Early Detection of Emergency Events from Social Media: a New Text Clustering Approach
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
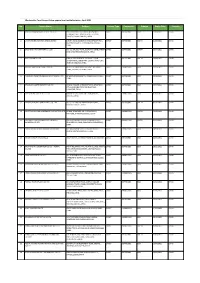
Apparel & Textile Factory List
Woolworths Food Group-Active apparel and textile factories- April 2021 No. Factory Name Address Factory Type Commodity Scheme Expiry Date Country 1 JIANGSU HONGMOFANG TEXTILE CO., LTD EAST CIFU ROAD, EAST RUISHENG AVENUE,, DIRECT SOFTGOODS BSCI 23/04/2021 CHINA ECONOMIC DEVELOPMENT ZONE, SHUYANG COUNTY,,SUQIAN,JIANGSU,,CHINA 2 LIANYUNGANG ZHAOWEN SHOES LIMITED 2 BEIHAI ROAD,ECONOMIC DEVELOPMENT AREA, DIRECT SOFTGOODS SMETA 11/05/2021 CHINA GUANNAN COUNTY,,LIANYUNGANG,JIANGSU,, CHINA 3 ZHUCHENG YIXIN GARMENT CO., LTD NO. 321 SHUNDU ROAD,,ECONOMIC DEVELOPMENT DIRECT SOFTGOODS SMETA 13/07/2021 CHINA ZONE,,ZHUCHENG,SHANDONG,,CHINA 4 HRX FASHION CO LTD 1000 METERS SOUTH OF GUOCANG TOWN DIRECT SOFTGOODS SMETA 25/08/2021 CHINA GOVERNMENT,,WENSHANG COUNTY, JINING CITY, JINING,SHANDONG,,CHINA 5 PUJIANG KINGSHOW CARPET CO LTD NO.75-1 ZHEN PU ROAD, PU JIANG, ZHE JIANG, DIRECT HARDGOODS BSCI 24/12/2021 CHINA CHINA,,PUJIANG,ZHEJIANG,,CHINA 6 YANGZHOU TENGYI SHOES MANUFACTURE CO., LTD. 13 WEST HONGCHENG RD,,,FANGXIANG,JIANGSU,, DIRECT SOFTGOODS BSCI 22/10/2021 CHINA CHINA 7 ZHAOYUAN CASTTE GARMENT CO LTD PANJIAJI VILLAGE, LINGLONG TOWN,,ZHAOYUAN DIRECT SOFTGOODS BSCI 06/07/2021 CHINA CITY, SHANDONG PROVINCE,ZHAOYUAN, SHANDONG,,CHINA 8 RUGAO HONGTAI TEXTILE CO LTD XINJIAN VILLAGE, JIANGAN TOWN,,RUGAO, DIRECT HARDGOODS BSCI 07/12/2021 CHINA JIANGSU,,CHINA 9 NANJING BIAOMEI HOMETEXTILES CO.,LTD NO.13 ERST WUCHU ROAD,HENGXI TOWN,,, DIRECT SOFTGOODS SMETA 04/11/2021 CHINA NANJING,JIANGSU,,CHINA 10 NANTONG YAOXING HOUSEWARE PRODUCTS CO.,LTD NO.999, TONGFUBEI RD., CHONGCHUAN, DIRECT HARDGOODS SMETA 24/09/2021 CHINA NANTONG,,NANTONG,JIANGSU,,CHINA 11 CHAOZHOU CHAOAN ZHENGYUN CERAMICS QIAO HU VILLAGE, CHAOAN, CHAOZHOU CITY, DIRECT HARDGOODS SMETA 19/05/2021 CHINA INDUSTRIAL CO LTD GUANGDONG, CHINA,,CHAOZHOU,GUANGDONG,, CHINA 12 YANTAI PACIFIC HOME FASHION FUSHAN MILL NO. -

