Quantifying Bias of the US Media
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Tea Party and the Muslim Brotherhood: Who They Are and How American News Media Gets It Wrong
Jeremy Abrams The Tea Party and the Muslim Brotherhood: Who they are and How American News Media Gets it Wrong Jeremy Abrams 1 Table of Content I. Introduction ........................................................................................................................................................ 2 II. Defining Political Parties and their Role in Democracies ................................................................. 2 A. Generally ......................................................................................................................................................... 2 B. Structurally .................................................................................................................................................... 3 C. How the Tea Party and the Muslim Brotherhood Fit the Mold ................................................. 4 III. Brief Descriptions of the Tea Party and the Muslim Brotherhood ............................................. 4 A. The Tea Party ................................................................................................................................................ 5 1. History ......................................................................................................................................................... 5 2. The System in Which it Operates ..................................................................................................... 9 3. Official Status ........................................................................................................................................ -

Chapter 4 the Right-Wing Media Enablers of Anti-Islam Propaganda
Chapter 4 The right-wing media enablers of anti-Islam propaganda Spreading anti-Muslim hate in America depends on a well-developed right-wing media echo chamber to amplify a few marginal voices. The think tank misinforma- tion experts and grassroots and religious-right organizations profiled in this report boast a symbiotic relationship with a loosely aligned, ideologically-akin group of right-wing blogs, magazines, radio stations, newspapers, and television news shows to spread their anti-Islam messages and myths. The media outlets, in turn, give members of this network the exposure needed to amplify their message, reach larger audiences, drive fundraising numbers, and grow their membership base. Some well-established conservative media outlets are a key part of this echo cham- ber, mixing coverage of alarmist threats posed by the mere existence of Muslims in America with other news stories. Chief among the media partners are the Fox News empire,1 the influential conservative magazine National Review and its website,2 a host of right-wing radio hosts, The Washington Times newspaper and website,3 and the Christian Broadcasting Network and website.4 They tout Frank Gaffney, David Yerushalmi, Daniel Pipes, Robert Spencer, Steven Emerson, and others as experts, and invite supposedly moderate Muslim and Arabs to endorse bigoted views. In so doing, these media organizations amplify harm- ful, anti-Muslim views to wide audiences. (See box on page 86) In this chapter we profile some of the right-wing media enablers, beginning with the websites, then hate radio, then the television outlets. The websites A network of right-wing websites and blogs are frequently the primary movers of anti-Muslim messages and myths. -

Periodicalspov.Pdf
“Consider the Source” A Resource Guide to Liberal, Conservative and Nonpartisan Periodicals 30 East Lake Street ∙ Chicago, IL 60601 HWC Library – Room 501 312.553.5760 ver heard the saying “consider the source” in response to something that was questioned? Well, the same advice applies to what you read – consider the source. When conducting research, bear in mind that periodicals (journals, magazines, newspapers) may have varying points-of-view, biases, and/or E political leanings. Here are some questions to ask when considering using a periodical source: Is there a bias in the publication or is it non-partisan? Who is the sponsor (publisher or benefactor) of the publication? What is the agenda of the sponsor – to simply share information or to influence social or political change? Some publications have specific political perspectives and outright state what they are, as in Dissent Magazine (self-described as “a magazine of the left”) or National Review’s boost of, “we give you the right view and back it up.” Still, there are other publications that do not clearly state their political leanings; but over time have been deemed as left- or right-leaning based on such factors as the points- of-view of their opinion columnists, the make-up of their editorial staff, and/or their endorsements of politicians. Many newspapers fall into this rather opaque category. A good rule of thumb to use in determining whether a publication is liberal or conservative has been provided by Media Research Center’s L. Brent Bozell III: “if the paper never met a conservative cause it didn’t like, it’s conservative, and if it never met a liberal cause it didn’t like, it’s liberal.” Outlined in the following pages is an annotated listing of publications that have been categorized as conservative, liberal, non-partisan and religious. -

