Analysis, Modeling and Design of Flash-Based Solid-State Drives
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Synnex Corporate 2021 Line Card
SYNNEX CORPORATE 2021 LINE CARD Corporate Headquarters Fremont, California* Sales Headquarters Greenville, South Carolina Warehouse Locations 1 Tracy, California 3 5 2 Chantilly, Virginia 6 10 3 Romeoville, Illinois 1 4 Richardson, Texas 2 5 Monroe, New Jersey 8 6 Grove City, Ohio 9 7 Miami, Florida 4 8 Southaven, Mississippi* 9 Chino, California 10 Columbus, Ohio 7 *ISO-9001:2015 Manufacturing Facilities ADVANCING IT INNOVATIONS SERVICES Map your destination to increased productivity, Sounds simple, but at • GSA Schedule cost savings and overall business success. Our SYNNEX we understand that • ECExpress Online Ordering true business growth requires • Software Licensing distribution centers are strategically located across access to meaningful, tangible the United States to provide you with product business infrastructure, tools, • Reseller Marketing Services where you need it when you need it. Each of our and resources. That’s why • Leasing distribution centers provides our customers with over the last year we’ve • Integration Services invested heavily in providing • Trade Up warehouse ratings of nearly 100% in accuracy and our partners with high-impact • A Menu of Financial Services business services, designed PPS (pick, pack and ship) performance. Couple that • SYNNEX Service Network with unsurpassed service from our infrastructure from the ground up to provide real value, and delivering on • ASCii Program support, giving you one more reason why you our commitment to provide • PRINTSolv should be doing business with SYNNEX. That’s -

PX-850A X 16X DVD-ROM 12 48X CD-R/ROM Internal DVD Super Multi Drive 32X CD-RW
22X DVD±R 12X DVD-RAM x 8X DVD-R DL 22 8X DVD+R DL PATA (IDE) 8X DVD+RW 6X DVD-RW PX-850A x 16X DVD-ROM 12 48X CD-R/ROM Internal DVD Super Multi Drive 32X CD-RW The PX-850A Internal PATA DVD Super Multi Drive from Plextor® offers all the advantages of our legendary DVD and CD-RW drives. It supports blazing fast 22X burns on single layer DVD±R media (4.7 GB), 8X burns on double/dual layer media (8.5 GB) and 12X on reliable DVD-RAM media. With a PATA (IDE) interface, great features such as PlexREAD and PlexERASE, the PX-850A Internal PATA DVD Super Multi Drive is the only burner you’ll need to get the job done right the first time. Powerful Software that Works for You Take control of several powerful features of Plextor drives. FEATURES UTILITIES With the power of PlexUTILITIES for Windows® you now • Works with Windows® XP/Vista™ have extra support for your Plextor hardware. PlexUTILITIES allows you to view basic and advance drive information as well as offering high quality audio and multimedia capabili- • Records CSS (Content Scrambling ties. By allowing you to measure and control the burn quality of every disc on a Windows® System) encrypted content on dedicated platform, PlexUTILITIES makes coasters a thing of the past. The distinctive design in DVD download disc for CSS managed PlexUTILITIESERASE allows ease of use for newcomers without compromising on the powerful recording. features that experienced burners demand. • Supports PlexUTILITIES technologies to enhance your recording activities. -

