DISTRIBUTED SYSTEMS CONTENTS 1.0 Aim And
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Postfix-Cyrus-Web-Cyradm-HOWTO
Postfix-Cyrus-Web-cyradm-HOWTO Luc de Louw luc at delouw.ch Revision History Revision 1.2.6 2004-03-30 Revised by: ldl Added minor additions and corrected to amavisd-new, corrected cronjob-time for freshclam Revision 1.2.5 2004-03-28 Revised by: ldl Added Anti-Virus and SPAM methods (amavisd-new, spamassassin, clamav), updated cyrus-imapd section with update instructions, added instruction to restrict imapd admin access. Revision 1.2.4 2003-11-30 Revised by: ldl Input from English proofreading, minor correction and enhancements from user-input, updated software mentioned in the HOWTO Revision 1.2.3 2003-03-24 Revised by: ldl Some minor correction and enhancements from user-input, updated software mentioned in the HOWTO Revision 1.2.2 2003-02-14 Revised by: ldl Lots of grammar and typos fixed. Some corrections to the pam_mysql Makefile Revision 1.2.1 2003-02-12 Revised by: ldl Non-official test-release: Added lots of fixes and updates. Added OpenSSL and more pam related stuff. Revision 1.2.0 2002-10-16 Revised by: ldl Added lot of user requests, updated the software mentioned in the HOWTO Revision 1.1.7 2002-10-15 Revised by: ldl Added Michael Muenz’ hints for SMTP AUTH, corrected ca-cert related mistake, improved SGML code (more metadata), updated the software mentioned in the document. Revision 1.1.6 2002-06-14 Revised by: ldl Added sasl_mech_list: PLAIN to imapd.conf, added web-cyradm mailinglist, added more to web-cyradm Revision 1.1.5 2002-06-11 Revised by: ldl Added new SQL query to initialize web-cyradm to have full data integrity in the MySQL Database, mysql-mydestination.cf reported to be operational as expected. -

Toward an Automated Vulnerability Comparison of Open Source IMAP Servers Chaos Golubitsky – Carnegie Mellon University
Toward an Automated Vulnerability Comparison of Open Source IMAP Servers Chaos Golubitsky – Carnegie Mellon University ABSTRACT The attack surface concept provides a means of discussing the susceptibility of software to as-yet-unknown attacks. A system’s attack surface encompasses the methods the system makes available to an attacker, and the system resources which can be used to further an attack. A measurement of the size of the attack surface could be used to compare the security of multiple systems which perform the same function. The Internet Message Access Protocol (IMAP) has been in existence for over a decade. Relative to HTTP or SMTP, IMAP is a niche protocol, but IMAP servers are widely deployed nonetheless. There are three popular open source UNIX IMAP servers – UW-IMAP, Cyrus, and Courier-IMAP – and there has not been a formal security comparison between them. In this paper, I use attack surfaces to compare the relative security risks posed by these three products. I undertake this evaluation in service of two complementary goals: to provide an honest examination of the security postures and risks of the three servers, and to advance the study of attack surfaces by performing an automated attack surface measurement using a methodology based on counting entry and exit points in the code. Introduction Contributions and Roadmap System administrators frequently confront the The paper makes two major contributions. First, problem of selecting a software package to perform a I undertake an in-depth discussion of the relative secu- desired function. Many considerations affect this deci- rity postures of the three major open source IMAP sion, including functionality, ease of installation, soft- servers in use today. -

VI. Lotus Domino
Le groupware - 1 / 60 - Sommaire I. Introduction ................................................................................................ 2 A. Histoire (Source : Michel Alberganti) ................................................................................ 2 B. Définition................................................................................................................... 2 C. L'offre....................................................................................................................... 2 1. Intranet / Internet................................................................................................. 2 2. Messagerie........................................................................................................... 3 II. Les clients de messagerie ............................................................................... 3 A. Windows Messaging : Msmail........................................................................................... 4 1. Installer et administrer un bureau de poste .................................................................. 4 2. Propriétés du client MAPI......................................................................................... 7 B. Utiliser Outlook ......................................................................................................... 15 1. Les options .........................................................................................................15 2. Envoi de messages ................................................................................................20 -

