Optimizing Molecular Inversion Probe Assays to Characterize Human-Specific Neurodevelopmental Genes
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Novel Genetic Features of Human and Mouse Purkinje Cell Differentiation Defined by Comparative Transcriptomics
Novel genetic features of human and mouse Purkinje cell differentiation defined by comparative transcriptomics David E. Buchholza, Thomas S. Carrollb, Arif Kocabasa, Xiaodong Zhua, Hourinaz Behestia, Phyllis L. Faustc, Lauren Stalbowa, Yin Fanga, and Mary E. Hattena,1 aLaboratory of Developmental Neurobiology, The Rockefeller University, New York, NY 10065; bBioinformatics Resource Center, The Rockefeller University, New York, NY 10065; and cDepartment of Pathology and Cell Biology, Columbia University Irving Medical Center and the New York Presbyterian Hospital, New York, NY 10032 Contributed by Mary E. Hatten, April 22, 2020 (sent for review January 3, 2020; reviewed by Lorenz Studer and Hynek Wichterle) Comparative transcriptomics between differentiating human plu- is ataxia-telangiectasia, which shows massive loss of PCs in hu- ripotent stem cells (hPSCs) and developing mouse neurons offers a mans but not in the mouse (11). Human pluripotent stem cells powerful approach to compare genetic and epigenetic pathways (hPSCs) provide a complementary approach to studying human in human and mouse neurons. To analyze human Purkinje cell disease in the mouse (12–14). Validated methods to derive (PC) differentiation, we optimized a protocol to generate human specific neural subtypes from hPSCs are necessary prerequisites pluripotent stem cell-derived Purkinje cells (hPSC-PCs) that formed to disease modeling. We and others have recently developed synapses when cultured with mouse cerebellar glia and granule protocols to derive PCs from hPSCs (15–18). cells and fired large calcium currents, measured with the geneti- One limitation of most hPSC-derived central nervous system cally encoded calcium indicator jRGECO1a. To directly compare (CNS) neurons is the lack of genetic information, especially of global gene expression of hPSC-PCs with developing mouse PCs, transcriptomic signatures, to rigorously identify specific types of we used translating ribosomal affinity purification (TRAP). -

Supplementary Table 1: Adhesion Genes Data Set
Supplementary Table 1: Adhesion genes data set PROBE Entrez Gene ID Celera Gene ID Gene_Symbol Gene_Name 160832 1 hCG201364.3 A1BG alpha-1-B glycoprotein 223658 1 hCG201364.3 A1BG alpha-1-B glycoprotein 212988 102 hCG40040.3 ADAM10 ADAM metallopeptidase domain 10 133411 4185 hCG28232.2 ADAM11 ADAM metallopeptidase domain 11 110695 8038 hCG40937.4 ADAM12 ADAM metallopeptidase domain 12 (meltrin alpha) 195222 8038 hCG40937.4 ADAM12 ADAM metallopeptidase domain 12 (meltrin alpha) 165344 8751 hCG20021.3 ADAM15 ADAM metallopeptidase domain 15 (metargidin) 189065 6868 null ADAM17 ADAM metallopeptidase domain 17 (tumor necrosis factor, alpha, converting enzyme) 108119 8728 hCG15398.4 ADAM19 ADAM metallopeptidase domain 19 (meltrin beta) 117763 8748 hCG20675.3 ADAM20 ADAM metallopeptidase domain 20 126448 8747 hCG1785634.2 ADAM21 ADAM metallopeptidase domain 21 208981 8747 hCG1785634.2|hCG2042897 ADAM21 ADAM metallopeptidase domain 21 180903 53616 hCG17212.4 ADAM22 ADAM metallopeptidase domain 22 177272 8745 hCG1811623.1 ADAM23 ADAM metallopeptidase domain 23 102384 10863 hCG1818505.1 ADAM28 ADAM metallopeptidase domain 28 119968 11086 hCG1786734.2 ADAM29 ADAM metallopeptidase domain 29 205542 11085 hCG1997196.1 ADAM30 ADAM metallopeptidase domain 30 148417 80332 hCG39255.4 ADAM33 ADAM metallopeptidase domain 33 140492 8756 hCG1789002.2 ADAM7 ADAM metallopeptidase domain 7 122603 101 hCG1816947.1 ADAM8 ADAM metallopeptidase domain 8 183965 8754 hCG1996391 ADAM9 ADAM metallopeptidase domain 9 (meltrin gamma) 129974 27299 hCG15447.3 ADAMDEC1 ADAM-like, -

