Guidance for Data Quality Assessment
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Data Quality: Letting Data Speak for Itself Within the Enterprise Data Strategy
Data Quality: Letting Data Speak for Itself within the Enterprise Data Strategy Collaboration & Transformation (C&T) Shared Interest Group (SIG) Financial Management Committee DATA Act – Transparency in Federal Financials Project Date Released: September 2015 SYNOPSIS Data quality and information management across the enterprise is challenging. Today’s information systems consist of multiple, interdependent platforms that are interfaced across the enterprise. Each of these systems and the business processes they support often use and define the same piece of data differently. How the information is used across the enterprise becomes a critical part of the equation when managing data quality. Letting the data speak for itself is the process of analyzing how the data and information is used across the enterprise, providing details on how the data is defined, what systems and processes are responsible for authoring and maintaining the data, and how the information is used to support the agency, and what needs to be done to support data quality and governance. This information also plays a critical role in the agency’s capacity to meet the requirements of the DATA Act. American Council for Technology-Industry Advisory Council (ACT-IAC) 3040 Williams Drive, Suite 500, Fairfax, VA 22031 www.actiac.org ● (p) (703) 208.4800 (f) ● (703) 208.4805 Advancing Government through Collaboration, Education and Action Data Quality: Letting the Data Speak for Itself within the Enterprise Data Strategy American Council for Technology-Industry Advisory Council (ACT-IAC) The American Council for Technology (ACT) is a non-profit educational organization established in 1979 to improve government through the efficient and innovative application of information technology. -
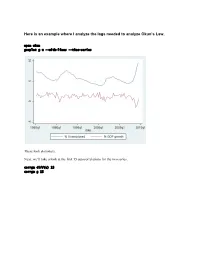
Here Is an Example Where I Analyze the Lags Needed to Analyze Okun's
Here is an example where I analyze the lags needed to analyze Okun’s Law. open okun gnuplot g u --with-lines --time-series These look stationary. Next, we’ll take a look at the first 15 autocorrelations for the two series. corrgm diff(u) 15 corrgm g 15 These are autocorrelated and so are these. I would expect that a simple regression will not be sufficient to model this relationship. Let’s try anyway. Run a simple regression and look at the residuals ols diff(u) const g series ehat=$uhat gnuplot ehat --with-lines --time-series These look positively autocorrelated to me. Notice how the residuals fall below zero for a while, then rise above for a while, and repeat this pattern. Take a look at the correlogram. The first autocorrelation is significant. More lags of D.u or g will probably fix this. LM test of residuals smpl 1985.2 2009.3 ols diff(u) const g modeltab add modtest 1 --autocorr --quiet modtest 2 --autocorr --quiet modtest 3 --autocorr --quiet modtest 4 --autocorr --quiet Breusch-Godfrey test for first-order autocorrelation Alternative statistic: TR^2 = 6.576105, with p-value = P(Chi-square(1) > 6.5761) = 0.0103 Breusch-Godfrey test for autocorrelation up to order 2 Alternative statistic: TR^2 = 7.922218, with p-value = P(Chi-square(2) > 7.92222) = 0.019 Breusch-Godfrey test for autocorrelation up to order 3 Alternative statistic: TR^2 = 11.200978, with p-value = P(Chi-square(3) > 11.201) = 0.0107 Breusch-Godfrey test for autocorrelation up to order 4 Alternative statistic: TR^2 = 11.220956, with p-value = P(Chi-square(4) > 11.221) = 0.0242 Yep, that’s not too good. -

12.6 Sign Test (Web)
12.4 Sign test (Web) Click on 'Bookmarks' in the Left-Hand menu and then click on the required section. 12.6 Sign test (Web) 12.6.1 Introduction The Sign Test is a one sample test that compares the median of a data set with a specific target value. The Sign Test performs the same function as the One Sample Wilcoxon Test, but it does not rank data values. Without the information provided by ranking, the Sign Test is less powerful (9.4.5) than the Wilcoxon Test. However, the Sign Test is useful for problems involving 'binomial' data, where observed data values are either above or below a target value. 12.6.2 Sign Test The Sign Test aims to test whether the observed data sample has been drawn from a population that has a median value, m, that is significantly different from (or greater/less than) a specific value, mO. The hypotheses are the same as in 12.1.2. We will illustrate the use of the Sign Test in Example 12.14 by using the same data as in Example 12.2. Example 12.14 The generation times, t, (5.2.4) of ten cultures of the same micro-organisms were recorded. Time, t (hr) 6.3 4.8 7.2 5.0 6.3 4.2 8.9 4.4 5.6 9.3 The microbiologist wishes to test whether the generation time for this micro- organism is significantly greater than a specific value of 5.0 hours. See following text for calculations: In performing the Sign Test, each data value, ti, is compared with the target value, mO, using the following conditions: ti < mO replace the data value with '-' ti = mO exclude the data value ti > mO replace the data value with '+' giving the results in Table 12.14 Difference + - + ----- + - + - + + Table 12.14 Signs of Differences in Example 12.14 12.4.p1 12.4 Sign test (Web) We now calculate the values of r + = number of '+' values: r + = 6 in Example 12.14 n = total number of data values not excluded: n = 9 in Example 12.14 Decision making in this test is based on the probability of observing particular values of r + for a given value of n. -

