Fine-Grained Api Usage Extractor
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Skalierbare Echtzeitverarbeitung Mit Spark Streaming: Realisierung Und Konzeption Eines Car Information Systems
Bachelorarbeit Philipp Grulich Skalierbare Echtzeitverarbeitung mit Spark Streaming: Realisierung und Konzeption eines Car Information Systems Fakultät Technik und Informatik Faculty of Engineering and Computer Science Department Informatik Department of Computer Science Philipp Grulich Skalierbare Echtzeitverarbeitung mit Spark Streaming: Realisierung und Konzeption eines Car Information Systems Bachelorarbeit eingereicht im Rahmen Bachelorprüfung im Studiengang Angewandte Informatik am Department Informatik der Fakultät Technik und Informatik der Hochschule für Angewandte Wissenschaften Hamburg Betreuender Prüfer: Prof. Dr.-Ing. Olaf Zukunft Zweitgutachter: Prof. Dr. Stefan Sarstedt Abgegeben am 1.3.2016 Philipp Grulich Thema der Arbeit Skalierbare Echtzeitverarbeitung mit Spark Streaming: Realisierung und Konzeption eines Car Information Systems Stichworte Echtzeitverarbeitung, Spark, Spark Streaming, Car Information System, Event Processing, Skalierbarkeit, Fehlertoleranz Kurzzusammenfassung Stream Verarbeitung ist mittlerweile eines der relevantesten Bereiche im Rahmen der Big Data Analyse, da es die Verarbeitung einer Vielzahl an Events innerhalb einer kurzen Latenz erlaubt. Eines der momentan am häufigsten genutzten Stream Verarbeitungssysteme ist Spark Streaming. Dieses wird im Rahmen dieser Arbeit anhand der Konzeption und Realisie- rung eines Car Information Systems demonstriert und diskutiert, wobei viel Wert auf das Er- zeugen einer möglichst generischen Anwendungsarchitektur gelegt wird. Abschließend wird sowohl das CIS als -
Unravel Data Systems Version 4.5
UNRAVEL DATA SYSTEMS VERSION 4.5 Component name Component version name License names jQuery 1.8.2 MIT License Apache Tomcat 5.5.23 Apache License 2.0 Tachyon Project POM 0.8.2 Apache License 2.0 Apache Directory LDAP API Model 1.0.0-M20 Apache License 2.0 apache/incubator-heron 0.16.5.1 Apache License 2.0 Maven Plugin API 3.0.4 Apache License 2.0 ApacheDS Authentication Interceptor 2.0.0-M15 Apache License 2.0 Apache Directory LDAP API Extras ACI 1.0.0-M20 Apache License 2.0 Apache HttpComponents Core 4.3.3 Apache License 2.0 Spark Project Tags 2.0.0-preview Apache License 2.0 Curator Testing 3.3.0 Apache License 2.0 Apache HttpComponents Core 4.4.5 Apache License 2.0 Apache Commons Daemon 1.0.15 Apache License 2.0 classworlds 2.4 Apache License 2.0 abego TreeLayout Core 1.0.1 BSD 3-clause "New" or "Revised" License jackson-core 2.8.6 Apache License 2.0 Lucene Join 6.6.1 Apache License 2.0 Apache Commons CLI 1.3-cloudera-pre-r1439998 Apache License 2.0 hive-apache 0.5 Apache License 2.0 scala-parser-combinators 1.0.4 BSD 3-clause "New" or "Revised" License com.springsource.javax.xml.bind 2.1.7 Common Development and Distribution License 1.0 SnakeYAML 1.15 Apache License 2.0 JUnit 4.12 Common Public License 1.0 ApacheDS Protocol Kerberos 2.0.0-M12 Apache License 2.0 Apache Groovy 2.4.6 Apache License 2.0 JGraphT - Core 1.2.0 (GNU Lesser General Public License v2.1 or later AND Eclipse Public License 1.0) chill-java 0.5.0 Apache License 2.0 Apache Commons Logging 1.2 Apache License 2.0 OpenCensus 0.12.3 Apache License 2.0 ApacheDS Protocol -

