Characterizing the Triggering Phenomenon in Wikipedia
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
E-Register: June, 2019
E-Register: June, 2019 S. No. Diary No. RoC No. Date Title of Work Category Applicant 1 4347/2019-CO/L L-82912/2019 03/06/2019 ETHANOL AS Literary/ RAHUL KRISHNAJI BAWANE ,SHANTANU ALTERNATIVE FOR Dramatic RAJESH KAMTHE 2 3626/2019-CO/A A-129633/2019 03/06/2019 BEDSHEETCONVENTIONAL DESIGN FUEL 7 Artistic RAGHAV EXPORTS, AN INDIAN CHAKRAS PARTNERSHIP FIRM, THROUGH PARTNER MR VIKAS GARG 3 3432/2019-CO/SR SR-14114/2019 03/06/2019 WOH AUR KOI NAHI Sound SAMARTHA SUTRALE MERI MAA THI Recording 4 2362/2019-CO/A A-129634/2019 03/06/2019 INDIAN BUSINESS Artistic KARTIK GUPTA STORY 5 6379/2019-CO/L L-82913/2019 03/06/2019 CERTIFICATE COURSE Literary/ SRI SRI UNIVERSITY IN HUMAN Dramatic DEVELOPMENT AND COUNSELLING VEDIC AND MODERN PERSPECTIVES 6 6023/2019-CO/SW SW-12476/2019 03/06/2019 Skysite F&A Collection Computer ARC Document Solutions India Private recovery manager Software Limited 7 6463/2019-CO/L L-82914/2019 03/06/2019 Hamara Beta Hokhi Literary/ Ganesh Chandra Surya Team Film Pvt. Ltd Dramatic 8 6441/2019-CO/L L-82915/2019 03/06/2019 AADARAVAYOR Literary/ M. K ALIKKUTTY alias SAIDALAVI AASHICHA NATTIL Dramatic 9 6444/2019-CO/L L-82916/2019 03/06/2019 RAVILIN NAM Literary/ M. K ALIKKUTTY alias SAIDALAVI RABBINORKUM Dramatic 10 6462/2019-CO/L L-82917/2019 03/06/2019 Jaye Ke Beriya Literary/ Ganesh Chandra Surya Team Film Pvt. Ltd Dramatic 11 6458/2019-CO/L L-82918/2019 03/06/2019 Pakadi Sipahiya Ram Literary/ Ganesh Chandra Surya Team Film Pvt. -

Proceedings of the 11Th International Symposium on Open Collaboration
Proceedings of the 11th International Symposium on Open Collaboration August 19-21, 2015 San Francisco, California, U.S.A. General chair: Dirk Riehle, Friedrich-Alexander University Erlangen-Nürnberg Research track chairs: Kevin Crowston, Syracuse University Carlos Jensen, Oregon State University Carl Lagoze, University of Michigan Ann Majchrzak, University of Southern California Arvind Malhotra, University of North Carolina at Chapel Hill Claudia Müller-Birn, Freie Universität Berlin Gregorio Robles, Universidad Rey Juan Carlos Aaron Shaw, Northwestern University Sponsors: Wikimedia Foundation Google Inc. University of California Berkeley In-cooperation: ACM SIGSOFT ACM SIGWEB Fiscal sponsor: The John Ernest Foundation The Association for Computing Machinery 2 Penn Plaza, Suite 701 New York New York 10121-0701 ACM COPYRIGHT NOTICE. Copyright © 2014 by the Association for Computing Machin- ery, Inc. Permission to make digital or hard copies of part or all of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. Copyrights for components of this work owned by others than ACM must be hon- ored. Abstracting with credit is permitted. To copy otherwise, to republish, to post on servers, or to redistribute to lists, requires prior specific permission and/or a fee. Request permissions from Publications Dept., ACM, Inc., fax +1 (212) 869-0481, or [email protected]. For other copying of articles that carry a code at the bottom of the first or last page, copying is permitted provided that the per-copy fee indicated in the code is paid through the Copyright Clearance Center, 222 Rosewood Drive, Danvers, MA 01923, +1-978-750-8400, +1-978-750- 4470 (fax). -

