Open Source Systems: Towards Robust Practices
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Netapp Solutions for Hadoop Reference Architecture: Cloudera Faiz Abidi (Netapp) and Udai Potluri (Cloudera) June 2018 | WP-7217
White Paper NetApp Solutions for Hadoop Reference Architecture: Cloudera Faiz Abidi (NetApp) and Udai Potluri (Cloudera) June 2018 | WP-7217 In partnership with Abstract There has been an exponential growth in data over the past decade and analyzing huge amounts of data in a reasonable time can be a challenge. Apache Hadoop is an open- source tool that can help your organization quickly mine big data and extract meaningful patterns from it. However, enterprises face several technical challenges when deploying Hadoop, specifically in the areas of cluster availability, operations, and scaling. NetApp® has developed a reference architecture with Cloudera to deliver a solution that overcomes some of these challenges so that businesses can ingest, store, and manage big data with greater reliability and scalability and with less time spent on operations and maintenance. This white paper discusses a flexible, validated, enterprise-class Hadoop architecture that is based on NetApp E-Series storage using Cloudera’s Hadoop distribution. TABLE OF CONTENTS 1 Introduction ........................................................................................................................................... 4 1.1 Big Data ..........................................................................................................................................................4 1.2 Hadoop Overview ...........................................................................................................................................4 2 NetApp E-Series -

Lecture Notes: the Mathematics of Phylogenetics
Lecture Notes: The Mathematics of Phylogenetics Elizabeth S. Allman, John A. Rhodes IAS/Park City Mathematics Institute June-July, 2005 University of Alaska Fairbanks Spring 2009, 2012, 2016 c 2005, Elizabeth S. Allman and John A. Rhodes ii Contents 1 Sequences and Molecular Evolution 3 1.1 DNA structure . .4 1.2 Mutations . .5 1.3 Aligned Orthologous Sequences . .7 2 Combinatorics of Trees I 9 2.1 Graphs and Trees . .9 2.2 Counting Binary Trees . 14 2.3 Metric Trees . 15 2.4 Ultrametric Trees and Molecular Clocks . 17 2.5 Rooting Trees with Outgroups . 18 2.6 Newick Notation . 19 2.7 Exercises . 20 3 Parsimony 25 3.1 The Parsimony Criterion . 25 3.2 The Fitch-Hartigan Algorithm . 28 3.3 Informative Characters . 33 3.4 Complexity . 35 3.5 Weighted Parsimony . 36 3.6 Recovering Minimal Extensions . 38 3.7 Further Issues . 39 3.8 Exercises . 40 4 Combinatorics of Trees II 45 4.1 Splits and Clades . 45 4.2 Refinements and Consensus Trees . 49 4.3 Quartets . 52 4.4 Supertrees . 53 4.5 Final Comments . 54 4.6 Exercises . 55 iii iv CONTENTS 5 Distance Methods 57 5.1 Dissimilarity Measures . 57 5.2 An Algorithmic Construction: UPGMA . 60 5.3 Unequal Branch Lengths . 62 5.4 The Four-point Condition . 66 5.5 The Neighbor Joining Algorithm . 70 5.6 Additional Comments . 72 5.7 Exercises . 73 6 Probabilistic Models of DNA Mutation 81 6.1 A first example . 81 6.2 Markov Models on Trees . 87 6.3 Jukes-Cantor and Kimura Models . -

