Explorations in the Grid/WS Computing Jungle
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Open Source Used in Cisco Unity Connection 11.5 SU 1
Open Source Used In Cisco Unity Connection 11.5 SU 1 Cisco Systems, Inc. www.cisco.com Cisco has more than 200 offices worldwide. Addresses, phone numbers, and fax numbers are listed on the Cisco website at www.cisco.com/go/offices. Text Part Number: 78EE117C99-132949842 Open Source Used In Cisco Unity Connection 11.5 SU 1 1 This document contains licenses and notices for open source software used in this product. With respect to the free/open source software listed in this document, if you have any questions or wish to receive a copy of any source code to which you may be entitled under the applicable free/open source license(s) (such as the GNU Lesser/General Public License), please contact us at [email protected]. In your requests please include the following reference number 78EE117C99-132949842 Contents 1.1 ace 5.3.5 1.1.1 Available under license 1.2 Apache Commons Beanutils 1.6 1.2.1 Notifications 1.2.2 Available under license 1.3 Apache Derby 10.8.1.2 1.3.1 Available under license 1.4 Apache Mina 2.0.0-RC1 1.4.1 Available under license 1.5 Apache Standards Taglibs 1.1.2 1.5.1 Available under license 1.6 Apache STRUTS 1.2.4. 1.6.1 Available under license 1.7 Apache Struts 1.2.9 1.7.1 Available under license 1.8 Apache Xerces 2.6.2. 1.8.1 Notifications 1.8.2 Available under license 1.9 axis2 1.3 1.9.1 Available under license 1.10 axis2/cddl 1.3 1.10.1 Available under license 1.11 axis2/cpl 1.3 1.11.1 Available under license 1.12 BeanUtils(duplicate) 1.6.1 1.12.1 Notifications Open Source Used In Cisco Unity Connection -

Roller: an Open Source Javatm Ee Blogging Platform
ROLLER: AN OPEN SOURCE JAVATM EE BLOGGING PLATFORM • Dave Johnson – Staff Engineer S/W – Sun Microsystems, Inc. Agenda • Roller history • Roller features • Roller community • Roller internals: backend • Roller internals: frontend • Customizing Roller • Roller futures Roller started as an EJB example... • Homeport – a home page / portal (2001) ... became an O'Reilly article • Ditched EJBs and HAHTsite IDE (2002) • Used all open source tools instead and thus... ... and escaped into the wild I am allowing others to use my installation of Roller for their weblogging. Hopefully this will provide a means for enhancing the Roller user base as well as provide a nice environment for communication and expression. Anthony Eden August 8, 2002 ... to find a new home at Apache • Apache Roller (incubating) – Incubation period: June 2005 - ??? Agenda • Roller history • Roller features • Roller community • Roller internals: backend • Roller internals: frontend • Customizing Roller • Roller futures Roller features: standard blog stuff • Individual and group blogs • Hierarchical categories • Comments, trackbacks and referrers • File-upload and Podcasting support • User editable page templates • RSS and Atom feeds • Blog client support (Blogger/MetaWeblog API) • Built-in search engine Multiple blogs per user Multiple users per blog Blog client support • XML-RPC based Blogger and MetaWeblog API • Lots of blog clients work with Roller, for example: ecto http://ecto.kung-foo.tv For Mac OSX and Windows Roller 3.0: What's new • Big new release, 3 months in dev -

Return of Organization Exempt from Income
OMB No. 1545-0047 Return of Organization Exempt From Income Tax Form 990 Under section 501(c), 527, or 4947(a)(1) of the Internal Revenue Code (except black lung benefit trust or private foundation) Open to Public Department of the Treasury Internal Revenue Service The organization may have to use a copy of this return to satisfy state reporting requirements. Inspection A For the 2011 calendar year, or tax year beginning 5/1/2011 , and ending 4/30/2012 B Check if applicable: C Name of organization The Apache Software Foundation D Employer identification number Address change Doing Business As 47-0825376 Name change Number and street (or P.O. box if mail is not delivered to street address) Room/suite E Telephone number Initial return 1901 Munsey Drive (909) 374-9776 Terminated City or town, state or country, and ZIP + 4 Amended return Forest Hill MD 21050-2747 G Gross receipts $ 554,439 Application pending F Name and address of principal officer: H(a) Is this a group return for affiliates? Yes X No Jim Jagielski 1901 Munsey Drive, Forest Hill, MD 21050-2747 H(b) Are all affiliates included? Yes No I Tax-exempt status: X 501(c)(3) 501(c) ( ) (insert no.) 4947(a)(1) or 527 If "No," attach a list. (see instructions) J Website: http://www.apache.org/ H(c) Group exemption number K Form of organization: X Corporation Trust Association Other L Year of formation: 1999 M State of legal domicile: MD Part I Summary 1 Briefly describe the organization's mission or most significant activities: to provide open source software to the public that we sponsor free of charge 2 Check this box if the organization discontinued its operations or disposed of more than 25% of its net assets. -