Transmissibility of Hand, Foot, and Mouth Disease in 97 Counties of Jiangsu Province, China, 2015- 2020
Transmissibility of Hand, Foot, and Mouth Disease in 97 Counties of Jiangsu Province, China, 2015- 2020 Wei Zhang Xiamen University Jia Rui Xiamen University Xiaoqing Cheng Jiangsu Provincial Center for Disease Control and Prevention Bin Deng Xiamen University Hesong Zhang Xiamen University Lijing Huang Xiamen University Lexin Zhang Xiamen University Simiao Zuo Xiamen University Junru Li Xiamen University XingCheng Huang Xiamen University Yanhua Su Xiamen University Benhua Zhao Xiamen University Yan Niu Chinese Center for Disease Control and Prevention, Beijing City, People’s Republic of China Hongwei Li Xiamen University Jian-li Hu Jiangsu Provincial Center for Disease Control and Prevention Tianmu Chen ( [email protected] ) Page 1/30 Xiamen University Research Article Keywords: Hand foot mouth disease, Jiangsu Province, model, transmissibility, effective reproduction number Posted Date: July 30th, 2021 DOI: https://doi.org/10.21203/rs.3.rs-752604/v1 License: This work is licensed under a Creative Commons Attribution 4.0 International License. Read Full License Page 2/30 Abstract Background: Hand, foot, and mouth disease (HFMD) has been a serious disease burden in the Asia Pacic region represented by China, and the transmission characteristics of HFMD in regions haven’t been clear. This study calculated the transmissibility of HFMD at county levels in Jiangsu Province, China, analyzed the differences of transmissibility and explored the reasons. Methods: We built susceptible-exposed-infectious-asymptomatic-removed (SEIAR) model for seasonal characteristics of HFMD, estimated effective reproduction number (Reff) by tting the incidence of HFMD in 97 counties of Jiangsu Province from 2015 to 2020, compared incidence rate and transmissibility in different counties by non -parametric test, rapid cluster analysis and rank-sum ratio. -

Zhang Jian's Project Harnessing the Hwai River
Harnessing the Huai River Planned by Zhang Jian And the American Red Cross by QIAN Jian (Yulizi)① (Faculty of Liberal Arts, University of Nantong, Jiangsu, China. Postcode 226007) Abstract from p.1; Preface from p.2; Part one from p.3; Part two from p.6; Part three from p.11; Part four from p.14; Part five from p.19; Epilogue from p.22. Abstract: Flood out of the Huai River has yet not been completely forestalled, the terrible disaster happened frequently for several hundred years. Zhang Jian, who called for the harness of the Huai River as early as in 1887, set up the Department of Survey and Draw inside the Tungchow Teachers School in 1905. He was appointed Participating-Officer General of the Preparing Bureau of Releasing Huai next year. In 1909, he founded the Company of Water Conservancy Facilities along the Yangtze and Huai Rivers. In 1911, he established further the Bureau of Conservancy and Survey in the Yangtze and Huai Rivers and started formally the survey and plan of harness of the Huai River. In the same year, when the Huai River brought up a flood while the American Red Cross tried to relieve the people during the disaster and assigned an engineer to make survey at the same time and drew up a project for dredging up the Huai River. It was thought to be the beginning of the American Red Cross involving in the ① QIAN Jian, 钱健,号和笔名为羽离子,male, 1954 - , penname Yulizi, Vice- Professor at Faculty of Liberal Arts, University of Nantong, China. -

01E21072147important 0..0
THIS CIRCULAR IS IMPORTANT AND REQUIRES YOUR IMMEDIATE ATTENTION If you are in any doubt as to any aspect of this circular or as to the action to be taken, you should consult your stockbroker or other licensed securities dealer, bank manager, solicitor, professional accountant or other professional adviser. If you have sold or transferred all your shares in Yue Da International Holdings Limited, you should at once hand this circular to the purchaser(s) or transferee(s), or to the bank or licensed securities dealer or registered institution in securities or other agent through whom the sale or transfer was effected, for transmission to the purchaser(s) or transferee(s). Hong Kong Exchanges and Clearing Limited and The Stock Exchange of Hong Kong Limited take no responsibility for the contents of this circular, make no representation as to its accuracy or completeness and expressly disclaim any liability whatsoever for any loss howsoever arising from or in reliance upon the whole or any part of the contents of this circular. YUE DA INTERNATIONAL HOLDINGS LIMITED 悅 達國際控股有限公司 (Incorporated in the Cayman Islands with limited liability) (Stock Code: 629) MAJOR TRANSACTIONS – FACTORING AGREEMENTS AND SUPPLEMENTAL REVERSE FACTORING AGREEMENT Capitalised terms used in this cover page shall have the same meanings as those defined in this circular. A letter from the Board is set out on pages 4 to 13 of this circular. This circular will remain on the Stock Exchange’s website at www.hkexnews.hk and, in the case of this circular, on the ‘‘Latest Company Announcements’’ page for at least 7 days from the date of its posting. -