Desktop Migration and Administration Guide
Red Hat Enterprise Linux 7 Desktop Migration and Administration Guide GNOME 3 desktop migration planning, deployment, configuration, and administration in RHEL 7 Last Updated: 2021-05-05 Red Hat Enterprise Linux 7 Desktop Migration and Administration Guide GNOME 3 desktop migration planning, deployment, configuration, and administration in RHEL 7 Marie Doleželová Red Hat Customer Content Services [email protected] Petr Kovář Red Hat Customer Content Services [email protected] Jana Heves Red Hat Customer Content Services Legal Notice Copyright © 2018 Red Hat, Inc. This document is licensed by Red Hat under the Creative Commons Attribution-ShareAlike 3.0 Unported License. If you distribute this document, or a modified version of it, you must provide attribution to Red Hat, Inc. and provide a link to the original. If the document is modified, all Red Hat trademarks must be removed. Red Hat, as the licensor of this document, waives the right to enforce, and agrees not to assert, Section 4d of CC-BY-SA to the fullest extent permitted by applicable law. Red Hat, Red Hat Enterprise Linux, the Shadowman logo, the Red Hat logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries. Linux ® is the registered trademark of Linus Torvalds in the United States and other countries. Java ® is a registered trademark of Oracle and/or its affiliates. XFS ® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries. MySQL ® is a registered trademark of MySQL AB in the United States, the European Union and other countries. -
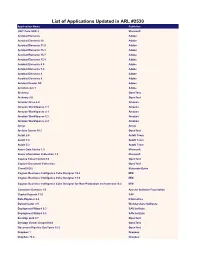
List of Applications Updated in ARL #2530
List of Applications Updated in ARL #2530 Application Name Publisher .NET Core SDK 2 Microsoft Acrobat Elements Adobe Acrobat Elements 10 Adobe Acrobat Elements 11.0 Adobe Acrobat Elements 15.1 Adobe Acrobat Elements 15.7 Adobe Acrobat Elements 15.9 Adobe Acrobat Elements 6.0 Adobe Acrobat Elements 7.0 Adobe Application Name Acrobat Elements 8 Adobe Acrobat Elements 9 Adobe Acrobat Reader DC Adobe Acrobat.com 1 Adobe Alchemy OpenText Alchemy 9.0 OpenText Amazon Drive 4.0 Amazon Amazon WorkSpaces 1.1 Amazon Amazon WorkSpaces 2.1 Amazon Amazon WorkSpaces 2.2 Amazon Amazon WorkSpaces 2.3 Amazon Ansys Ansys Archive Server 10.1 OpenText AutoIt 2.6 AutoIt Team AutoIt 3.0 AutoIt Team AutoIt 3.2 AutoIt Team Azure Data Studio 1.9 Microsoft Azure Information Protection 1.0 Microsoft Captiva Cloud Toolkit 3.0 OpenText Capture Document Extraction OpenText CloneDVD 2 Elaborate Bytes Cognos Business Intelligence Cube Designer 10.2 IBM Cognos Business Intelligence Cube Designer 11.0 IBM Cognos Business Intelligence Cube Designer for Non-Production environment 10.2 IBM Commons Daemon 1.0 Apache Software Foundation Crystal Reports 11.0 SAP Data Explorer 8.6 Informatica DemoCreator 3.5 Wondershare Software Deployment Wizard 9.3 SAS Institute Deployment Wizard 9.4 SAS Institute Desktop Link 9.7 OpenText Desktop Viewer Unspecified OpenText Document Pipeline DocTools 10.5 OpenText Dropbox 1 Dropbox Dropbox 73.4 Dropbox Dropbox 74.4 Dropbox Dropbox 75.4 Dropbox Dropbox 76.4 Dropbox Dropbox 77.4 Dropbox Dropbox 78.4 Dropbox Dropbox 79.4 Dropbox Dropbox 81.4 -

NETS1028 06 Backup and Change Mgmt
Security Design Backup and Change Management System Examination System Configuration Firewalls and Filters Hardening Software Backups and Change Management Access Control and Authentication Virtual Private Networking Logging and Monitoring Security Policy and Management Support SELinux Linux Systems Security NETS1028 LINUX SYSTEMS SECURITY - DENNIS SIMPSON ©2015-2021 Backup • Security breaches can cast doubt on entire installations or render them corrupt • Files or entire systems may have to be recovered from backup • Many tools are available to help with this task in Linux • Two of the more commonly used ones are rsync and duplicity https://en.wikipedia.org/wiki/Rsync http://duplicity.nongnu.org/features.html NETS1028 LINUX SYSTEMS SECURITY - DENNIS SIMPSON ©2015-2021 Legacy Tools • cp is the original way to make a copy of files, but assumptions people make cause problems in using it • GUI-based drag and drop tools make the assumptions problem worse • cpio, tar are archival tools created to copy files to backup media (tape by default) - satisfactory for years but they make it cumbersome to manage backup media https://en.wikipedia.org/wiki/Manuscript_culture • Various software packages provide frontends to these tools in order to make backup/restore easier to manage and more robust NETS1028 LINUX SYSTEMS SECURITY - DENNIS SIMPSON ©2015-2021 Rsync • Rsync has a command line interface which resembles a smart cp, and provides a base for many backup software packages with GUIs • Can preserve special files such as links and devices • Can copy -

