Context in Neural Machine Translation: a Review of Models and Evaluations
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Final Study Report on CEF Automated Translation Value Proposition in the Context of the European LT Market/Ecosystem
Final study report on CEF Automated Translation value proposition in the context of the European LT market/ecosystem FINAL REPORT A study prepared for the European Commission DG Communications Networks, Content & Technology by: Digital Single Market CEF AT value proposition in the context of the European LT market/ecosystem Final Study Report This study was carried out for the European Commission by Luc MEERTENS 2 Khalid CHOUKRI Stefania AGUZZI Andrejs VASILJEVS Internal identification Contract number: 2017/S 108-216374 SMART number: 2016/0103 DISCLAIMER By the European Commission, Directorate-General of Communications Networks, Content & Technology. The information and views set out in this publication are those of the author(s) and do not necessarily reflect the official opinion of the Commission. The Commission does not guarantee the accuracy of the data included in this study. Neither the Commission nor any person acting on the Commission’s behalf may be held responsible for the use which may be made of the information contained therein. ISBN 978-92-76-00783-8 doi: 10.2759/142151 © European Union, 2019. All rights reserved. Certain parts are licensed under conditions to the EU. Reproduction is authorised provided the source is acknowledged. 2 CEF AT value proposition in the context of the European LT market/ecosystem Final Study Report CONTENTS Table of figures ................................................................................................................................................ 7 List of tables .................................................................................................................................................. -

A Comparison of Free Online Machine Language Translators Mahesh Vanjani1,* and Milam Aiken2 1Jesse H
Journal of Management Science and Business Intelligence, 2020, 5–1 July. 2020, pages 26-31 doi: 10.5281/zenodo.3961085 http://www.ibii-us.org/Journals/JMSBI/ ISBN 2472-9264 (Online), 2472-9256 (Print) A Comparison of Free Online Machine Language Translators Mahesh Vanjani1,* and Milam Aiken2 1Jesse H. Jones School of Business, Texas Southern University, 3100 Cleburne Street, Houston, TX 77004 2School of Business Administration, University of Mississippi, University, MS 38677 *Email: [email protected] Received on 5/15/2020; revised on 7/25/2020; published on 7/26/2020 Abstract Automatic Language Translators also referred to as machine translation software automate the process of language translation without the intervention of humans While several automated language translators are available online at no cost there are large variations in their capabilities. This article reviews prior tests of some of these systems, and, provides a new and current comprehensive evaluation of the following eight: Google Translate, Bing Translator, Systran, PROMT, Babylon, WorldLingo, Yandex, and Reverso. This re- search could be helpful for users attempting to explore and decide which automated language translator best suits their needs. Keywords: Automated Language Translator, Multilingual, Communication, Machine Translation published results of prior tests and experiments we present a new and cur- 1 Introduction rent comprehensive evaluation of the following eight electronic automatic language translators: Google Translate, Bing Translator, Systran, Automatic Language Translators also referred to as machine translation PROMT, Babylon, WorldLingo, Yandex, and Reverso. This research software automate the process of language translation without the inter- could be helpful for users attempting to explore and decide which auto- vention of humans. -

Machine Translation in the Field of Law: a Study of the Translation of Italian Legal Texts Into German
Comparative Legilinguistics vol. 37/2019 DOI: http://dx.doi.org/10.14746/cl.2019.37.4 MACHINE TRANSLATION IN THE FIELD OF LAW: A STUDY OF THE TRANSLATION OF ITALIAN LEGAL TEXTS INTO GERMAN EVA WIESMANN, Prof., PhD Department of Interpreting and Translation, University of Bologna Corso della Repubblica 136, 47121 Forlì, Italy [email protected] ORCID: https://orcid.org/0000-0001-9414-8038 Abstract: With the advent of the neural paradigm, machine translation has made another leap in quality. As a result, its use by trainee translators has increased considerably, which cannot be disregarded in translation pedagogy. However, since legal texts have features that pose major challenges to machine translation, the question arises as to what extent machine translation is now capable of translating legal texts or at least certain types of legal text into another legal language well enough so that the post- editing effort is limited, and, consequently, whether a targeted use in translation pedagogy can be considered. In order to answer this question, DeepL Translator, a machine translation system, and MateCat, a CAT system that integrates machine translation, were tested. The test, undertaken at different times and without specific translation memories, provided Eva Wiesmann: Machine Translation in… for the translation of several legal texts of different types utilising both systems, and was followed by systematisation of errors and evaluation of translation results. The evaluation was carried out according to the following criteria: 1) comprehensibility and meaningfulness of the target text; and 2) correspondence between source and target text in consideration of the specific translation situation. -

