HLT/NAACL 2004 Template
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

New Approaches to Functional Process Discovery in HPV 16-Associated Cervical Cancer Cells by Gene Ontology
Cancer Research and Treatment 2003;35(4):304-313 New Approaches to Functional Process Discovery in HPV 16-Associated Cervical Cancer Cells by Gene Ontology Yong-Wan Kim, Ph.D.1, Min-Je Suh, M.S.1, Jin-Sik Bae, M.S.1, Su Mi Bae, M.S.1, Joo Hee Yoon, M.D.2, Soo Young Hur, M.D.2, Jae Hoon Kim, M.D.2, Duck Young Ro, M.D.2, Joon Mo Lee, M.D.2, Sung Eun Namkoong, M.D.2, Chong Kook Kim, Ph.D.3 and Woong Shick Ahn, M.D.2 1Catholic Research Institutes of Medical Science, 2Department of Obstetrics and Gynecology, College of Medicine, The Catholic University of Korea, Seoul; 3College of Pharmacy, Seoul National University, Seoul, Korea Purpose: This study utilized both mRNA differential significant genes of unknown function affected by the display and the Gene Ontology (GO) analysis to char- HPV-16-derived pathway. The GO analysis suggested that acterize the multiple interactions of a number of genes the cervical cancer cells underwent repression of the with gene expression profiles involved in the HPV-16- cancer-specific cell adhesive properties. Also, genes induced cervical carcinogenesis. belonging to DNA metabolism, such as DNA repair and Materials and Methods: mRNA differential displays, replication, were strongly down-regulated, whereas sig- with HPV-16 positive cervical cancer cell line (SiHa), and nificant increases were shown in the protein degradation normal human keratinocyte cell line (HaCaT) as a con- and synthesis. trol, were used. Each human gene has several biological Conclusion: The GO analysis can overcome the com- functions in the Gene Ontology; therefore, several func- plexity of the gene expression profile of the HPV-16- tions of each gene were chosen to establish a powerful associated pathway, identify several cancer-specific cel- cervical carcinogenesis pathway. -

The Rnase H-Like Superfamily: New Members, Comparative Structural Analysis and Evolutionary Classification Karolina A
4160–4179 Nucleic Acids Research, 2014, Vol. 42, No. 7 Published online 23 January 2014 doi:10.1093/nar/gkt1414 The RNase H-like superfamily: new members, comparative structural analysis and evolutionary classification Karolina A. Majorek1,2,3,y, Stanislaw Dunin-Horkawicz1,y, Kamil Steczkiewicz4, Anna Muszewska4,5, Marcin Nowotny6, Krzysztof Ginalski4 and Janusz M. Bujnicki1,3,* 1Laboratory of Bioinformatics and Protein Engineering, International Institute of Molecular and Cell Biology, ul. Ks. Trojdena 4, PL-02-109 Warsaw, Poland, 2Department of Molecular Physiology and Biological Physics, University of Virginia, 1340 Jefferson Park Avenue, Charlottesville, VA USA-22908, USA, 3Bioinformatics Laboratory, Institute of Molecular Biology and Biotechnology, Adam Mickiewicz University, Umultowska 89, PL-61-614 Poznan, Poland, 4Laboratory of Bioinformatics and Systems Biology, Centre of New Technologies, University of Warsaw, Zwirki i Wigury 93, PL-02-089 Warsaw, Poland, 5Institute of Biochemistry and Biophysics PAS, Pawinskiego 5A, PL-02-106 Warsaw, Poland and 6Laboratory of Protein Structure, International Institute of Molecular and Cell Biology, ul. Ks. Trojdena 4, PL-02-109 Warsaw, Poland Received September 23, 2013; Revised December 12, 2013; Accepted December 26, 2013 ABSTRACT revealed a correlation between the orientation of Ribonuclease H-like (RNHL) superfamily, also called the C-terminal helix with the exonuclease/endo- the retroviral integrase superfamily, groups together nuclease function and the architecture of the numerous enzymes involved in nucleic acid metab- active site. Our analysis provides a comprehensive olism and implicated in many biological processes, picture of sequence-structure-function relation- including replication, homologous recombination, ships in the RNHL superfamily that may guide func- DNA repair, transposition and RNA interference. -