Appendix 2. Significantly Differentially Regulated Genes in Term Compared with Second Trimester Amniotic Fluid Supernatant
Appendix 2. Significantly Differentially Regulated Genes in Term Compared With Second Trimester Amniotic Fluid Supernatant Fold Change in term vs second trimester Amniotic Affymetrix Duplicate Fluid Probe ID probes Symbol Entrez Gene Name 1019.9 217059_at D MUC7 mucin 7, secreted 424.5 211735_x_at D SFTPC surfactant protein C 416.2 206835_at STATH statherin 363.4 214387_x_at D SFTPC surfactant protein C 295.5 205982_x_at D SFTPC surfactant protein C 288.7 1553454_at RPTN repetin solute carrier family 34 (sodium 251.3 204124_at SLC34A2 phosphate), member 2 238.9 206786_at HTN3 histatin 3 161.5 220191_at GKN1 gastrokine 1 152.7 223678_s_at D SFTPA2 surfactant protein A2 130.9 207430_s_at D MSMB microseminoprotein, beta- 99.0 214199_at SFTPD surfactant protein D major histocompatibility complex, class II, 96.5 210982_s_at D HLA-DRA DR alpha 96.5 221133_s_at D CLDN18 claudin 18 94.4 238222_at GKN2 gastrokine 2 93.7 1557961_s_at D LOC100127983 uncharacterized LOC100127983 93.1 229584_at LRRK2 leucine-rich repeat kinase 2 HOXD cluster antisense RNA 1 (non- 88.6 242042_s_at D HOXD-AS1 protein coding) 86.0 205569_at LAMP3 lysosomal-associated membrane protein 3 85.4 232698_at BPIFB2 BPI fold containing family B, member 2 84.4 205979_at SCGB2A1 secretoglobin, family 2A, member 1 84.3 230469_at RTKN2 rhotekin 2 82.2 204130_at HSD11B2 hydroxysteroid (11-beta) dehydrogenase 2 81.9 222242_s_at KLK5 kallikrein-related peptidase 5 77.0 237281_at AKAP14 A kinase (PRKA) anchor protein 14 76.7 1553602_at MUCL1 mucin-like 1 76.3 216359_at D MUC7 mucin 7, -

Human Induced Pluripotent Stem Cell–Derived Podocytes Mature Into Vascularized Glomeruli Upon Experimental Transplantation
BASIC RESEARCH www.jasn.org Human Induced Pluripotent Stem Cell–Derived Podocytes Mature into Vascularized Glomeruli upon Experimental Transplantation † Sazia Sharmin,* Atsuhiro Taguchi,* Yusuke Kaku,* Yasuhiro Yoshimura,* Tomoko Ohmori,* ‡ † ‡ Tetsushi Sakuma, Masashi Mukoyama, Takashi Yamamoto, Hidetake Kurihara,§ and | Ryuichi Nishinakamura* *Department of Kidney Development, Institute of Molecular Embryology and Genetics, and †Department of Nephrology, Faculty of Life Sciences, Kumamoto University, Kumamoto, Japan; ‡Department of Mathematical and Life Sciences, Graduate School of Science, Hiroshima University, Hiroshima, Japan; §Division of Anatomy, Juntendo University School of Medicine, Tokyo, Japan; and |Japan Science and Technology Agency, CREST, Kumamoto, Japan ABSTRACT Glomerular podocytes express proteins, such as nephrin, that constitute the slit diaphragm, thereby contributing to the filtration process in the kidney. Glomerular development has been analyzed mainly in mice, whereas analysis of human kidney development has been minimal because of limited access to embryonic kidneys. We previously reported the induction of three-dimensional primordial glomeruli from human induced pluripotent stem (iPS) cells. Here, using transcription activator–like effector nuclease-mediated homologous recombination, we generated human iPS cell lines that express green fluorescent protein (GFP) in the NPHS1 locus, which encodes nephrin, and we show that GFP expression facilitated accurate visualization of nephrin-positive podocyte formation in -