Automated Translation in Typo3
AUTOMATED TRANSLATION IN TYPO3 Whitepaper on Translating contents automatically using DeepL and Google Translate in TYPO3 backend by Georgy GE What is TYPO3? TYPO3 CMS is an Open Source Enterprise Content Management System with a large global community. TYPO3 is written in PHP scripting language and was initially authored by Dane Kasper Skårhøj in 1997. The standout features of TYPO3 is its diversity and modularity. It can keep running on multiple web servers like Apache, Nginx or IIS and over numerous operating systems such as Linux, Microsoft Windows, FreeBSD, Mac OS X and OS/2. TYPO3 provides the basis for modern content management that can be adapted by small business websites to large multi-lingual global enterprises portals. TYPO3 always keeps a check on the updated requirements of businesses and public institutions. TYPO3 is opted by small and medium enterprises and municipalities because of its license- cost-free open source approach. In addition to the basic set of interfaces, functions and modules, TYPO3's functionality spectrum can be implemented using extensions. TYPO3 allows users or website operators to upgrade the corresponding websites using a solid extensions framework, and helps to publish and deliver any form of content to multiple devices. During the course of development of a TYPO3 website, a developer can rely on a strong community and about 6,000 extensions that offer unlimited possibilities. Ph : +41 43 558 4360 E-mail: [email protected] Visit: www.pitsolutions.com 2 Why TYPO3? 1. No license cost TYPO3 is an open source software under the GNU General Public License with no license fee. -

Report About a Survey-Based Research on Machine Translation Post-Editing
REPORT ABOUT A SURVEY‐BASED RESEARCH ON MACHINE TRANSLATION POST‐EDITING Common ground and gaps between LSCs, linguists and trainers Clara Ginovart Cid Universitat Pompeu Fabra Barcelona 22/12/2020 This report presents the findings of a survey‐based research based on three online questionnaires. It is part of the Industrial Doctorates research n° “2017 DI 010”. One questionnaire is addressed to Language Service Companies (LSCs) that sell or use as a process machine translation post‐editing (MTPE, also abbreviated PEMT). It received 66 submissions. Another questionnaire is addressed to individual linguists (inhouse or freelance) who accept MTPE assignments, and it received 141 submissions. Finally, the third questionnaire is addressed to European master or postgraduate PE educators, and it received 54 submissions. The survey‐based research is completed in between the end of 2018 and the beginning of 2019. In this report, the content of each questionnaire is presented in the first section (1. Content of the Questionnaires). In the second section (2. Results of the Submissions), the data of their findings is displayed, where the percentages have been rounded off. The three related publications where the findings are discussed are cited below: Ginovart Cid C, Colominas C, Oliver A. Language industry views on the profile of the post‐ editor. Translation Spaces. 2020 Jan 14. DOI:10.1075/ts.19010.cid Ginovart Cid C. The Professional Profile of a Post‐editor according to LSCs and Linguists: a Survey‐Based Research. HERMES ‐ Journal of Language and Communication in Business, 60, 171‐190. 2020 Jul 08. DOI:10.7146/hjlcb.v60i0.121318 Ginovart Cid C, Oliver A. -