Identification and Functional Analysis of Novel Genes Associated with Inherited Bone Marrow Failure Syndromes
Identification and Functional Analysis of Novel Genes Associated with Inherited Bone Marrow Failure Syndromes by Anna Matveev A thesis submitted in conformity with the requirements for the degree of Master of Science Institute of Medical Science University of Toronto © Copyright by Anna Matveev 2020 Abstract Identification and Functional Analysis of Novel Genes Associated with Inherited Bone Marrow Failure Syndromes Anna Matveev Master of Science Institute of Medical Science University of Toronto 2020 Inherited bone marrow failure syndromes are multisystem-disorders that affect development of hematopoietic system. One of IBMFSs is Shwachman-Diamond-syndrome and about 80-90% of patients have mutations in the Shwachman-Bodian-Diamond-Syndrome gene. To unravel the genetic cause of the disease in the remaining 10-20% of patients, we performed WES as well as SNP-genotyping in families with SDS-phenotype and no mutations in SBDS. The results showed a region of homozygosity in chromosome 5p-arm DNAJC21 is in this region. Western blotting revealed reduced/null protein in patient. DNAJC21-homolog in yeast has been shown facilitating the release of the Arx1/Alb1 heterodimer from pre-60S.To investigate the cellular functions of DNAJC21 we knocked-down it in HEK293T-cells. We observed a high-level of ROS, which led to reduced cell proliferation. Our data indicate that mutations in DNAJC21 contribute to SDS. We hypothesize that DNAJC21 related ribosomal defects lead to increased levels of ROS therefore altering development and maturation of hematopoietic cells. ii Acknowledgments I would like to take this opportunity to extend my deepest gratitude to everyone who has helped me throughout my degree. -

Datasheet: VMA00210 Product Details
Datasheet: VMA00210 Description: MOUSE ANTI NAB1 Specificity: NAB1 Format: Purified Product Type: PrecisionAb™ Monoclonal Clone: OTI1D2 Isotype: IgG1 Quantity: 100 µl Product Details Applications This product has been reported to work in the following applications. This information is derived from testing within our laboratories, peer-reviewed publications or personal communications from the originators. Please refer to references indicated for further information. For general protocol recommendations, please visit www.bio-rad-antibodies.com/protocols. Yes No Not Determined Suggested Dilution Western Blotting 1/1000 PrecisionAb antibodies have been extensively validated for the western blot application. The antibody has been validated at the suggested dilution. Where this product has not been tested for use in a particular technique this does not necessarily exclude its use in such procedures. Further optimization may be required dependant on sample type. Target Species Human Product Form Purified IgG - liquid Preparation Mouse monoclonal antibody purified by affinity chromatography from ascites Buffer Solution Phosphate buffered saline Preservative 0.09% Sodium Azide (NaN3) Stabilisers 1% Bovine Serum Albumin 50% Glycerol Immunogen Recombinant protein corresponding to amino acids 237-487 of human NAB1 (NP_005957) produced in E. coli External Database UniProt: Links Q13506 Related reagents Entrez Gene: 4664 NAB1 Related reagents Specificity Mouse anti Human NAB1 antibody recognizes the NGFI-A-binding protein 1, also known as Page 1 of 2 EGR-1-binding protein 1, EGR1 binding protein 1 and transcriptional regulatory protein p54. Mouse anti Human NAB1 antibody detects a band of 54 kDa. The antibody has been extensively validated for western blotting using whole cell lysates. Western Blotting Anti NAB1 detects a band of approximately 54 kDa in Jurkat cell lysates Instructions For Use Please refer to the PrecisionAb western blotting protocol. -