Hominin-Specific NOTCH2 Paralogs Expand Human Cortical Neurogenesis
bioRxiv preprint doi: https://doi.org/10.1101/221358; this version posted November 17, 2017. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. Hominin-specific NOTCH2 paralogs expand human cortical neurogenesis through regulation of Delta/Notch interactions. Ikuo K. Suzuki1,2, David Gacquer1, Roxane Van Heurck1,2, Devesh Kumar1,2, Marta Wojno1,2, Angéline Bilheu1,2, Adèle Herpoel1,2, Julian Chéron1,2, Franck Polleux6, Vincent Detours1, and Pierre Vanderhaeghen1,2,3,4,5*. 1 Université Libre de Bruxelles (ULB), Institute for Interdisciplinary Research (IRIBHM), B-1070 Brussels, Belgium 2 ULB Institute of Neuroscience (UNI), B-1070 Brussels, Belgium 3 WELBIO, Université Libre de Bruxelles, B-1070 Brussels, Belgium 4 VIB, Center for Brain and Disease Research, B-3000 Leuven, Belgium 5 University of Leuven (KU Leuven), Department of Neurosciences, B-3000 Leuven, Belgium 6 Department of Neuroscience, Columbia University Medical Center, Columbia University, New York, NY 10027, USA *Correspondence and Lead Contact: [email protected] Keywords Human brain development, human brain evolution, neurogenesis, Notch pathway, cerebral cortex bioRxiv preprint doi: https://doi.org/10.1101/221358; this version posted November 17, 2017. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. Summary The human cerebral cortex has undergone rapid expansion and increased complexity during recent evolution. Hominid-specific gene duplications represent a major driving force of evolution, but their impact on human brain evolution remains unclear. -

Paired Involvement of Human-Specific Olduvai Domains and NOTCH2NL
Human Genetics (2019) 138:715–721 https://doi.org/10.1007/s00439-019-02018-4 ORIGINAL INVESTIGATION Paired involvement of human‑specifc Olduvai domains and NOTCH2NL genes in human brain evolution Ian T. Fiddes1 · Alex A. Pollen2 · Jonathan M. Davis3 · James M. Sikela3 Received: 31 October 2018 / Accepted: 16 April 2019 / Published online: 13 May 2019 © The Author(s) 2019 Abstract Sequences encoding Olduvai (DUF1220) protein domains show the largest human-specifc increase in copy number of any coding region in the genome and have been linked to human brain evolution. Most human-specifc copies of Olduvai (119/165) are encoded by three NBPF genes that are adjacent to three human-specifc NOTCH2NL genes that have been shown to promote cortical neurogenesis. Here, employing genomic, phylogenetic, and transcriptomic evidence, we show that these NOTCH2NL/NBPF gene pairs evolved jointly, as two-gene units, very recently in human evolution, and are likely co-regulated. Remarkably, while three NOTCH2NL paralogs were added, adjacent Olduvai sequences hyper-amplifed, adding 119 human- specifc copies. The data suggest that human-specifc Olduvai domains and adjacent NOTCH2NL genes may function in a coordinated, complementary fashion to promote neurogenesis and human brain expansion in a dosage-related manner. Introduction part of these eforts, genomic factors are beginning to be uncovered that potentially contributed to the evolutionary The increasing availability of primate genomic data is pro- expansion of the human brain (Sikela 2006; O’Bleness et al. viding a unique opportunity to identify lineage-specifc 2012a). While there are a number of genomic mechanisms sequence diferences among human and other primates. -
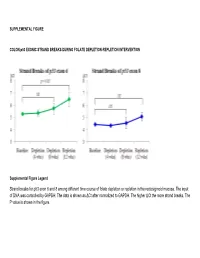
Strand Breaks for P53 Exon 6 and 8 Among Different Time Course of Folate Depletion Or Repletion in the Rectosigmoid Mucosa