Hazardous Chemical Releases at Large
Hazardous Chemical Releases at Large: An Investigation at the Lianyungang Chemical Industrial Park, Jiangsu Province, China Greenpeace East Asia May 2017 Contents Copyright Acronyms I. Introduction II. Executive Summary III. Background of Investigation IV. Lianyungang Chemical Industrial Park V. Investigation and Findings VI. Discussion and Suggestion Appendix Figures Figure 1. Industrial Zones surrounding Yancheng National Natural Reserve Area in Jiangsu Province Figure 2. The location of Lianyungang Chemical Industrial Park in Jiangsu Province Figure 3. Environmental Non-Compliance Penalties of Enterprises at Lianyungang Chemical Industrial Park in 2014-2016 Figure 4. Sampling locations in Lianyungang Chemical Industrial Park Tables: Table 1. Description of Sampling Locations, Time, and Sample Types Table 2. Key Organic Contaminants and their Concentrations in the Samples Collected from Lianyungang Chemical Industrial Park Table 3. Examples of Hazardous Chemicals Identified in the Samples Table 4. The comparison between hazardous chemicals identified in water samples and their permitted discharge limits as regulated in Integrated Wastewater Discharge Standard (GB8978-1996). Table 5. List of the Chemicals with High Environmental and Health Concerns 2 Copyright This report is published by Greenpeace. Greenpeace is the exclusive owner of the copyright of this report. Disclaimer 1. This report is originally written in English and translated into Chinese subsequently. In case of a discrepancy, the English version prevails. 2. The content -

Spatial and Temporal Evaluation of Ecological Footprint Intensity of Jiangsu Province at the County-Level Scale
International Journal of Environmental Research and Public Health Article Spatial and Temporal Evaluation of Ecological Footprint Intensity of Jiangsu Province at the County-Level Scale Decun Wu 1 and Jinping Liu 2,* 1 School of Public Administration and Sociology, Jiangsu Normal University, Xuzhou 221116, China; [email protected] 2 School of Economics and Management, China University of Mining and Technology, Xuzhou 221116, China * Correspondence: [email protected] Received: 10 September 2020; Accepted: 23 October 2020; Published: 26 October 2020 Abstract: Due to the high ecological pressure that exists in the process of rapid economic development in Jiangsu Province, it is necessary to evaluate its ecological footprint intensity (EFI). This article focuses on ecological footprint intensity analysis at the county scale. We used county-level data to evaluate the spatial distributions and temporal trends of the ecological footprint intensity in Jiangsu’s counties from 1995 to 2015. The temporal trends of counties are divided into five types: linear declining type, N-shape type, inverted-N type, U-shape type and inverted-U shape type. It was discovered that the proportions of the carbon footprint intensity were maintained or increased in most counties. Exploratory spatial data analysis shows that there was a certain regularity of the EFI spatial distributions, i.e., a gradient decrease from north to south, and there was a decline in the spatial heterogeneity of EFI in Jiangsu’s counties over time. The global Moran’s index (Moran’s I) and local spatial association index (LISA) are used to analyze both the global and local spatial correlation of EFIs among counties of Jiangsu Province. -

