Amazon Sagemaker Automatic Model Tuning: Scalable Gradient-Free Optimization
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Building Alexa Skills Using Amazon Sagemaker and AWS Lambda
Bootcamp: Building Alexa Skills Using Amazon SageMaker and AWS Lambda Description In this full-day, intermediate-level bootcamp, you will learn the essentials of building an Alexa skill, the AWS Lambda function that supports it, and how to enrich it with Amazon SageMaker. This course, which is intended for students with a basic understanding of Alexa, machine learning, and Python, teaches you to develop new tools to improve interactions with your customers. Intended Audience This course is intended for those who: • Are interested in developing Alexa skills • Want to enhance their Alexa skills using machine learning • Work in a customer-focused industry and want to improve their customer interactions Course Objectives In this course, you will learn: • The basics of the Alexa developer console • How utterances and intents work, and how skills interact with AWS Lambda • How to use Amazon SageMaker for the machine learning workflow and for enhancing Alexa skills Prerequisites We recommend that attendees of this course have the following prerequisites: • Basic familiarity with Alexa and Alexa skills • Basic familiarity with machine learning • Basic familiarity with Python • An account on the Amazon Developer Portal Delivery Method This course is delivered through a mix of: • Classroom training • Hands-on Labs Hands-on Activity • This course allows you to test new skills and apply knowledge to your working environment through a variety of practical exercises • This course requires a laptop to complete lab exercises; tablets are not appropriate Duration One Day Course Outline This course covers the following concepts: • Getting started with Alexa • Lab: Building an Alexa skill: Hello Alexa © 2018, Amazon Web Services, Inc. -
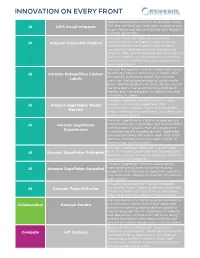
Innovation on Every Front
INNOVATION ON EVERY FRONT AWS DeepComposer uses AI to compose music. AI AWS DeepComposer The new service gives developers a creative way to get started and become familiar with machine learning capabilities. Amazon Transcribe Medical is a machine AI Amazon Transcribe Medical learning service that makes it easy to quickly create accurate transcriptions from medical consultations between patients and physician dictated notes, practitioner/patient consultations, and tele-medicine are automatically converted from speech to text for use in clinical documen- tation applications. Amazon Rekognition Custom Labels helps users AI Amazon Rekognition Custom identify the objects and scenes in images that are specific to business needs. For example, Labels users can find corporate logos in social media posts, identify products on store shelves, classify machine parts in an assembly line, distinguish healthy and infected plants, or detect animated characters in videos. Amazon SageMaker Model Monitor is a new AI Amazon SageMaker Model capability of Amazon SageMaker that automatically monitors machine learning (ML) Monitor models in production, and alerts users when data quality issues appear. Amazon SageMaker is a fully managed service AI Amazon SageMaker that provides every developer and data scientist with the ability to build, train, and deploy ma- Experiments chine learning (ML) models quickly. SageMaker removes the heavy lifting from each step of the machine learning process to make it easier to develop high quality models. Amazon SageMaker Debugger is a new capa- AI Amazon SageMaker Debugger bility of Amazon SageMaker that automatically identifies complex issues developing in machine learning (ML) training jobs. Amazon SageMaker Autopilot automatically AI Amazon SageMaker Autopilot trains and tunes the best machine learning models for classification or regression, based on your data while allowing to maintain full control and visibility. -
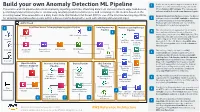
Build Your Own Anomaly Detection ML Pipeline
Device telemetry data is ingested from the field Build your own Anomaly Detection ML Pipeline 1 devices on a near real-time basis by calls to the This end-to-end ML pipeline detects anomalies by ingesting real-time, streaming data from various network edge field devices, API via Amazon API Gateway. The requests get performing transformation jobs to continuously run daily predictions/inferences, and retraining the ML models based on the authenticated/authorized using Amazon Cognito. incoming newer time series data on a daily basis. Note that Random Cut Forest (RCF) is one of the machine learning algorithms Amazon Kinesis Data Firehose ingests the data in for detecting anomalous data points within a data set and is designed to work with arbitrary-dimensional input. 2 real time, and invokes AWS Lambda to transform the data into parquet format. Kinesis Data AWS Cloud Firehose will automatically scale to match the throughput of the data being ingested. 1 Real-Time Device Telemetry Data Ingestion Pipeline 2 Data Engineering Machine Learning Devops Pipeline Pipeline The telemetry data is aggregated on an hourly 3 3 basis and re-partitioned based on the year, month, date, and hour using AWS Glue jobs. The Amazon Cognito AWS Glue Data Catalog additional steps like transformations and feature Device #1 engineering are performed for training the SageMaker AWS CodeBuild Anomaly Detection ML Model using AWS Glue Notebook Create ML jobs. The training data set is stored on Amazon Container S3 Data Lake. Amazon Kinesis AWS Lambda S3 Data Lake AWS Glue Device #2 Amazon API The training code is checked in an AWS Gateway Data Firehose 4 AWS SageMaker CodeCommit repo which triggers a Machine Training CodeCommit Containers Learning DevOps (MLOps) pipeline using AWS Dataset for Anomaly CodePipeline. -