SUPPLEMENTAL FIGURE COLON p53 EXONIC STRAND BREAKS DURING FOLATE DEPLETION-REPLETION INTERVENTION Supplemental Figure Legend Strand breaks for p53 exon 6 and 8 among different time course of folate depletion or repletion in the rectosigmoid mucosa. The input of DNA was controlled by GAPDH. The data is shown as ΔCt after normalized to GAPDH. The higher ΔCt the more strand breaks. The P value is shown in the figure. SUPPLEMENT S1 Genes that were significantly UPREGULATED after folate intervention (by unadjusted paired t-test), list is sorted by P value Gene Symbol Nucleotide P VALUE Description OLFM4 NM_006418 0.0000 Homo sapiens differentially expressed in hematopoietic lineages (GW112) mRNA. FMR1NB NM_152578 0.0000 Homo sapiens hypothetical protein FLJ25736 (FLJ25736) mRNA. IFI6 NM_002038 0.0001 Homo sapiens interferon alpha-inducible protein (clone IFI-6-16) (G1P3) transcript variant 1 mRNA. Homo sapiens UDP-N-acetyl-alpha-D-galactosamine:polypeptide N-acetylgalactosaminyltransferase 15 GALNTL5 NM_145292 0.0001 (GALNT15) mRNA. STIM2 NM_020860 0.0001 Homo sapiens stromal interaction molecule 2 (STIM2) mRNA. ZNF645 NM_152577 0.0002 Homo sapiens hypothetical protein FLJ25735 (FLJ25735) mRNA. ATP12A NM_001676 0.0002 Homo sapiens ATPase H+/K+ transporting nongastric alpha polypeptide (ATP12A) mRNA. U1SNRNPBP NM_007020 0.0003 Homo sapiens U1-snRNP binding protein homolog (U1SNRNPBP) transcript variant 1 mRNA. RNF125 NM_017831 0.0004 Homo sapiens ring finger protein 125 (RNF125) mRNA. FMNL1 NM_005892 0.0004 Homo sapiens formin-like (FMNL) mRNA. ISG15 NM_005101 0.0005 Homo sapiens interferon alpha-inducible protein (clone IFI-15K) (G1P2) mRNA. SLC6A14 NM_007231 0.0005 Homo sapiens solute carrier family 6 (neurotransmitter transporter) member 14 (SLC6A14) mRNA. -

Transcriptional Fates of Human-Specific Segmental Duplications in Brain
Downloaded from genome.cshlp.org on September 27, 2021 - Published by Cold Spring Harbor Laboratory Press Method Transcriptional fates of human-specific segmental duplications in brain Max L. Dougherty,1,7 Jason G. Underwood,1,2,7 Bradley J. Nelson,1 Elizabeth Tseng,2 Katherine M. Munson,1 Osnat Penn,1 Tomasz J. Nowakowski,3,4 Alex A. Pollen,5 and Evan E. Eichler1,6 1Department of Genome Sciences, University of Washington School of Medicine, Seattle, Washington 98195, USA; 2Pacific Biosciences (PacBio) of California, Incorporated, Menlo Park, California 94025, USA; 3Department of Anatomy, 4Department of Psychiatry, 5Department of Neurology, University of California, San Francisco, San Francisco, California 94158, USA; 6Howard Hughes Medical Institute, University of Washington, Seattle, Washington 98195, USA Despite the importance of duplicate genes for evolutionary adaptation, accurate gene annotation is often incomplete, in- correct, or lacking in regions of segmental duplication. We developed an approach combining long-read sequencing and hybridization capture to yield full-length transcript information and confidently distinguish between nearly identical genes/paralogs. We used biotinylated probes to enrich for full-length cDNA from duplicated regions, which were then am- plified, size-fractionated, and sequenced using single-molecule, long-read sequencing technology, permitting us to distin- guish between highly identical genes by virtue of multiple paralogous sequence variants. We examined 19 gene families as expressed in developing and adult human brain, selected for their high sequence identity (average >99%) and overlap with human-specific segmental duplications (SDs). We characterized the transcriptional differences between related paralogs to better understand the birth–death process of duplicate genes and particularly how the process leads to gene innovation. -

