Xi Yang, Ying
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
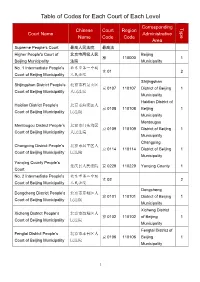
Table of Codes for Each Court of Each Level
Table of Codes for Each Court of Each Level Corresponding Type Chinese Court Region Court Name Administrative Name Code Code Area Supreme People’s Court 最高人民法院 最高法 Higher People's Court of 北京市高级人民 Beijing 京 110000 1 Beijing Municipality 法院 Municipality No. 1 Intermediate People's 北京市第一中级 京 01 2 Court of Beijing Municipality 人民法院 Shijingshan Shijingshan District People’s 北京市石景山区 京 0107 110107 District of Beijing 1 Court of Beijing Municipality 人民法院 Municipality Haidian District of Haidian District People’s 北京市海淀区人 京 0108 110108 Beijing 1 Court of Beijing Municipality 民法院 Municipality Mentougou Mentougou District People’s 北京市门头沟区 京 0109 110109 District of Beijing 1 Court of Beijing Municipality 人民法院 Municipality Changping Changping District People’s 北京市昌平区人 京 0114 110114 District of Beijing 1 Court of Beijing Municipality 民法院 Municipality Yanqing County People’s 延庆县人民法院 京 0229 110229 Yanqing County 1 Court No. 2 Intermediate People's 北京市第二中级 京 02 2 Court of Beijing Municipality 人民法院 Dongcheng Dongcheng District People’s 北京市东城区人 京 0101 110101 District of Beijing 1 Court of Beijing Municipality 民法院 Municipality Xicheng District Xicheng District People’s 北京市西城区人 京 0102 110102 of Beijing 1 Court of Beijing Municipality 民法院 Municipality Fengtai District of Fengtai District People’s 北京市丰台区人 京 0106 110106 Beijing 1 Court of Beijing Municipality 民法院 Municipality 1 Fangshan District Fangshan District People’s 北京市房山区人 京 0111 110111 of Beijing 1 Court of Beijing Municipality 民法院 Municipality Daxing District of Daxing District People’s 北京市大兴区人 京 0115 -

As Economy Booms, Hebei Govt Notes Greater Need for Civility
14 businessinternational THURSDAY, MARCH 18, 2010 CHINA DAILY hebeispecial Capital city Shijiazhuang all set and ready to grow By LIU XIANG the world’s oldest existing ies” in 2011, a ranking com- AND JIA JINGQI stone arch bridge, built in the piled by the Chinese Acad- year 595 in the Sui Dynasty emy of Social Sciences. Shijiazhuang, the capital (581-618). With profound culture of North China’s Hebei prov- It is also home to the and a wide range of folk art, ince, is on its way to national Xibaipo memorial, a national the city’s cultural industry prominence thanks to its rap- base for patriotic educa- has strong momentum, con- id development in economy, tion. Xibaipo was the site tributing 22.4 percent of the tourism and culture. of the Communist Party of output value of the province’s The provincial capital has China’s last headquarters in culture industry. A public lec- one of the country’s biggest a rural area before it moved ture, the “Yanzhao Lecture”, industrial pharmaceutical to Beijing and liberated the has been held 1,200 times to bases and one of the most entire country. give residents knowledge in important textile centers. The Shijiazhuang also joined various fields. It is called the PHOTOS PROVIDED TO CHINA DAILY industrial clusters for biologi- the ranks of the top 100 cities “university without walls” by Built in the Ming Dynasty (1368-1644), Laolongtou — or Old Dragon’s Head — at Shanhaiguan Pass in Qinhuangdao is the eastern cal industries, semiconductor in the nation for comprehen- locals. -

Minimum Wage Standards in China August 11, 2020
Minimum Wage Standards in China August 11, 2020 Contents Heilongjiang ................................................................................................................................................. 3 Jilin ............................................................................................................................................................... 3 Liaoning ........................................................................................................................................................ 4 Inner Mongolia Autonomous Region ........................................................................................................... 7 Beijing......................................................................................................................................................... 10 Hebei ........................................................................................................................................................... 11 Henan .......................................................................................................................................................... 13 Shandong .................................................................................................................................................... 14 Shanxi ......................................................................................................................................................... 16 Shaanxi ...................................................................................................................................................... -