States Symbols State/ Union Territories Motto Song Animal / Aquatic
States Symbols State/ Animal / Foundation Butterfly / Motto Song Bird Fish Flower Fruit Tree Union territories Aquatic Animal day Reptile Maa Telugu Rose-ringed Snakehead Blackbuck Common Mango సతవ జయే Thalliki parakeet Murrel Neem Andhra Pradesh (Antilope jasmine (Mangifera indica) 1 November Satyameva Jayate (To Our Mother (Coracias (Channa (Azadirachta indica) cervicapra) (Jasminum officinale) (Truth alone triumphs) Telugu) benghalensis) striata) सयमेव जयते Mithun Hornbill Hollong ( Dipterocarpus Arunachal Pradesh (Rhynchostylis retusa) 20 February Satyameva Jayate (Bos frontalis) (Buceros bicornis) macrocarpus) (Truth alone triumphs) Satyameva O Mur Apunar Desh Indian rhinoceros White-winged duck Foxtail orchid Hollong (Dipterocarpus Assam सयमेव जयते 2 December Jayate (Truth alone triumphs) (O My Endearing Country) (Rhinoceros unicornis) (Asarcornis scutulata) (Rhynchostylis retusa) macrocarpus) Mere Bharat Ke House Sparrow Kachnar Mango Bihar Kanth Haar Gaur (Mithun) Peepal tree (Ficus religiosa) 22 March (Passer domesticus) (Phanera variegata) (Mangifera indica) (The Garland of My India) Arpa Pairi Ke Dhar Satyameva Wild buffalo Hill myna Rhynchostylis Chhattisgarh सयमेव जयते (The Streams of Arpa Sal (Shorea robusta) 1 November (Bubalus bubalis) (Gracula religiosa) gigantea Jayate (Truth alone triumphs) and Pairi) सव भाण पयतु मा किच Coconut palm Cocos दुःखमानुयात् Ruby Throated Grey mullet/Shevtto Jasmine nucifera (State heritage tree)/ Goa Sarve bhadrāṇi paśyantu mā Gaur (Bos gaurus) Yellow Bulbul in Konkani 30 May (Plumeria rubra) -

Kisan Swaraj Yatra
” “KISAN SWARAJ YATRA – Sabarmati to Rajghat ‘Kisan Ki mazbooti mein hi desh ki mazbooti’ ‘Krishi Bache, Kisan Bache, Desh bache’ An outreach effort across India towards self-reliant, ecological farming and for securing farming communities’ rights – October 2 nd – December 11 th , 2010 Jal, Jangal, Zameen aur BEEJ (Water, Forest, Land & SEED) – the basic common resources that have always belonged to people who acted as the resource-savers and resource- keepers – are in great jeopardy today. These are the basic resources which are pre-requisites for the sustainable livelihoods of millions of Indians. Along with these resources, the very lives of our fellow citizens are perched precariously, mired in unconscionable poverty, hunger, lack of basic rights and any assertive power. While unsuitable (market-driven, anti-nature, ‘treadmill’) technologies have degraded and contaminated these resources over the decades, a more basic concern is around the appropriation of these resources by the State and commercial interests, posing a serious question on the fundamental rights for all citizens of India and on the very vision (or lack of it) for Sustainable Development for all. It is no surprise that we are all a witness to thousands of farmers committing suicides, given that key members of our government articulate a vision that would like to see only 15% of Indians in rural areas soon! It is a matter of shame that in a country where nearly 70% of the population is still connected with farming and food production, rural hunger and starvation is also very high. Worse, the people who are producing food to feed the entire nation are committing suicides in lakhs and are demoralized with their self-respect being eroded constantly, while the industry and sections of the government are gloating about the business opportunities presented by agriculture in India! As we are conversing, the largest displacement ever in our history is happening from agriculture….., with not even basic social security assured for those who are fleeing and are being displaced. -

Understanding the Challenges of Collaborative Evidence-Based
Do you have a source for that? Understanding the Challenges of Collaborative Evidence-based Journalism Sheila O’Riordan Gaye Kiely Bill Emerson Joseph Feller Business Information Business Information Business Information Business Information Systems, University Systems, University Systems, University Systems, University College Cork, Ireland College Cork, Ireland College Cork, Ireland College Cork, Ireland [email protected] [email protected] [email protected] [email protected] ABSTRACT consumption has evolved [25]. There has been a move WikiTribune is a pilot news service, where evidence-based towards digital news with increasing user involvement as articles are co-created by professional journalists and a well as the use of social media platforms for accessing and community of volunteers using an open and collaborative discussing current affairs [14,39,43]. As such, the boundaries digital platform. The WikiTribune project is set within an are shifting between professional and amateur contributions. evolving and dynamic media landscape, operating under Traditional news organizations are adding interactive principles of openness and transparency. It combines a features as participatory journalism practices rise (see [8,42]) commercial for-profit business model with an open and the technologies that allow citizens to interact en masse collaborative mode of production with contributions from provide new avenues for engaging in democratic both paid professionals and unpaid volunteers. This deliberation [19]; the “process of reaching reasoned descriptive case study captures the first 12-months of agreement among free and equal citizens” [6:322]. WikiTribune’s operations to understand the challenges and opportunities within this hybrid model of production. We use With these changes, a number of challenges have arisen. -

