Toward Improved Traceability of Safety Requirements and State-Based Design Models
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

OMG Systems Modeling Language (OMG Sysml™) Tutorial 25 June 2007
OMG Systems Modeling Language (OMG SysML™) Tutorial 25 June 2007 Sanford Friedenthal Alan Moore Rick Steiner (emails included in references at end) Copyright © 2006, 2007 by Object Management Group. Published and used by INCOSE and affiliated societies with permission. Status • Specification status – Adopted by OMG in May ’06 – Finalization Task Force Report in March ’07 – Available Specification v1.0 expected June ‘07 – Revision task force chartered for SysML v1.1 in March ‘07 • This tutorial is based on the OMG SysML adopted specification (ad-06-03-01) and changes proposed by the Finalization Task Force (ptc/07-03-03) • This tutorial, the specifications, papers, and vendor info can be found on the OMG SysML Website at http://www.omgsysml.org/ 7/26/2007 Copyright © 2006,2007 by Object Management Group. 2 Objectives & Intended Audience At the end of this tutorial, you should have an awareness of: • Benefits of model driven approaches for systems engineering • SysML diagrams and language concepts • How to apply SysML as part of a model based SE process • Basic considerations for transitioning to SysML This course is not intended to make you a systems modeler! You must use the language. Intended Audience: • Practicing Systems Engineers interested in system modeling • Software Engineers who want to better understand how to integrate software and system models • Familiarity with UML is not required, but it helps 7/26/2007 Copyright © 2006,2007 by Object Management Group. 3 Topics • Motivation & Background • Diagram Overview and Language Concepts • SysML Modeling as Part of SE Process – Structured Analysis – Distiller Example – OOSEM – Enhanced Security System Example • SysML in a Standards Framework • Transitioning to SysML • Summary 7/26/2007 Copyright © 2006,2007 by Object Management Group. -

VI. the Unified Modeling Language UML Diagrams
Conceptual Modeling CSC2507 VI. The Unified Modeling Language Use Case Diagrams Class Diagrams Attributes, Operations and ConstraintsConstraints Generalization and Aggregation Sequence and Collaboration Diagrams State and Activity Diagrams 2004 John Mylopoulos UML -- 1 Conceptual Modeling CSC2507 UML Diagrams I UML was conceived as a language for modeling software. Since this includes requirements, UML supports world modeling (...at least to some extend). I UML offers a variety of diagrammatic notations for modeling static and dynamic aspects of an application. I The list of notations includes use case diagrams, class diagrams, interaction diagrams -- describe sequences of events, package diagrams, activity diagrams, state diagrams, …more... 2004 John Mylopoulos UML -- 2 Conceptual Modeling CSC2507 Use Case Diagrams I A use case [Jacobson92] represents “typical use scenaria” for an object being modeled. I Modeling objects in terms of use cases is consistent with Cognitive Science theories which claim that every object has obvious suggestive uses (or affordances) because of its shape or other properties. For example, Glass is for looking through (...or breaking) Cardboard is for writing on... Radio buttons are for pushing or turning… Icons are for clicking… Door handles are for pulling, bars are for pushing… I Use cases offer a notation for building a coarse-grain, first sketch model of an object, or a process. 2004 John Mylopoulos UML -- 3 Conceptual Modeling CSC2507 Use Cases for a Meeting Scheduling System Initiator Participant -

EB GUIDE Documentation Version 6.1.0.101778 EB GUIDE Documentation
EB GUIDE documentation Version 6.1.0.101778 EB GUIDE documentation Elektrobit Automotive GmbH Am Wolfsmantel 46 D-91058 Erlangen GERMANY Phone: +49 9131 7701-0 Fax: +49 9131 7701-6333 http://www.elektrobit.com Legal notice Confidential and proprietary information. ALL RIGHTS RESERVED. No part of this publication may be copied in any form, by photocopy, microfilm, retrieval system, or by any other means now known or hereafter invented without the prior written permission of Elektrobit Automotive GmbH. ProOSEK®, tresos®, and street director® are registered trademarks of Elektrobit Automotive GmbH. All brand names, trademarks and registered trademarks are property of their rightful owners and are used only for description. Copyright 2015, Elektrobit Automotive GmbH. Page 2 of 324 EB GUIDE documentation Table of Contents 1. About this documentation ................................................................................................................ 15 1.1. Target audiences of the user documentation ......................................................................... 15 1.1.1. Modelers .................................................................................................................. 15 1.1.2. System integrators .................................................................................................... 16 1.1.3. Application developers ............................................................................................... 16 1.1.4. Extension developers ............................................................................................... -