Cloud Computing & Big Data
Cloud Computing & Big Data PARALLEL & SCALABLE MACHINE LEARNING & DEEP LEARNING Ph.D. Student Chadi Barakat School of Engineering and Natural Sciences, University of Iceland, Reykjavik, Iceland Juelich Supercomputing Centre, Forschungszentrum Juelich, Germany @MorrisRiedel LECTURE 11 @Morris Riedel @MorrisRiedel Big Data Analytics & Cloud Data Mining November 10, 2020 Online Lecture Review of Lecture 10 –Software-As-A-Service (SAAS) ▪ SAAS Examples of Customer Relationship Management (CRM) Applications (PAAS) (introducing a growing range of machine (horizontal learning and scalability artificial enabled by (IAAS) intelligence Virtualization capabilities) in Clouds) [5] AWS Sagemaker [4] Freshworks Web page [3] ZOHO CRM Web page modfied from [2] Distributed & Cloud Computing Book [1] Microsoft Azure SAAS Lecture 11 – Big Data Analytics & Cloud Data Mining 2 / 36 Outline of the Course 1. Cloud Computing & Big Data Introduction 11. Big Data Analytics & Cloud Data Mining 2. Machine Learning Models in Clouds 12. Docker & Container Management 13. OpenStack Cloud Operating System 3. Apache Spark for Cloud Applications 14. Online Social Networking & Graph Databases 4. Virtualization & Data Center Design 15. Big Data Streaming Tools & Applications 5. Map-Reduce Computing Paradigm 16. Epilogue 6. Deep Learning driven by Big Data 7. Deep Learning Applications in Clouds + additional practical lectures & Webinars for our hands-on assignments in context 8. Infrastructure-As-A-Service (IAAS) 9. Platform-As-A-Service (PAAS) ▪ Practical Topics 10. Software-As-A-Service -

Build a Secure Enterprise Machine Learning Platform on AWS AWS Technical Guide Build a Secure Enterprise Machine Learning Platform on AWS AWS Technical Guide
Build a Secure Enterprise Machine Learning Platform on AWS AWS Technical Guide Build a Secure Enterprise Machine Learning Platform on AWS AWS Technical Guide Build a Secure Enterprise Machine Learning Platform on AWS: AWS Technical Guide Copyright © Amazon Web Services, Inc. and/or its affiliates. All rights reserved. Amazon's trademarks and trade dress may not be used in connection with any product or service that is not Amazon's, in any manner that is likely to cause confusion among customers, or in any manner that disparages or discredits Amazon. All other trademarks not owned by Amazon are the property of their respective owners, who may or may not be affiliated with, connected to, or sponsored by Amazon. Build a Secure Enterprise Machine Learning Platform on AWS AWS Technical Guide Table of Contents Abstract and introduction .................................................................................................................... i Abstract .................................................................................................................................... 1 Introduction .............................................................................................................................. 1 Personas for an ML platform ............................................................................................................... 2 AWS accounts .................................................................................................................................... 3 Networking architecture ..................................................................................................................... -

Analytics Lens AWS Well-Architected Framework Analytics Lens AWS Well-Architected Framework
Analytics Lens AWS Well-Architected Framework Analytics Lens AWS Well-Architected Framework Analytics Lens: AWS Well-Architected Framework Copyright © Amazon Web Services, Inc. and/or its affiliates. All rights reserved. Amazon's trademarks and trade dress may not be used in connection with any product or service that is not Amazon's, in any manner that is likely to cause confusion among customers, or in any manner that disparages or discredits Amazon. All other trademarks not owned by Amazon are the property of their respective owners, who may or may not be affiliated with, connected to, or sponsored by Amazon. Analytics Lens AWS Well-Architected Framework Table of Contents Abstract ............................................................................................................................................ 1 Abstract .................................................................................................................................... 1 Introduction ...................................................................................................................................... 2 Definitions ................................................................................................................................. 2 Data Ingestion Layer ........................................................................................................... 2 Data Access and Security Layer ............................................................................................ 3 Catalog and Search Layer ................................................................................................... -