Using Shape Expressions (Shex) to Share RDF Data Models and to Guide Curation with Rigorous Validation B Katherine Thornton1( ), Harold Solbrig2, Gregory S
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Repositorio Institucional de la Universidad de Oviedo Using Shape Expressions (ShEx) to Share RDF Data Models and to Guide Curation with Rigorous Validation B Katherine Thornton1( ), Harold Solbrig2, Gregory S. Stupp3, Jose Emilio Labra Gayo4, Daniel Mietchen5, Eric Prud’hommeaux6, and Andra Waagmeester7 1 Yale University, New Haven, CT, USA [email protected] 2 Johns Hopkins University, Baltimore, MD, USA [email protected] 3 The Scripps Research Institute, San Diego, CA, USA [email protected] 4 University of Oviedo, Oviedo, Spain [email protected] 5 Data Science Institute, University of Virginia, Charlottesville, VA, USA [email protected] 6 World Wide Web Consortium (W3C), MIT, Cambridge, MA, USA [email protected] 7 Micelio, Antwerpen, Belgium [email protected] Abstract. We discuss Shape Expressions (ShEx), a concise, formal, modeling and validation language for RDF structures. For instance, a Shape Expression could prescribe that subjects in a given RDF graph that fall into the shape “Paper” are expected to have a section called “Abstract”, and any ShEx implementation can confirm whether that is indeed the case for all such subjects within a given graph or subgraph. There are currently five actively maintained ShEx implementations. We discuss how we use the JavaScript, Scala and Python implementa- tions in RDF data validation workflows in distinct, applied contexts. We present examples of how ShEx can be used to model and validate data from two different sources, the domain-specific Fast Healthcare Interop- erability Resources (FHIR) and the domain-generic Wikidata knowledge base, which is the linked database built and maintained by the Wikimedia Foundation as a sister project to Wikipedia. -

Classifying Wikipedia Article Quality with Revision History Networks
Classifying Wikipedia Article Quality With Revision History Networks Narun Raman∗ Nathaniel Sauerberg∗ Carleton College Carleton College [email protected] [email protected] Jonah Fisher Sneha Narayan Carleton College Carleton College [email protected] [email protected] ABSTRACT long been interested in maintaining and investigating the quality We present a novel model for classifying the quality of Wikipedia of its content [4][6][12]. articles based on structural properties of a network representation Editors and WikiProjects typically rely on assessments of article of the article’s revision history. We create revision history networks quality to focus volunteer attention on improving lower quality (an adaptation of Keegan et. al’s article trajectory networks [7]), articles. This has led to multiple efforts to create classifiers that can where nodes correspond to individual editors of an article, and edges predict the quality of a given article [3][4][18]. These classifiers can join the authors of consecutive revisions. Using descriptive statistics assist in providing assessments of article quality at scale, and help generated from these networks, along with general properties like further our understanding of the features that distinguish high and the number of edits and article size, we predict which of six quality low quality Wikipedia articles. classes (Start, Stub, C-Class, B-Class, Good, Featured) articles belong While many Wikipedia article quality classifiers have focused to, attaining a classification accuracy of 49.35% on a stratified sample on assessing quality based on the content of the latest version of of articles. These results suggest that structures of collaboration an article [1, 4, 18], prior work has suggested that high quality arti- underlying the creation of articles, and not just the content of the cles are associated with more intense collaboration among editors article, should be considered for accurate quality classification. -