Open Source Used in Cisco Virtual Topology System 2.1
Open Source Used In Cisco Virtual Topology System 2.1 Cisco Systems, Inc. www.cisco.com Cisco has more than 200 offices worldwide. Addresses, phone numbers, and fax numbers are listed on the Cisco website at www.cisco.com/go/offices. Text Part Number: 78EE117C99-112340008 Open Source Used In Cisco Virtual Topology System 2.1 1 This document contains licenses and notices for open source software used in this product. With respect to the free/open source software listed in this document, if you have any questions or wish to receive a copy of any source code to which you may be entitled under the applicable free/open source license(s) (such as the GNU Lesser/General Public License), please contact us at [email protected]. In your requests please include the following reference number 78EE117C99-112340008 The product also uses the Linux operating system, Ubuntu 14.04.2 (Server Version) BUNDLE. CLONE for VTS1.5 1.0. Information on this distribution is available at http://software.cisco.com/download/release.html?i=!y&mdfid=286285090&softwareid=286 283930&release=1.5&os=. The full source code for this distribution, including copyright and license information, is available on request from opensource- [email protected]. Mention that you would like the Linux distribution source archive, and quote the following reference number for this distribution: 92795016- 112340008. The product also uses the Linux operating system, Ubuntu 14.04.3 Server 14.04.3. Information on this distribution is available at http://releases.ubuntu.com/14.04.3/. The full source code for this distribution, including copyright and license information, is available on request from [email protected]. -
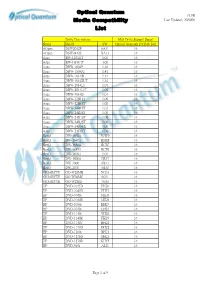
Optical Quantum Media Compatbility List
Optical Quantum v1.8B Media Compatbility Last Updated: 2020/06 List Drive Description Max Drive Support Speed Brand Model FW Optical Quantum DVD-R 16X AOpen DSW2012P 6A31 16 AOpen DSW2412S BA31 16 Asus BW-12B1ST 1.02 16 Asus BW-16D1HT 3.00 16 Asus DRW-1604P 1.18 16 Asus DRW-1608P2 1.41 16 Asus DRW-1814BL 1.14 16 Asus DRW-1814BLT 1.14 16 Asus DRW-2014L1 1.01 16 Asus DRW-2014L1T 1.02 16 Asus DRW-2014S1 1.01 16 Asus DRW-22B1LT 1.00 16 Asus DRW-22B1ST 1.00 16 Asus DRW-24B1ST 1.03 16 Asus DRW-24B3ST 1.00 16 Asus DRW-24D1ST 1.00 16 Asus DRW-24D3ST 1.00 16 Asus DRW-24D5MT 1.00 16 Asus DRW-24F1ST 1.00 16 BenQ DW-1620A B7W9 16 BenQ DW-1640A BSRB 16 BenQ DW-1650A BCIC 16 BenQ DW-1655A BCIB 16 BenQ DW-1670A 1.04 16 BenQ DW-1800A ZB37 16 BenQ DW-2000 6B33 16 BenQ DW-2010 5B33 16 GIGABYTE GO-W20MB XG33 16 GIGABYTE GO-W20MC 9G31 16 GIGABYTE GO-W20SD 7G33 16 HP DVD-1035D FH26 16 HP DVD-1040D EH27 16 HP DVD-1040i MH21 16 HP DVD-1040R MH21 16 HP DVD-1060i KH23 16 HP DVD-1070i LH23 16 HP DVD-1140i YH26 16 HP DVD-1140R FH25 16 HP DVD-1140T HH22 16 HP DVD-1170D DH22 16 HP DVD-1260i BH21 16 HP DVD-1270D GH23 16 HP DVD-1270R KHT5 16 HP DVD-540i A121 16 Page 1 of 9 Optical Quantum v1.8B Media Compatbility Last Updated: 2020/06 List Drive Description Max Drive Support Speed Brand Model FW Optical Quantum DVD-R 16X HP DVD-555R EH27 8 HP DVD-555S ZH22 8 HP DVD-556S MH24 8 HP DVD-557S QH22 8 HP DVD-565S PH22 8 HP DVD-630i CH16 16 HP DVD-640B E183 16 HP DVD-640C ES04 16 HP DVD-740B IL24 16 HP DVD-840D HPD5 16 HP DVD-940D 3H29 16 LG BH08LS20 2.00-03 16 LG BH08NS20 -

012NAG – December 2012
SOUTH AFRICA’S LEADING GAMING, COMPUTER & TECHNOLOGY MAGAZINE VOL 15 ISSUE 9 REVIEWS Halo 4 Need for Speed Most Wanted PC / PLAYSTATION / XBOX / NINTENDO Forza Horizon Assassin’s Creed III Medal of Honor: Warfi ghter Dishonored Zombi WIN ZombiU A Wii U + PREMIUM PACK Wii Limited Edition NINTENDO DIPS A TOE IN THE HARDCORE POND FEATURE 60 fun things to do in December Editor Michael “RedTide“ James [email protected] Contents Features Assistant editor 30 60 THINGS TO DO Geoff “GeometriX“ Burrows Regulars DURING YOUR HOLIDAY 10 Ed’s Note These holidays, you may fi nd yourself with a lot Staff writer of time to kill because you spent all your cash on Dane “Barkskin “ Remendes 12 Inbox 16 Bytes prezzies for other people and have none left to buy yourself a stack o’ new games. The fi rst thing you’re Contributing editor 49 home_coded Lauren “Guardi3n “ Das Neves going to want to do is write angry letters to all those 78 Everything Else horrible people who insist on receiving gift-wrapped Technical writer goodies from you, thereby robbing you of quality Neo “ShockG“ Sibeko gaming. Secondly, you’re going to want to read this Opinion list of gaming-related, time-killing activities, because International correspondent 16 I, Gamer it’s how you’re going to keep yourself from going Miktar “Miktar” Dracon 18 The Game Stalker insane due to boredom. 20 The Indie Investigator Contributors 40 WII U Rodain “Nandrew” Joubert 22 Miktar’s Meanderings Oh hey, a new gaming console! What a pleasant Walt “Ramjet” Pretorius 83 Hardwired surprise this is! We’ve taken a good, long look at Miklós “Mikit0707 “ Szecsei 98 Game Over Pippa “UnexpectedGirl” Tshabalala Nintendo’s Wii U, from its games to its delicious game- Tarryn “Azimuth “ Van Der Byl powering circuitry and its innovative tablet controller, Adam “Madman” Liebman to bring you all the info you need to decide if this is Previews the console for you. -