All Services Compute Developer Tools Machine Learning Mobile
AlL services X-Ray Storage Gateway Compute Rekognition d Satellite Developer Tools Amazon Sumerian Athena Machine Learning Elastic Beanstalk AWS Backup Mobile Amazon Transcribe Ground Station EC2 Servertess Application EMR Repository Codestar CloudSearch Robotics Amazon SageMaker Customer Engagement Amazon Transtate AWS Amplify Amazon Connect Application Integration Lightsail Database AWS RoboMaker CodeCommit Management & Governance Amazon Personalize Amazon Comprehend Elasticsearch Service Storage Mobile Hub RDS Amazon Forecast ECR AWS Organizations Step Functions CodeBuild Kinesis Amazon EventBridge AWS Deeplens Pinpoint S3 AWS AppSync DynamoDe Amazon Textract ECS CloudWatch Blockchain CodeDeploy Quicksight EFS Amazon Lex Simple Email Service AWS DeepRacer Device Farm ElastiCache Amazont EKS AWS Auto Scaling Amazon Managed Blockchain CodePipeline Data Pipeline Simple Notification Service Machine Learning Neptune FSx Lambda CloudFormation Analytics Cloud9 AWS Glue Simple Queue Service Amazon Polly Business Applications $3 Glacer AR & VR Amazon Redshift SWF Batch CloudTrail AWS Lake Formation Server Migration Service lot Device Defender Alexa for Business GuardDuty MediaConnect Amazon QLDB WorkLink WAF & Shield Config AWS Well. Architected Tool Route 53 MSK AWS Transfer for SFTP Artifact Amazon Chime Inspector lot Device Management Amazon DocumentDB Personal Health Dashboard C MediaConvert OpsWorks Snowball API Gateway WorkMait Amazon Macie MediaLive Service Catalog AWS Chatbot Security Hub Security, Identity, & Internet of Things loT -

Predictive Analytics with Amazon Sagemaker
Predictive Analytics with Amazon SageMaker Steve Shirkey Specialist SA, AWS (Singapore) © 2018 Amazon Web Services, Inc. or its Affiliates. All rights reserved. 2 Explosion in AI and ML Use Cases Image recognition and tagging for photo organization Object detection, tracking and navigation for Autonomous Vehicles Speech recognition & synthesis in Intelligent Voice Assistants Algorithmic trading strategy performance improvement Sentiment analysis for targeted advertisements © 2018 Amazon Web Services, Inc. or its Affiliates. All rights reserved. ~1997 © 2018 Amazon Web Services, Inc. or its Affiliates. All rights reserved. Thousands of Amazon Engineers Focused on Machine Learning Fulfillment & Search & Existing New At logistics discovery products products AWS © 2018 Amazon Web Services, Inc. or its Affiliates. All rights reserved. © 2018 Amazon Web Services, Inc. or its Affiliates. All rights reserved. © 2018 Amazon Web Services, Inc. or its Affiliates. All rights reserved. © 2018, Amazon Web Services, Inc. or its Affiliates. All rights reserved. © 2018 Amazon Web Services, Inc. or its Affiliates. All rights reserved. © 2018, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Over 20 years of AI at Amazon… • Applied research • Q&A systems • Core research • Supply chain optimization • Alexa • Advertising • Demand forecasting • Machine translation • Risk analytics • Video content analysis • Search • Robotics • Recommendations • Lots of computer vision… • AI services • NLP/NLU © 2018 Amazon Web Services, Inc. or its Affiliates. All rights reserved. ML @ AWS Put machine learning in the OUR MISSION hands of every developer and data scientist © 2018 Amazon Web Services, Inc. or its Affiliates. All rights reserved. Customers Running Machine Learning On AWS Today © 2018 Amazon Web Services, Inc. or its Affiliates. -