Early Growth Response 1 Acts As a Tumor Suppressor in Vivo and in Vitro Via Regulation of P53
Research Article Early Growth Response 1 Acts as a Tumor Suppressor In vivo and In vitro via Regulation of p53 Anja Krones-Herzig,1 Shalu Mittal,1 Kelly Yule,1 Hongyan Liang,2 Chris English,1 Rafael Urcis,1 Tarun Soni,1 Eileen D. Adamson,2 and Dan Mercola1,3 1Sidney Kimmel Cancer Center, San Diego, California and 2The Burnham Institute; 3Cancer Center, University of California at San Diego, La Jolla, California Abstract human tumor cell lines express little or no Egr1 in contrast to their normal counterparts (9–12). Furthermore, Egr1 is decreased or The early growth response 1 (Egr1) gene is a transcription factor that acts as both a tumor suppressor and a tumor undetectable in small cell lung tumors, human breast tumors promoter. Egr1-null mouse embryo fibroblasts bypass repli- (11, 13), and human gliomas (12). Reexpression of Egr1 in human tumor cells inhibits transformation. The mechanism of suppression cative senescence and exhibit a loss of DNA damage response h and an apparent immortal growth, suggesting loss of p53 involves the direct induction of TGF- 1 leading to an autocrine- functions. Stringent expression analysis revealed 266 tran- mediated suppression of transformation (8), increased fibronectin, scripts with >2-fold differential expression in Egr1-null mouse and plasminogen activator inhibitor (9). Egr1 also has been embryo fibroblasts, including 143 known genes. Of the 143 implicated in the regulation of p53 in human melanoma cells genes, program-assisted searching revealed 66 informative leading to apoptosis (14–16), and the proapoptotic tumor genes linked to Egr1. All 66 genes could be placed on a single suppressor gene PTEN also is directly regulated by Egr1 (17). -

Gigantea: Uncovering New Functions in Flower Development
G C A T T A C G G C A T genes Review Gigantea: Uncovering New Functions in Flower Development Claudio Brandoli 1, Cesar Petri 2 , Marcos Egea-Cortines 1 and Julia Weiss 1,* 1 Genética Molecular, Instituto de Biotecnología Vegetal, Edificio I+D+I, Plaza del Hospital s/n, Universidad Politécnica de Cartagena, 30202 Cartagena, Spain; [email protected] (C.B.); [email protected] (M.E.-C.) 2 Instituto de Hortofruticultura Subtropical y Mediterránea-UMA-CSIC, Departamento de Fruticultura Subtropical y Mediterránea, 29750 Algarrobo-costa, Málaga, Spain; [email protected] * Correspondence: [email protected]; Tel.: +34-868-071-078 Received: 27 August 2020; Accepted: 22 September 2020; Published: 28 September 2020 Abstract: GIGANTEA (GI) is a gene involved in multiple biological functions, which have been analysed and are partially conserved in a series of mono- and dicotyledonous plant species. The identified biological functions include control over the circadian rhythm, light signalling, cold tolerance, hormone signalling and photoperiodic flowering. The latter function is a central role of GI, as it involves a multitude of pathways, both dependent and independent of the gene CONSTANS(CO), as well as on the basis of interaction with miRNA. The complexity of the gene function of GI increases due to the existence of paralogs showing changes in genome structure as well as incidences of sub- and neofunctionalization. We present an updated report of the biological function of GI, integrating late insights into its role in floral initiation, flower development and volatile flower production. Keywords: Gene ontology; molecular function; cellular localisation; biological function; circadian clock; flowering time; flower development; floral scent 1. -