Postfix−Cyrus−Web−Cyradm−HOWTO
Postfix−Cyrus−Web−cyradm−HOWTO Luc de Louw luc at delouw.ch Revision History Revision 1.2.0 2002−10−16 Revised by: ldl The first release of the 1.2 version. Revision 1.1.7 2002−10−15 Revised by: ldl Added Michael Muenz' hints for SMTP AUTH, corrected ca−cert related mistake, improved SGML code (more metadata), updated the software mentioned in the document. Revision 1.1.6 2002−06−14 Revised by: ldl Added sasl_mech_list: PLAIN to imapd.conf, added web−cyradm Mailinglist, added more to web−cyradm Revision 1.1.5 2002−06−11 Revised by: ldl Added new SQL query to initialize web−cyradm to have full data integrity in the MySQL Database, mysql−mydestination.cf reported to be operational as expected. Revision 1.1.4 2002−05−15 Revised by: ldl Added description what is needed in /etc/services Another fix for pam_mysql compile, updated software versions. Revision 1.1.3 2002−05−08 Revised by: ldl Added more description for web−cyradm, fix for wrong path of the saslauthdb−socket, Fix for wrong place of com_err.h, protection of the TLS/SSL private key. Revision 1.1.2 2002−04−29 Revised by: ldl Added description for Redhat users how to install the init scripts. Revision 1.1.1 2002−04−29 Revised by: ldl Fixed bug in configuring cyrus−IMAP (disabled unused kerberos authentication) Revision 1.1.0 2002−04−28 Revised by: ldl Initial support for building cyrus from source, dropped binary installation for Cyrus, because configuration has changed with Release 2.1.x Revision 1.0.2 2002−04−25 Revised by: ldl Added basic description for sieve and correct sender handling, minor fixes to db related stuff, Added mysql−lookup for »mydestination« , fixed bug for building postfix with mysql support. -

Brave Gnu World
LINUXCOVERCOMMUNITY USERSTORY SchlagwortSchlagwortBrave GNU sollte Worldsollte hier hier stehen stehen Schlagwort sollte hier stehen COVER STORY The Monthly GNU Column BRAVE GNU WORLD This column looks into projects and current affairs in the world of free software from the perspective of the GNU Project and the FSF. In this issue, I’ll focus on Comspari and the EU decision on software patents. BY GEORG C.F. GREVE n the past, the German government the Kroupware project in 2002. The pub- principles back to front. For example, has often caused a (positive) stir due lic tender by the BSI was aimed to pro- many other solutions are based on the Ito its activities with free software. duce a groupware solution that would principle that the server is the king of The Federal Ministry of the Economy support strong cryptography and inte- the hill and the users have to bow down (BMWi) sponsored Gnupg [1], for exam- grate seamlessly into a heterogeneous and worship it. The Kolab server does ple. Add to this a number of accompany- environment. things differently. The program makes ing activities, such as a report by the The government office gave a consor- the user king, and gives the user power Bavarian Accounts Office, the KBST let- tium comprising Erfrakon, Klarälvdalens to do things. The software simply helps ter, and the highly acclaimed migration Datakonsult [2], and Intevation [3] the coordinate things as a central intermedi- guide by the Federal Ministry of the Inte- task of developing the software. Inter- ary. rior (BMI). nally, the design and the software was Kolab 1 combined so-called partial referred to as Kolab 1. -