Assessing the Comprehensibility and Perception of Machine Translations
ASSESSING THE COMPREHENSIBILITY AND PERCEPTION OF MACHINE TRANSLATIONS A PILOT STUDY Aantal woorden: 16 804 Iris Ghyselen Studentennummer: 01400320 Promotor: Prof. dr. Lieve Macken Masterproef voorgelegd voor het behalen van de graad master in het vertalen in de richting Toegepaste Taalkunde Academiejaar: 2017 – 2018 ASSESSING THE COMPREHENSIBILITY AND PERCEPTION OF MACHINE TRANSLATIONS A PILOT STUDY Aantal woorden: 16 804 Iris Ghyselen Studentennummer: 01400320 Promotor: Prof. dr. Lieve Macken Masterproef voorgelegd voor het behalen van de graad master in het vertalen in de richting Toegepaste Taalkunde Academiejaar: 2017 – 2018 i VERKLARING I.V.M. AUTEURSRECHT De auteur en de promotor(en) geven de toelating deze studie als geheel voor consultatie beschikbaar te stellen voor persoonlijk gebruik. Elk ander gebruik valt onder de beperkingen van het auteursrecht, in het bijzonder met betrekking tot de verplichting de bron uitdrukkelijk te vermelden bij het aanhalen van gegevens uit deze studie. ii ACKNOWLEDGMENTS There are several people who deserve my profound gratitude for their help and support while I was writing this dissertation. In the first place I would like to give thanks to all the respondents who filled in my questionnaire. That small act of kindness meant a great deal to me. The questionnaire required some time and attention to fill in and was distributed in a period when people were being overwhelmed on social media with all kinds of questionnaires for other theses. Therefore, I am very grateful to each and every one of them who helped me. Secondly, I would like to express my deep sense of gratitude to my supervisor, Prof. -
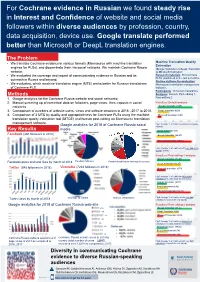
Methods Diversity in Communicating Cochrane Evidence to Diverse Russian-Speaking Audiences the Problem Key Results
For Cochrane evidence in Russian we found steady rise in Interest and Confidence of website and social media followers within diverse audiences by profession, country, data acquisition, device use. Google translate performed better than Microsoft or DeepL translation engines. The Problem Machine Translation Quality • We translate Cochrane evidence in various formats (Memsource with machine translation Estimation engines for PLSs), and disseminate them via social networks. We maintain Cochrane Russia (Google Translator vs DeepL Translator website; vs Microsoft Translator) • We evaluated the coverage and impact of communicating evidence in Russian and its Research materials: 90 Cochrane outreach in Russia and beyond; PLSs, published in the last 6 months. On-line platform for evaluation: • We evaluated, which machine translation engine (MTE) works better for Russian translations Memsource translation management of Cochrane PLS. software. Participants: 10 human translators Methods Analyses: Default, Post-editing 1, Post-editing 2 1. Google analytics for the Cochrane Russia website and social networks; 2. Manual summing up of numerical data on followers, page views, likes, reposts in social Results of Default analysis networks Google translator (0,09) DeepL translator (0,03) 3. Comparison of numbers of website users, views and website sessions in 2016 , 2017 to 2018. 4. Comparison of 3 MTE by quality and appropriateness for Cochrane PLSs using the machine Microsoft translator (0,01) translation quality estimation tool (MTQE) and human post-editing -