Deception, Disinformation, and Strategic Communications: How One Interagency Group Made a Major Difference by Fletcher Schoen and Christopher J
STRATEGIC PERSPECTIVES 11 Deception, Disinformation, and Strategic Communications: How One Interagency Group Made a Major Difference by Fletcher Schoen and Christopher J. Lamb Center for Strategic Research Institute for National Strategic Studies National Defense University Institute for National Strategic Studies National Defense University The Institute for National Strategic Studies (INSS) is National Defense University’s (NDU’s) dedicated research arm. INSS includes the Center for Strategic Research, Center for Complex Operations, Center for the Study of Chinese Military Affairs, Center for Technology and National Security Policy, Center for Transatlantic Security Studies, and Conflict Records Research Center. The military and civilian analysts and staff who comprise INSS and its subcomponents execute their mission by conducting research and analysis, publishing, and participating in conferences, policy support, and outreach. The mission of INSS is to conduct strategic studies for the Secretary of Defense, Chairman of the Joint Chiefs of Staff, and the Unified Combatant Commands in support of the academic programs at NDU and to perform outreach to other U.S. Government agencies and the broader national security community. Cover: Kathleen Bailey presents evidence of forgeries to the press corps. Credit: The Washington Times Deception, Disinformation, and Strategic Communications: How One Interagency Group Made a Major Difference Deception, Disinformation, and Strategic Communications: How One Interagency Group Made a Major Difference By Fletcher Schoen and Christopher J. Lamb Institute for National Strategic Studies Strategic Perspectives, No. 11 Series Editor: Nicholas Rostow National Defense University Press Washington, D.C. June 2012 Opinions, conclusions, and recommendations expressed or implied within are solely those of the contributors and do not necessarily represent the views of the Defense Department or any other agency of the Federal Government. -

Online Media and the 2016 US Presidential Election
Partisanship, Propaganda, and Disinformation: Online Media and the 2016 U.S. Presidential Election The Harvard community has made this article openly available. Please share how this access benefits you. Your story matters Citation Faris, Robert M., Hal Roberts, Bruce Etling, Nikki Bourassa, Ethan Zuckerman, and Yochai Benkler. 2017. Partisanship, Propaganda, and Disinformation: Online Media and the 2016 U.S. Presidential Election. Berkman Klein Center for Internet & Society Research Paper. Citable link http://nrs.harvard.edu/urn-3:HUL.InstRepos:33759251 Terms of Use This article was downloaded from Harvard University’s DASH repository, and is made available under the terms and conditions applicable to Other Posted Material, as set forth at http:// nrs.harvard.edu/urn-3:HUL.InstRepos:dash.current.terms-of- use#LAA AUGUST 2017 PARTISANSHIP, Robert Faris Hal Roberts PROPAGANDA, & Bruce Etling Nikki Bourassa DISINFORMATION Ethan Zuckerman Yochai Benkler Online Media & the 2016 U.S. Presidential Election ACKNOWLEDGMENTS This paper is the result of months of effort and has only come to be as a result of the generous input of many people from the Berkman Klein Center and beyond. Jonas Kaiser and Paola Villarreal expanded our thinking around methods and interpretation. Brendan Roach provided excellent research assistance. Rebekah Heacock Jones helped get this research off the ground, and Justin Clark helped bring it home. We are grateful to Gretchen Weber, David Talbot, and Daniel Dennis Jones for their assistance in the production and publication of this study. This paper has also benefited from contributions of many outside the Berkman Klein community. The entire Media Cloud team at the Center for Civic Media at MIT’s Media Lab has been essential to this research. -