World Bank Document
"'U" 0, u JJ 11' JI If ti Public Disclosure Authorized - IA---AJ: I.1-, I IT I', ml (T , -I- It IT- ItP. I It W. (I !,. - 111-11 ;I ?A- i I., 10 It it 41i :U to J- fl,;t 11 ?j ;I 11'. 14 l 11 AT 't J, A .,R All t-l' 116 ,11 if 0 11 Public Disclosure Authorized jJ 11A n A 11 (611 Al 14 's I A, 't. I IT I V;u Z IA: ..t., ;-I D.C::A ., J. I . - IA, IT. If 't it V A. 1,1, -1 n. IJ: 3"t.._'M Al Z. ri- 41; Public Disclosure Authorized 11 L A if If !I 11 fJ Public Disclosure Authorized PRESIDENT: JIANG SHUXUE (VICE), SENIOR ENGINEEROF HARBOURENGINEERING CHIEF ENGINEER: LIN QINGLING(VICE), SENIOR ENGINEEROF HARBOURENGINEERING DIRECTOR:DENG ENGUO,SENIOR ENGINEER OF ENVIRONMENT ENGINEERING REVIEWEDBY: DENG ENGUO,SENIOR ENGINEER OF ENVIRONMENTENGINEERING PROJECTMANAGER: LUO XIANQING PREPAREDBY: LUO XIANQING, YOU LIXIN, YU JINGBIAO HAN WEI, CHEN YONG PANG XUEMEI, ZHANG BO 2 ASSESSMENTPARTICIPANT: INSTITUTEOF HYDROLOGY,WATER RESOURCEAND ENVIRONMENTSCIENCE, THE HEHAI UNIVERSITY CERTIFICATENO.: JIAZI 0222 TECHNICALLEADER: WANGHUIMIN, YAOQl PARTICIPANTS: CHU JUNDA, DING SHUANQING, PANG YONG XUHUICI, XUYING, XIANGLIPING MAOYONGGEN 3 PROJECTCOOPERATION UNITS BIOLOGYDEPARTMENT, NANJINGNORMAL UNIVERSITY XUZHOU ENVIRONMENTMONITORING STATION HUAIYINENVIRONMENT MONITORING STATION ZHENJIANGENVIRONMENT MONITORING STATION SUZHOUENVIRONMENT MONITORING STATION XISHAN ENVIRONMENTMONITORING STATION 4 TABLE OF CONTENTS PREFACE 1. GENERAL 1.1 ASSESSMENT PURPOSES 1.2 ASSESSMENT BASIS 1.3 ASSESSMENT GRADE 1.4 EVALUATION STANDARDOF ENVIRONMENTALIMPACT 1.5 ENVIRONMENTPROTECTION OBJECTIVES 1.6 ASSESSMENT METHODS 2. BRIEF INTRODUCTIONTO THE PROJECT 2.1 PROJECT OBJECTIVES 2.2 PROJECT COMPOSITION 2.3 PROJECT SCALE AND CONSTRUCTION STANDARD 2.4 MAJORWORKS 2.5 INVESTMENTAND FUND RAISING 2.6 PROJECT IMPLEMENTATIONPLAN 3. -

Subsidy Programs
SUBSIDIES REQUEST FROM THE UNITED STATES TO CHINA PURSUANT TO ARTICLE 25.10 OF THE AGREEMENT The following communication, dated 15 April 2016, is being circulated at the request of the Delegation of the United States. _______________ In the report that it prepared for China's most recent Trade Policy Review, held in July 2014, the Secretariat included information that it had uncovered on 30 support programs for China's fisheries sector.1 The Secretariat's Report noted that China had not notified any of these support programs to the Committee on Subsidies and Countervailing Measures (Committee) and that China could not verify any of the information provided to it by the Secretariat. During the ensuing Trade Policy Review meetings, China responded to Members' questions about these support programs by stating that it needed more time to identify and verify information regarding these support programs. In April of last year, the United States submitted questions to China with respect to these programs and other fishery support measures the United States had uncovered through its own efforts.2 Once again, despite its obligation under Article 25.9 of the Agreement to provide answers "as quickly as possible and in a comprehensive manner", China to date has not meaningfully responded to the United States' request and has refused repeated requests to meet bilaterally to discuss the issue, and the issue of subsidy notifications more generally. In November of last year, China submitted its latest subsidy notification covering the period 2009 through 2014.3 In this notification, China did not include: (1) any of the fishery subsidy programs identified in China's 2014 TPR report, (2) any of the additional measures identified by the United States in its Article 25.8 submission or (3) any of the fisheries subsidies measures identified in the 2014 Article 25.10 submission of the United States4. -

G/Scm/Q2/Chn/59
G/SCM/Q2/CHN/59 21 April 2016 (16-2252) Page: 1/297 Committee on Subsidies and Countervailing Measures Original: English SUBSIDIES REQUEST FROM THE UNITED STATES TO CHINA PURSUANT TO ARTICLE 25.10 OF THE AGREEMENT The following communication, dated 15 April 2016, is being circulated at the request of the Delegation of the United States. _______________ In the report that it prepared for China's most recent Trade Policy Review, held in July 2014, the Secretariat included information that it had uncovered on 30 support programs for China's fisheries sector.1 The Secretariat's Report noted that China had not notified any of these support programs to the Committee on Subsidies and Countervailing Measures (Committee) and that China could not verify any of the information provided to it by the Secretariat. During the ensuing Trade Policy Review meetings, China responded to Members' questions about these support programs by stating that it needed more time to identify and verify information regarding these support programs. In April of last year, the United States submitted questions to China with respect to these programs and other fishery support measures the United States had uncovered through its own efforts.2 Once again, despite its obligation under Article 25.9 of the Agreement to provide answers "as quickly as possible and in a comprehensive manner", China to date has not meaningfully responded to the United States' request and has refused repeated requests to meet bilaterally to discuss the issue, and the issue of subsidy notifications more generally. 1 See WT/TPR/S/300, page 88, paragraph 3.126, and pages 191-98, Table A3.6. -

