Course Report Project CS (1DT054) - Autumn 2013 Uppsala University
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Yet Another Web Server
Yaws - Yet Another Web Server Claes Wikstrom [email protected] September 9, 2018 Contents 1 Introduction 4 1.1 Prerequisites . 5 1.2 A tiny example . 5 2 Compile, Install, Config and Run 7 2.0.1 Compile and Install . 7 2.0.2 Configure . 8 3 Static content 11 4 Dynamic content 12 4.1 Introduction . 12 4.2 EHTML . 12 4.3 POSTs . 17 4.3.1 Queries . 17 4.3.2 Forms . 17 4.4 POSTing files . 18 5 Mode of operation 22 5.1 On-the-fly compilation . 22 5.2 Evaluating the Yaws Code . 23 6 SSL 24 6.1 Server Name Indication . 25 7 Applications 26 7.1 Login scenarios . 26 7.1.1 The session server . 26 1 CONTENTS 2 7.1.2 Arg rewrite . 28 7.1.3 Authenticating . 29 7.1.4 Database driven applications . 31 7.2 Appmods . 31 7.3 The opaque data . 32 7.4 Customizations . 32 7.4.1 404 File not found . 33 7.4.2 Crash messages . 33 7.5 Stream content . 34 7.6 All out/1 Return Values . 35 8 Debugging and Development 39 8.1 Logs . 39 9 External scripts via CGI 40 10 FastCGI 41 10.1 The FastCGI Responder Role . 41 10.2 The FastCGI Authorizer Role . 42 10.3 The FastCGI Filter Role . 42 10.4 FastCGI Configuration . 42 11 Security 43 11.1 WWW-Authenticate . 43 12 Embedded mode 45 12.1 Creating Global and Server Configurations . 45 12.2 Starting Yaws in Embedded Mode . 46 13 The config file - yaws.conf 47 13.1 Global Part . -

SDK De AWS Para Ruby Developer Guide
SDK de AWS para Ruby Developer Guide SDK de AWS para Ruby: Developer Guide Copyright © Amazon Web Services, Inc. and/or its affiliates. All rights reserved. SDK de AWS para Ruby Developer Guide Las marcas comerciales y la imagen comercial de Amazon no se pueden utilizar en relación con ningún producto o servicio que no sea de Amazon de ninguna manera que pueda causar confusión entre los clientes y que menosprecie o desacredite a Amazon. Todas las demás marcas comerciales que no son propiedad de Amazon son propiedad de sus respectivos propietarios, que pueden o no estar afiliados, conectados o patrocinados por Amazon. SDK de AWS para Ruby Developer Guide Table of Contents AWSGuía para desarrolladores de SDK for Ruby ................................................................................... 1 Mediante laAWSSDK for Ruby conAWS Cloud9 .............................................................................. 1 Acerca de esta guía ................................................................................................................... 1 Documentación y recursos adicionales .......................................................................................... 2 Implementación enAWSCloud ............................................................................................... 2 Mantenimiento y soporte para las versiones principales del SDK ........................................................ 2 Introducción ...................................................................................................................................... -

85324630.Pdf
About NetTantra NetTantra is a creative technology and design company based out of India, US and UK. We provide web based solutions and mobile solutions to various industries like manufacturing, consulting, education. We have expertise in various sectors of the web including an array of server-side languages, OpenSource CMS/Blog frameworks, Linux/UNIX system administration, production server backup and recovery solutions, cloud infrastructure set-up and much more. Our expertise in providing WordPress based solutions has been acclaimed by many of our clients and the OpenSource community. We also provide cloud based solutions like migrating existing applications and building cloud applications for public or private cloud setups. We are known among our clients for on-time delivery and extraordinary quality of service. In mobile based solutions, we have expertise in developing native applications for iOS and Android platforms. We also develop cross-platform mobile applications using Sencha Touch and jQuery Mobile frameworks. 2 of 14 pages Why Hire Us ✔ Technology ◦ We have expertise in the most cutting edge tools and technologies used in the industry with special focus on OpenSource Technologies ◦ We pay special attention to web and network security for all projects ◦ Our team follows highly optimized project delivery life cycles and processes ✔ Cost ◦ We offer the best price to quality ratio ✔ Infrastructure ◦ Advanced workstations ◦ Cutting edge computing and network systems ◦ Power packed online servers ◦ Smart communications systems ◦ Conference halls, CBT and video learning facilities ◦ High-speed uninterrupted Internet connection ✔ Quality of Service ◦ Guaranteed client satisfaction ◦ Real-time customer support with the least turn-around in the industry ◦ Pre-sales technical and business related support to partners and agencies ✔ Ethics and Principles ◦ We ensure confidentiality in all our dealings. -