E-Posters in Academic/Scientific Conferεnces – Guidelines, Comparative Study & New Suggestions
University of the Aegean Department of Product and Systems Design Engineering DISSERTATION: E-POSTERS IN ACADEMIC/SCIENTIFIC CONFERΕNCES – GUIDELINES, COMPARATIVE STUDY & NEW SUGGESTIONS Pissaridi Maria Anastasia 511/2004041 Supervisor: Paraskevas Papanikos Committee Members: Nikolaos Zacharopoulos Maria Simosi Syros, June 2015 DISSERTATION: E-POSTERS IN ACADEMIC/SCIENTIFIC CONFERENCES – GUIDELINES, COMPARATIVE STUDY & NEW SUGGESTIONS Supervisor: Paraskevas Papanikos Committee Members: Nikolaos Zacharopoulos Maria Simosi Pissaridi Maria Anastasia Syros, June 2015 3 ABSTRACT Conferences play a key role in getting people interested in a field together to network and exchange knowledge. The poster presentation is a commonly used format for communicating information within the academic scientific conference sector. Paper posters were the beginning but as technology and the way people work changes, posters have to be developed and implemented in order to achieve successful knowledge transfer. Incorporating aspects of information technology into poster presentations can promote an interactive learning environment for users and counter the current passive nature of poster design as an integrated approach with supplemental material is required to achieve changes in user knowledge, attitude and behaviour. After conducting literature review, research of existing e-poster providers, interviews with 5 of them and a personal evaluation in a real time conference environment results show a gradual turn towards e-posters with the medical sector pioneering. Authors, viewers and organisers embrace this new format, and the features and functions it offers, although objections exist since people have different preferences and the e-poster sector is relatively young, an average of 5 years. Pissaridi Maria Anastasia dpsd04041 4 SUMMARY Η ανάγκη των ανθρώπων να συγκεντρώνονται για να ανταλλάσσουν ιδέες, ευρήματα, έρευνες και απόψεις υπήρχε από τη δημιουργία των πρώτων πόλεων όπου φτιάχνονται με χώρους συγκέντρωσης. -

Edit Filters on English Wikipedia
You Shall Not Publish: Edit Filters on English Wikipedia Lyudmila Vaseva Claudia Müller-Birn Human-Centered Computing | Freie Universität Berlin Human-Centered Computing | Freie Universität Berlin [email protected] [email protected] Figure 1: Warning Message of an edit filter to inform the editor that their edit is potentially non-constructive. ABSTRACT ACM Reference Format: Ensuring the quality of the content provided in online settings Lyudmila Vaseva and Claudia Müller-Birn. 2020. You Shall Not Publish: is an important challenge today, for example, for social media or Edit Filters on English Wikipedia. In 16th International Symposium on Open Collaboration (OpenSym 2020), August 25–27, 2020, Virtual conference, Spain. news. The Wikipedia community has ensured the high-quality ACM, New York, NY, USA, 10 pages. https://doi.org/10.1145/3412569.3412580 standards for an online encyclopaedia from the beginning and has built a sophisticated set of automated, semi-automated, and manual 1 INTRODUCTION quality assurance mechanisms over the last fifteen years. The scien- tific community has systematically studied these mechanisms but The public heatedly debated so-called "upload filters" in the context 1 one mechanism has been overlooked — edit filters. Edit filters are of the EU copyright law reform in 2019 . Upload filters are con- syntactic rules that assess incoming edits, file uploads or account ceived as a form of copyright protection. They should check for creations. As opposed to many other quality assurance mechanisms, possible infringements of copyrighted material even before a con- edit filters are effective before a new revision is stored in the online tribution is published online — and the contributions affected can encyclopaedia. -