Full Text (PDF)
Journal of Liberal Arts and Humanities (JLAH) Issue: Vol. 2; No. 3; March 2021 pp. 26-46 ISSN 2690-070X (Print) 2690-0718 (Online) Website: www.jlahnet.com E-mail: [email protected] Doi: 10.48150/jlah.v2no3.2021.a3 MACHINE TRANSLATION AND POSTEDITING: AN OPINION POLL OF THE PROFESSIONAL TRANSLATION MARKET Enrique J. Vercher García Departamento de Filología Alemana y Filología Eslava Universidad Complutense de Madrid 91 394 7758 | 600 33 91 45 E-mail: [email protected] Abstract Over the years, significant advances have been made in the field of machine translation. This type of translation and the different programs and applications which exist seem to be well known and accepted in the academic world specialised in translation. However, the level of knowledge and acceptance of machine translation seems to be very different in the business world for clients who request translation services. In our paper we present the result of a study carried out on the translation market to ascertain the level of knowledge, acceptance and application by TSPs and end clients of different sectors. The opinion poll has been carried out through surveys adapted to the three target groups: translation agencies, professional translators and clients/users of professional translation. In the case of TSPs (agencies and translators), information has been gathered on their awareness and provision of machine translation and postediting (machine translation + proofreading), the percentage of assignments carried out through this service, as well as an evaluation of pure machine translation (without postediting) from their perspective and from the perspective of clients. In the case of clients/users of professional translation, information has been gathered on their knowledge and evaluation of machine translation (software translators). -

Online Translation Pricing Issues»
Online Translation Pricing Issues Claire Larsonneur Abstract Digital technologies such as translation platforms, crowdsourcing and neural machine translation disrupt the economics of translation. Benchmarking the pricing policies of nine global language services firms uncovers a shift Claire Larsonneur towards online business models that contribute to reshaping the traditional volume-based content-oriented 2018 University Paris 8 model of translation towards a range of linguistic services Claire.larsonneur@univ- focused on user experience. de e paris8.fr; ORCID: Keywords: online translation, economics, pricing, freemium, 0000-0002-5129-5844 language services, user experience, content. desembr Resum Les tecnologies digitals, com les plataformes de traducció, Publicació: | el crowdsourcing i la traducció automàtica neuronal han creat disrupció en l'economia de la traducció. L'anàlisi de les polítiques de preus de nou empreses de serveis lingüístics d'abast mundial revela un canvi cap a models en línia que contribueixen a reformar el model de traducció tradicional basat en el volum i orientat al contingut per oferir un catàleg de serveis lingüístics centrat en l'experiència d'usuari. 2018 de juliol de 20 Paraules clau: Traducció en línia; economia; tarifació; serveis de semipagament; serveis lingüístics, experiència d'usuari; contingut. | Acceptació: Acceptació: | Resumen Las tecnologías digitales como las plataformas de traducción, el crowdsourcing y la traducción automática neuronal disrumpen la economía de la traducción. El análisis de las políticas de precios de nueve empresas de servicios lingüísticos de envergadura mundial muestra un 2018 de març de 3 cambio hacia modelos de negocio en línea que contribuyen a reformar el modelo de traducción basado en el volumen y orientado al contenido para ofrecer un Rebuda: 2 Rebuda: catálogo de servicios lingüísticos centrado en la experiencia de usuario. -

Workshop Proceeding
The 14th Conference of The Association for Machine Translation in the Americas www.amtaweb.org WORKSHOP PROCEEDING Workshop on the Impact of Machine Translation Organizers: Sharon O'Brien (ADAPT, CTTS Dublin City University) Michel Simard (National Research Council Canada) ©2020 The Authors. These articles are licensed under a Creative Commons 3.0 license, no derivative works, attribution, CC-BY-ND. Contents 1 The Machine is Blind: Bottom-Up Feedback on the Impact of MT on Human Translation Performance Invited Speaker: Rhett Whitaker 18 Responsible ‘Gist’ MT Use in the Age of Neural MT Marianna J. Martindale 46 A Different, Ethical Machine Translation is Possible: English- Catalan Free/Open-Source Neural Machine Translation Vicent Briva-Iglesias 62 A Case Study of Natural Gender Phenomena in Translation: A Comparison of Google Translate, Bing Microsoft Translator and DeepL for English to Italian, French and Spanish Argentina Anna Rescigno, Johanna Monti, Andy Way and Eva Vanmassenhove 91 Empowering translators of marginalized languages through the use of language technology Alp Öktem, Manuel Locria, Eric Paquin and Grace Tang 123 Exploring Greater Impact: Business Translation Beyond Localization? Kirti Vashee 152 Predictive Translation Memory in the Wild - A Study of Interactive Machine Translation Use on Lilt Invited Speaker: Geza Kovacs Proceedings of the 14th Conference of the Association for Machine Translation in the Americas Page 1 October 6 - 9, 2020, Workshop on the Impact of Machine Translation The Machine is Blind Bottom-Up -