Religious Persecution Persists
CHINA RELIGIOUS PERSECUTION PERSISTS December 1995 Vol. 7, No. 16 SUMMARY ...............................................................................................................................................................3 RECOMMENDATIONS............................................................................................................................................5 To the Government of the People=s Republic of China..................................................................................5 To the International Community....................................................................................................................5 BACKGROUND........................................................................................................................................................6 THE "LEGAL" TACK: CENTRAL GOVERNMENT REGULATIONS .................................................................7 Regulations Aimed at Foreigners.................................................................................................................10 THE EXTRA-LEGAL TACK: LOCAL RESPONSES ...........................................................................................11 Silencing a Charismatic Seminarian ............................................................................................................11 Curtailing Evangelical Networks .................................................................................................................13 Curtailing Catholic Networks ......................................................................................................................16 -
This Article Appeared in a Journal Published by Elsevier. the Attached Copy Is Furnished to the Author for Internal Non-Commerci
This article appeared in a journal published by Elsevier. The attached copy is furnished to the author for internal non-commercial research and education use, including for instruction at the authors institution and sharing with colleagues. Other uses, including reproduction and distribution, or selling or licensing copies, or posting to personal, institutional or third party websites are prohibited. In most cases authors are permitted to post their version of the article (e.g. in Word or Tex form) to their personal website or institutional repository. Authors requiring further information regarding Elsevier’s archiving and manuscript policies are encouraged to visit: http://www.elsevier.com/authorsrights Author's personal copy Journal of Asian Earth Sciences 72 (2013) 178–189 Contents lists available at SciVerse ScienceDirect Journal of Asian Earth Sciences journal homepage: www.elsevier.com/locate/jseaes Delineation of the ca. 2.7 Ga TTG gneisses in the Zanhuang Complex, North China Craton and its geological implications ⇑ Chonghui Yang a, , Lilin Du a, Liudong Ren a, Huixia Song a, Yusheng Wan a,b, Hangqiang Xie a,b, Yuansheng Geng a a Institute of Geology, Chinese Academy of Geological Sciences, Beijing 100037, China b Beijing SHRIMP Center, Beijing 100037, China article info abstract Article history: Through detailed studies we have delineated a suite of banded TTG gneisses from the Zanhuang Complex. Available online 16 October 2012 The protolith of the gneisses, predominantly tonalite, has undergone intensive metamorphism, deforma- tion and anatexis and in a banded structure is intimately associated with melanocratic dioritic gneiss and Keywords: leucocratic trondhjemitic veins. SHRIMP Zircon U–Pb data show that the tonalite was formed ca. -
Partnership in China's Soy Sauce Fortification
Business Innovation to Combat Malnutrition Case Study Series Two Wheels Turning: Public Disclosure Authorized Partnership in China’s Soy Sauce Fortification Program Case B This case was coordinated NOVEMBER 2003 WAS supposed to be a groundwork, including certification of and free by Michael Jarvis (World celebratory period for Chen Junshi and his technical assistance to industry participants, it Bank Institute) and Bérangère China CDC colleagues working to ameliorate was disappointing for CDC staff to hear the Magarinos (Global Alliance for Improved Nutrition). the problems of iron deficiency and iron defi- objections voiced by soy sauce makers, just as We would like to express ciency anemia (IDA). After two years of testing funds had materialized to publicize the pro- our gratitude to the staff of and preparation, China CDC had received gram in seven provinces. Public Disclosure Authorized Shijiazhuang Zhenji Brew funding from Geneva-based Global Alliance Group Company, Ltd, the Center for Disease Control for Improved Nutrition (GAIN) to launch its Four years later, not only had Zhenji been a and Prevention (CDC) in soy sauce iron fortification program in seven lead participant in the soy fortification project, China and their partner provinces and the municipality of Beijing, and but the program had made a tangible impact organizations for their had already held several provincial launch on the incidence of IDA among Hebei’s 67 mil- invaluable contributions to the case’s development. conferences to kick off the campaign. But in a lion inhabitants. While iron fortified soy sauce recent conversation, Zhang Lin, CEO of Shijiaz- was unavailable to Hebei consumers in 2001, This case was commissioned huang Zhenji Brew Group Company (Zhenji), by mid 2007, fortified soy sauce was displayed by the World Bank Institute had relayed the resistance of his own managers if not sold in 90% of Hebei supermarkets. -

