MINIX 3 C Compiler Performance
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Red Hat Enterprise Linux 6 Developer Guide
Red Hat Enterprise Linux 6 Developer Guide An introduction to application development tools in Red Hat Enterprise Linux 6 Dave Brolley William Cohen Roland Grunberg Aldy Hernandez Karsten Hopp Jakub Jelinek Developer Guide Jeff Johnston Benjamin Kosnik Aleksander Kurtakov Chris Moller Phil Muldoon Andrew Overholt Charley Wang Kent Sebastian Red Hat Enterprise Linux 6 Developer Guide An introduction to application development tools in Red Hat Enterprise Linux 6 Edition 0 Author Dave Brolley [email protected] Author William Cohen [email protected] Author Roland Grunberg [email protected] Author Aldy Hernandez [email protected] Author Karsten Hopp [email protected] Author Jakub Jelinek [email protected] Author Jeff Johnston [email protected] Author Benjamin Kosnik [email protected] Author Aleksander Kurtakov [email protected] Author Chris Moller [email protected] Author Phil Muldoon [email protected] Author Andrew Overholt [email protected] Author Charley Wang [email protected] Author Kent Sebastian [email protected] Editor Don Domingo [email protected] Editor Jacquelynn East [email protected] Copyright © 2010 Red Hat, Inc. and others. The text of and illustrations in this document are licensed by Red Hat under a Creative Commons Attribution–Share Alike 3.0 Unported license ("CC-BY-SA"). An explanation of CC-BY-SA is available at http://creativecommons.org/licenses/by-sa/3.0/. In accordance with CC-BY-SA, if you distribute this document or an adaptation of it, you must provide the URL for the original version. Red Hat, as the licensor of this document, waives the right to enforce, and agrees not to assert, Section 4d of CC-BY-SA to the fullest extent permitted by applicable law. -

Ethereal Developer's Guide Draft 0.0.2 (15684) for Ethereal 0.10.11
Ethereal Developer's Guide Draft 0.0.2 (15684) for Ethereal 0.10.11 Ulf Lamping, Ethereal Developer's Guide: Draft 0.0.2 (15684) for Ethere- al 0.10.11 by Ulf Lamping Copyright © 2004-2005 Ulf Lamping Permission is granted to copy, distribute and/or modify this document under the terms of the GNU General Public License, Version 2 or any later version published by the Free Software Foundation. All logos and trademarks in this document are property of their respective owner. Table of Contents Preface .............................................................................................................................. vii 1. Foreword ............................................................................................................... vii 2. Who should read this document? ............................................................................... viii 3. Acknowledgements ................................................................................................... ix 4. About this document .................................................................................................. x 5. Where to get the latest copy of this document? ............................................................... xi 6. Providing feedback about this document ...................................................................... xii I. Ethereal Build Environment ................................................................................................14 1. Introduction .............................................................................................................15 -

The GNU Compiler Collection on Zseries
The GNU Compiler Collection on zSeries Dr. Ulrich Weigand Linux for zSeries Development, IBM Lab Böblingen [email protected] Agenda GNU Compiler Collection History and features Architecture overview GCC on zSeries History and current status zSeries specific features and challenges Using GCC GCC optimization settings GCC inline assembly Future of GCC GCC and Linux Apache Samba mount cvs binutils gdb gcc Linux ls grep Kernel glibc DB2 GNU - essentials UDB SAP R/3 Unix - tools Applications GCC History Timeline January 1984: Start of the GNU project May 1987: Release of GCC 1.0 February 1992: Release of GCC 2.0 August 1997: EGCS project announced November 1997: Release of EGCS 1.0 April 1999: EGCS / GCC merge July 1999: Release of GCC 2.95 June 2001: Release of GCC 3.0 May/August 2002: Release of GCC 3.1/3.2 March 2003: Release of GCC 3.3 (estimated) GCC Features Supported Languages part of GCC distribution: C, C++, Objective C Fortran 77 Java Ada distributed separately: Pascal Modula-3 under development: Fortran 95 Cobol GCC Features (cont.) Supported CPU targets i386, ia64, rs6000, s390 sparc, alpha, mips, arm, pa-risc, m68k, m88k many embedded targets Supported OS bindings Unix: Linux, *BSD, AIX, Solaris, HP/UX, Tru64, Irix, SCO DOS/Windows, Darwin (MacOS X) embedded targets and others Supported modes of operation native compiler cross-compiler 'Canadian cross' builds GCC Architecture: Overview C C++ Fortran Java ... front-end front-end front-end front-end tree Optimizer rtx i386 s390 rs6000 sparc ... back-end back-end back-end -

