down menu, move your cursor to the View Attachments option and then click on VoiceMessage.wav from the sub‐list. 4. Make sure that the Express Settings donut is selected, then click on 3. -

How to Use the Mail App in Windows 10
How to use the Mail App in Windows 10 Click on the Mail icon on the right-hand column of the Start menu. Or, if the icon is no longer there, type "mail" in the search bar. How to use the Mail App in Windows 10 Page 1 How to use the Mail App in Windows 10 Follow the prompts in the proceeding windows. Click Add account to find the email account you want to add. How to use the Mail App in Windows 10 Page 2 How to use the Mail App in Windows 10 For Paul Smith's emails, select Exchange, and enter in your information in the proceeding screens. You can add more than one email account. How to use the Mail App in Windows 10 Page 3 How to use the Mail App in Windows 10 When you are done setting up the account(s), the Mail app will open up. 1. Select the three lines in the top left corner to access the menu. 2. Selec the plus sign to create a new email. 3. Select the circle atop a semi-circle to switch between email accounts. 4. Select the folder icon to access folders within each account. 5. Select the gear icon at the bottom of the screen for Settings. How to use the Mail App in Windows 10 Page 4 How to use the Mail App in Windows 10 In Settings, you can manage each or both of your accounts, personalize how the Mail app appears, choose what certain actions do, choose how you receive notifications, customize your signatures, and more.