Angularjs Native Rich Clients with Eclipse RCP WEB APPS UNTIL NOW
Die Grundlagen Philipp Burgmer theCodeCampus / Weigle Wilczek GmbH ABOUT ME Philipp Burgmer Software Engineer / Consultant / Trainer Focus: Frontend, Web Technologies WeigleWilczek GmbH [email protected] ABOUT US WeigleWilczek / W11k Software Design, Development & Maintenance Consulting, Trainings & Project Kickoff Web Applications with AngularJS Native Rich Clients with Eclipse RCP WEB APPS UNTIL NOW JSF UI on Server A lot HTTP Requests Just to Update UI Hard to Use JS Libs / Scatters UI Logic GWT UI in Java / XML Hard to Use JS Libs / Scatters UI Logic "Java World" Instead of "Web World" Flex Clean Separation of Front- and Backend Based on Flash, Adobe Discontinues Developement MXML and ActionScript Instead of HTML and JavaScript WEB APPS FROM NOW ON Frontend Runs Completely in the Browser Stateful UI, Stateless Server Server Delivers Static Resources Server Delivers Dynamic Data HTML, CSS and JavaScript as UI Toolkit WHAT IS ANGULARJS? HTML Enhanced for Web Apps angularjs.com Client / Browser JS Framework Rich Browser Applications Brings Core Frontend Concepts and Features to the Browser Extends HTML Instead of Abstracting or Wrapping It angularjs.org Current Versions: 1.2.23 and 1.3.0-beta.19 License: MIT CORE CONCEPTS Model View Controller Modules Pattern Dependency Injection Two Way Data-Binding Services Directives Filter Goals Separation of Concerns Make It Easier to Write Clean Code Make It Easier to Write Testable Code Offer Concepts and Be Open for Extensions DEMO Two Way Data-Binding [ JS Bin | localhost ] Add Logic with a Controller -

Lmproving Microcontroller and Computer Architecture Education Through Software Simulation
Western University Scholarship@Western Electronic Thesis and Dissertation Repository 8-28-2017 12:00 AM lmproving Microcontroller and Computer Architecture Education through Software Simulation Kevin Brightwell The University of Western Ontario Supervisor McIsaac, Kenneth The University of Western Ontario Graduate Program in Electrical and Computer Engineering A thesis submitted in partial fulfillment of the equirr ements for the degree in Master of Engineering Science © Kevin Brightwell 2017 Follow this and additional works at: https://ir.lib.uwo.ca/etd Part of the Computer and Systems Architecture Commons, Digital Circuits Commons, and the Engineering Education Commons Recommended Citation Brightwell, Kevin, "lmproving Microcontroller and Computer Architecture Education through Software Simulation" (2017). Electronic Thesis and Dissertation Repository. 4886. https://ir.lib.uwo.ca/etd/4886 This Dissertation/Thesis is brought to you for free and open access by Scholarship@Western. It has been accepted for inclusion in Electronic Thesis and Dissertation Repository by an authorized administrator of Scholarship@Western. For more information, please contact [email protected]. Abstract In this thesis, we aim to improve the outcomes of students learning Computer Architecture and Embedded Systems topics within Software and Computer Engineering programs. We de- velop a simulation of processors that attempts to improve the visibility of hardware within the simulation environment and replace existing solutions in use within the classroom. We desig- nate a series of requirements of a successful simulation suite based on current state-of-the-art simulations within literature. Provided these requirements, we build a quantitative rating of the same set of simulations. Additionally, we rate our previously implemented tool, hc12sim, with current solutions. -

Full-Graph-Limited-Mvn-Deps.Pdf
org.jboss.cl.jboss-cl-2.0.9.GA org.jboss.cl.jboss-cl-parent-2.2.1.GA org.jboss.cl.jboss-classloader-N/A org.jboss.cl.jboss-classloading-vfs-N/A org.jboss.cl.jboss-classloading-N/A org.primefaces.extensions.master-pom-1.0.0 org.sonatype.mercury.mercury-mp3-1.0-alpha-1 org.primefaces.themes.overcast-${primefaces.theme.version} org.primefaces.themes.dark-hive-${primefaces.theme.version}org.primefaces.themes.humanity-${primefaces.theme.version}org.primefaces.themes.le-frog-${primefaces.theme.version} org.primefaces.themes.south-street-${primefaces.theme.version}org.primefaces.themes.sunny-${primefaces.theme.version}org.primefaces.themes.hot-sneaks-${primefaces.theme.version}org.primefaces.themes.cupertino-${primefaces.theme.version} org.primefaces.themes.trontastic-${primefaces.theme.version}org.primefaces.themes.excite-bike-${primefaces.theme.version} org.apache.maven.mercury.mercury-external-N/A org.primefaces.themes.redmond-${primefaces.theme.version}org.primefaces.themes.afterwork-${primefaces.theme.version}org.primefaces.themes.glass-x-${primefaces.theme.version}org.primefaces.themes.home-${primefaces.theme.version} org.primefaces.themes.black-tie-${primefaces.theme.version}org.primefaces.themes.eggplant-${primefaces.theme.version} org.apache.maven.mercury.mercury-repo-remote-m2-N/Aorg.apache.maven.mercury.mercury-md-sat-N/A org.primefaces.themes.ui-lightness-${primefaces.theme.version}org.primefaces.themes.midnight-${primefaces.theme.version}org.primefaces.themes.mint-choc-${primefaces.theme.version}org.primefaces.themes.afternoon-${primefaces.theme.version}org.primefaces.themes.dot-luv-${primefaces.theme.version}org.primefaces.themes.smoothness-${primefaces.theme.version}org.primefaces.themes.swanky-purse-${primefaces.theme.version} -