Open Source License and Copyright Information for Gplv3 and Lgplv3
Open Source License and Copyright Information for GPLv3/LGPLv3 Dell EMC PowerStore Open Source License and Copyright Information for GPLv3/LGPLv3 June 2021 Rev A02 Revisions Revisions Date Description May 2020 Initial release December 2020 Version updates for some licenses, and addition and deletion of other components June, 2021 Version updates for some licenses, and addition and deletion of other components The information in this publication is provided “as is.” Dell Inc. makes no representations or warranties of any kind with respect to the information in this publication, and specifically disclaims implied warranties of merchantability or fitness for a particular purpose. Use, copying, and distribution of any software described in this publication requires an applicable software license. Copyright © 2020-2021 Dell Inc. or its subsidiaries. All Rights Reserved. Dell Technologies, Dell, EMC, Dell EMC and other trademarks are trademarks of Dell Inc. or its subsidiaries. Other trademarks may be trademarks of their respective owners. [6/1/2021] [Open Source License and Copyright Information for GPLv3/LGPLv3] [Rev A02] 2 Dell EMC PowerStore: Open Source License and Copyright Information for GPLv3/LGPLv3 Table of contents Table of contents Revisions............................................................................................................................................................................. 2 Table of contents ............................................................................................................................................................... -

Gnu Compiler Collection Backend Port for the Integral Parallel Architecture
U.P.B. Sci. Bull., Series C, Vol. 74, Iss. 3, 2012 ISSN 1454-234x GNU COMPILER COLLECTION BACKEND PORT FOR THE INTEGRAL PARALLEL ARCHITECTURE Radu HOBINCU1, Valeriu CODREANU2, Lucian PETRICĂ3 Lucrarea de față prezintă procesul de portare a compilatorului GCC oferit de către Free Software Foundation pentru arhitectura hibridă Integral Parallel Architecture, constituită dintr-un controller multithreading și o mașina vectorială SIMD. Este bine cunoscut faptul că motivul principal pentru care mașinile hibride ca și cele vectoriale sunt dificil de utilizat eficient, este programabilitatea. În această lucrare vom demonstra că folosind un compilator open-source și facilitățile de care acesta dispune, putem ușura procesul de dezvoltare software pentru aplicații complexe. This paper presents the process of porting the GCC compiler offered by the Free Software Foundation, for the hybrid Integral Parallel Architecture composed of an interleaved multithreading controller and a vectorial SIMD machine. It is well known that the main reason for which hybrid and vectorial machines are difficult to use efficiently, is programmability. In this paper we well show that by using an open-source compiler and the features it provides, we can ease the software developing process for complex applications. Keywords: integral parallel architecture, multithreading, interleaved multithreading, bubble-free embedded architecture for multithreading, compiler, GCC, backend port 1. Introduction The development of hardware technology in the last decades has required the programmers to offer support for the new features and performances of the last generation processors. This support comes as more complex compilers that have to use the machines' capabilities at their best, and more complex operating systems that need to meet the users' demand for speed, flexibility and accessibility. -