Next Generation Web Scanning Presentation
Next generation web scanning New Zealand: A case study First presented at KIWICON III 2009 By Andrew Horton aka urbanadventurer NZ Web Recon Goal: To scan all of New Zealand's web-space to see what's there. Requirements: – Targets – Scanning – Analysis Sounds easy, right? urbanadventurer (Andrew Horton) www.morningstarsecurity.com Targets urbanadventurer (Andrew Horton) www.morningstarsecurity.com Targets What does 'NZ web-space' mean? It could mean: •Geographically within NZ regardless of the TLD •The .nz TLD hosted anywhere •All of the above For this scan it means, IPs geographically within NZ urbanadventurer (Andrew Horton) www.morningstarsecurity.com Finding Targets We need creative methods to find targets urbanadventurer (Andrew Horton) www.morningstarsecurity.com DNS Zone Transfer urbanadventurer (Andrew Horton) www.morningstarsecurity.com Find IP addresses on IRC and by resolving lots of NZ websites 58.*.*.* 60.*.*.* 65.*.*.* 91.*.*.* 110.*.*.* 111.*.*.* 113.*.*.* 114.*.*.* 115.*.*.* 116.*.*.* 117.*.*.* 118.*.*.* 119.*.*.* 120.*.*.* 121.*.*.* 122.*.*.* 123.*.*.* 124.*.*.* 125.*.*.* 130.*.*.* 131.*.*.* 132.*.*.* 138.*.*.* 139.*.*.* 143.*.*.* 144.*.*.* 146.*.*.* 150.*.*.* 153.*.*.* 156.*.*.* 161.*.*.* 162.*.*.* 163.*.*.* 165.*.*.* 166.*.*.* 167.*.*.* 192.*.*.* 198.*.*.* 202.*.*.* 203.*.*.* 210.*.*.* 218.*.*.* 219.*.*.* 222.*.*.* 729,580,500 IPs. More than we want to try. urbanadventurer (Andrew Horton) www.morningstarsecurity.com IP address blocks in the IANA IPv4 Address Space Registry Prefix Designation Date Whois Status [1] ----- -

Pipenightdreams Osgcal-Doc Mumudvb Mpg123-Alsa Tbb
pipenightdreams osgcal-doc mumudvb mpg123-alsa tbb-examples libgammu4-dbg gcc-4.1-doc snort-rules-default davical cutmp3 libevolution5.0-cil aspell-am python-gobject-doc openoffice.org-l10n-mn libc6-xen xserver-xorg trophy-data t38modem pioneers-console libnb-platform10-java libgtkglext1-ruby libboost-wave1.39-dev drgenius bfbtester libchromexvmcpro1 isdnutils-xtools ubuntuone-client openoffice.org2-math openoffice.org-l10n-lt lsb-cxx-ia32 kdeartwork-emoticons-kde4 wmpuzzle trafshow python-plplot lx-gdb link-monitor-applet libscm-dev liblog-agent-logger-perl libccrtp-doc libclass-throwable-perl kde-i18n-csb jack-jconv hamradio-menus coinor-libvol-doc msx-emulator bitbake nabi language-pack-gnome-zh libpaperg popularity-contest xracer-tools xfont-nexus opendrim-lmp-baseserver libvorbisfile-ruby liblinebreak-doc libgfcui-2.0-0c2a-dbg libblacs-mpi-dev dict-freedict-spa-eng blender-ogrexml aspell-da x11-apps openoffice.org-l10n-lv openoffice.org-l10n-nl pnmtopng libodbcinstq1 libhsqldb-java-doc libmono-addins-gui0.2-cil sg3-utils linux-backports-modules-alsa-2.6.31-19-generic yorick-yeti-gsl python-pymssql plasma-widget-cpuload mcpp gpsim-lcd cl-csv libhtml-clean-perl asterisk-dbg apt-dater-dbg libgnome-mag1-dev language-pack-gnome-yo python-crypto svn-autoreleasedeb sugar-terminal-activity mii-diag maria-doc libplexus-component-api-java-doc libhugs-hgl-bundled libchipcard-libgwenhywfar47-plugins libghc6-random-dev freefem3d ezmlm cakephp-scripts aspell-ar ara-byte not+sparc openoffice.org-l10n-nn linux-backports-modules-karmic-generic-pae -
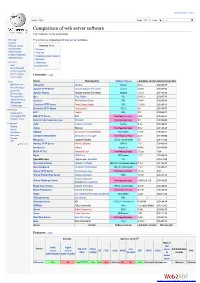
Comparison of Web Server Software from Wikipedia, the Free Encyclopedia
Create account Log in Article Talk Read Edit ViewM ohrisetory Search Comparison of web server software From Wikipedia, the free encyclopedia Main page This article is a comparison of web server software. Contents Featured content Contents [hide] Current events 1 Overview Random article 2 Features Donate to Wikipedia 3 Operating system support Wikimedia Shop 4 See also Interaction 5 References Help 6 External links About Wikipedia Community portal Recent changes Overview [edit] Contact page Tools Server Developed by Software license Last stable version Latest release date What links here AOLserver NaviSoft Mozilla 4.5.2 2012-09-19 Related changes Apache HTTP Server Apache Software Foundation Apache 2.4.10 2014-07-21 Upload file Special pages Apache Tomcat Apache Software Foundation Apache 7.0.53 2014-03-30 Permanent link Boa Paul Phillips GPL 0.94.13 2002-07-30 Page information Caudium The Caudium Group GPL 1.4.18 2012-02-24 Wikidata item Cite this page Cherokee HTTP Server Álvaro López Ortega GPL 1.2.103 2013-04-21 Hiawatha HTTP Server Hugo Leisink GPLv2 9.6 2014-06-01 Print/export Create a book HFS Rejetto GPL 2.2f 2009-02-17 Download as PDF IBM HTTP Server IBM Non-free proprietary 8.5.5 2013-06-14 Printable version Internet Information Services Microsoft Non-free proprietary 8.5 2013-09-09 Languages Jetty Eclipse Foundation Apache 9.1.4 2014-04-01 Čeština Jexus Bing Liu Non-free proprietary 5.5.2 2014-04-27 Galego Nederlands lighttpd Jan Kneschke (Incremental) BSD variant 1.4.35 2014-03-12 Português LiteSpeed Web Server LiteSpeed Technologies Non-free proprietary 4.2.3 2013-05-22 Русский Mongoose Cesanta Software GPLv2 / commercial 5.5 2014-10-28 中文 Edit links Monkey HTTP Server Monkey Software LGPLv2 1.5.1 2014-06-10 NaviServer Various Mozilla 1.1 4.99.6 2014-06-29 NCSA HTTPd Robert McCool Non-free proprietary 1.5.2a 1996 Nginx NGINX, Inc. -