LINE CARD Worldwide Sourcing Network PRODUCT PORTFOLIO
LINE CARD Worldwide Sourcing Network PRODUCT PORTFOLIO ABOUT FUSION WORLDWIDE Fusion Worldwide is the premier sourcing distributor of electronic components. Partnering with the world’s largest electronics companies, we source current production goods on the open market. Fusion Worldwide’s capabilities extend into quality inspection and testing, inventory management and global logistics as well as obsolete and end of life products and after-market services. To learn more, visit fusionww.com FUSION WORLDWIDE 2 PRODUCT PORTFOLIO PRODUCT PORTFOLIO Integrated Circuits Memory Passives FPGA, Diodes, Analog, Chips, DIMM, Flash, Memory Capacitors, Resistors, Inductors, MOSFETS, Discretes, LEDs, Modules, Cards, SD-RAM, NAND Oscillators, Resistor Networks, Logic, Linear, Microcontrollers, Flash and all forms of DDR Crystals and more Transistors and more Storage CPUs Cards SSD, HDD, Memory Cards, Chipsets, CPUs, Processors and Graphics Cards, Raid Controllers, CD-ROM drives, DVD drives, Microprocessors Riser Cards, Ethernet Cards, Hard Drives and Optical Sound Cards and Expansion Cards Networking Boards Computer Products Optical Transceivers, Modems, Motherboards, Daughtercards LCDs, Power Supplies, Batteries, Routers, Network Interface and PCB Assemblies. Cables, CPU Fans, Monitors Cards, Switches and more and more Peripherals Finished Products Electomechanical Mice, Keyboards, Speakers, Laptops, Servers, Tablets, Relays, Switches, Connectors, Webcams and other I/O Devices. Phones, Desktops and more Fuses, IC Sockets, Sensors and Activators FUSION -

3Rd Dimension Veritas Et Visus November 2010 Vol 6 No 3
3rd Dimension Veritas et Visus November 2010 Vol 6 No 3 Hatsune Miku, p6 Keio University, p27 Holorad, p41 Letter from the publisher : Garage doors…by Mark Fihn 2 News from around the world 4 SD&A, January 18-20, 2010, San Jose, California 15 3D and Interactivity at SIGGRAPH 2010 by Michael Starks 21 It will be awesome if they don’t screw it up: 44 3D Printing, IP, and the Fight over the Next Great Disruptive Technology by Michael Weinberg Stereoscopic 3D Benchmarking: (DDD, iZ3D, NVIDIA) by Neil Schneider 60 Last Word: The film from hell…by Lenny Lipton 67 The 3rd Dimension is focused on bringing news and commentary about developments and trends related to the use of 3D displays and supportive components and software. The 3rd Dimension is published electronically 10 times annually by Veritas et Visus, 3305 Chelsea Place, Temple, Texas, USA, 76502. Phone: +1 254 791 0603. http://www.veritasetvisus.com Publisher & Editor-in-Chief Mark Fihn [email protected] Managing Editor Phillip Hill [email protected] Contributors Lenny Lipton, Neil Schneider, Michael Starks, and Michael Weinberg Subscription rate: US$47.99 annually. Single issues are available for US$7.99 each. Hard copy subscriptions are available upon request, at a rate based on location and mailing method. Copyright 2010 by Veritas et Visus. All rights reserved. Veritas et Visus disclaims any proprietary interest in the marks or names of others. Veritas et Visus 3rd Dimension November 2010 Garage doors… by Mark Fihn Long-time readers of this newsletter will be aware of my fascination with clever efforts to create 3D images from 2D surfaces. -