Supplementary Materials
Supplementary materials Supplementary Table S1: MGNC compound library Ingredien Molecule Caco- Mol ID MW AlogP OB (%) BBB DL FASA- HL t Name Name 2 shengdi MOL012254 campesterol 400.8 7.63 37.58 1.34 0.98 0.7 0.21 20.2 shengdi MOL000519 coniferin 314.4 3.16 31.11 0.42 -0.2 0.3 0.27 74.6 beta- shengdi MOL000359 414.8 8.08 36.91 1.32 0.99 0.8 0.23 20.2 sitosterol pachymic shengdi MOL000289 528.9 6.54 33.63 0.1 -0.6 0.8 0 9.27 acid Poricoic acid shengdi MOL000291 484.7 5.64 30.52 -0.08 -0.9 0.8 0 8.67 B Chrysanthem shengdi MOL004492 585 8.24 38.72 0.51 -1 0.6 0.3 17.5 axanthin 20- shengdi MOL011455 Hexadecano 418.6 1.91 32.7 -0.24 -0.4 0.7 0.29 104 ylingenol huanglian MOL001454 berberine 336.4 3.45 36.86 1.24 0.57 0.8 0.19 6.57 huanglian MOL013352 Obacunone 454.6 2.68 43.29 0.01 -0.4 0.8 0.31 -13 huanglian MOL002894 berberrubine 322.4 3.2 35.74 1.07 0.17 0.7 0.24 6.46 huanglian MOL002897 epiberberine 336.4 3.45 43.09 1.17 0.4 0.8 0.19 6.1 huanglian MOL002903 (R)-Canadine 339.4 3.4 55.37 1.04 0.57 0.8 0.2 6.41 huanglian MOL002904 Berlambine 351.4 2.49 36.68 0.97 0.17 0.8 0.28 7.33 Corchorosid huanglian MOL002907 404.6 1.34 105 -0.91 -1.3 0.8 0.29 6.68 e A_qt Magnogrand huanglian MOL000622 266.4 1.18 63.71 0.02 -0.2 0.2 0.3 3.17 iolide huanglian MOL000762 Palmidin A 510.5 4.52 35.36 -0.38 -1.5 0.7 0.39 33.2 huanglian MOL000785 palmatine 352.4 3.65 64.6 1.33 0.37 0.7 0.13 2.25 huanglian MOL000098 quercetin 302.3 1.5 46.43 0.05 -0.8 0.3 0.38 14.4 huanglian MOL001458 coptisine 320.3 3.25 30.67 1.21 0.32 0.9 0.26 9.33 huanglian MOL002668 Worenine -

Quantitative SUMO Proteomics Reveals the Modulation of Several
www.nature.com/scientificreports OPEN Quantitative SUMO proteomics reveals the modulation of several PML nuclear body associated Received: 10 October 2017 Accepted: 28 March 2018 proteins and an anti-senescence Published: xx xx xxxx function of UBC9 Francis P. McManus1, Véronique Bourdeau2, Mariana Acevedo2, Stéphane Lopes-Paciencia2, Lian Mignacca2, Frédéric Lamoliatte1,3, John W. Rojas Pino2, Gerardo Ferbeyre2 & Pierre Thibault1,3 Several regulators of SUMOylation have been previously linked to senescence but most targets of this modifcation in senescent cells remain unidentifed. Using a two-step purifcation of a modifed SUMO3, we profled the SUMO proteome of senescent cells in a site-specifc manner. We identifed 25 SUMO sites on 23 proteins that were signifcantly regulated during senescence. Of note, most of these proteins were PML nuclear body (PML-NB) associated, which correlates with the increased number and size of PML-NBs observed in senescent cells. Interestingly, the sole SUMO E2 enzyme, UBC9, was more SUMOylated during senescence on its Lys-49. Functional studies of a UBC9 mutant at Lys-49 showed a decreased association to PML-NBs and the loss of UBC9’s ability to delay senescence. We thus propose both pro- and anti-senescence functions of protein SUMOylation. Many cellular mechanisms of defense have evolved to reduce the onset of tumors and potential cancer develop- ment. One such mechanism is cellular senescence where cells undergo cell cycle arrest in response to various stressors1,2. Multiple triggers for the onset of senescence have been documented. While replicative senescence is primarily caused in response to telomere shortening3,4, senescence can also be triggered early by a number of exogenous factors including DNA damage, elevated levels of reactive oxygen species (ROS), high cytokine signa- ling, and constitutively-active oncogenes (such as H-RAS-G12V)5,6. -