Reading the Runes for Java Runtimes the Latest IBM Java Sdks
Java Technology Centre Reading the runes for Java runtimes The latest IBM Java SDKs ... and beyond Tim Ellison [email protected] © 2009 IBM Corporation Java Technology Centre Goals . IBM and Java . Explore the changing landscape of hardware and software influences . Discuss the impact to Java runtime technology due to these changes . Show how IBM is leading the way with these changes 2 Mar 9, 2009 © 2009 IBM Corporation Java Technology Centre IBM and Java . Java is critically important to IBM – Provides fundamental infrastructure to IBM software portfolio – Delivers standard development environment – Enables cost effective multi platform support – Delivered to Independent Software Vendors supporting IBM server platforms . IBM is investing strategically in virtual machine technology – Since Java 5.0, a single Java platform technology supports ME, SE and EE – Technology base on which to delivery improved performance, reliability and serviceability • Some IBM owned code (Virtual machine, JIT compiler, ...) • Some open source code (Apache XML parser, Apache Core libraries, Zlib, ...) • Some Sun licensed code (class libraries, tools, ...) . Looking to engender accelerated and open innovation in runtime technologies – Support for Eclipse, Apache (Harmony, XML, Derby, Geronimo, Tuscany) – Broad participation of relevant standards bodies such as JCP and OSGi 3 Mar 9, 2009 © 2009 IBM Corporation Java Technology Centre IBM Java – 2009 key initiatives . Consumability – Deliver value without complexity. – Ensure that problems with our products can be addressed quickly, allowing customers to keep focus on their own business issues. – Deliver a consistent model for solving customer problems. “Scaling Up” - Emerging hardware and applications – Provide a Java implementation that can scale to the most demanding application needs. -

Xerox® Igen™ 150 Press 3 Party Software License Disclosure
Xerox® iGen™ 150 Press 3rd Party Software License Disclosure October 2013 The following software packages are copyrighted for use in this product according to the license stated. Full terms and conditions of all 3rd party software licenses are available from the About screen under the Help menu on the Press Interface or by accessing the Support & Drivers page located on the http://www.xerox.com website. Adobe Icons and Web Logos, license: Adobe Icons and Web Logos License Apache log4j 1.2.8, Apache log4j 1.2.9, Apache Web Services XML-RPC 1.2.b1, Apache Lucene Java 1.3, Apache Tomcat 4.1.27, license: Apache License 1.1 Apache Axis 1.x 1.4, Apache Jakarta Commons HttpClient 3.0.alpha1, Apache Jakarta Commons Logging 1.0.4, Apache Jakarta Lucene 1.9.1, Apache XML Security Java 1.3.0, saxpath 1.0 FCS, Skin Look And Feel (skinlf) 1.2.8, Spring Framework Utilities 0.7, Apache Web Services Axis 1.2rc3, Apache Xerces Java XML Parser 2.7.1, Apache XML Xalan-Java 2.7.0, Jetty - Java HTTP Servlet Server 4.0.D0, Lucene Snowball, Streaming API for XML (StAX) - JSR-173 20040819, license: Apache License 2.0 Perl 5.8.5, Perl 5.10.0, AppConfig-1.66, Archive-Tar-1.58, Compress::Zlib-2.020, Expect.pm- 1.21, File-NCopy-0.36, File-NFSLock-1.20, Filesys-Df-0.92, Filesys-DiskFree-0.06, HTML- Parser-3.69, HTML-Tagset-3.20, HTML-Template-2.9, IO-Stty-0.02, IO-Tty-1.08, IO-Zlib- 1.09, libxml-perl-0.08, Net-Netmask-1.9015, Net-Telnet-3.03, perl-5.8.3, perlindex-1.605, Pod- Escapes-1.04, Pod-POM-0.25, Pod-Simple-3.13, Proc-ProcessTable-0.45, Socket6-0.23, Stat- -