Liver Cancer Mortality Trends During the Last 30 Years in Hebei
DOI:http://dx.doi.org/10.7314/APJCP.2012.13.5.1895 Liver Cancer Mortality in Hebei: Comparison of the 1970’s, 1980’s, 1990’s and 2004-2005 RESEARCH COMMUNICATION Liver Cancer Mortality Trends during the Last 30 Years in Hebei province: Comparison Results from Provincial Death Surveys Conducted in the 1970’s, 1980’s, 1990’s and 2004-2005 Hong Xu1, Yu-Tong He2*, Jun-Qing Zhu3 Abstract Background and Aims: Liver cancer is a major health problem in low-resource countries. Approximately 55% of all liver cancer occurs in China. Hebei Province is one of the important covering nearly 6% of the population of China. The aim of this paper was to explore liver cancer mortality trends during past 30 years, and provide basic information on prevention strategies. Methods: Hebei was covered covered all the three national surveys during 1973-1975, 1990-1992, and 2004-2005 and one provincial survey during 1984-1986. Subjects included all cases dying from liver cancer in Hebei Province. Liver cancer mortality trend and geographic differences across cities and counties were analyzed. Results: There were 82,878 deaths in Hebei Province during 2004-2005 with an average mortality rate was 600.9/10,000, and an age-adjusted rate of 552.3/10,000. Those dying of cancer were 18,424 cases, accounting for 22.2% of all deaths, second only to cerebrovascular disease as a cause of death. Cancer mortality was 133.6/100,000 (age-adjusted rate was 119.2/100,000). Liver cancer ranked fourth in this survey with a mortality rate of 21.0/100,000, 28.4/100,000 in males and 13.35/10,000 in females, accounting for 15.7%, 17.1% and 13.4% of the total number of cancer deaths and in males and females, respectively. -

Minimum Wage Standards in China June 28, 2018
Minimum Wage Standards in China June 28, 2018 Contents Heilongjiang .................................................................................................................................................. 3 Jilin ................................................................................................................................................................ 3 Liaoning ........................................................................................................................................................ 4 Inner Mongolia Autonomous Region ........................................................................................................... 7 Beijing ......................................................................................................................................................... 10 Hebei ........................................................................................................................................................... 11 Henan .......................................................................................................................................................... 13 Shandong .................................................................................................................................................... 14 Shanxi ......................................................................................................................................................... 16 Shaanxi ....................................................................................................................................................... -

A12 List of China's City Gas Franchising Zones
附录 A12: 中国城市管道燃气特许经营区收录名单 Appendix A03: List of China's City Gas Franchising Zones • 1 Appendix A12: List of China's City Gas Franchising Zones 附录 A12:中国城市管道燃气特许经营区收录名单 No. of Projects / 项目数:3,404 Statistics Update Date / 统计截止时间:2017.9 Source / 来源:http://www.chinagasmap.com Natural gas project investment in China was relatively simple and easy just 10 CNG)、控股投资者(上级管理机构)和一线运营单位的当前主官经理、公司企业 years ago because of the brand new downstream market. It differs a lot since 所有制类型和联系方式。 then: LNG plants enjoyed seller market before, while a LNG plant investor today will find himself soon fighting with over 300 LNG plants for buyers; West East 这套名录的作用 Gas Pipeline 1 enjoyed virgin markets alongside its paving route in 2002, while today's Xin-Zhe-Yue Pipeline Network investor has to plan its route within territory 1. 在基础数据收集验证层面为您的专业信息团队节省 2,500 小时之工作量; of a couple of competing pipelines; In the past, city gas investors could choose to 2. 使城市燃气项目投资者了解当前特许区域最新分布、其他燃气公司的控股势力范 sign golden areas with best sales potential and easy access to PNG supply, while 围;结合中国 LNG 项目名录和中国 CNG 项目名录时,投资者更易于选择新项 today's investors have to turn their sights to areas where sales potential is limited 目区域或谋划收购对象; ...Obviously, today's investors have to consider more to ensure right decision 3. 使 LNG 和 LNG 生产商掌握采购商的最新布局,提前为充分市场竞争做准备; making in a much complicated gas market. China Natural Gas Map's associated 4. 便于 L/CNG 加气站投资者了解市场进入壁垒,并在此基础上谨慎规划选址; project directories provide readers a fundamental analysis tool to make their 5. 结合中国天然气管道名录时,长输管线项目的投资者可根据竞争性供气管道当前 decisions. With a completed idea about venders, buyers and competitive projects, 格局和下游用户的分布,对管道路线和分输口建立初步规划框架。 analyst would be able to shape a better market model when planning a new investment or marketing program. -