Fraud Detection in Online Lending Using Amazon Sagemaker
Case study Fraud Detection in online lending using Amazon SageMaker A powerful Machine Learning-based model enabled this company to implement an automated anomaly detection and fraud prevention mechanism that cut online Payment frauds by 27% ABOUT AXCESS.IO ABOUT Lend.in AXCESS.IO offers world-class Managed Cloud Services to businesses Designed for today's financial enterprises, Lend. It provides a worldwide. In a relatively short period, AXCESS.IO has already low-code, digital-first lending platform that accelerates scalable served several enterprise clients and has quickly evolved into a digital transformation, improves speed to market, and supports niche consulting firm specializing in Cloud Advisory, Cloud Managed business growth. The company helps many banks, credit Services, and DevOps Automation. institutions and lending agencies modernize their loan processes. The Lend-in platform leverages user-friendly API-based integrations and powerful cogn axcess.io © 2020, Amazon Web Services, Inc. or its affiliates. All rights reserved. THE CHALLENGE Lend.in’s lending management platform is leveraged by a number of financial services companies to enable digital lending. Through this platform, the company’s customers take advantage of a highly simplified application process where they can apply for credit using any device from anywhere. This unique offering provides much-needed credit that enhances the experience. However, there was no way to accurately screen applicants’ profile and compare against the pattern, so it also increases the potential for fraud. This issue was seriously increasing the credit risk, as well as it was a gap in Lend.in’s standing as an integrated FinTech solutions company THE SOLUTION Lend. -

Enabling Continual Learning in Deep Learning Serving Systems
ModelCI-e: Enabling Continual Learning in Deep Learning Serving Systems Yizheng Huang∗ Huaizheng Zhang∗ Yonggang Wen Nanyang Technological University Nanyang Technological University Nanyang Technological University [email protected] [email protected] [email protected] Peng Sun Nguyen Binh Duong TA SenseTime Group Limited Singapore Management University [email protected] [email protected] ABSTRACT streamline model deployment and provide optimizing mechanisms MLOps is about taking experimental ML models to production, (e.g., batching) for higher efficiency, thus reducing inference costs. i.e., serving the models to actual users. Unfortunately, existing ML We note that existing DL serving systems are not able to handle serving systems do not adequately handle the dynamic environ- the dynamic production environments adequately. The main reason ments in which online data diverges from offline training data, comes from the concept drift [8, 10] issue - DL model quality is resulting in tedious model updating and deployment works. This tied to offline training data and will be stale soon after deployed paper implements a lightweight MLOps plugin, termed ModelCI-e to serving systems. For instance, spam patterns keep changing (continuous integration and evolution), to address the issue. Specif- to avoid detection by the DL-based anti-spam models. In another ically, it embraces continual learning (CL) and ML deployment example, as fashion trends shift rapidly over time, a static model techniques, providing end-to-end supports for model updating and will result in an inappropriate product recommendation. If a serving validation without serving engine customization. ModelCI-e in- system is not able to quickly adapt to the data shift, the quality of cludes 1) a model factory that allows CL researchers to prototype inference would degrade significantly. -

Media2cloud Implementation Guide Media2cloud Implementation Guide
Media2Cloud Implementation Guide Media2Cloud Implementation Guide Media2Cloud: Implementation Guide Copyright © Amazon Web Services, Inc. and/or its affiliates. All rights reserved. Amazon's trademarks and trade dress may not be used in connection with any product or service that is not Amazon's, in any manner that is likely to cause confusion among customers, or in any manner that disparages or discredits Amazon. All other trademarks not owned by Amazon are the property of their respective owners, who may or may not be affiliated with, connected to, or sponsored by Amazon. Media2Cloud Implementation Guide Table of Contents Home ............................................................................................................................................... 1 Overview ........................................................................................................................................... 2 Cost .......................................................................................................................................... 2 Architecture ............................................................................................................................... 2 Ingest Workflow ................................................................................................................. 3 Analysis Workflow .............................................................................................................. 3 Labeling Workflow ............................................................................................................ -

Aws-Mlops-Framework.Pdf
AWS MLOps Framework Implementation Guide AWS MLOps Framework Implementation Guide AWS MLOps Framework: Implementation Guide Copyright © Amazon Web Services, Inc. and/or its affiliates. All rights reserved. Amazon's trademarks and trade dress may not be used in connection with any product or service that is not Amazon's, in any manner that is likely to cause confusion among customers, or in any manner that disparages or discredits Amazon. All other trademarks not owned by Amazon are the property of their respective owners, who may or may not be affiliated with, connected to, or sponsored by Amazon. AWS MLOps Framework Implementation Guide Table of Contents Home ............................................................................................................................................... 1 Cost ................................................................................................................................................ 3 Example cost table ..................................................................................................................... 3 Architecture overview ........................................................................................................................ 4 Template option 1: Single account deployment .............................................................................. 4 Template option 2: Multi-account deployment ............................................................................... 5 Shared resources and data between accounts ...............................................................................