Genomics Analysis of Potassium Channel Genes in Songbirds Reveals
Lovell et al. BMC Genomics 2013, 14:470 http://www.biomedcentral.com/1471-2164/14/470 RESEARCH ARTICLE Open Access Genomics analysis of potassium channel genes in songbirds reveals molecular specializations of brain circuits for the maintenance and production of learned vocalizations Peter V Lovell, Julia B Carleton and Claudio V Mello* Abstract Background: A fundamental question in molecular neurobiology is how genes that determine basic neuronal properties shape the functional organization of brain circuits underlying complex learned behaviors. Given the growing availability of complete vertebrate genomes, comparative genomics represents a promising approach to address this question. Here we used genomics and molecular approaches to study how ion channel genes influence the properties of the brain circuitry that regulates birdsong, a learned vocal behavior with important similarities to human speech acquisition. We focused on potassium (K-)Channels, which are major determinants of neuronal cell excitability. Starting with the human gene set of K-Channels, we used cross-species mRNA/protein alignments, and syntenic analysis to define the full complement of orthologs, paralogs, allelic variants, as well as novel loci not previously predicted in the genome of zebra finch (Taeniopygia guttata). We also compared protein coding domains in chicken and zebra finch orthologs to identify genes under positive selective pressure, and those that contained lineage-specific insertions/deletions in functional domains. Finally, we conducted comprehensive in situ hybridizations to determine the extent of brain expression, and identify K-Channel gene enrichments in nuclei of the avian song system. Results: We identified 107 K-Channel finch genes, including 6 novel genes common to non-mammalian vertebrate lineages. -

S41467-019-10037-Y.Pdf
ARTICLE https://doi.org/10.1038/s41467-019-10037-y OPEN Feedback inhibition of cAMP effector signaling by a chaperone-assisted ubiquitin system Laura Rinaldi1, Rossella Delle Donne1, Bruno Catalanotti 2, Omar Torres-Quesada3, Florian Enzler3, Federica Moraca 4, Robert Nisticò5, Francesco Chiuso1, Sonia Piccinin5, Verena Bachmann3, Herbert H Lindner6, Corrado Garbi1, Antonella Scorziello7, Nicola Antonino Russo8, Matthis Synofzik9, Ulrich Stelzl 10, Lucio Annunziato11, Eduard Stefan 3 & Antonio Feliciello1 1234567890():,; Activation of G-protein coupled receptors elevates cAMP levels promoting dissociation of protein kinase A (PKA) holoenzymes and release of catalytic subunits (PKAc). This results in PKAc-mediated phosphorylation of compartmentalized substrates that control central aspects of cell physiology. The mechanism of PKAc activation and signaling have been largely characterized. However, the modes of PKAc inactivation by regulated proteolysis were unknown. Here, we identify a regulatory mechanism that precisely tunes PKAc stability and downstream signaling. Following agonist stimulation, the recruitment of the chaperone- bound E3 ligase CHIP promotes ubiquitylation and proteolysis of PKAc, thus attenuating cAMP signaling. Genetic inactivation of CHIP or pharmacological inhibition of HSP70 enhances PKAc signaling and sustains hippocampal long-term potentiation. Interestingly, primary fibroblasts from autosomal recessive spinocerebellar ataxia 16 (SCAR16) patients carrying germline inactivating mutations of CHIP show a dramatic dysregulation of PKA signaling. This suggests the existence of a negative feedback mechanism for restricting hormonally controlled PKA activities. 1 Department of Molecular Medicine and Medical Biotechnologies, University Federico II, 80131 Naples, Italy. 2 Department of Pharmacy, University Federico II, 80131 Naples, Italy. 3 Institute of Biochemistry and Center for Molecular Biosciences, University of Innsbruck, A-6020 Innsbruck, Austria. -
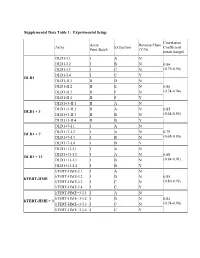
Table 3: Average Gene Expression Profiles by Chromosome
Supplemental Data Table 1: Experimental Setup Correlation Array Reverse Fluor Array Extraction Coefficient Print Batch (Y/N) mean (range) DLD1-I.1 I A N DLD1-I.2 I B N 0.86 DLD1-I.3 I C N (0.79-0.90) DLD1-I.4 I C Y DLD1 DLD1-II.1 II D N DLD1-II.2 II E N 0.86 DLD1-II.3 II F N (0.74-0.94) DLD1-II.4 II F Y DLD1+3-II.1 II A N DLD1+3-II.2 II A N 0.85 DLD1 + 3 DLD1+3-II.3 II B N (0.64-0.95) DLD1+3-II.4 II B Y DLD1+7-I.1 I A N DLD1+7-I.2 I A N 0.79 DLD1 + 7 DLD1+7-I.3 I B N (0.68-0.90) DLD1+7-I.4 I B Y DLD1+13-I.1 I A N DLD1+13-I.2 I A N 0.88 DLD1 + 13 DLD1+13-I.3 I B N (0.84-0.91) DLD1+13-I.4 I B Y hTERT-HME-I.1 I A N hTERT-HME-I.2 I B N 0.85 hTERT-HME hTERT-HME-I.3 I C N (0.80-0.92) hTERT-HME-I.4 I C Y hTERT-HME+3-I.1 I A N hTERT-HME+3-I.2 I B N 0.84 hTERT-HME + 3 hTERT-HME+3-I.3 I C N (0.74-0.90) hTERT-HME+3-I.4 I C Y Supplemental Data Table 2: Average gene expression profiles by chromosome arm DLD1 hTERT-HME Ratio.7 Ratio.1 Ratio.3 Ratio.3 Chrom. -