SUGI 28: the Value of ETL and Data Quality
SUGI 28 Data Warehousing and Enterprise Solutions Paper 161-28 The Value of ETL and Data Quality Tho Nguyen, SAS Institute Inc. Cary, North Carolina ABSTRACT Information collection is increasing more than tenfold each year, with the Internet a major driver in this trend. As more and more The adage “garbage in, garbage out” becomes an unfortunate data is collected, the reality of a multi-channel world that includes reality when data quality is not addressed. This is the information e-business, direct sales, call centers, and existing systems sets age and we base our decisions on insights gained from data. If in. Bad data (i.e. inconsistent, incomplete, duplicate, or inaccurate data is entered without subsequent data quality redundant data) is affecting companies at an alarming rate and checks, only inaccurate information will prevail. Bad data can the dilemma is to ensure that how to optimize the use of affect businesses in varying degrees, ranging from simple corporate data within every application, system and database misrepresentation of information to multimillion-dollar mistakes. throughout the enterprise. In fact, numerous research and studies have concluded that data quality is the culprit cause of many failed data warehousing or Customer Relationship Management (CRM) projects. With the Take into consideration the director of data warehousing at a large price tags on these high-profile initiatives and the major electronic component manufacturer who realized there was importance of accurate information to business intelligence, a problem linking information between an inventory database and improving data quality has become a top management priority. a customer order database. -

A Machine Learning Approach to Outlier Detection and Imputation of Missing Data1
Ninth IFC Conference on “Are post-crisis statistical initiatives completed?” Basel, 30-31 August 2018 A machine learning approach to outlier detection and imputation of missing data1 Nicola Benatti, European Central Bank 1 This paper was prepared for the meeting. The views expressed are those of the authors and do not necessarily reflect the views of the BIS, the IFC or the central banks and other institutions represented at the meeting. A machine learning approach to outlier detection and imputation of missing data Nicola Benatti In the era of ready-to-go analysis of high-dimensional datasets, data quality is essential for economists to guarantee robust results. Traditional techniques for outlier detection tend to exclude the tails of distributions and ignore the data generation processes of specific datasets. At the same time, multiple imputation of missing values is traditionally an iterative process based on linear estimations, implying the use of simplified data generation models. In this paper I propose the use of common machine learning algorithms (i.e. boosted trees, cross validation and cluster analysis) to determine the data generation models of a firm-level dataset in order to detect outliers and impute missing values. Keywords: machine learning, outlier detection, imputation, firm data JEL classification: C81, C55, C53, D22 Contents A machine learning approach to outlier detection and imputation of missing data ... 1 Introduction .............................................................................................................................................. -

Alternative Tests for Time Series Dependence Based on Autocorrelation Coefficients
Alternative Tests for Time Series Dependence Based on Autocorrelation Coefficients Richard M. Levich and Rosario C. Rizzo * Current Draft: December 1998 Abstract: When autocorrelation is small, existing statistical techniques may not be powerful enough to reject the hypothesis that a series is free of autocorrelation. We propose two new and simple statistical tests (RHO and PHI) based on the unweighted sum of autocorrelation and partial autocorrelation coefficients. We analyze a set of simulated data to show the higher power of RHO and PHI in comparison to conventional tests for autocorrelation, especially in the presence of small but persistent autocorrelation. We show an application of our tests to data on currency futures to demonstrate their practical use. Finally, we indicate how our methodology could be used for a new class of time series models (the Generalized Autoregressive, or GAR models) that take into account the presence of small but persistent autocorrelation. _______________________________________________________________ An earlier version of this paper was presented at the Symposium on Global Integration and Competition, sponsored by the Center for Japan-U.S. Business and Economic Studies, Stern School of Business, New York University, March 27-28, 1997. We thank Paul Samuelson and the other participants at that conference for useful comments. * Stern School of Business, New York University and Research Department, Bank of Italy, respectively. 1 1. Introduction Economic time series are often characterized by positive -