Human-Specific NOTCH-Like Genes in a Region Linked to Neurodevelopmental Disorders Affect Cortical Neurogenesis
bioRxiv preprint doi: https://doi.org/10.1101/221226; this version posted November 17, 2017. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC 4.0 International license. Human-specific NOTCH-like genes in a region linked to neurodevelopmental disorders affect cortical neurogenesis Authors: Ian T Fiddes1,12, Gerrald A Lodewijk2,12, Meghan Mooring1, Colleen M Bosworth1, Adam D Ewing1#, Gary L Mantalas1,3, Adam M Novak1, Anouk van den Bout2, Alex Bishara4, Jimi L Rosenkrantz1,5, Ryan Lorig-Roach1, Andrew R Field1,3, Maximilian Haeussler1, Lotte Russo2, Aparna Bhaduri6, Tomasz J. Nowakowski6, Alex A. Pollen6, Max L. Dougherty7, Xander Nuttle8, Marie-Claude Addor9, Simon Zwolinski10, Sol Katzman1, Arnold Kriegstein6, Evan E. Eichler7,11, Sofie R Salama1,5,13, Frank MJ Jacobs1,2,13.14*, David Haussler1,5,13,14* Affiliations: 1 UC Santa Cruz Genomics Institute, Santa Cruz, California, United States of America, 2 University of Amsterdam, Swammerdam Institute for Life Sciences, Amsterdam, The Netherlands 3 Molecular, Cell and Developmental Biology, of California Santa Cruz, Santa Cruz, California, United States of America 4 Department of Computer Science and Department of Medicine, Division of Hematology, Stanford University, California, USA 5Howard Hughes Medical Institute, University of California Santa Cruz, Santa Cruz, California, United States of America 6The Eli and Edythe Broad -

Characterizing Genomic Duplication in Autism Spectrum Disorder by Edward James Higginbotham a Thesis Submitted in Conformity
Characterizing Genomic Duplication in Autism Spectrum Disorder by Edward James Higginbotham A thesis submitted in conformity with the requirements for the degree of Master of Science Graduate Department of Molecular Genetics University of Toronto © Copyright by Edward James Higginbotham 2020 i Abstract Characterizing Genomic Duplication in Autism Spectrum Disorder Edward James Higginbotham Master of Science Graduate Department of Molecular Genetics University of Toronto 2020 Duplication, the gain of additional copies of genomic material relative to its ancestral diploid state is yet to achieve full appreciation for its role in human traits and disease. Challenges include accurately genotyping, annotating, and characterizing the properties of duplications, and resolving duplication mechanisms. Whole genome sequencing, in principle, should enable accurate detection of duplications in a single experiment. This thesis makes use of the technology to catalogue disease relevant duplications in the genomes of 2,739 individuals with Autism Spectrum Disorder (ASD) who enrolled in the Autism Speaks MSSNG Project. Fine-mapping the breakpoint junctions of 259 ASD-relevant duplications identified 34 (13.1%) variants with complex genomic structures as well as tandem (193/259, 74.5%) and NAHR- mediated (6/259, 2.3%) duplications. As whole genome sequencing-based studies expand in scale and reach, a continued focus on generating high-quality, standardized duplication data will be prerequisite to addressing their associated biological mechanisms. ii Acknowledgements I thank Dr. Stephen Scherer for his leadership par excellence, his generosity, and for giving me a chance. I am grateful for his investment and the opportunities afforded me, from which I have learned and benefited. I would next thank Drs. -