KDE Free Qt Foundation Strengthens Qt
How the KDE Free Qt Foundation strengthens Qt by Olaf Schmidt-Wischhöfer (board member of the foundation)1, December 2019 Executive summary The development framework Qt is available both as Open Source and under paid license terms. Two decades ago, when Qt 2.0 was first released as Open Source, this was excep- tional. Today, most popular developing frameworks are Free/Open Source Software2. Without the dual licensing approach, Qt would not exist today as a popular high-quality framework. There is another aspect of Qt licensing which is still very exceptional today, and which is not as well-known as it ought to be. The Open Source availability of Qt is legally protected through the by-laws and contracts of a foundation. 1 I thank Eike Hein, board member of KDE e.V., for contributing. 2 I use the terms “Open Source” and “Free Software” interchangeably here. Both have a long history, and the exact differences between them do not matter for the purposes of this text. How the KDE Free Qt Foundation strengthens Qt 2 / 19 The KDE Free Qt Foundation was created in 1998 and guarantees the continued availabil- ity of Qt as Free/Open Source Software3. When it was set up, Qt was developed by Troll- tech, its original company. The foundation supported Qt through the transitions first to Nokia and then to Digia and to The Qt Company. In case The Qt Company would ever attempt to close down Open Source Qt, the founda- tion is entitled to publish Qt under the BSD license. This notable legal guarantee strengthens Qt. -

Licensing Information User Manual Release 9.1 F13415-01
Oracle® Hospitality Cruise Fleet Management Licensing Information User Manual Release 9.1 F13415-01 August 2019 LICENSING INFORMATION USER MANUAL Oracle® Hospitality Fleet Management Licensing Information User Manual Version 9.1 Copyright © 2004, 2019, Oracle and/or its affiliates. All rights reserved. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error- free. If you find any errors, please report them to us in writing. If this software or related documentation is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, delivered to U.S. Government end users are "commercial computer software" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, use, duplication, disclosure, modification, and adaptation of the programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, shall be subject to license terms and license restrictions applicable to the programs. -

Release Notes for Fedora 15
Fedora 15 Release Notes Release Notes for Fedora 15 Edited by The Fedora Docs Team Copyright © 2011 Red Hat, Inc. and others. The text of and illustrations in this document are licensed by Red Hat under a Creative Commons Attribution–Share Alike 3.0 Unported license ("CC-BY-SA"). An explanation of CC-BY-SA is available at http://creativecommons.org/licenses/by-sa/3.0/. The original authors of this document, and Red Hat, designate the Fedora Project as the "Attribution Party" for purposes of CC-BY-SA. In accordance with CC-BY-SA, if you distribute this document or an adaptation of it, you must provide the URL for the original version. Red Hat, as the licensor of this document, waives the right to enforce, and agrees not to assert, Section 4d of CC-BY-SA to the fullest extent permitted by applicable law. Red Hat, Red Hat Enterprise Linux, the Shadowman logo, JBoss, MetaMatrix, Fedora, the Infinity Logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries. For guidelines on the permitted uses of the Fedora trademarks, refer to https:// fedoraproject.org/wiki/Legal:Trademark_guidelines. Linux® is the registered trademark of Linus Torvalds in the United States and other countries. Java® is a registered trademark of Oracle and/or its affiliates. XFS® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries. MySQL® is a registered trademark of MySQL AB in the United States, the European Union and other countries. All other trademarks are the property of their respective owners. -
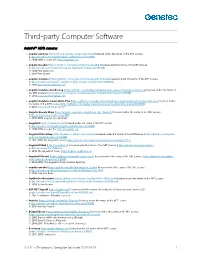
Software License Agreement (EULA)
Third-party Computer Software AutoVu™ ALPR cameras • angular-animate (https://docs.angularjs.org/api/ngAnimate) licensed under the terms of the MIT License (https://github.com/angular/angular.js/blob/master/LICENSE). © 2010-2016 Google, Inc. http://angularjs.org • angular-base64 (https://github.com/ninjatronic/angular-base64) licensed under the terms of the MIT License (https://github.com/ninjatronic/angular-base64/blob/master/LICENSE). © 2010 Nick Galbreath © 2013 Pete Martin • angular-translate (https://github.com/angular-translate/angular-translate) licensed under the terms of the MIT License (https://github.com/angular-translate/angular-translate/blob/master/LICENSE). © 2014 [email protected] • angular-translate-handler-log (https://github.com/angular-translate/bower-angular-translate-handler-log) licensed under the terms of the MIT License (https://github.com/angular-translate/angular-translate/blob/master/LICENSE). © 2014 [email protected] • angular-translate-loader-static-files (https://github.com/angular-translate/bower-angular-translate-loader-static-files) licensed under the terms of the MIT License (https://github.com/angular-translate/angular-translate/blob/master/LICENSE). © 2014 [email protected] • Angular Google Maps (http://angular-ui.github.io/angular-google-maps/#!/) licensed under the terms of the MIT License (https://opensource.org/licenses/MIT). © 2013-2016 angular-google-maps • AngularJS (http://angularjs.org/) licensed under the terms of the MIT License (https://github.com/angular/angular.js/blob/master/LICENSE). © 2010-2016 Google, Inc. http://angularjs.org • AngularUI Bootstrap (http://angular-ui.github.io/bootstrap/) licensed under the terms of the MIT License (https://github.com/angular- ui/bootstrap/blob/master/LICENSE). -