RNA–Protein Interaction Mapping Via MS2- Or Cas13-Based APEX Targeting
RNA–protein interaction mapping via MS2- or Cas13-based APEX targeting Shuo Hana,b,c,1, Boxuan Simen Zhaoa,b,c,1, Samuel A. Myersd, Steven A. Carrd, Chuan Hee,f, and Alice Y. Tinga,b,c,2 aDepartment of Genetics, Chan Zuckerberg Biohub, Stanford University, Stanford, CA 94305; bDepartment of Biology, Chan Zuckerberg Biohub, Stanford University, Stanford, CA 94305; cDepartment of Chemistry, Chan Zuckerberg Biohub, Stanford University, Stanford, CA 94305; dThe Broad Institute of Massachusetts Institute of Technology and Harvard University, Cambridge, MA 02142; eDepartment of Chemistry, Institute for Biophysical Dynamics, Howard Hughes Medical Institute, University of Chicago, Chicago, IL 60637; and fDepartment of Biochemistry and Molecular Biology, Institute for Biophysical Dynamics, Howard Hughes Medical Institute, University of Chicago, Chicago, IL 60637 Edited by Robert H. Singer, Albert Einstein College of Medicine, Bronx, NY, and approved July 24, 2020 (received for review April 8, 2020) RNA–protein interactions underlie a wide range of cellular pro- and oncogenesis by serving as the template for reverse transcrip- cesses. Improved methods are needed to systematically map RNA– tion of telomeres (26, 27). While hTR’s interaction with the protein interactions in living cells in an unbiased manner. We used telomerase complex has been extensively characterized (28), hTR two approaches to target the engineered peroxidase APEX2 to is present in stoichiometric excess over telomerase in cancer cells specific cellular RNAs for RNA-centered proximity biotinylation of (29) and is broadly expressed in tissues lacking telomerase protein protein interaction partners. Both an MS2-MCP system and an (30). These observations suggest that hTR could also function engineered CRISPR-Cas13 system were used to deliver APEX2 to outside of the telomerase complex (31), and uncharacterized the human telomerase RNA hTR with high specificity.