TU07 XML at The
ApacheCon 2004 November 2004 XML at the ASF Ted Leung [email protected] Copyright © Sauria Associates, LLC 2004 1 ApacheCon 2004 November 2004 Overview xml.apache.org ws.apache.org Xerces XML-RPC Xalan Axis FOP WSIF Batik JaxMe Xindice cocoon.apache.org Forrest XML-Security Cocoon XML-Commons Lenya XMLBeans Copyright © Sauria Associates, LLC ApacheCon 2004 2 There are three major XML focused projects at the ASF. Originally there was one project, xml.apache.org. Earlier this year, the Cocoon and web services projects were formed. Xml.apache.org contains a number of projects that are general purpose XML tools. Most of these tools are based on specifications from the World Wide Web Consortium. This includes XML itself, XSLT, XSL Formatting object, Scalable Vector Graphics, and XML Signature and XML Encryption The web services project, ws.apache.org contains projects that cluster around standards for dealing with Web Services, including SOAP and XML-RPC The Cocoon project is oriented around the Cocoon Web publishing framework which is basd on XML, XSLT, and a number of other XML related technologies. I’m not going to be able to give you any deep technical details regarding all of these projects. Instead, I’m going to try to describe what these projects are, what standards they implement, and talk about situations where you might use them. Unless I say otherwise, I’m going to be covering the Java projects. There are a few projects which have C/C++ versions and I’ll mention that where applicable. Copyright © Sauria Associates, -

Full-Graph-Limited-Mvn-Deps.Pdf
org.jboss.cl.jboss-cl-2.0.9.GA org.jboss.cl.jboss-cl-parent-2.2.1.GA org.jboss.cl.jboss-classloader-N/A org.jboss.cl.jboss-classloading-vfs-N/A org.jboss.cl.jboss-classloading-N/A org.primefaces.extensions.master-pom-1.0.0 org.sonatype.mercury.mercury-mp3-1.0-alpha-1 org.primefaces.themes.overcast-${primefaces.theme.version} org.primefaces.themes.dark-hive-${primefaces.theme.version}org.primefaces.themes.humanity-${primefaces.theme.version}org.primefaces.themes.le-frog-${primefaces.theme.version} org.primefaces.themes.south-street-${primefaces.theme.version}org.primefaces.themes.sunny-${primefaces.theme.version}org.primefaces.themes.hot-sneaks-${primefaces.theme.version}org.primefaces.themes.cupertino-${primefaces.theme.version} org.primefaces.themes.trontastic-${primefaces.theme.version}org.primefaces.themes.excite-bike-${primefaces.theme.version} org.apache.maven.mercury.mercury-external-N/A org.primefaces.themes.redmond-${primefaces.theme.version}org.primefaces.themes.afterwork-${primefaces.theme.version}org.primefaces.themes.glass-x-${primefaces.theme.version}org.primefaces.themes.home-${primefaces.theme.version} org.primefaces.themes.black-tie-${primefaces.theme.version}org.primefaces.themes.eggplant-${primefaces.theme.version} org.apache.maven.mercury.mercury-repo-remote-m2-N/Aorg.apache.maven.mercury.mercury-md-sat-N/A org.primefaces.themes.ui-lightness-${primefaces.theme.version}org.primefaces.themes.midnight-${primefaces.theme.version}org.primefaces.themes.mint-choc-${primefaces.theme.version}org.primefaces.themes.afternoon-${primefaces.theme.version}org.primefaces.themes.dot-luv-${primefaces.theme.version}org.primefaces.themes.smoothness-${primefaces.theme.version}org.primefaces.themes.swanky-purse-${primefaces.theme.version} -