Liferay Third Party Libraries
Third Party Software List Liferay Portal 6.2 EE SP20 There were no third party library changes in this version. Liferay Portal 6.2 EE SP19 There were no third party library changes in this version. Liferay Portal 6.2 EE SP18 There were no third party library changes in this version. Liferay Portal 6.2 EE SP17 File Name Version Project License Comments lib/portal/monte-cc.jar 0.7.7 Monte Media Library (http://www.randelshofer.ch/monte) LGPL 3.0 (https://www.gnu.org/licenses/lgpl-3.0) lib/portal/netcdf.jar 4.2 NetCDF (http://www.unidata.ucar.edu/packages/netcdf-java) Netcdf License (http://www.unidata.ucar.edu/software/netcdf/copyright.html) lib/portal/netty-all.jar 4.0.23 Netty (http://netty.io) Apache License 2.0 (http://www.apache.org/licenses/LICENSE-2.0) Liferay Portal 6.2 EE SP16 File Name Version Project License Comments lib/development/postgresql.jar 9.4-1201 JDBC 4 PostgreSQL JDBC Driver (http://jdbc.postgresql.org) BSD Style License (http://en.wikipedia.org/wiki/BSD_licenses) lib/portal/commons-fileupload.jar 1.2.2 Commons FileUpload (http://commons.apache.org/fileupload) Apache License 2.0 (http://www.apache.org/licenses/LICENSE-2.0) This includes a public Copyright (c) 2002-2006 The Apache Software Foundation patch for CVE-2014-0050 and CVE-2016-3092. lib/portal/fontbox.jar 1.8.12 PDFBox (http://pdfbox.apache.org) Apache License 2.0 (http://www.apache.org/licenses/LICENSE-2.0) lib/portal/jempbox.jar 1.8.12 PDFBox (http://pdfbox.apache.org) Apache License 2.0 (http://www.apache.org/licenses/LICENSE-2.0) lib/portal/pdfbox.jar 1.8.12 PDFBox (http://pdfbox.apache.org) Apache License 2.0 (http://www.apache.org/licenses/LICENSE-2.0) lib/portal/poi-ooxml.jar 3.9 POI (http://poi.apache.org) Apache License 2.0 (http://www.apache.org/licenses/LICENSE-2.0) This includes a public Copyright (c) 2009 The Apache Software Foundation patch from bug 56164 for CVE-2014-3529 and from bug 54764 for CVE-2014-3574. -

Java Libraries You Can't Afford to Miss
JAVA LIBRARIES YOU CAN’T AFFORD TO MISS ANDRES ALMIRAY @AALMIRAY THE CHALLENGE Write an application that consumes a REST API. Components must be small and reusable. Say no to boilerplate code. Behavior should be easy to test. THE LIBRARIES PRODUCTION TEST Guice | Spring JUnitParams OkHttp Mockito Retrofit Jukito JDeferred Awaitility RxJava | Reactor Spock MBassador WireMock Lombok Slf4j | Log4j2 DISCLAIMER THE CHALLENGE Write an application that consumes a REST API. Components must be small and reusable. Say no to boilerplate code. Behavior should be easy to test. GITHUB API Well documented REST API Latest version located at https://developer.github.com/v3/ We’re interested in the repositories operation for now QUERYING REPOSITORIES API described at https://developer.github.com/v3/repos/#list- organization-repositories Given a query of the form GET /orgs/${organization}/repos QUERY RESULT [ { "id": 1296269, "owner": { /* omitted for brevity */ }, "name": "Hello-World", "full_name": "octocat/Hello-World", "description": "This your first repo!", "html_url": "https://github.com/octocat/Hello-World", /* many other properties follow */ }, /* additional repositories if they exist */ ] WHAT WE’LL NEED Dependency Injection HTTP client & REST behavior JSON mapping Boilerplate buster Handle concurrency GET THE CODE https://github.com/aalmiray/javatrove/ DEPENDENCY INJECTION public interface Github { Promise<Collection<Repository>> repositories(String name); } public class AppController { @Inject private AppModel model; @Inject private Github github; -