Introduction to the Linux Kernel: Challenges and Case Studies
Introduction to the Linux kernel: challenges and case studies Juan Carlos Sáez Alcaide Department of Computer Architecture and Automation ArTeCS Group Complutense University of Madrid IV Semana de la Informática 2018 Feb 8, 2018 About Me Juan Carlos Sáez Alcaide ([email protected]) Interim Associate Professor, UCM Department of Computer Architecture and Automation Teaching: Operating Systems, Linux and Android Internals,… Member of the ArTeCS Research Group High Performance Computing Computer Architecture Interaction between system software and architecture … UCM Campus Representative of the USENIX Int’l Association Login (USENIX Magazine) IV Semana de la Informática 2018 - 2 Outline 1 Introduction 2 Main Features 3 Kernel Control Paths and Concurrency 4 Common Kernel abstractions 5 A case study: PMCTrack tool IV Semana de la Informática 2018 - 3 Outline 1 Introduction 2 Main Features 3 Kernel Control Paths and Concurrency 4 Common Kernel abstractions 5 A case study: PMCTrack tool IV Semana de la Informática 2018 - 4 Unix (I) Unics – Unix (1969) Created by Ken Thompson and rewrit- ten in “C” by Dennis Ritchie (1973) V6 (1975): Public source code (AT&T license) BSD distributions (Billy Joy) John Lion’s book on UNIX V6 Keys to success 1 Inexpensive license 2 Source code available 3 Code was simple and easy to modify 4 Ran on modest HW IV Semana de la Informática 2018 - 5 Unix (II) Unix (Cont.) V7 (1979): code can be no longer used for academic purposes Xenix (1980) Microsoft SCO Unix System III (1982) Unix System V (1983) HP-UX, IBM’s AIX, Sun’s Solaris IV Semana de la Informática 2018 - 6 Unix (III) Proyecto GNU (1983) - Richard Stallman SO GNU: Emacs, GNU compiler collection (GCC), GNU Hurd (kernel) Minix v1 (1987) - Andrew Tanenbaum Richard Stallman Minimal Unix-like OS (Unix clone) Teaching purposes. -

Introduction to Free Software-SELF
Introduction to Free Software Jordi Mas Hernández (coordinador) David Megías Jiménez (coordinador) Jesús M. González Barahona Joaquín Seoane Pascual Gregorio Robles XP07/M2101/02708 © FUOC • XP07/M2101/02708 Introduction to Free Software Jordi Mas Hernández David Megías Jiménez Jesús M. González Barahona Founding member of Softcatalà and Computer Science Engineer by the Professor in the Department of Tele- of the telematic network RedBBS. Universitat Autònoma de Barcelona matic Systems and Computation of He has worked as a consultant in (UAB, Spain). Master in Advanced the Rey Juan Carlos University (Ma- companies like Menta, Telépolis, Vo- Process Automatisation Techniques drid, Spain), where he coordinates dafone, Lotus, eresMas, Amena and by the UAB. PhD. in Computer Sci- the research group LibreSoft. His Terra España. ence by the UAB. Associate Profes- professional areas of interest include sor in the Computer Science, Multi- the study of free software develop- media and Telecommunication De- ment and the transfer of knowledge partment of the Universitat Oberta in this field to the industrial sector. de Catalunya (UOC, Spain) and Di- rector of the Master Programme in Free Software at the UOC. Joaquín Seoane Pascual Gregorio Robles PhD. Enigeer of Telecommunicati- Assistant professor in the Rey Juan ons in the Politechnical University Carlos University (Madrid, Spain), of Madrid (Spain). He has worked where he acquired his PhD. de- in the private sector and has al- gree in February 2006. Besides his so taught in the Computer Scien- teaching tasks, he researches free ce Faculty of that same university. software development from the Nowadays he is professor in the De- point of view of software enginee- partment of Telematic Systems En- ring, with special focus in quantitati- gineering, and has taught courses ve issues. -