ABB to Provide Power Products for China's Large Offshore
ABB to provide power products for China’s large 联系我们 媒体联系人: offshore wind farm 马林 链接 Power Products division Smart Technology, Intelligent Upgrading 中文 A gust of sea wind that can light tens of thousands of households - this is becoming a reality in some of China’s coastal areas. Some 10 kilometers off the coast of Xiangshui County, a series of wind turbines with fan blades longer than 60 meters are being installed. Here is the Jiangsu Xiangshui Offshore 200 MW Wind Farm Demonstration Project, China’s first wind power project that transmits power to onshore areas via an offshore transformer substation. As a coastal county located at the intersection of Lianyungang, Huai’an and Yancheng in northeastern Jiangsu Province, Xiangshui boasts abundant offshore wind resources. With a total installed capacity of 201 MW, the Xiangshui Offshore Wind Farm will be equipped with 37 sets of 4 MW wind turbines and 18 sets of 3 MW wind turbines. The first phase of 50 MW wind turbines will be installed and brought into operation by the end of 2015. The Xiangshui Offshore Wind Farm will feature China’s first offshore substation equipped with ABB’s full range of power equipment in a relay station that delivers wind power to onshore transformer stations. The system will decrease the power loss caused by long-distance transmission and improve the transmission capability. The voltage created by wind turbines will be boosted from 35 kV to 220 kV, then transmitted onshore via undersea AC cables, constantly delivering clean wind power to the grid of Northern Jiangsu. -

Haixi Overseas Investment Company Limited Us$100000000 2.30 Per Cent. Credit Enhanced Bonds Due 2024
Hong Kong Exchanges and Clearing Limited and The Stock Exchange of Hong Kong Limited (the “SEHK”) take no responsibility for the contents of this announcement, make no representation as to its accuracy or completeness and expressly disclaim any liability whatsoever for any loss howsoever arising from or in reliance upon the whole or any part of the contents of this announcement. This announcement and the listing document referred to herein are not intended to be and does not constitute an invitation or offer to acquire, purchase or subscribe for securities. The securities referred to herein have not been and will not be registered under the U.S. Securities Act of 1933, as amended (the “Securities Act”), or the securities laws of any state of the United States or any other jurisdiction, and may not be offered or sold within the United States except pursuant to an exemption from, or in a transaction not subject to, the registration requirements of the Securities Act. This announcement and the listing document referred to herein have been published for information purposes only as required by the Rules Governing the Listing of Securities on The Stock Exchange of Hong Kong Limited (“Listing Rules”) and do not constitute an offer to sell nor a solicitation of an offer to buy any securities. Neither this announcement nor anything referred to herein (including the listing document) forms the basis for any contract or commitment whatsoever. For the avoidance of doubt, the publication of this announcement and the listing document referred to herein shall not be deemed to be an offer of securities made pursuant to a prospectus issued by or on behalf of the Issuer (as defined below) for the purposes of the Companies (Winding Up and Miscellaneous Provisions) Ordinance (Cap. -

JIANGSU YUEDA GROUP CO., LTD. (江蘇悅達集團有限公司 ) (Incorporated with Limited Liability in the PRC) U.S.$87,250,000 5.70 Per Cent
Hong Kong Exchanges and Clearing Limited and The Stock Exchange of Hong Kong Limited take no responsibility for the contents of this announcement, make no representation as to its accuracy or completeness and expressly disclaim any liability whatsoever for any loss howsoever arising from or in reliance upon the whole or any part of the contents of this announcement. This announcement is for information purposes only and does not constitute an invitation or offer to acquire, purchase or subscribe for securities. This announcement does not constitute or form a part of any offer or solicitation to purchase or subscribe for securities in the United States. The securities have not been and will not be registered under the U.S. Securities Act of 1933, as amended (the “Securities Act”), or the securities laws of any state of the United States or any other jurisdiction, and may not be offered or sold within the United States except pursuant to an exemption from, or in a transaction not subject to, the registration requirements of the Securities Act. Accordingly, the Bonds are being offered and sold only outside the United States in offshore transactions in compliance with Regulation S under the Securities Act. This announcement and the information contained herein are not for distribution, directly or indirectly, in or into the United States. No public offer of the securities referred to herein is being or will be made in the United States. This announcement and the listing document referred to herein have been published for information purposes only as required by the Rules Governing the Listing of Securities on The Stock Exchange of Hong Kong Limited (“Listing Rules”) and do not constitute an offer to sell nor a solicitation of an offer to buy any securities.