The Jumpgate Definitive Guide
THE JUMPGATE DEFINITIVE GUIDE Compiled by: Odiche Special Thanks to: NETDEVIL© NewDawn IkeProf RazorKiss Lady Dracoe SpaceDrake Zalty’s And all the Pilots I have forgotten to thank! FACTIONS Solrain: Medium-fast ships, heavy, fast-recharging shields. A little light on firepower, lots of flexibility in ship loadout because of a large number of MODx slots. (MODx are worth reading up on in JOSSH). All Solrain ships have buckets of cargo space... the Solrain Fighter-class ship, the Intensity can carry a full set of equipment in it's hold to re-equip a downed squadmate. The Solrain Bomber and Medium Fighter are top-of-the-line, and they have a good Light Transport as well. Solrain ships are fairly forgiving for a new pilot; the glut of Flashfire MODxes they can equip can ensure their survival in situations where any other ship would be gunned down before it could escape. Solrain ships often utilize hit and run techniques in combat to gain the maximum advantage from their fast-recharging shields. Solrain ships can generally re-equip to a fairly good degree from their home stations. Solrain are typically RPed (Roleplayed) as greedy, profiteering traders. Which they are. Assassins, Mercenaries, Pirates, Traders, or Factionalists. To piss off a Solrain pilot, call him a Smurf. Quantar: Usually have the fastest ships in a given class. They also have a medium load- out of MODx slots. Quantar ships rely on maneuvrability to evade incoming fire; the Quantar fighters, the Typhoon, is an ideal wolf-pack ship. Their speed can carry them out of most trouble; only scouts or an Intensity can really catch them up, and if you are a skilled pilot, you can evade and escape from those also. -