Statistical Characterization of Tissue Images for Detec- Tion and Classification of Cervical Precancers
Statistical characterization of tissue images for detec- tion and classification of cervical precancers Jaidip Jagtap1, Nishigandha Patil2, Chayanika Kala3, Kiran Pandey3, Asha Agarwal3 and Asima Pradhan1, 2* 1Department of Physics, IIT Kanpur, U.P 208016 2Centre for Laser Technology, IIT Kanpur, U.P 208016 3G.S.V.M. Medical College, Kanpur, U.P. 208016 * Corresponding author: [email protected], Phone: +91 512 259 7971, Fax: +91-512-259 0914. Abstract Microscopic images from the biopsy samples of cervical cancer, the current “gold standard” for histopathology analysis, are found to be segregated into differing classes in their correlation properties. Correlation domains clearly indicate increasing cellular clustering in different grades of pre-cancer as compared to their normal counterparts. This trend manifests in the probabilities of pixel value distribution of the corresponding tissue images. Gradual changes in epithelium cell density are reflected well through the physically realizable extinction coefficients. Robust statistical parameters in the form of moments, characterizing these distributions are shown to unambiguously distinguish tissue types. These parameters can effectively improve the diagnosis and classify quantitatively normal and the precancerous tissue sections with a very high degree of sensitivity and specificity. Key words: Cervical cancer; dysplasia, skewness; kurtosis; entropy, extinction coefficient,. 1. Introduction Cancer is a leading cause of death worldwide, with cervical cancer being the fifth most common cancer in women [1-2]. It originates as a few abnormal cells in the initial stage and then spreads rapidly. Treatment of cancer is often ineffective in the later stages, which makes early detection the key to survival. Pre-cancerous cells can sometimes take 10-15 years to develop into cancer and regular tests such as pap-smear are recommended. -

Outlier Detection for Improved Data Quality and Diversity in Dialog Systems
Outlier Detection for Improved Data Quality and Diversity in Dialog Systems Stefan Larson Anish Mahendran Andrew Lee Jonathan K. Kummerfeld Parker Hill Michael A. Laurenzano Johann Hauswald Lingjia Tang Jason Mars Clinc, Inc. Ann Arbor, MI, USA fstefan,anish,andrew,[email protected] fparkerhh,mike,johann,lingjia,[email protected] Abstract amples in a dataset that are atypical, provides a means of approaching the questions of correctness In a corpus of data, outliers are either errors: and diversity, but has mainly been studied at the mistakes in the data that are counterproduc- document level (Guthrie et al., 2008; Zhuang et al., tive, or are unique: informative samples that improve model robustness. Identifying out- 2017), whereas texts in dialog systems are often no liers can lead to better datasets by (1) remov- more than a few sentences in length. ing noise in datasets and (2) guiding collection We propose a novel approach that uses sen- of additional data to fill gaps. However, the tence embeddings to detect outliers in a corpus of problem of detecting both outlier types has re- short texts. We rank samples based on their dis- ceived relatively little attention in NLP, partic- tance from the mean embedding of the corpus and ularly for dialog systems. We introduce a sim- consider samples farthest from the mean outliers. ple and effective technique for detecting both erroneous and unique samples in a corpus of Outliers come in two varieties: (1) errors, sen- short texts using neural sentence embeddings tences that have been mislabeled whose inclusion combined with distance-based outlier detec- in the dataset would be detrimental to model per- tion. -

3 Autocorrelation
3 Autocorrelation Autocorrelation refers to the correlation of a time series with its own past and future values. Autocorrelation is also sometimes called “lagged correlation” or “serial correlation”, which refers to the correlation between members of a series of numbers arranged in time. Positive autocorrelation might be considered a specific form of “persistence”, a tendency for a system to remain in the same state from one observation to the next. For example, the likelihood of tomorrow being rainy is greater if today is rainy than if today is dry. Geophysical time series are frequently autocorrelated because of inertia or carryover processes in the physical system. For example, the slowly evolving and moving low pressure systems in the atmosphere might impart persistence to daily rainfall. Or the slow drainage of groundwater reserves might impart correlation to successive annual flows of a river. Or stored photosynthates might impart correlation to successive annual values of tree-ring indices. Autocorrelation complicates the application of statistical tests by reducing the effective sample size. Autocorrelation can also complicate the identification of significant covariance or correlation between time series (e.g., precipitation with a tree-ring series). Autocorrelation implies that a time series is predictable, probabilistically, as future values are correlated with current and past values. Three tools for assessing the autocorrelation of a time series are (1) the time series plot, (2) the lagged scatterplot, and (3) the autocorrelation function. 3.1 Time series plot Positively autocorrelated series are sometimes referred to as persistent because positive departures from the mean tend to be followed by positive depatures from the mean, and negative departures from the mean tend to be followed by negative departures (Figure 3.1). -