The GCC Compilers
Software Design Lecture Notes Prof. Stewart Weiss The GCC Compilers The GCC Compilers Preface If all you really want to know is how to compile your C or C++ program using GCC, and you don't have the time or interest in understanding what you're doing or what GCC is, you can skip most of these notes and cut to the chase by jumping to the examples in Section 6. I think you will be better o if you take the time to read the whole thing, since I believe that when you understand what something is, you are better able to gure out how to use it. If you have never used GCC, or if you have used it without really knowing what you did, (because you were pretty much using it by rote), then you should read this. If you think you do understand GCC and do not use it by rote, you may still benet from reading this; you might learn something anyway. Because I believe in the importance of historical context, I begin with a brief history of GCC. 1 Brief History Richard Stallman started the GNU Project in 1984 with the purpose of creating a free, Unix-like operating system. His motivation was to promote freedom and cooperation among users and programmers. Since Unix requires a C compiler and there were no free C compilers at the time, the GNU Project had to build a C compiler from the ground up. The Free Software Foundation was a non-prot organization created to support the work of the GNU Project. -

Productive High Performance Parallel Programming with Auto-Tuned Domain-Specific Embedded Languages
Productive High Performance Parallel Programming with Auto-tuned Domain-Specific Embedded Languages By Shoaib Ashraf Kamil A dissertation submitted in partial satisfaction of the requirements for the degree of Doctor of Philosophy in Computer Science in the Graduate Division of the University of California, Berkeley Committee in charge: Professor Armando Fox, Co-Chair Professor Katherine Yelick, Co-Chair Professor James Demmel Professor Berend Smit Fall 2012 Productive High Performance Parallel Programming with Auto-tuned Domain-Specific Embedded Languages Copyright c 2012 Shoaib Kamil. Abstract Productive High Performance Parallel Programming with Auto-tuned Domain-Specific Embedded Languages by Shoaib Ashraf Kamil Doctor of Philosophy in Computer Science University of California, Berkeley Professor Armando Fox, Co-Chair Professor Katherine Yelick, Co-Chair As the complexity of machines and architectures has increased, performance tuning has become more challenging, leading to the failure of general compilers to generate the best possible optimized code. Expert performance programmers can often hand-write code that outperforms compiler- optimized low-level code by an order of magnitude. At the same time, the complexity of programs has also increased, with modern programs built on a variety of abstraction layers to manage complexity, yet these layers hinder efforts at optimization. In fact, it is common to lose one or two additional orders of magnitude in performance when going from a low-level language such as Fortran or C to a high-level language like Python, Ruby, or Matlab. General purpose compilers are limited by the inability of program analysis to determine pro- grammer intent, as well as the lack of detailed performance models that always determine the best executable code for a given computation and architecture. -

Using and Porting the GNU Compiler Collection
Using and Porting the GNU Compiler Collection Richard M. Stallman Last updated 14 June 2001 for gcc-3.0 Copyright c 1988, 1989, 1992, 1993, 1994, 1995, 1996, 1998, 1999, 2000, 2001 Free Software Foundation, Inc. For GCC Version 3.0 Published by the Free Software Foundation 59 Temple Place - Suite 330 Boston, MA 02111-1307, USA Last printed April, 1998. Printed copies are available for $50 each. ISBN 1-882114-37-X Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.1 or any later version published by the Free Software Foundation; with the Invariant Sections being “GNU General Public License”, the Front-Cover texts being (a) (see below), and with the Back-Cover Texts being (b) (see below). A copy of the license is included in the section entitled “GNU Free Documentation License”. (a) The FSF’s Front-Cover Text is: A GNU Manual (b) The FSF’s Back-Cover Text is: You have freedom to copy and modify this GNU Manual, like GNU software. Copies published by the Free Software Foundation raise funds for GNU development. Short Contents Introduction......................................... 1 1 Compile C, C++, Objective C, Fortran, Java ............... 3 2 Language Standards Supported by GCC .................. 5 3 GCC Command Options ............................. 7 4 Installing GNU CC ............................... 111 5 Extensions to the C Language Family .................. 121 6 Extensions to the C++ Language ...................... 165 7 GNU Objective-C runtime features .................... 175 8 gcov: a Test Coverage Program ...................... 181 9 Known Causes of Trouble with GCC ................... 187 10 Reporting Bugs................................. -