UML 2 Toolkit, Penker Has Also Collaborated with Hans- Erik Eriksson on Business Modeling with UML: Business Practices at Work
UML™ 2 Toolkit Hans-Erik Eriksson Magnus Penker Brian Lyons David Fado UML™ 2 Toolkit UML™ 2 Toolkit Hans-Erik Eriksson Magnus Penker Brian Lyons David Fado Publisher: Joe Wikert Executive Editor: Bob Elliott Development Editor: Kevin Kent Editorial Manager: Kathryn Malm Production Editor: Pamela Hanley Permissions Editors: Carmen Krikorian, Laura Moss Media Development Specialist: Travis Silvers Text Design & Composition: Wiley Composition Services Copyright 2004 by Hans-Erik Eriksson, Magnus Penker, Brian Lyons, and David Fado. All rights reserved. Published by Wiley Publishing, Inc., Indianapolis, Indiana Published simultaneously in Canada No part of this publication may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, electronic, mechanical, photocopying, recording, scanning, or otherwise, except as permitted under Section 107 or 108 of the 1976 United States Copyright Act, without either the prior written permission of the Publisher, or authorization through payment of the appropriate per-copy fee to the Copyright Clearance Center, Inc., 222 Rose- wood Drive, Danvers, MA 01923, (978) 750-8400, fax (978) 646-8700. Requests to the Pub- lisher for permission should be addressed to the Legal Department, Wiley Publishing, Inc., 10475 Crosspoint Blvd., Indianapolis, IN 46256, (317) 572-3447, fax (317) 572-4447, E-mail: [email protected]. Limit of Liability/Disclaimer of Warranty: While the publisher and author have used their best efforts in preparing this book, they make no representations or warranties with respect to the accuracy or completeness of the contents of this book and specifically disclaim any implied warranties of merchantability or fitness for a particular purpose. -

PML, an Object Oriented Process Modelling Language
PML, an Object Oriented Process Modeling Language Prof. Dr.-Ing. Reiner Anderl 1, and Dipl.-Ing. Jochen Raßler 2 1 Prof. Dr.-Ing. Reiner Anderl, Germany, [email protected] 2 Dipl.-Ing. Jochen Raßler, Germany, [email protected] Abstract: Processes are very important for the success within many business fields. They define the proper application of methods, technologies, tools and company structures in order to reach business goals. Important processes to be defined are manufacturing processes or product development processes for example to guarantee the company’s success. Over the last decades many process modeling languages have been developed to cover the needs of process modeling. Those modeling languages have several limitations, mainly they are still procedural and didn’t follow the paradigm change to object oriented modeling and thus often lead to process models, which are difficult to maintain. In previous papers we have introduced PML, Process Modeling Language, and shown it’s usage in process modeling. PML is derived from UML and hence fully object oriented and uses modern modeling techniques. It is based on process class diagrams that describe methods and resources for process modeling. In this paper the modeling language is described in more detail and new language elements will be introduced to develop the language to a generic usable process modeling language. Keywords: process modeling language, PML, UML 1. Introduction As the tendency of enterprises to collaborate growths steadily, industry faces new challenges managing business processes, product development processes, manufacturing processes and much more. Furthermore, discipline spanning product development processes are increasing, e. -

APECS: Polychrony Based End-To-End Embedded System Design and Code Synthesis
APECS: Polychrony based End-to-End Embedded System Design and Code Synthesis Matthew E. Anderson Dissertation submitted to the faculty of the Virginia Polytechnic Institute and State University in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Computer Engineering Sandeep K. Shukla, Chair Lamine Mili Alireza Haghighat Chao Wang Yi Deng April 3, 2015 Blacksburg, Virginia Keywords: AADL, CPS, Model-based code synthesis, correct-by-construction code synthesis, Polychrony, code generators, OSATE, Ocarina Copyright 2015, Matthew E. Anderson APECS: Polychrony based End-to-End Embedded System Design and Code Synthesis Matthew E. Anderson (ABSTRACT) The development of high integrity embedded systems remains an arduous and error-prone task, despite the efforts by researchers in inventing tools and techniques for design automa- tion. Much of the problem arises from the fact that the semantics of the modeling languages for the various tools, are often distinct, and the semantics gaps are often filled manually through the engineer's understanding of one model or an abstraction. This provides an op- portunity for bugs to creep in, other than standardising software engineering errors germane to such complex system engineering. Since embedded systems applications such as avionics, automotive, or industrial automation are safety critical, it is very important to invent tools, and methodologies for safe and reliable system design. Much of the tools, and techniques deal with either the design of embedded platforms (hardware, networking, firmware etc), and software stack separately. The problem of the semantic gap between these two, as well as between models of computation used to capture semantics must be solved in order to design safer embedded systems. -