Biblioteca Antispam De Propósito Geral
Universidade Federal do Rio de Janeiro Escola Politécnica Departamento de Eletrônica e de Computação LibAntispam – Biblioteca Antispam de Propósito Geral Autor: _________________________________________________ Rafael Jorge Csura Szendrodi Orientador: _________________________________________________ Prof. Jorge Lopes de Souza Leão, Dr. Ing. Examinador: _________________________________________________ Prof. Antônio Cláudio Gómez de Sousa, M. Sc. Examinador: _________________________________________________ Prof. Aloysio de Castro Pinto Pedroza, Dr. DEL Maio de 2009 DEDICATÓRIA Dedico este trabalho: À Zeus (Jupiter), deus do Céu e da Terra, pai e rei dos deuses e dos homens, senhor do Olímpio e deus supremo deste universo. À Hera (Juno), rainha dos deuses, protetora da vida, das mulheres, da fecundidade e do matrimônio. À Athena (Miverva), deusa da sabedoria, do oficio, da inteligência e da guerra justa. Protetora do povo de Atenas. À Ártemis (Diana), deusa da caça, da natureza, da colheita, da serena luz da lua, dos nascimentos e protetora das Amazonas. À Afrodite (Venus), deusa da beleza e do amor, mãe de Enéias, fundador da raça romana, e matriarca da dinastia Julia (a dinastia de Julio Cesar). À minha mãe, Ildi e ao meu pai Gyorgy, pelo meu nascimento e por, de certa forma, terem contribuído para que eu me moldasse no que sou hoje. ii AGRADECIMENTO Ao povo brasileiro que contribuiu de forma significativa à minha formação e estada nesta Universidade. Este projeto é uma pequena forma de retribuir o investimento e confiança em mim depositados. Ao professor Leão, meu orientador neste projeto, por ter aceitado me guiar nesta minha jornada final do meu curso. Aos professores Baruqui (meu orientador acadêmico), Joarez, Gabriel, Petraglia e Mariane, meus amigos há vários anos que sempre me incentivaram a não desistir do curso de eletrônica. -

Server Administration
Server administration Remo Suppi Boldrito PID_00148466 GNUFDL • PID_00148466 Server administration Copyright © 2009, FUOC. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or any later version published by the Free Software Foundation; with no Invariant Sections, no Front-Cover Texts, and no Back-Cover Texts. A copy of the license is included in the section entitled "GNU Free Documentation License" GNUFDL • PID_00148466 Server administration Index Introduction............................................................................................... 5 1. Domain name system (DNS)............................................................ 7 1.1. Cache names server .................................................................... 7 1.2. Forwarders ................................................................................... 10 1.3. Configuration of an own domain .............................................. 11 2. NIS (YP)................................................................................................. 14 2.1. ¿How do we initiate a local NIS client in Debian? ..................... 14 2.2. What resources must be specified in order to use NIS? .............. 15 2.3. How should we execute a master NIS server? ............................ 16 2.4. How should we configure a server? ............................................ 17 3. Remote connection services: telnet and ssh............................... 19 3.1. Telnet and telnetd -

Eudora® Email 7.1 User Guide for Windows
Eudora® Email 7.1 User Guide for Windows This manual was written for use with the Eudora® for Windows software version 7.1. This manual and the Eudora software described in it are copyrighted, with all rights reserved. This manual and the Eudora software may not be copied, except as otherwise provided in your software license or as expressly permitted in writing by QUALCOMM Incorporated. Export of this technology may be controlled by the United States Government. Diversion contrary to U.S. law prohibited. Copyright © 2006 by QUALCOMM Incorporated. All rights reserved. QUALCOMM, Eudora, Eudora Pro, Eudora Light, and QChat are registered trademarks of QUALCOMM Incorporated. PureVoice, SmartRate, MoodWatch, WorldMail, Eudora Internet Mail Server, and the Eudora logo are trademarks of QUALCOMM Incorporated. Microsoft, Outlook, Outlook Express, and Windows are either registered trademarks or trademarks of Microsoft Incorporated in the United States and/or other countries. Adobe, Acrobat, and Acrobat Exchange are registered trademarks of Adobe Systems Incorporated. Apple and the Apple logo are registered trademarks, and QuickTime is a trademark of Apple Computer, Inc. Netscape, Netscape Messenger, and Netscape Messenger are registered trademarks of the Netscape Communications Corporation in the United States and other countries. Netscape's logos and Netscape product and service names are also trademarks of Netscape Communications Corporation, which may be registered in other countries. All other trademarks and service marks are the property of their respective owners. Use of the Eudora software and other software and fonts accompanying your license (the "Software") and its documentation are governed by the terms set forth in your license. -