Case Study Applications of Statistics in Institutional Research
/-- ; / \ \ CASE STUDY APPLICATIONS OF STATISTICS IN INSTITUTIONAL RESEARCH By MARY ANN COUGHLIN and MARIAN PAGAN( Case Study Applications of Statistics in Institutional Research by Mary Ann Coughlin and Marian Pagano Number Ten Resources in Institutional Research A JOINTPUBLICA TION OF THE ASSOCIATION FOR INSTITUTIONAL RESEARCH AND THE NORTHEASTASSO CIATION FOR INSTITUTIONAL REASEARCH © 1997 Association for Institutional Research 114 Stone Building Florida State University Ta llahassee, Florida 32306-3038 All Rights Reserved No portion of this book may be reproduced by any process, stored in a retrieval system, or transmitted in any form, or by any means, without the express written permission of the publisher. Printed in the United States To order additional copies, contact: AIR 114 Stone Building Florida State University Tallahassee FL 32306-3038 Tel: 904/644-4470 Fax: 904/644-8824 E-Mail: [email protected] Home Page: www.fsu.edul-airlhome.htm ISBN 1-882393-06-6 Table of Contents Acknowledgments •••••••••••••••••.•••••••••.....••••••••••••••••.••. Introduction .•••••••••••..•.•••••...•••••••.....••••.•••...••••••••• 1 Chapter 1: Basic Concepts ..•••••••...••••••...••••••••..••••••....... 3 Characteristics of Variables and Levels of Measurement ...................3 Descriptive Statistics ...............................................8 Probability, Sampling Theory and the Normal Distribution ................ 16 Chapter 2: Comparing Group Means: Are There Real Differences Between Av erage Faculty Salaries Across Departments? •...••••••••.••.•••••• -

The Instat Guide to Choosing and Interpreting Statistical Tests
Statistics for biologists The InStat Guide to Choosing and Interpreting Statistical Tests GraphPad InStat Version 3 for Macintosh By GraphPad Software, Inc. © 1990-2001,,, GraphPad Soffftttware,,, IIInc... Allllll riiighttts reserved... Program design, manual and help Dr. Harvey J. Motulsky screens: Paige Searle Programming: Mike Platt John Pilkington Harvey Motulsky Maciiintttosh conversiiion by Soffftttware MacKiiiev... www...mackiiiev...com Project Manager: Dennis Radushev Programmers: Alexander Bezkorovainy Dmitry Farina Quality Assurance: Lena Filimonihina Help and Manual: Pavel Noga Andrew Yeremenko InStat and GraphPad Prism are registered trademarks of GraphPad Software, Inc. All Rights Reserved. Manufactured in the United States of America. Except as permitted under the United States copyright law of 1976, no part of this publication may be reproduced or distributed in any form or by any means without the prior written permission of the publisher. Use of the software is subject to the restrictions contained in the accompanying software license agreement. How ttto reach GraphPad: Phone: (US) 858-457-3909 Fax: (US) 858-457-8141 Email: [email protected] or [email protected] Web: www.graphpad.com Mail: GraphPad Software, Inc. 5755 Oberlin Drive #110 San Diego, CA 92121 USA The entire text of this manual is available on-line at www.graphpad.com Contents Welcome to InStat........................................................................................7 The InStat approach ---------------------------------------------------------------7 -

Statistical Tool for Soil Biology : 11. Autocorrelogram and Mantel Test
‘i Pl w f ’* Em J. 1996, (4), i Soil BioZ., 32 195-203 Statistical tool for soil biology. XI. Autocorrelogram and Mantel test Jean-Pierre Rossi Laboratoire d Ecologie des Sols Trofiicaux, ORSTOM/Université Paris 6, 32, uv. Varagnat, 93143 Bondy Cedex, France. E-mail: rossij@[email protected]. fr. Received October 23, 1996; accepted March 24, 1997. Abstract Autocorrelation analysis by Moran’s I and the Geary’s c coefficients is described and illustrated by the analysis of the spatial pattern of the tropical earthworm Clzuniodrilus ziehe (Eudrilidae). Simple and partial Mantel tests are presented and illustrated through the analysis various data sets. The interest of these methods for soil ecology is discussed. Keywords: Autocorrelation, correlogram, Mantel test, geostatistics, spatial distribution, earthworm, plant-parasitic nematode. L’outil statistique en biologie du sol. X.?. Autocorrélogramme et test de Mantel. Résumé L’analyse de l’autocorrélation par les indices I de Moran et c de Geary est décrite et illustrée à travers l’analyse de la distribution spatiale du ver de terre tropical Chuniodi-ibs zielae (Eudrilidae). Les tests simple et partiel de Mantel sont présentés et illustrés à travers l’analyse de jeux de données divers. L’intérêt de ces méthodes en écologie du sol est discuté. Mots-clés : Autocorrélation, corrélogramme, test de Mantel, géostatistiques, distribution spatiale, vers de terre, nématodes phytoparasites. INTRODUCTION the variance that appear to be related by a simple power law. The obvious interest of that method is Spatial heterogeneity is an inherent feature of that samples from various sites can be included in soil faunal communities with significant functional the analysis.