Annual Development Report on China's Trademark Strategy 2013
Annual Development Report on China's Trademark Strategy 2013 TRADEMARK OFFICE/TRADEMARK REVIEW AND ADJUDICATION BOARD OF STATE ADMINISTRATION FOR INDUSTRY AND COMMERCE PEOPLE’S REPUBLIC OF CHINA China Industry & Commerce Press Preface Preface 2013 was a crucial year for comprehensively implementing the conclusions of the 18th CPC National Congress and the second & third plenary session of the 18th CPC Central Committee. Facing the new situation and task of thoroughly reforming and duty transformation, as well as the opportunities and challenges brought by the revised Trademark Law, Trademark staff in AICs at all levels followed the arrangement of SAIC and got new achievements by carrying out trademark strategy and taking innovation on trademark practice, theory and mechanism. ——Trademark examination and review achieved great progress. In 2013, trademark applications increased to 1.8815 million, with a year-on-year growth of 14.15%, reaching a new record in the history and keeping the highest a mount of the world for consecutive 12 years. Under the pressure of trademark examination, Trademark Office and TRAB of SAIC faced the difficuties positively, and made great efforts on soloving problems. Trademark Office and TRAB of SAIC optimized the examination procedure, properly allocated examiners, implemented the mechanism of performance incentive, and carried out the “double-points” management. As a result, the Office examined 1.4246 million trademark applications, 16.09% more than last year. The examination period was maintained within 10 months, and opposition period was shortened to 12 months, which laid a firm foundation for performing the statutory time limit. —— Implementing trademark strategy with a shift to effective use and protection of trademark by law. -

The Latest List of 592 Poor Counties in China
The latest list of 592 poor counties in China March 19 (Chinanews.com) the poverty alleviation and Development Leading Group Office of the State Council today released the list of key counties for national poverty alleviation and development on its official website. The list includes 592 poor counties in China, including 217 counties in central provinces and 375 counties in western provinces. List of key counties for national poverty alleviation and development National 592 Middle 217 West 375 Eight ethnic provinces 232 Hebei 39: Xingtang County, Lingshou County, Zanhuang County, Pingshan County, Qinglong County, Daming County, Wei County, Lincheng County, Julu County, Xinhe County, Guangzong County, Pingxiang County, Wei County, Fuping County, Tang County, Laiyuan County, Shunping County, Zhangbei County, Kangbao County, Guyuan County, Shangyi County, Wei County, Yangyuan County, Huai'an County, Wanquan County, Chicheng County, Chongli County, Pingquan County, Luanping county Longhua County, Fengning County, Weichang County, Haixing County, Yanshan County, Nanpi County, Wuyi County, Wuqiang County, Raoyang County, Fucheng County, (zhaojiapeng District, Zhuolu county) Shanxi 35: Loufan County, Yanggao County, Tianzhen County, Guangling County, Lingqiu County, Hunyuan County, Pingshun County, Huguan County, Wuxiang County, Youyu County, Zuoquan County, Heshun County, Pinglu County, Wutai County, Dai County, Fanshi County, Ningwu County, jingle County, Shenchi County, Wuzhai County, Kelan County, Hequ County, Baode County, Pianguan County, -

Supplementary Material Continued
1 Supplementary Material 2 Table S1. Counties in the Jingjinji region. No City County No City County 1 Beijing Dongcheng District 26 Tianjin Beichen District 2 Beijing Xicheng District 27 Tianjin Wuqing District 3 Beijing Chaoyang District 28 Tianjin Baodi District 4 Beijing Fengtai District 29 Tianjin Binhai New District 5 Beijing Shijingshan District 30 Tianjin Ninghe District 6 Beijing Haidian District 31 Tianjin Jinghai District 7 Beijing Mentougou District 32 Tianjin Jizhou District 8 Beijing Fangshan District 33 Shijiazhuang Chang'an District 9 Beijing Tongzhou District 34 Shijiazhuang Qiaoxi District 10 Beijing Shunyi District 35 Shijiazhuang Xinhua District 11 Beijing Changping District 36 Shijiazhuang Jingxing Mining Area 12 Beijing Daxing District 37 Shijiazhuang Yuhua District 13 Beijing Huairou District 38 Shijiazhuang Gaocheng District 14 Beijing Pinggu District 39 Shijiazhuang Luquan District 15 Beijing Miyun District 40 Shijiazhuang Luancheng District 16 Beijing Yanqing District 41 Shijiazhuang Jingxing County 17 Tianjin Heping District 42 Shijiazhuang Zhengding County 18 Tianjin Hedong District 43 Shijiazhuang Xingtang County 19 Tianjin Hexi District 44 Shijiazhuang Lingshou County 20 Tianjin Nankai District 45 Shijiazhuang Gaoyi County 21 Tianjin Hebei District 46 Shijiazhuang Shenze County 22 Tianjin Hongqiao District 47 Shijiazhuang Zanhuang County 23 Tianjin Dongli District 48 Shijiazhuang Wuji County 24 Tianjin Xiqing District 49 Shijiazhuang Pingshan County 25 Tianjin Jinnan District 50 Shijiazhuang Yuanshi County