Channel Lineup January 2018
MyTV CHANNEL LINEUP JANUARY 2018 ON ON ON SD HD• DEMAND SD HD• DEMAND SD HD• DEMAND My64 (WSTR) Cincinnati 11 511 Foundation Pack Kids & Family Music Choice 300-349• 4 • 4 A&E 36 536 4 Music Choice Play 577 Boomerang 284 4 ABC (WCPO) Cincinnati 9 509 4 National Geographic 43 543 4 Cartoon Network 46 546 • 4 Big Ten Network 206 606 NBC (WLWT) Cincinnati 5 505 4 Discovery Family 48 548 4 Beauty iQ 637 Newsy 508 Disney 49 549 • 4 Big Ten Overflow Network 207 NKU 818+ Disney Jr. 50 550 + • 4 Boone County 831 PBS Dayton/Community Access 16 Disney XD 282 682 • 4 Bounce TV 258 QVC 15 515 Nickelodeon 45 545 • 4 Campbell County 805-807, 810-812+ QVC2 244• Nick Jr. 286 686 4 • CBS (WKRC) Cincinnati 12 512 SonLife 265• Nicktoons 285 • 4 Cincinnati 800-804, 860 Sundance TV 227• 627 Teen Nick 287 • 4 COZI TV 290 TBNK 815-817, 819-821+ TV Land 35 535 • 4 C-Span 21 The CW 17 517 Universal Kids 283 C-Span 2 22 The Lebanon Channel/WKET2 6 Movies & Series DayStar 262• The Word Network 263• 4 Discovery Channel 32 532 THIS TV 259• MGM HD 628 ESPN 28 528 4 TLC 57 557 4 STARZEncore 482 4 ESPN2 29 529 Travel Channel 59 559 4 STARZEncore Action 497 4 EVINE Live 245• Trinity Broadcasting Network (TBN) 18 STARZEncore Action West 499 4 EVINE Too 246• Velocity HD 656 4 STARZEncore Black 494 4 EWTN 264•/97 Waycross 850-855+ STARZEncore Black West 496 4 FidoTV 688 WCET (PBS) Cincinnati 13 513 STARZEncore Classic 488 4 Florence 822+ WKET/Community Access 96 596 4 4 STARZEncore Classic West 490 Food Network 62 562 WKET1 294• 4 4 STARZEncore Suspense 491 FOX (WXIX) Cincinnati 3 503 WKET2 295• STARZEncore Suspense West 493 4 FOX Business Network 269• 669 WPTO (PBS) Oxford 14 STARZEncore Family 479 4 FOX News 66 566 Z Living 636 STARZEncore West 483 4 FOX Sports 1 25 525 STARZEncore Westerns 485 4 FOX Sports 2 219• 619 Variety STARZEncore Westerns West 487 4 FOX Sports Ohio (FSN) 27 527 4 AMC 33 533 FLiX 432 4 FOX Sports Ohio Alt Feed 601 4 Animal Planet 44 544 Showtime 434 435 4 Ft. -

The Tea Party Movement As a Modern Incarnation of Nativism in the United States and Its Role in American Electoral Politics, 2009-2014
City University of New York (CUNY) CUNY Academic Works All Dissertations, Theses, and Capstone Projects Dissertations, Theses, and Capstone Projects 10-2014 The Tea Party Movement as a Modern Incarnation of Nativism in the United States and Its Role in American Electoral Politics, 2009-2014 Albert Choi Graduate Center, City University of New York How does access to this work benefit ou?y Let us know! More information about this work at: https://academicworks.cuny.edu/gc_etds/343 Discover additional works at: https://academicworks.cuny.edu This work is made publicly available by the City University of New York (CUNY). Contact: [email protected] The Tea Party Movement as a Modern Incarnation of Nativism in the United States and Its Role in American Electoral Politics, 2009-2014 by Albert Choi A master’s thesis submitted to the Graduate Faculty in Political Science in partial fulfillment of the requirements for the degree of Master of Arts, The City University of New York 2014 i Copyright © 2014 by Albert Choi All rights reserved. No part of this publication may be reproduced, distributed, or transmitted in any form or by any means, including photocopying, recording, or other electronic or mechanical methods, without the prior written permission of the publisher, except in the case of brief quotations embodied in critical reviews and certain other noncommercial uses permitted by copyright law. ii This manuscript has been read and accepted for the Graduate Faculty in Political Science in satisfaction of the dissertation requirement for the degree of Master of Arts. THE City University of New York iii Abstract The Tea Party Movement as a Modern Incarnation of Nativism in the United States and Its Role in American Electoral Politics, 2009-2014 by Albert Choi Advisor: Professor Frances Piven The Tea Party movement has been a keyword in American politics since its inception in 2009. -