Sysml Distilled: a Brief Guide to the Systems Modeling Language
ptg11539604 Praise for SysML Distilled “In keeping with the outstanding tradition of Addison-Wesley’s techni- cal publications, Lenny Delligatti’s SysML Distilled does not disappoint. Lenny has done a masterful job of capturing the spirit of OMG SysML as a practical, standards-based modeling language to help systems engi- neers address growing system complexity. This book is loaded with matter-of-fact insights, starting with basic MBSE concepts to distin- guishing the subtle differences between use cases and scenarios to illu- mination on namespaces and SysML packages, and even speaks to some of the more esoteric SysML semantics such as token flows.” — Jeff Estefan, Principal Engineer, NASA’s Jet Propulsion Laboratory “The power of a modeling language, such as SysML, is that it facilitates communication not only within systems engineering but across disci- plines and across the development life cycle. Many languages have the ptg11539604 potential to increase communication, but without an effective guide, they can fall short of that objective. In SysML Distilled, Lenny Delligatti combines just the right amount of technology with a common-sense approach to utilizing SysML toward achieving that communication. Having worked in systems and software engineering across many do- mains for the last 30 years, and having taught computer languages, UML, and SysML to many organizations and within the college setting, I find Lenny’s book an invaluable resource. He presents the concepts clearly and provides useful and pragmatic examples to get you off the ground quickly and enables you to be an effective modeler.” — Thomas W. Fargnoli, Lead Member of the Engineering Staff, Lockheed Martin “This book provides an excellent introduction to SysML. -
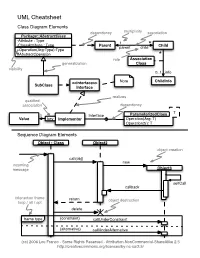
UML Cheatsheet
UML Cheatsheet Class Diagram Elements dependency multiplicity association Package::AbstractClass -Attribute : Type 1 -ClassAttribute : Type Parent Child parent child* +Operation(Arg:Type):Type #AbstractOperation * role Association generalization Class visibility 0..1 info <<interface>> Note ChildInfo SubClass Interface realizes qualified association dependency T 1 Interface ParameterizedClass Value key Implementor Operation(Arg: T) Operation2(): T Sequence Diagram Elements Object : Class Object2 object creation call(obj) new incoming message Object3 selfCall callback interaction frame return object destruction loop / alt / opt delete frame type {constraint} callUnderConstraint {alternative} callUnderAlternative (cc) 2006 Lou Franco - Some Rights Reserved - Attribution-NonCommercial-ShareAlike 2.5 (cc) 2006 Lou Franco - Some Rights Reserved - Attribution-NonCommercial-ShareAlike 2.5 http://creativecommons.org/licenses/by-nc-sa/2.5/ http://creativecommons.org/licenses/by-nc-sa/2.5/ Package Diagram Elements dependency Data View Model SQLServer Oracle Object Diagram Elements John : Child name = "John" parent: Parent Mary : Child name = "Mary" Use Case Diagram Elements system boundary actor 1 Library checkout 1 Membership <<include>> Common return start : Date Role Use Case Use Case renewal : Date * LendRecord Role Lendable due : Date <<include>> id 1 returned : Boolean newArrival : Boolean * LendRecord(lendable, member, date) calcDueDate(member): Date isDue() : Boolean Use Case Use Case renew(Date) * Role Book CD 1 Role * Member DVD (cc) 2006 -

UML Profile for Communicating Systems a New UML Profile for the Specification and Description of Internet Communication and Signaling Protocols
UML Profile for Communicating Systems A New UML Profile for the Specification and Description of Internet Communication and Signaling Protocols Dissertation zur Erlangung des Doktorgrades der Mathematisch-Naturwissenschaftlichen Fakultäten der Georg-August-Universität zu Göttingen vorgelegt von Constantin Werner aus Salzgitter-Bad Göttingen 2006 D7 Referent: Prof. Dr. Dieter Hogrefe Korreferent: Prof. Dr. Jens Grabowski Tag der mündlichen Prüfung: 30.10.2006 ii Abstract This thesis presents a new Unified Modeling Language 2 (UML) profile for communicating systems. It is developed for the unambiguous, executable specification and description of communication and signaling protocols for the Internet. This profile allows to analyze, simulate and validate a communication protocol specification in the UML before its implementation. This profile is driven by the experience and intelligibility of the Specification and Description Language (SDL) for telecommunication protocol engineering. However, as shown in this thesis, SDL is not optimally suited for specifying communication protocols for the Internet due to their diverse nature. Therefore, this profile features new high-level language concepts rendering the specification and description of Internet protocols more intuitively while abstracting from concrete implementation issues. Due to its support of several concrete notations, this profile is designed to work with a number of UML compliant modeling tools. In contrast to other proposals, this profile binds the informal UML semantics with many semantic variation points by defining formal constraints for the profile definition and providing a mapping specification to SDL by the Object Constraint Language. In addition, the profile incorporates extension points to enable mappings to many formal description languages including SDL. To demonstrate the usability of the profile, a case study of a concrete Internet signaling protocol is presented. -