Using the GNU Compiler Collection
Using the GNU Compiler Collection Richard M. Stallman Last updated 20 April 2002 for GCC 3.2.3 Copyright c 1988, 1989, 1992, 1993, 1994, 1995, 1996, 1997, 1998, 1999, 2000, 2001, 2002 Free Software Foundation, Inc. For GCC Version 3.2.3 Published by the Free Software Foundation 59 Temple Place—Suite 330 Boston, MA 02111-1307, USA Last printed April, 1998. Printed copies are available for $50 each. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.1 or any later version published by the Free Software Foundation; with the Invariant Sections being “GNU General Public License”, the Front-Cover texts being (a) (see below), and with the Back-Cover Texts being (b) (see below). A copy of the license is included in the section entitled “GNU Free Documentation License”. (a) The FSF’s Front-Cover Text is: A GNU Manual (b) The FSF’s Back-Cover Text is: You have freedom to copy and modify this GNU Manual, like GNU software. Copies published by the Free Software Foundation raise funds for GNU development. i Short Contents Introduction ...................................... 1 1 Compile C, C++, Objective-C, Ada, Fortran, or Java ....... 3 2 Language Standards Supported by GCC ............... 5 3 GCC Command Options .......................... 7 4 C Implementation-defined behavior ................. 153 5 Extensions to the C Language Family ................ 157 6 Extensions to the C++ Language ................... 255 7 GNU Objective-C runtime features.................. 267 8 Binary Compatibility ........................... 273 9 gcov—a Test Coverage Program ................... 277 10 Known Causes of Trouble with GCC ............... -
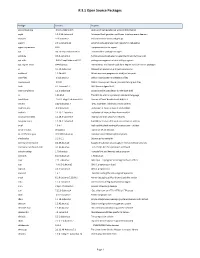
R 3.1 Open Source Packages
R 3.1 Open Source Packages Package Version Purpose accountsservice 0.6.15-2ubuntu9.3 query and manipulate user account information acpid 1:2.0.10-1ubuntu3 Advanced Configuration and Power Interface event daemon adduser 3.113ubuntu2 add and remove users and groups apport 2.0.1-0ubuntu12 automatically generate crash reports for debugging apport-symptoms 0.16 symptom scripts for apport apt 0.8.16~exp12ubuntu10.27 commandline package manager aptitude 0.6.6-1ubuntu1 Terminal-based package manager (terminal interface only) apt-utils 0.8.16~exp12ubuntu10.27 package managment related utility programs apt-xapian-index 0.44ubuntu5 maintenance and search tools for a Xapian index of Debian packages at 3.1.13-1ubuntu1 Delayed job execution and batch processing authbind 1.2.0build3 Allows non-root programs to bind() to low ports base-files 6.5ubuntu6.2 Debian base system miscellaneous files base-passwd 3.5.24 Debian base system master password and group files bash 4.2-2ubuntu2.6 GNU Bourne Again Shell bash-completion 1:1.3-1ubuntu8 programmable completion for the bash shell bc 1.06.95-2 The GNU bc arbitrary precision calculator language bind9-host 1:9.8.1.dfsg.P1-4ubuntu0.16 Version of 'host' bundled with BIND 9.X binutils 2.22-6ubuntu1.4 GNU assembler, linker and binary utilities bsdmainutils 8.2.3ubuntu1 collection of more utilities from FreeBSD bsdutils 1:2.20.1-1ubuntu3 collection of more utilities from FreeBSD busybox-initramfs 1:1.18.5-1ubuntu4 Standalone shell setup for initramfs busybox-static 1:1.18.5-1ubuntu4 Standalone rescue shell with tons of built-in utilities bzip2 1.0.6-1 High-quality block-sorting file compressor - utilities ca-certificates 20111211 Common CA certificates ca-certificates-java 20110912ubuntu6 Common CA certificates (JKS keystore) checkpolicy 2.1.0-1.1 SELinux policy compiler command-not-found 0.2.46ubuntu6 Suggest installation of packages in interactive bash sessions command-not-found-data 0.2.46ubuntu6 Set of data files for command-not-found.