Yaws : Yet Another Web Server
Yaws : Yet Another Web Server Xavier Van de Woestyne ~ @derniercriio (Lille |> Elixir) 3 WHOAMI I @vdwxv sur Twitter, @xvw sur Github ; I Erlang, OCaml, Elixir, Ruby etc. ; I Développeur à Dernier Cri ; I LilleFP. Qui a de l’expérience dans le tuning de BEAM et de OTP et du Lexer Erlang ? Figure 1: Ouf, moins de 4 personnes ! Sommaire Objectif Faire une brève présentation des outils Erlang ! Plan I Erlang et le web (Cowboy + blablabla) ; I présentation formelle de Yaws ; I applications structurées avec modernité et Appmode ; I et dans le futur ; I conclusion. “Erlang is the DSL for writing (web) servers” @pavlobaron I Concurrent ; I la VM peut transformer les interactions avec des sockets en envois de messages ; I gen_(...) et inets. On peut imaginer écrire un serveur en ~40 lignes de codes. Et comment tenir la montée en charge ? I gen_server I supervisor I application (pour la bogossitude) C’est tellement simple qu’il existe des milliers de serveurs (web) sur les internets ! I Elli ; I Cowboy ; I Yaws ; I MochiWeb ; I Misultin ; I ... Figure 2: aha Cowboy, le choix de Phoenix ! En vrai, Cowboy n’est pas un serveur HTTP(s) . I Bibliothèque Low-level ; I discutablement composable ; I très efficace ; I facile à prendre en main. C’était un choix qui s’inscrivait vraiment bien dans la vibe de Phoenix ! Les apports de Cowboy dans le monde Erlang I Une culture de la bibliothèque spécialisée ; I une véritable culture de l’usage des high-order-function (sans troll) ; I de l’agilité (facile à maintenir et tout) ! I Phoenix. -

Steve Vinoski Architect, Basho Technologies Erlang Factory London 2011 9 June 2011 @Stevevinoski
A Decade of Yaws Steve Vinoski Architect, Basho Technologies Erlang Factory London 2011 9 June 2011 @stevevinoski http://steve.vinoski.net/ 1 What We’ll Cover • Some Yaws history • Yaws community • Some Yaws features • Performance discussion • Yaws future 2 What is Yaws? • "Yet Another Web Server" — an HTTP 1.1 web server • Brainchild of Claes "Klacke" Wikström, who also created Erlang features such as • bit syntax • dets • Mnesia • Distributed Erlang • Yaws is known for years of reliability and stability • Current version: 1.90, released 26 May 2011 3 Why Yaws? • In 2001 Klacke was in a floorball league and needed a way for players to sign up on the web • He was horrified by the LAMP stack and PHP • So he wrote Yaws, but never finished the floorball site :-) 4 Yaws Community 5 Website and Email • Website: http://yaws.hyber.org • Mailing list: [email protected] • List archives: http://sourceforge.net/ mailarchive/forum.php?forum_name=erlyaws- list 6 Committers Claes Wikstrom Steve Vinoski Johan Bevemyr Carsten Schultz 1%1%0%0%0%0%0%0%0%0%0%0%0%0%0%0%0% Tobbe Tornquist Christopher Faulet 1%1%1% 1%1% Mikael Karlsson Fabian Alenius 2% 5% Mickael Remond Olivier Girondel Luke Gorrie Leon Smith 5% Martin Bjorklund Yariv Sadan Tuncer Ayaz Hans Ulrich Niedermann 12% 55% Davide Marquês Paul Hampson Julian Noble Sean Hinde Eric Liang Per Andersson Nicolas Thauvin Dominique Boucher 12% Thomas O'Dowd Sebastian Stroll Peter Lemenkov Jean-Sébastien Pédron Fabian Linzberger Bruce Fitzsimmons Anders Nygren (two or more commits) 7 Commits -

Delivering Web Content
Delivering web content GET /rfc.html HTTP/1.1 Host: www.ie.org GET /rfc.html HTTP/1.1 User-agent: Mozilla/4.0 Host: www.ie.org GET /rfc.html HTTP/1.1 User-agent: Mozilla/4.0 Host: www.ie.org User-agent: Mozilla/4.0 GET /rfc.html HTTP/1.1 Host: www.ie.org GET /rfc.html HTTP/1.1 User-agent: Mozilla/4.0 Host: www.ie.org User-agent: Mozilla/4.0 CSCI 470: Web Science • Keith Vertanen • Copyright © 2011 Overview • HTTP protocol review – Request and response format – GET versus POST • Stac and dynamic content – Client-side scripIng – Server-side extensions • CGI • Server-side includes • Server-side scripng • Server modules • … 2 HTTP protocol • HyperText Transfer Protocol (HTTP) – Simple request-response protocol – Runs over TCP, port 80 – ASCII format request and response headers GET /rfc.html HTTP/1.1 Host: www.ie.org Method User-agent: Mozilla/4.0 Header lines Carriage return, line feed indicates end of request 3 TCP details MulIple Persistent Persistent connecIons and connecIon and connecIon and sequenIal requests. sequenIal requests. pipelined requests. 4 HTTP request GET /rfc.html HTTP/1.1 Host: www.ie7.org User-agent: Mozilla/4.0 POST /login.html HTTP/1.1 Host: www.store.com User-agent: Mozilla/4.0 Content-Length: 27 Content-Type: applicaon/x-www-form-urlencoded userid=joe&password=guessme 5 HTTP response • Response from server – Status line: protocol version, status code, status phrase – Response headers: extra info – Body: opIonal data HTTP/1.1 200 OK Date: Thu, 17 Nov 2011 15:54:10 GMT Server: Apache/2.2.16 (Debian) Last-Modified: Wed, -