A Study on Automatic Machine Translation Tools: a Comparative Error Analysis Between Deepl and Yandex for Russian-Italian Medical Translation
Università degli Studi di Padova Dipartimento di Studi Linguistici e Letterari Corso di Laurea Magistrale in Lingue Moderne per la Comunicazione e la Cooperazione Internazionale Classe LM-38 Tesi di Laurea A Study on Automatic Machine Translation Tools: A Comparative Error Analysis Between DeepL and Yandex for Russian-Italian Medical Translation Relatore Laureanda Prof. Giorgio Maria Di Nunzio Giulia Cambedda Correlatrice n° matr.1205696 / LMLCC Prof.ssa Viviana Nosilia Anno Accademico 2020 / 2021 TABLE OF CONTENTS Introduction ............................................................................................................................ 1 1. THE EVOLUTION OF MACHINE TRANSLATION: FROM THE ORIGINS TO NEURAL MACHINE TRANSLATION ................................................................................ 3 1.1. The pioneers of Machine Translation ..................................................................... 3 1.2. A focus on Natural Language Processing ............................................................... 7 1.3. The ALPAC report ................................................................................................ 10 1.4. Rule-Based Machine Translation .......................................................................... 12 1.5. Example-Based Machine Translation ................................................................... 14 1.6. Statistical Machine Translation ............................................................................ 16 1.7. Neural Machine Translation ................................................................................ -

Intralinea Part 2: Corpora and Other Tools in Translation Teaching and Learning (2018) Christine Heiss & Marcello Soffritti
©inTRAlinea & Christine Heiss & Marcello Soffritti (2018). "DeepL Traduttore e didattica della traduzione dall’italiano in tedesco Alcune valutazioni preliminari", inTRAlinea Special Issue: Translation And Interpreting for Language Learners (TAIL). Stable URL: http://www.intralinea.org/archive/article/2294 inTRAlinea [ISSN 1827-000X] is the online translation journal of the Department of Interpreting and Translation (DIT) of the University of Bologna, Italy. This printout was generated directly from the online version of this article and can be freely distributed under Creative Commons License CC BY-NC-ND 4.0. DeepL Traduttore e didattica della traduzione dall’italiano in tedesco Alcune valutazioni preliminari By Christine Heiss & Marcello Soffritti (Università di Bologna, Italy) Abstract & Keywords English: What effects can the availability of a tool such as DeepL Translator have on the teaching of translation from Italian into German? This paper examines the most relevant factors to be taken into account, beyond simple standardised measurements. Starting from samples contained in two theses of Bachelor and Master's degree courses in translation, we explore quality levels of DeepL Translator’s raw output (with some reflections on BLEU scores) and successive improvements achievable with a simple kind of post-editing (without formal check- lists). Our findings confirm that this application provides quite promising results even without domain-related adaptation. Although some residual failures to be addressed in post-editing are insidious and challenging, DeepL Translator is likely to become an invaluable tool for more advanced and efficient practices in teaching and training. Accordingly, post-editing should become an essential training activity. Italian: Quali effetti può avere la disponibilità di uno strumento come DeepL Translator sull'insegnamento della traduzione dall'italiano al tedesco? Questo articolo esamina i fattori più rilevanti da prendere in considerazione, al di là delle semplici misure standardizzate.