Company Vendor ID (Decimal Format) (AVL) Ditest Fahrzeugdiagnose Gmbh 4621 @Pos.Com 3765 0XF8 Limited 10737 1MORE INC
Vendor ID Company (Decimal Format) (AVL) DiTEST Fahrzeugdiagnose GmbH 4621 @pos.com 3765 0XF8 Limited 10737 1MORE INC. 12048 360fly, Inc. 11161 3C TEK CORP. 9397 3D Imaging & Simulations Corp. (3DISC) 11190 3D Systems Corporation 10632 3DRUDDER 11770 3eYamaichi Electronics Co., Ltd. 8709 3M Cogent, Inc. 7717 3M Scott 8463 3T B.V. 11721 4iiii Innovations Inc. 10009 4Links Limited 10728 4MOD Technology 10244 64seconds, Inc. 12215 77 Elektronika Kft. 11175 89 North, Inc. 12070 Shenzhen 8Bitdo Tech Co., Ltd. 11720 90meter Solutions, Inc. 12086 A‐FOUR TECH CO., LTD. 2522 A‐One Co., Ltd. 10116 A‐Tec Subsystem, Inc. 2164 A‐VEKT K.K. 11459 A. Eberle GmbH & Co. KG 6910 a.tron3d GmbH 9965 A&T Corporation 11849 Aaronia AG 12146 abatec group AG 10371 ABB India Limited 11250 ABILITY ENTERPRISE CO., LTD. 5145 Abionic SA 12412 AbleNet Inc. 8262 Ableton AG 10626 ABOV Semiconductor Co., Ltd. 6697 Absolute USA 10972 AcBel Polytech Inc. 12335 Access Network Technology Limited 10568 ACCUCOMM, INC. 10219 Accumetrics Associates, Inc. 10392 Accusys, Inc. 5055 Ace Karaoke Corp. 8799 ACELLA 8758 Acer, Inc. 1282 Aces Electronics Co., Ltd. 7347 Aclima Inc. 10273 ACON, Advanced‐Connectek, Inc. 1314 Acoustic Arc Technology Holding Limited 12353 ACR Braendli & Voegeli AG 11152 Acromag Inc. 9855 Acroname Inc. 9471 Action Industries (M) SDN BHD 11715 Action Star Technology Co., Ltd. 2101 Actions Microelectronics Co., Ltd. 7649 Actions Semiconductor Co., Ltd. 4310 Active Mind Technology 10505 Qorvo, Inc 11744 Activision 5168 Acute Technology Inc. 10876 Adam Tech 5437 Adapt‐IP Company 10990 Adaptertek Technology Co., Ltd. 11329 ADATA Technology Co., Ltd. -

Plextorpx-750A-UF Manual, 4Th Draft
Model PX-750A Internal ATAPI Drive Model PX-750UF External USB/FireWire Drive DVD±R DL (DOUBLE LAYER/DUAL LAYER), DVD±R/RW, DVD-RAM, CD-R/RW DRIVE INSTALLATION AND USERS MANUAL JANUARY 2006 Plextor reserves the right to make improvements in the products described in this manual at any time without prior notice. Plextor makes no representation or warranties with respect to the contents hereof and specifically disclaims any implied warranties of merchantability or fitness for any particular purpose. Further, Plextor Corp. reserves the right to revise this manual and to make changes in its content without obligation to notify any person or organization of such revision or change. This manual is copyrighted, all rights reserved. It may not be copied, photocopied, translated, or reduced to any electronic medium or machine-readable form without Plextor’s prior permission. Manual copyright ©2006 Plextor Corp. First edition, January 2006. Licenses and Trademarks Plextor and the Plextor logo are registered trademarks of Plextor Corp. All other licenses and trademarks are property of their respective owners. Record Your Serial Number For future reference, record the serial number and the TLA code (found on your drive’s label) in the space provided below. TLA/Firmware Revision Number FEDERAL COMMUNICATIONS COMMISSION STATEMENT This device complies with Part 15 of the FCC Rules. Operation is subject to the following two conditions: (1) This device may not cause harmful interference, and (2) this device must accept any interference received, including interference that may cause undesired operation. CAUTION: Any changes or modifications not expressly approved by the party responsible for compliance could void the user's authority to operate the equipment. -

Plextor 8/2/20 Manual, 4Th Draft
Models: PX-W8220Ti (Internal) PX-W8220Te (External) Congratulations! Thank you for purchasing the PlexWriter 8/2/20, a reliable, high-performance CD rewriter, recorder and reader. We appreciate the confidence you have shown in us. Our goal is to put you—and keep you—on the leading edge of CD technology. To get you there, we first have to help you install your PlexWriter drive properly and operate it correctly. After that, the responsibility is yours to seek the applications that make rewritable CD such a powerful and exciting addition to your system. FCC NOTICE This equipment has been tested and found to comply with the limits for a Class B digital device, pursuant to Part 15 of the FCC Rules. These limits are designed to provide reasonable protection against harmful interference in a residential installation. This equipment generates, uses, and can radiate radio frequency energy, and, if not installed and used in accordance with the instructions, may cause harmful interference to radio communications. However, there is no guarantee interference will not occur in a particular installation. If this equipment causes harmful interference to radio or television reception, which can be determined by turning the equipment off and on, the user is encouraged to try to correct the interference by one or more of the following measures: • Reorient or relocate the receiving antenna. • Increase the separation between the equipment and receiver. • Connect the equipment into an outlet on a circuit different from that to which the receiver is connected. • Consult the dealer or an experienced radio/TV technician for help. -