Chromatin Conformation Links Distal Target Genes to CKD Loci
BASIC RESEARCH www.jasn.org Chromatin Conformation Links Distal Target Genes to CKD Loci Maarten M. Brandt,1 Claartje A. Meddens,2,3 Laura Louzao-Martinez,4 Noortje A.M. van den Dungen,5,6 Nico R. Lansu,2,3,6 Edward E.S. Nieuwenhuis,2 Dirk J. Duncker,1 Marianne C. Verhaar,4 Jaap A. Joles,4 Michal Mokry,2,3,6 and Caroline Cheng1,4 1Experimental Cardiology, Department of Cardiology, Thoraxcenter Erasmus University Medical Center, Rotterdam, The Netherlands; and 2Department of Pediatrics, Wilhelmina Children’s Hospital, 3Regenerative Medicine Center Utrecht, Department of Pediatrics, 4Department of Nephrology and Hypertension, Division of Internal Medicine and Dermatology, 5Department of Cardiology, Division Heart and Lungs, and 6Epigenomics Facility, Department of Cardiology, University Medical Center Utrecht, Utrecht, The Netherlands ABSTRACT Genome-wide association studies (GWASs) have identified many genetic risk factors for CKD. However, linking common variants to genes that are causal for CKD etiology remains challenging. By adapting self-transcribing active regulatory region sequencing, we evaluated the effect of genetic variation on DNA regulatory elements (DREs). Variants in linkage with the CKD-associated single-nucleotide polymorphism rs11959928 were shown to affect DRE function, illustrating that genes regulated by DREs colocalizing with CKD-associated variation can be dysregulated and therefore, considered as CKD candidate genes. To identify target genes of these DREs, we used circular chro- mosome conformation capture (4C) sequencing on glomerular endothelial cells and renal tubular epithelial cells. Our 4C analyses revealed interactions of CKD-associated susceptibility regions with the transcriptional start sites of 304 target genes. Overlap with multiple databases confirmed that many of these target genes are involved in kidney homeostasis. -

Supplementary Table 1 Double Treatment Vs Single Treatment
Supplementary table 1 Double treatment vs single treatment Probe ID Symbol Gene name P value Fold change TC0500007292.hg.1 NIM1K NIM1 serine/threonine protein kinase 1.05E-04 5.02 HTA2-neg-47424007_st NA NA 3.44E-03 4.11 HTA2-pos-3475282_st NA NA 3.30E-03 3.24 TC0X00007013.hg.1 MPC1L mitochondrial pyruvate carrier 1-like 5.22E-03 3.21 TC0200010447.hg.1 CASP8 caspase 8, apoptosis-related cysteine peptidase 3.54E-03 2.46 TC0400008390.hg.1 LRIT3 leucine-rich repeat, immunoglobulin-like and transmembrane domains 3 1.86E-03 2.41 TC1700011905.hg.1 DNAH17 dynein, axonemal, heavy chain 17 1.81E-04 2.40 TC0600012064.hg.1 GCM1 glial cells missing homolog 1 (Drosophila) 2.81E-03 2.39 TC0100015789.hg.1 POGZ Transcript Identified by AceView, Entrez Gene ID(s) 23126 3.64E-04 2.38 TC1300010039.hg.1 NEK5 NIMA-related kinase 5 3.39E-03 2.36 TC0900008222.hg.1 STX17 syntaxin 17 1.08E-03 2.29 TC1700012355.hg.1 KRBA2 KRAB-A domain containing 2 5.98E-03 2.28 HTA2-neg-47424044_st NA NA 5.94E-03 2.24 HTA2-neg-47424360_st NA NA 2.12E-03 2.22 TC0800010802.hg.1 C8orf89 chromosome 8 open reading frame 89 6.51E-04 2.20 TC1500010745.hg.1 POLR2M polymerase (RNA) II (DNA directed) polypeptide M 5.19E-03 2.20 TC1500007409.hg.1 GCNT3 glucosaminyl (N-acetyl) transferase 3, mucin type 6.48E-03 2.17 TC2200007132.hg.1 RFPL3 ret finger protein-like 3 5.91E-05 2.17 HTA2-neg-47424024_st NA NA 2.45E-03 2.16 TC0200010474.hg.1 KIAA2012 KIAA2012 5.20E-03 2.16 TC1100007216.hg.1 PRRG4 proline rich Gla (G-carboxyglutamic acid) 4 (transmembrane) 7.43E-03 2.15 TC0400012977.hg.1 SH3D19