Code Smell Prediction Employing Machine Learning Meets Emerging Java Language Constructs"
Appendix to the paper "Code smell prediction employing machine learning meets emerging Java language constructs" Hanna Grodzicka, Michał Kawa, Zofia Łakomiak, Arkadiusz Ziobrowski, Lech Madeyski (B) The Appendix includes two tables containing the dataset used in the paper "Code smell prediction employing machine learning meets emerging Java lan- guage constructs". The first table contains information about 792 projects selected for R package reproducer [Madeyski and Kitchenham(2019)]. Projects were the base dataset for cre- ating the dataset used in the study (Table I). The second table contains information about 281 projects filtered by Java version from build tool Maven (Table II) which were directly used in the paper. TABLE I: Base projects used to create the new dataset # Orgasation Project name GitHub link Commit hash Build tool Java version 1 adobe aem-core-wcm- www.github.com/adobe/ 1d1f1d70844c9e07cd694f028e87f85d926aba94 other or lack of unknown components aem-core-wcm-components 2 adobe S3Mock www.github.com/adobe/ 5aa299c2b6d0f0fd00f8d03fda560502270afb82 MAVEN 8 S3Mock 3 alexa alexa-skills- www.github.com/alexa/ bf1e9ccc50d1f3f8408f887f70197ee288fd4bd9 MAVEN 8 kit-sdk-for- alexa-skills-kit-sdk- java for-java 4 alibaba ARouter www.github.com/alibaba/ 93b328569bbdbf75e4aa87f0ecf48c69600591b2 GRADLE unknown ARouter 5 alibaba atlas www.github.com/alibaba/ e8c7b3f1ff14b2a1df64321c6992b796cae7d732 GRADLE unknown atlas 6 alibaba canal www.github.com/alibaba/ 08167c95c767fd3c9879584c0230820a8476a7a7 MAVEN 7 canal 7 alibaba cobar www.github.com/alibaba/ -

State of Mutation Testing at Google
State of Mutation Testing at Google Goran Petrovi´c Marko Ivankovi´c Google Inc. Google Inc. [email protected] [email protected] ABSTRACT mutants of the original code, and judges the effectiveness of Mutation testing assesses test suite efficacy by inserting small the test suite by its ability to detect those faults. Mutation faults into programs and measuring the ability of the test analysis is widely considered the best method of evaluating suite to detect them. It is widely considered the strongest test test suite efficacy [1]. Mutants resemble real world bugs, and criterion in terms of finding the most faults and it subsumes a that the test suite effectiveness in detecting mutants is corre- number of other coverage criteria. Traditional mutation anal- lated to its effectiveness in detecting real faults [11]. While ysis is computationally prohibitive which hinders its adoption being a powerful tool, it is often computationally prohibitive. as an industry standard. In order to alleviate the computa- Furthermore, the cost of developer attention in evaluating tional issues, we present a diff-based probabilistic approach and mitigating the results of the analysis is also expensive to mutation analysis that drastically reduces the number of and can be exorbitant even for medium sized systems. mutants by omitting lines of code without statement coverage To leverage mutation analysis in a large complex software and lines that are determined to be uninteresting - we dub system like Google's, in this work we propose a diff-based these arid lines. Furthermore, by reducing the number of approach to mutation analysis. Moreover, in the work we de- mutants and carefully selecting only the most interesting ones scribe a method of transitive mutation suppression of uninter- we make it easier for humans to understand and evaluate esting, arid lines based on developer feedback and program's the result of mutation analysis. -
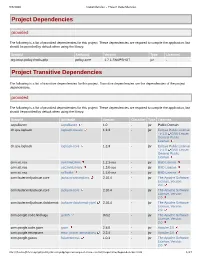
Project Dependencies Project Transitive Dependencies
9/8/2020 Dependencies – Project Dependencies Project Dependencies provided The following is a list of provided dependencies for this project. These dependencies are required to compile the application, but should be provided by default when using the library: GroupId ArtifactId Version Type Licenses org.onap.policy.drools-pdp policy-core 1.7.1-SNAPSHOT jar - Project Transitive Dependencies The following is a list of transitive dependencies for this project. Transitive dependencies are the dependencies of the project dependencies. provided The following is a list of provided dependencies for this project. These dependencies are required to compile the application, but should be provided by default when using the library: GroupId ArtifactId Version Classifier Type Licenses aopalliance aopalliance 1.0 - jar Public Domain ch.qos.logback logback-classic 1.2.3 - jar Eclipse Public License - v 1.0 GNU Lesser General Public License ch.qos.logback logback-core 1.2.3 - jar Eclipse Public License - v 1.0 GNU Lesser General Public License com.att.nsa cambriaClient 1.2.1-oss - jar BSD License com.att.nsa saClientLibrary 1.3.0-oss - jar BSD License com.att.nsa saToolkit 1.2.0-oss - jar BSD License com.fasterxml.jackson.core jackson-annotations 2.10.4 - jar The Apache Software License, Version 2.0 com.fasterxml.jackson.core jackson-core 2.10.4 - jar The Apache Software License, Version 2.0 com.fasterxml.jackson.dataformat jackson-dataformat-yaml 2.10.4 - jar The Apache Software License, Version 2.0 com.google.code.findbugs jsr305 3.0.2 - jar The Apache -