N Software Furman PLANON 1/4 TAPE FUTURE DESIGNS Planters 16X9 Inc
Positively Web Partners and Affiliates /n software Furman PLANON 1/4 TAPE FUTURE DESIGNS Planters 16x9 Inc. FUTURE MEMORY SOLUTIONS PLANTRONIC 1E SOFTWARE Future-Call Plantronics 2GIG FutureIT PLASMON 2N G Data PLDA 2X Software Gable Louvers & Vents Plews 2XL GammaTech Plextor 360Heros Ganz PLUSTEK 3CX Garmin Pneumatic Actuators 3M Garrett Pneumatic Control Valves 3M - ERGO Gateworks Pneumatic Cylinders 3M - OPTICAL SYSTEMS DIVISION GATOR Pneumatic Fittings 3M Industrial GBC Pneumatic Hoses 3M TOUCH SCREEN GE Pneumatic Parts Washers 3M VISUAL SYSTEMS DIVISION GE Critical Power Pneumatic Quick Connect Couplings 3NG Private Label Voip GE Lighting Pneumatic Solenoid Valves 3R Technologies GEAR HEAD-COMPUTER Pneumatic Tools Accessories 3WARE/AMCC Gearboxes Pneumatic Vibrators 4 Flute Countersinks GearWrench PNY 4MM TAPE Geemarc PNY MEMORY 4XEM GEFEN PNY QUADRO 5NINE GELID Solutions PNY VIDEO GRAPHICS 6 Flute Chatterless Countersinks GEM Electronics PoE Technologies 80/20 GENEVA PolarCool 8MM TAPE GENICOM Polaroid 8x8 Genie-Soft Polycom 9 Circle Genius POLYCOM AUDIO 9940/9840 GENOVATION POLYCOM CX Aaeon Electronics Gentex Corp. POLYCOM SPECTRALINK Aastra George Risk Industries POLYCOM VIDEO Aavid Thermalloy Georgia Pacific Polymer Bathroom Partitions ABA Cable Georgia SoftWorks Polypropylene ABBYY Geovision Pomona Electronics ABILITYONE Gerson PORELON ABLE BAY - NITHO GESTETNER Port-A-Cool AbleNet GFI Portescap Ableton GFX Power Porto-Power Abracon Ghent Portwell Absoft GIGABYTE POSITIVELY WEB ABSOLUTE LICENSE Gigaset Potter Absolute Software -

PX-Q840U X 16X DVD-ROM 12 48X CD-R/ROM External DVD Super Multi Drive 32X CD-RW
20X DVD±R 12X DVD-RAM x 8X DVD-R DL 20 8X DVD+R DL USB 2.0 8X DVD+RW 6X DVD-RW PX-Q840U x 16X DVD-ROM 12 48X CD-R/ROM External DVD Super Multi Drive 32X CD-RW The PX-Q840U External DVD Super Multi Drive from Plextor® follows the Qflix™ Program by Sonic Solutions and offers all the advantages of our legendary DVD and CD-RW drives. It supports blazing fast 20X burns on single layer DVD±R media (4.7 GB), 8X burns on double/ dual layer media (8.5 GB) and 12X on reliable DVD-RAM media. With a versatile USB 2.0 interface, the PX-Q840U External DVD Super Multi Drive is the only burner you’ll need to get the job done right the first time. Qflix drives and media make downloading and burning your favorite movies and TV titles as simple. Included with the purchase of a Qflix drive is Roxio Venue – a rich, user-friendly application that connects FEATURES directly to CinemaNow for easy purchase and download, organization, and burning of • Works with Windows® XP/Vista™ hit movies to DVD. Select your favorite movies online and then simply insert Qflix media into the Qflix drive and click to copy and create your own personal entertainment library. • Records CSS (Content Scrambling Watch your favorite movies anytime, anywhere. System) encrypted content on dedicated Qflix™ disc for CSS managed recording. Powerful Software that Works for You • Supports Qflix™ and PlexUTILITIES technologies to enhance your recording Take control of several powerful features of Plextor drives.