R. Stuart Geiger Curriculum Vitae September 2021 [email protected] | | @Staeiou | Google Scholar | Github
Geiger CV 1/14 R. Stuart Geiger Curriculum Vitae September 2021 [email protected] | http://stuartgeiger.com | @staeiou | Google Scholar | GitHub Education University of California at Berkeley, School of Information Ph.D., Information Management & Systems, designated emphasis in New Media December 2015 Georgetown University M.A., Communication, Culture, and Technology May 2009 University of Texas at Austin B.A., Humanities Honors May 2007 Employment University of California at San Diego Assistant Professor, Dept of Communication & Halıcıoğlu Data Science Institute Jul 2020 – present University of California at Berkeley, Berkeley Institute for Data Science Postdoctoral scholar and staff ethnographer Jan 2016 – June 2020 Wikimedia Foundation Research intern (full-time) May 2011 – Aug 2011 Georgetown University Research associate, Communication, Culture, and Technology (full-time) May 2009 – Aug 2010 Publications & Other Scholarly Outputs: Peer-Reviewed Journal Publications: 1. Geiger, R. S., Cope, D., Ip, J., Lotosh, M., Shah, A., Weng, J., & Tang, R. (2021). “Garbage In, Garbage Out” Revisited: What Do Machine Learning Application Papers Report About Human- Labeled Training Data?. Quantitative Science Studies, Online First. 1-32. https://doi.org/10.1162/qss_a_00144 2. Geiger, R. S., Howard, D., & Irani, L. (2021). The Labor of Maintaining and Scaling Free and Open-Source Software Projects. Proceedings of the ACM on Human-Computer Interaction, 5 (CSCW1), 1-28. https://dl.acm.org/doi/pdf/10.1145/3449249 Geiger CV 2/14 3. Scroggins, M.J., Pasquetto, I.V., Geiger, R.S., Boscoe, B.M., Darch, P.T., Cabasse-Mazel, C., Thompson, C. and Borgman, C.L. (2020). “Thorny Problems in Data (-Intensive) Science.” Communications of the ACM. -
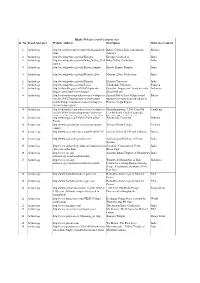
2.Hindu Websites Sorted Category Wise
Hindu Websites sorted Category wise Sl. No. Broad catergory Website Address Description Reference Country 1 Archaelogy http://aryaculture.tripod.com/vedicdharma/id10. India's Cultural Link with Ancient Mexico html America 2 Archaelogy http://en.wikipedia.org/wiki/Harappa Harappa Civilisation India 3 Archaelogy http://en.wikipedia.org/wiki/Indus_Valley_Civil Indus Valley Civilisation India ization 4 Archaelogy http://en.wikipedia.org/wiki/Kiradu_temples Kiradu Barmer Temples India 5 Archaelogy http://en.wikipedia.org/wiki/Mohenjo_Daro Mohenjo_Daro Civilisation India 6 Archaelogy http://en.wikipedia.org/wiki/Nalanda Nalanda University India 7 Archaelogy http://en.wikipedia.org/wiki/Taxila Takshashila University Pakistan 8 Archaelogy http://selians.blogspot.in/2010/01/ganesha- Ganesha, ‘lingga yoni’ found at newly Indonesia lingga-yoni-found-at-newly.html discovered site 9 Archaelogy http://vedicarcheologicaldiscoveries.wordpress.c Ancient Idol of Lord Vishnu found Russia om/2012/05/27/ancient-idol-of-lord-vishnu- during excavation in an old village in found-during-excavation-in-an-old-village-in- Russia’s Volga Region russias-volga-region/ 10 Archaelogy http://vedicarcheologicaldiscoveries.wordpress.c Mahendraparvata, 1,200-Year-Old Cambodia om/2013/06/15/mahendraparvata-1200-year- Lost Medieval City In Cambodia, old-lost-medieval-city-in-cambodia-unearthed- Unearthed By Archaeologists 11 Archaelogy http://wikimapia.org/7359843/Takshashila- Takshashila University Pakistan Taxila 12 Archaelogy http://www.agamahindu.com/vietnam-hindu- Vietnam -

Submission Data for 2020-2021 CORE Conference Ranking Process (Submitted As a Comparator for International Conference on Testing Software and Systems )
Submission Data for 2020-2021 CORE conference Ranking process (Submitted as a comparator for International Conference on Testing Software and Systems ) Mercedes G. Merayo, Ana Rosa Cavalli Conference Details Conference Title: International Symposium on Open Collaboration (was International Symposiums on Wikis) Acronym : OPENSYM Rank: B DBLP Link DBLP url: https://dblp.uni-trier.de/db/conf/wikis Recent Years Proceedings Publishing Style Proceedings Publishing: series Link to most recent proceedings: https://dl.acm.org/doi/proceedings/10.1145/3412569 Further details: Proceedings are published in the ACMâĂŹs International Conference Proceeding Series (ICPS). In addition to Full Research Papers, Emerging Research Papers are included in the proceedings. They are labelled as Short Papers. Also posters have been included in the proceedings (OpenSym 2017) in a dedicated section, POSTER SESSION: Posters. Most Recent Years Most Recent Year Year: 2019 URL: https://opensym.org/os2019/ Location: SkÃűvde, Sweden Papers submitted: 23 Papers published: 17 Acceptance rate: 74 Source for numbers: https://dl.acm.org/doi/proceedings/10.1145/3306446#acceptance-rates General Chairs Name: BjÃűrn Lundell Affiliation: University of SkÃűvde, Sweden Gender: M H Index: 23 GScholar url: https://scholar.google.com/citations?user=HzSO6UQAAAAJ&hl=en DBLP url: https://dblp.org/pid/37/6147.html Name: Jonas Gamalielsson Affiliation: University of SkÃűvde, Sweden Gender: M H Index: 10 GScholar url: DBLP url: https://dblp.org/pid/95/49.html Program Chairs 1 Name: Lorraine Morgan