Web Server Deathmatch
Web Server Deathmatch Joe Williams Cloudant @williamsjoe on Twitter http://www.joeandmotorboat.com/ Overview The Contenders The Systems, Test Setup, Environment and Configuration The Results Base Tests Experiements 13A vs 12B-5 Take Home Web Server Deathmatch - Joe Williams - Erlang Factory 2009 The Contenders Apache (Prefork) Apache (Worker) Erlang INETS:HTTP Lighttpd MochiWeb Nginx Yaws Web Server Deathmatch - Joe Williams - Erlang Factory 2009 The Systems Server Intel Core 2 Duo T7500 2.20GHz 4GB RAM 7200 RPM Hard Disk Ubuntu 8.10 x86_64 httperf Client Intel Core 2 Duo P7350 2.0GHz 2GB RAM 5400 RPM Hard Disk OSX x86_64 GigE link between machines Web Server Deathmatch - Joe Williams - Erlang Factory 2009 The Test Used httperf to test performance of serving static files Request payload 10k PNG file Six total test runs Three tests then reboot of server then three more Httperf configuration Request rates, 1000 to 5000/sec Incremented by 1000 each test Based on connections and calls 1000 requests = 100 connections x 10 calls per connection 2000 requests = 200 connections x 10 calls per connection etc .. Web Server Deathmatch - Joe Williams - Erlang Factory 2009 Environment & Configuration Ran many iterations of the test to find optimal configurations for each server httperf via autobench httperf compiled with -DFD_SETSIZE=10000 -D_DARWIN_ULIMITED_SELECT autobench is a wrapper script for automating httperf tests http://www.xenoclast.org/autobench/ http://www.hpl.hp.com/research/linux/httperf/ Web Server Deathmatch - Joe Williams - Erlang -

E.2 Instalación Del Sistema De Monitoreo Web De Signos Vitales 168 E.2.1 Instalación De Noisette 168
INSTITUTO POLITÉCNICO NACIONAL UNIDAD PROFESIONAL INTERDISCIPLINARIA EN INGENIERÍA Y TECNOLOGÍAS AVANZADAS UPIITA Trabajo Terminal Desarrollo de un Sistema de Monitoreo Web de Signos Vitales Que para obtener el título de “Ingeniero en Telemática” Presenta Mario Alberto García Torrea Asesores Ing. Francisco Antonio Polanco Montelongo M. en C. Noé Sierra Romero Dr. en F. Fernando Martínez Piñón México D. F. a 29 de mayo del 2008 INSTITUTO POLITÉCNICO NACIONAL UNIDAD PROFESIONAL INTERDISCIPLINARIA EN INGENIERÍA Y TECNOLOGÍAS AVANZADAS UPIITA Trabajo Terminal Desarrollo de un Sistema de Monitoreo Web de Signos Vitales Que para obtener el título de “Ingeniero en Telemática” Presenta Mario Alberto García Torrea Asesores Ing. Francisco Antonio M. en C. Noé Sierra Dr. en F. Fernando Polanco Montelongo Romero Martínez Piñón Presidente del Jurado Profesor Titular M. en C. Miguel Félix Mata M. en C. Susana Araceli Sánchez Rivera Nájera Agradecimientos A mi familia Por enseñarme a creer y ayudarme a crecer; porque siempre han estado ahí cuando los he necesitado; por enseñarme que las mejores cosas de la vida no son más que aquellas que hacemos con el corazón, en las que podemos soñar y alcanzar, y por las que debemos de luchar. Gracias papá por tu sabiduría y por todos los consejos que me has brindado. Gracias mamá por procurarnos sencillez y por enseñarnos a amar. Gracias hermano porque – aunque siempre buscas la forma de molestarme – estás ahí creyendo en mí. A mis amigos Porque han creido en mí y me han apoyado con su compañía, su alegría y consejos. Gracias por ayudarme a crecer y a creer que todo es posible si realmente queremos que así lo sea; y sobre todo si creemos en nosotros mismos.