Apache Axis Architektur Und Erweiterbarkeit
Apache Axis Architektur und Erweiterbarkeit AUTOR Thomas Bayer ) Schulung ) Orientation in Objects GmbH Veröffentlicht am: 23.9.2003 ABSTRACT Die SOAP Implementierung Apache Axis hat sich zu einem wichtigen Tool und ) Beratung ) Framework für Web Services in der Java-Welt entwickelt. Sein Design wurde von Grund auf neu gestaltet und basiert auf Handlern und dem SAX API. Dieser Artikel führt den Web Service und SOAP kundigen Leser in die Architektur von Axis ein und beschreibt, wie Axis mit eigener Funktionalität am Beispiel eines Handlers für signierte Nachrichten und eines Providers für Stored Procedures erweitert werden kann. ) Entwicklung ) ) Artikel ) Trivadis Germany GmbH Weinheimer Str. 68 D-68309 Mannheim Tel. +49 (0) 6 21 - 7 18 39 - 0 Fax +49 (0) 6 21 - 7 18 39 - 50 [email protected] Java, XML, UML, XSLT, Open Source, JBoss, SOAP, CVS, Spring, JSF, Eclipse ERWEITERN VON AXIS MIT HANDLERN UND PROVIDERN Axis stellt eine typische Web Anwendung dar, die in Form eines Web-Archives in einen Servlet 2.2 konformen Web Container wie z.B. Tomcat oder Jetty installiert werden kann. Das Web-Archiv enthält drei Servlets für die Laufzeit, die Administration und für das Verfolgen von SOAP Aufrufen wie in Abbildung 1 dargestellt. Abbildung 2: Subsysteme Von grundlegender Bedeutung sind Nachrichten und Handler. Nachrichten durchlaufen in Form eines MessageContext die einzelnen Subsysteme. MESSAGECONTEXT Abbildung 1: Axis im Web Container Der MessageContext ist, wie aus Abbildung 3 ersichtlich, eine Die benötigten Klassen befinden sich in Jar-Dateien im Struktur, die Referenzen auf die Request- und Response Nachricht lib-Verzeichnis. Das classes- sowie das lib-Verzeichnis können sowie auf eine Reihe von Attributen beinhaltet. -
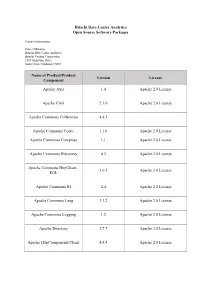
Hitachi Data Center Analytics Open Source Software Packages
Hitachi Data Center Analytics Open Source Software Packages Contact Information: Project Manager Hitachi Data Center Analytics Hitachi Vantara Corporation 2535 Augustine Drive Santa Clara, California 95054 Name of Product/Product Version License Component Apache Axis 1.4 Apache 2.0 License Apache Click 2.3.0 Apache 2.0 License Apache Commons Collections 4.4.1 Apache Commons Codec 1.10 Apache 2.0 License Apache Commons Compress 1.1 Apache 2.0 License Apache Commons Discovery 0.2 Apache 2.0 License Apache Commons HttpClient - 3.0.1 Apache 2.0 License EOL Apache Commons IO 2.4 Apache 2.0 License Apache Commons Lang 3.3.2 Apache 2.0 License Apache Commons Logging 1.2 Apache 2.0 License Apache Directory 2.7.7 Apache 2.0 License Apache HttpComponents Client 4.4.4 Apache 2.0 License Name of Product/Product Version License Component Apache HttpComponents 5.5.2 Apache 2.0 License Apache Log4j 1.2.17 Apache 2.0 License Apache Log4net 1.2.10 Apache 2.0 License Apache PDF Box 2.0.2 Apache 2.0 License Apache POI 3.15 Apache 2.0 License Apache Thrift 0.9.1 Apache 2.0 License Apache Web Services 1.0.2 Apache 2.0 License Apache Xerces Java Parser 2.9.0 Apache 2.0 License Apache XML Graphics 1.4 Apache 2.0 License Apache XML-RPC 3.1 Apache 2.0 License Apache XMLBeans 2.6.0 Apache 2.0 License Bouncy Castle Crypto API 1.45.0 MIT license CHILKAT CRYPT 9.5.0 Paid click-calendar 1.3.0 Apache 2.0 License Customized log4j File Appender Apache 2.0 License docx4j 2.7.0 Apache 2.0 License Name of Product/Product Version License Component dom4j 1.6.1 Apache 2.0 -