Index Images Download 2006 News Crack Serial Warez Full 12 Contact
index images download 2006 news crack serial warez full 12 contact about search spacer privacy 11 logo blog new 10 cgi-bin faq rss home img default 2005 products sitemap archives 1 09 links 01 08 06 2 07 login articles support 05 keygen article 04 03 help events archive 02 register en forum software downloads 3 security 13 category 4 content 14 main 15 press media templates services icons resources info profile 16 2004 18 docs contactus files features html 20 21 5 22 page 6 misc 19 partners 24 terms 2007 23 17 i 27 top 26 9 legal 30 banners xml 29 28 7 tools projects 25 0 user feed themes linux forums jobs business 8 video email books banner reviews view graphics research feedback pdf print ads modules 2003 company blank pub games copyright common site comments people aboutus product sports logos buttons english story image uploads 31 subscribe blogs atom gallery newsletter stats careers music pages publications technology calendar stories photos papers community data history arrow submit www s web library wiki header education go internet b in advertise spam a nav mail users Images members topics disclaimer store clear feeds c awards 2002 Default general pics dir signup solutions map News public doc de weblog index2 shop contacts fr homepage travel button pixel list viewtopic documents overview tips adclick contact_us movies wp-content catalog us p staff hardware wireless global screenshots apps online version directory mobile other advertising tech welcome admin t policy faqs link 2001 training releases space member static join health -

Analysis and Performance Optimization of E-Mail Server
Analysis and Performance Optimization of E-mail Server Disserta¸c~aoapresentada ao Instituto Polit´ecnicode Bragan¸capara cumprimento dos requisitos necess´arios `aobten¸c~aodo grau de Mestre em Sistemas de Informa¸c~ao,sob a supervis~aode Prof. Dr. Rui Pedro Lopes. Eduardo Manuel Mendes Costa Outubro 2010 Preface The e-mail service is increasingly important for organizations and their employees. As such, it requires constant monitoring to solve any performance issues and to maintain an adequate level of service. To cope with the increase of traffic as well as the dimension of organizations, several architectures have been evolving, such as cluster or cloud computing, promising new paradigms of service delivery, which can possibility solve many current problems such as scalability, increased storage and processing capacity, greater rationalization of resources, cost reduction, and increase in performance. However, it is necessary to check whether they are suitable to receive e-mail servers, and as such the purpose of this dissertation will concentrate on evaluating the performance of e-mail servers, in different hosting architectures. Beyond computing platforms, was also analze different server applications. They will be tested to determine which combinations of computer platforms and applications obtained better performances for the SMTP, POP3 and IMAP services. The tests are performed by measuring the number of sessions per ammount of time, in several test scenarios. This dissertation should be of interest for all system administrators of public and private organizations that are considering implementing enterprise wide e-mail services. i Acknowledgments This work would not be complete without thanking all who helped me directly or indirectly to complete it. -