Interop.Jar Activation
Resource name License name License reference Usage Type a-j-interop.jar Eclipse 1.0 http://www.j-interop.org/license.html Dynamic library http://mirrors.ibiblio.org/pub/mirrors/maven2/javax/activation/act activation-1.1.jar CDDL 1.0 ivation/1.1/activation-1.1.pom Dynamic library activation.jar LGPL 2.1 https://github.com/wildfly/wildfly/blob/master/README.md Dynamic library http://mirrors.ibiblio.org/pub/mirrors/maven2/org/apache/activem activemq-all-5.7.0.jar Apache 2.0 q/activemq-all/5.7.0/activemq-all-5.7.0.pom Dynamic library http://mirrors.ibiblio.org/pub/mirrors/maven2/org/apache/activem activemq-core-5.7.0.jar Apache 2.0 q/activemq-core/5.7.0/activemq-core-5.7.0.pom Dynamic library http://mirrors.ibiblio.org/pub/mirrors/maven2/org/apache/activem activemq-pool-5.7.0.jar Apache 2.0 q/activemq-pool/5.7.0/activemq-pool-5.7.0.pom Dynamic library http://mirrors.ibiblio.org/pub/mirrors/maven2/org/apache/activem activemq-protobuf-1.1.jar Apache 2.0 q/protobuf/activemq-protobuf/1.1/activemq-protobuf-1.1.pom Dynamic library http://mirrors.ibiblio.org/pub/mirrors/maven2/org/apache/axis2/a addressing-1.6.2.jar Apache 2.0 ddressing/1.6.2/addressing-1.6.2.pom Dynamic library advancedPersistentLookupLib-1.0.jar Commercial http://www.talend.com Dynamic library aether-api-1.11.jar Eclipse 1.0 https://www.eclipse.org/aether/download/ Dynamic library aether-connector-asynchttpclient-1.11.jar Eclipse 1.0 https://www.eclipse.org/aether/download/ Dynamic library aether-connector-wagon-1.11.jar Eclipse 1.0 https://www.eclipse.org/aether/download/ Dynamic -

EVVA General Licensing Conditions
EVVA General Licensing Conditions The purchaser of the License (hereinafter referred to as the LICENSEE) acknowledges that all use and provision of the LICENSED MATERIAL (Definition: see 1.2) is solely according to the following General Licensing Conditions of EVVA Sicherheitstechnologie GmbH, company number 120755g with registered office in 1120 Vienna, Austria (hereinafter referred to as the LICENSOR or EVVA), which are explicitly accepted in the context of the purchase of the License, by the first use of the PROGRAM, or by breaking the seal. Where applicable, additional regulations in a licensing contract and, subsidiarily, the General Terms and Conditions of Business of EVVA also apply. The EVVA General Licensing Conditions apply to all agreements in association with the use of the software or comparable Products of the LICENSOR, if these are part of the supply of a complete system, or other parts of an Agreement. General Terms and Conditions of Business of the LICENSEE, outline contracts, or references to these do not apply without the explicit consent of the LICENSOR. I. Definition of terms I.1 Program Within the meaning of this Agreement, the contractual parties understand PROGRAM to mean the computer program developed by the LICENSOR, which is the subject of this License. Software from third party suppliers, which is supplied with this PROGRAM, in particular Open Source Software (see Annex./1), is independent of the PROGRAM and is subject to separate licensing conditions. I.2 Licensed Material The LICENSED MATERIAL includes the PROGRAM according to the definition in the respective license contract, and any possible additional documentation.