Inequalities in Open Source Software Development: Analysis of Contributor’S Commits in Apache Software Foundation Projects
RESEARCH ARTICLE Inequalities in Open Source Software Development: Analysis of Contributor’s Commits in Apache Software Foundation Projects Tadeusz Chełkowski1☯, Peter Gloor2☯*, Dariusz Jemielniak3☯ 1 Kozminski University, Warsaw, Poland, 2 Massachusetts Institute of Technology, Center for Cognitive Intelligence, Cambridge, Massachusetts, United States of America, 3 Kozminski University, New Research on Digital Societies (NeRDS) group, Warsaw, Poland ☯ These authors contributed equally to this work. * [email protected] a11111 Abstract While researchers are becoming increasingly interested in studying OSS phenomenon, there is still a small number of studies analyzing larger samples of projects investigating the structure of activities among OSS developers. The significant amount of information that OPEN ACCESS has been gathered in the publicly available open-source software repositories and mailing- list archives offers an opportunity to analyze projects structures and participant involve- Citation: Chełkowski T, Gloor P, Jemielniak D (2016) Inequalities in Open Source Software Development: ment. In this article, using on commits data from 263 Apache projects repositories (nearly Analysis of Contributor’s Commits in Apache all), we show that although OSS development is often described as collaborative, but it in Software Foundation Projects. PLoS ONE 11(4): fact predominantly relies on radically solitary input and individual, non-collaborative contri- e0152976. doi:10.1371/journal.pone.0152976 butions. We also show, in the first published study of this magnitude, that the engagement Editor: Christophe Antoniewski, CNRS UMR7622 & of contributors is based on a power-law distribution. University Paris 6 Pierre-et-Marie-Curie, FRANCE Received: December 15, 2015 Accepted: March 22, 2016 Published: April 20, 2016 Copyright: © 2016 Chełkowski et al. -

Groups and Activities Report 2017
Groups and Activities Report 2017 ISBN 978-92-9083-491-5 This report is released under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License. 2 | Page CERN IT Department Groups and Activities Report 2017 CONTENTS GROUPS REPORTS 2017 Collaborations, Devices & Applications (CDA) Group ............................................................................. 6 Communication Systems (CS) Group .................................................................................................... 11 Compute & Monitoring (CM) Group ..................................................................................................... 16 Computing Facilities (CF) Group ........................................................................................................... 20 Databases (DB) Group ........................................................................................................................... 23 Departmental Infrastructure (DI) Group ............................................................................................... 27 Storage (ST) Group ................................................................................................................................ 28 ACTIVITIES AND PROJECTS REPORTS 2017 CERN openlab ........................................................................................................................................ 34 CERN School of Computing (CSC) ......................................................................................................... -

Exploring Factors and Measures to Select Open Source Software
Exploring Factors and Measures to Select Open Source Software Xiaozhou Li*a, Sergio Moreschini*a, Zheying Zhanga, Davide Taibia aTampere University, Tampere (Finland) ∗ the two authors equally contributed to the paper Abstract [Context] Open Source Software (OSS) is nowadays used and integrated in most of the commercial products. However, the selection of OSS projects for integration is not a simple process, mainly due to a of lack of clear selection models and lack of information from the OSS portals. [Objective] We investigated the current factors and measures that prac- titioners are currently considering when selecting OSS, the source of infor- mation and portals that can be used to assess the factors, and the possibility to automatically get this information with APIs. [Method] We elicited the factors and the measures adopted to assess and compare OSS performing a survey among 23 experienced developers who often integrate OSS in the software they develop. Moreover, we investigated the APIs of the portals adopted to assess OSS extracting information for the most starred 100K projects in GitHub. [Result] We identified a set consisting of 8 main factors and 74 sub- factors, together with 170 related metrics that companies can use to select OSS to be integrated in their software projects. Unexpectedly, only a small part of the factors can be evaluated automatically, and out of 170 metrics, only 40 are available, of which only 22 returned information for all the 100K projects. [Conclusion.] OSS selection can be partially automated, by extracting arXiv:2102.09977v1 [cs.SE] 19 Feb 2021 the information needed for the selection from portal APIs.