Configuring Apache Tomcat
SDL Collaborative Review installation guide Collaborative Review 7.7.0 November 2018 Legal notice Copyright and trademark information relating to this product release. Copyright © 2003–2017 SDL Group. SDL Group means SDL PLC. and its subsidiaries and affiliates. All intellectual property rights contained herein are the sole and exclusive rights of SDL Group. All references to SDL or SDL Group shall mean SDL PLC. and its subsidiaries and affiliates details of which can be obtained upon written request. All rights reserved. Unless explicitly stated otherwise, all intellectual property rights including those in copyright in the content of this website and documentation are owned by or controlled for these purposes by SDL Group. Except as otherwise expressly permitted hereunder or in accordance with copyright legislation, the content of this site, and/or the documentation may not be copied, reproduced, republished, downloaded, posted, broadcast or transmitted in any way without the express written permission of SDL. SDL Tridion Docs is a registered trademark of SDL Group. All other trademarks are the property of their respective owners. The names of other companies and products mentioned herein may be the trade- marks of their respective owners. Unless stated to the contrary, no association with any other company or product is intended or should be inferred. This product may include open source or similar third-party software, details of which can be found by clicking the following link: “Acknowledgments” on page 2. Although SDL Group takes all reasonable measures to provide accurate and comprehensive information about the product, this information is provided as-is and all warranties, conditions or other terms concerning the documentation whether express or implied by statute, common law or otherwise (including those relating to satisfactory quality and fitness for purposes) are excluded to the extent permitted by law. -

Fairplay License Server
Open Source Used In Fairplay DRM License 1.0.4 Cisco Systems, Inc. www.cisco.com Cisco has more than 200 offices worldwide. Addresses, phone numbers, and fax numbers are listed on the Cisco website at www.cisco.com/go/offices. Text Part Number: 78EE117C99-142022930 Open Source Used In Fairplay DRM License 1.0.4 1 This document contains licenses and notices for open source software used in this product. With respect to the free/open source software listed in this document, if you have any questions or wish to receive a copy of any source code to which you may be entitled under the applicable free/open source license(s) (such as the GNU Lesser/General Public License), please contact us at [email protected]. In your requests please include the following reference number 78EE117C99-142022930 Contents 1.1 Apache Commons Codec 1.3. 1.1.1 Available under license 1.2 Apache Commons Lib Apache 2.0 1.2.1 Available under license 1.3 Apache Commons Lib Apache 2.0 1.3.1 Available under license 1.4 Apache Derby 10.10.1.1 1.4.1 Available under license 1.5 Apache HTTP Server 2.2.9 1.5.1 Available under license 1.6 Apache Jakarta Commons Configuration 1.9 1.6.1 Available under license 1.7 Apache Jakarta Commons HttpClient 3.1 1.7.1 Available under license 1.8 Apache Jakarta Commons Lang 3.1 1.8.1 Available under license 1.9 Apache Log4j 1.2.16 1.9.1 Available under license 1.10 apache-log4j 1.2.15 1.10.1 Available under license 1.11 apache-log4j 1.2.15 :DUPLICATE 1.11.1 Available under license 1.12 args4j 2.0.12 1.12.1 Available under -

HCP-DM Third-Party Copyrights and Licenses
Hitachi Content Platform 7.3.0 HCP-DM Third-Party Copyrights and Licenses HCP Data Migrator (HCP-DM) software incorporates third-party software from a number of vendors. This book contains the copyright and license information for that software. MK-90ARC030-06 August 2017 © 2010, 2017 Hitachi Data Systems Corporation. All rights reserved. No part of this publication may be reproduced or transmitted in any form or by any means, electronic or mechanical, including photocopying and recording, or stored in a database or retrieval system for any purpose without the express written permission of Hitachi Data Systems Corporation (hereinafter referred to as “Hitachi Data Systems”) except that recipients may copy open source licenses and copyright notices without additional permission. Hitachi Data Systems reserves the right to make changes to this document at any time without notice and assumes no responsibility for its use. This document contains the most current information available at the time of publication. When new and/or revised information becomes available, this entire document will be updated and distributed to all registered users. Some of the features described in this document may not be currently available. Refer to the most recent product announcement or contact Hitachi Data Systems for information about feature and product availability. Notice: Hitachi Data Systems products and services can be ordered only under the terms and conditions of the applicable Hitachi Data Systems agreements. The use of Hitachi Data Systems products is governed by the terms of your agreements with Hitachi Data Systems. By using this software, you agree that you are responsible for: a) Acquiring the relevant consents as may be required under local privacy laws or otherwise from employees and other individuals to access relevant data; and b) Ensuring that data continues to be held, retrieved, deleted, or otherwise processed in accordance with relevant laws.