What Is Package Diagram? How to Draw Package Diagram?
Visual Paradigm Tutorial What is Package Diagram? How to Draw Package Diagram? What is Package Diagram? How to Draw Package Diagram? Written Date : July 29, 2014 At the beginning of the project, you only have a limited number of diagrams and everything is simple and beautiful. However, when time flies, more and more diagrams have been created and they start to become unmanageable. As a result, your project becomes hard to navigate and diagrams become difficult to locate when you want to review or make changes. How can we fix it up? We can make use of the Package Diagram to organize your diagrams into different packages. This helps you in categorizing your diagrams according to their natures, making them easier to be navigated and located. The Package Diagram also serves as a catalog for you to jump to the diagram that you want to look at. In this tutorial, we will show you how this can be done. Create Packages for your diagrams First, we need to have our packages ready. To create packages: 1. To create a Package Diagram, select Diagram > New from the toolbar. 2. In the New Diagram window, select Package Diagram and click Next. https://www.visual-paradigm.com/tutorials/packagediagram.jsp Page 1 of 11 Visual Paradigm Tutorial What is Package Diagram? How to Draw Package Diagram? 3. Enter Racing Game Packages as diagram name and click OK to confirm. 4. Click the Package button in diagram tool bar, then click on the blank area of the diagram to create the package. 5. Name the package as Race. -

Getting Started with Sysml 3 This Chapter Provides an Introduction to Sysml and Guidance on How to Begin Modeling in Sysml
CHAPTER Getting Started with SysML 3 This chapter provides an introduction to SysML and guidance on how to begin modeling in SysML. The chapter provides a brief overview of SysML, and then introduces a simplified version of the language we refer to as SysML-Lite, along with a simplified example, and tool tips on how to capture the model in a typical modeling tool. This chapter also introduces a simplified model-based systems engineering (MBSE) method that is consistent with the systems engineering process described in Chapter 1, Section 1.2. The chapter finishes by describing some of the challenges involved in learning SysML and MBSE. 3.1 SYSML PURPOSE AND KEY FEATURES SysML1 is a general-purpose graphical modeling language that supports the analysis, specification, design, verification, and validation of complex systems. These systems may include hardware, soft- ware, data, personnel, procedures, facilities, and other elements of man-made and natural systems. The language is intended to help specify and architect systems and specify their components that can then be designed using other domain-specific languages such as UML for software design and VHDL and three-dimensional geometric modeling for hardware design. SysML is intended to facilitate the application of an MBSE approach to create a cohesive and consistent model of the system that yields the benefits described in Chapter 2, Section 2.1.2. SysML can represent the following aspects of systems, components, and other entities: n Structural composition, interconnection, and classification n Function-based, message-based, and state-based behavior n Constraints on the physical and performance properties n Allocations between behavior, structure, and constraints n Requirements and their relationship to other requirements, design elements, and test cases 3.2 SYSML DIAGRAM OVERVIEW SysML includes nine diagrams as shown in the diagram taxonomy in Figure 3.1. -

Complete Code Generation from UML State Machine
Complete Code Generation from UML State Machine Van Cam Pham, Ansgar Radermacher, Sebastien´ Gerard´ and Shuai Li CEA, LIST, Laboratory of Model Driven Engineering for Embedded Systems, P.C. 174, Gif-sur-Yvette, 91191, France Keywords: UML State Machine, Code Generation, Semantics-conformance, Efficiency, Events, C++. Abstract: An event-driven architecture is a useful way to design and implement complex systems. The UML State Machine and its visualizations are a powerful means to the modeling of the logical behavior of such an archi- tecture. In Model Driven Engineering, executable code can be automatically generated from state machines. However, existing generation approaches and tools from UML State Machines are still limited to simple cases, especially when considering concurrency and pseudo states such as history, junction, and event types. This paper provides a pattern and tool for complete and efficient code generation approach from UML State Ma- chine. It extends IF-ELSE-SWITCH constructions of programming languages with concurrency support. The code generated with our approach has been executed with a set of state-machine examples that are part of a test-suite described in the recent OMG standard Precise Semantics Of State Machine. The traced execution results comply with the standard and are a good hint that the execution is semantically correct. The generated code is also efficient: it supports multi-thread-based concurrency, and the (static and dynamic) efficiency of generated code is improved compared to considered approaches. 1 INTRODUCTION Completeness: Existing tools and approaches mainly focus on the sequential aspect while the concurrency The UML State Machine (USM) (Specification and of state machines is limitedly supported.