Installation and Configuration Guide
Installation and Configuration Guide SOGo v5.1.1 Table of Contents 1. About this Guide . 2 2. Introduction . 3 2.1. Architecture and Compatibility . 3 3. System Requirements . 6 3.1. Assumptions . 6 3.2. Minimum Hardware Requirements. 6 3.3. Operating System Requirements . 7 4. Installation . 9 4.1. Software Downloads . 9 4.2. Software Installation . 10 5. Configuration. 11 5.1. GNUstep Environment Overview . 11 5.2. Preferences Hierarchy . 11 5.3. General Preferences . 12 5.4. Authentication using LDAP. 24 5.5. LDAP Attributes Indexing . 31 5.6. LDAP Attributes Mapping . 32 5.7. Authenticating using C.A.S.. 33 5.8. Authenticating using SAML2 . 35 5.9. Database Configuration . 35 5.10. Authentication using SQL . 40 5.11. SMTP Server Configuration . 43 5.12. IMAP Server Configuration. 44 5.13. Web Interface Configuration . 47 5.14. SOGo Configuration Summary. 57 5.15. Multi-domains Configuration . 58 5.16. Apache Configuration . 60 5.17. Starting Services . 61 5.18. Cronjob — EMail reminders. 61 5.19. Cronjob — Vacation messages activation and expiration . 62 6. Managing User Accounts . 63 6.1. Creating the SOGo Administrative Account . 63 6.2. Creating a User Account . 63 7. Microsoft Enterprise ActiveSync . 65 8. Microsoft Enterprise ActiveSync Tuning . 68 9. S/MIME Support in SOGo . 70 10. Using SOGo. 71 10.1. SOGo Web Interface. 71 10.2. Mozilla Thunderbird and Lightning . 71 10.3. Apple Calendar (macOS, iOS, iPadOS). 72 10.4. Apple AddressBook . 72 10.5. Microsoft ActiveSync . 73 11. Upgrading . 74 12. Additional Information . 76 13. Commercial Support and Contact Information . -
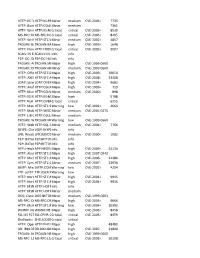
HTTP: IIS "Propfind" Rem HTTP:IIS:PROPFIND Minor Medium
HTTP: IIS "propfind"HTTP:IIS:PROPFIND RemoteMinor DoS medium CVE-2003-0226 7735 HTTP: IkonboardHTTP:CGI:IKONBOARD-BADCOOKIE IllegalMinor Cookie Languagemedium 7361 HTTP: WindowsHTTP:IIS:NSIISLOG-OF Media CriticalServices NSIISlog.DLLcritical BufferCVE-2003-0349 Overflow 8035 MS-RPC: DCOMMS-RPC:DCOM:EXPLOIT ExploitCritical critical CVE-2003-0352 8205 HTTP: WinHelp32.exeHTTP:STC:WINHELP32-OF2 RemoteMinor Buffermedium Overrun CVE-2002-0823(2) 4857 TROJAN: BackTROJAN:BACKORIFICE:BO2K-CONNECT Orifice 2000Major Client Connectionhigh CVE-1999-0660 1648 HTTP: FrontpageHTTP:FRONTPAGE:FP30REG.DLL-OF fp30reg.dllCritical Overflowcritical CVE-2003-0822 9007 SCAN: IIS EnumerationSCAN:II:IIS-ISAPI-ENUMInfo info P2P: DC: DirectP2P:DC:HUB-LOGIN ConnectInfo Plus Plus Clientinfo Hub Login TROJAN: AOLTROJAN:MISC:AOLADMIN-SRV-RESP Admin ServerMajor Responsehigh CVE-1999-0660 TROJAN: DigitalTROJAN:MISC:ROOTBEER-CLIENT RootbeerMinor Client Connectmedium CVE-1999-0660 HTTP: OfficeHTTP:STC:DL:OFFICEART-PROP Art PropertyMajor Table Bufferhigh OverflowCVE-2009-2528 36650 HTTP: AXIS CommunicationsHTTP:STC:ACTIVEX:AXIS-CAMERAMajor Camerahigh Control (AxisCamControl.ocx)CVE-2008-5260 33408 Unsafe ActiveX Control LDAP: IpswitchLDAP:OVERFLOW:IMAIL-ASN1 IMail LDAPMajor Daemonhigh Remote BufferCVE-2004-0297 Overflow 9682 HTTP: AnyformHTTP:CGI:ANYFORM-SEMICOLON SemicolonMajor high CVE-1999-0066 719 HTTP: Mini HTTP:CGI:W3-MSQL-FILE-DISCLSRSQL w3-msqlMinor File View mediumDisclosure CVE-2000-0012 898 HTTP: IIS MFCHTTP:IIS:MFC-EXT-OF ISAPI FrameworkMajor Overflowhigh (via