Divergent Coverage of the Early Tea Party Movement in The
DIVERGENT COVERAGE OF THE EARLY TEA PARTY MOVEMENT IN THE WASHINGTON TIMES AND THE NEW YORK TIMES THESIS Presented to the Graduate Council of Texas State University-San Marcos In Partial Fulfillment of the Requirements For the Degree Master of ARTS Mass Communication By George Hatt, B.A. San Marcos, Texas May 2011 DIVERGENT COVERAGE OF THE EARLY TEA PARTY MOVEMENT IN THE WASHINGTON TIMES AND THE NEW YORK TIMES Committee Members Approved: _____________________________ Dr. Tom Grimes, Chair _____________________________ Dr. Cindy Royal _____________________________ Dr. Bob Price Approved: ____________________________________ Dr. J. Michael Willoughby Dean of the Graduate College COPYRIGHT By George Hatt 2011 DEDICATION For my fiancee Cindy Schiurring. Thanks for being there through the rough times. FAIR USE AND AUTHOR’S PERMISSION STATEMENT Fair Use This work is protected by the Copyright Laws of the United States (Public Law 94-553, section 107). Consistent with fair use as defined in the Copyright Laws, brief quotations from this material are allowed with proper acknowledgment. Use of this material for financial gain without the author’s express written permission is not allowed. Duplication Permission As the copyright holder of this work I, George Hatt, authorize duplication of this work, in whole or in part, for educational or scholarly purposes only. ACKNOWLEDGEMENTS I would like to thank my fiancee, Cindy Schiurring, for sticking with me through a military deployment and more than two years of separation as I worked as an editor at a small-town paper while she pursued her masters degree. She encouraged me to pursue my graduate studies. I would also like to thank Dr. -

Smooth Operator?’ the Propaganda Model and Moments of Crisis
‘Smooth Operator?’ The Propaganda Model and Moments of Crisis Des Freedman Goldsmiths, University of London Keywords : Propaganda model, Iraq War, Tabloids, Daily Mirror Abstract The propaganda model is a powerful tool for explaining systematic flaws in media coverage. But does it explain the cracks and tensions within the commercial media that are capable of arising at moments of political crisis and elite disagreement? To what extent does the model privilege a flawless structuralist account of media power at the expense of focusing on contradictory dynamics inside the capitalist media? This article looks at a key moment where critical media content was generated by a mainstream media organization: the coverage of the run-up to the Iraq War in the British tabloid paper, the Daily Mirror in 2003. It reflects on the consequences of such a moment for resisting corporate media power and asks whether it suggests the need for a revision of the propaganda model or, rather, provides further validation of its relevance. What is a ‘moment’? A situation whose duration may be longer or shorter but which is distinguished from the process that leads up to it in that it forces together the essential tendencies of that process, and demands that a decision be taken over the future direction of the process . That is to say the tendencies reach a sort of zenith, and depending on how the situation concerned is handled, the process takes on a different direction after the ‘moment’ (Lukacs 2000, 55). The propaganda model (PM), as developed initially by Herman and Chomsky (1988), is a powerful reminder that the mainstream media are a crucial tool for legitimizing the ideas of the most powerful social actors and for securing consent for their actions. -

Press Credentials and Hybrid Boundary Zones: the Case of Worldnetdaily and the Standing Committee of Correspondents
Journalism Practice ISSN: 1751-2786 (Print) 1751-2794 (Online) Journal homepage: https://www.tandfonline.com/loi/rjop20 Press Credentials and Hybrid Boundary Zones: The Case of WorldNetDaily and the Standing Committee of Correspondents Jordan M. Foley To cite this article: Jordan M. Foley (2019): Press Credentials and Hybrid Boundary Zones: The Case of WorldNetDaily and the Standing Committee of Correspondents, Journalism Practice, DOI: 10.1080/17512786.2019.1671214 To link to this article: https://doi.org/10.1080/17512786.2019.1671214 Published online: 30 Sep 2019. Submit your article to this journal View related articles View Crossmark data Full Terms & Conditions of access and use can be found at https://www.tandfonline.com/action/journalInformation?journalCode=rjop20 JOURNALISM PRACTICE https://doi.org/10.1080/17512786.2019.1671214 Press Credentials and Hybrid Boundary Zones: The Case of WorldNetDaily and the Standing Committee of Correspondents Jordan M. Foley School of Journalism and Mass Communication, University of Wisconsin–Madison, Madison, WI, USA ABSTRACT KEYWORDS Press credentialing practices are a vital, yet understudied site of Boundary work; first scholarly research on journalistic norms and practices. Press amendment; hybrid credentialing not only structures internal professional hierarchies, boundary zone; online/digital but they also signify the boundaries of the journalistic field itself. journalism; press credentials; standing committee of This paper explores the legal and theoretical implications of press correspondents -
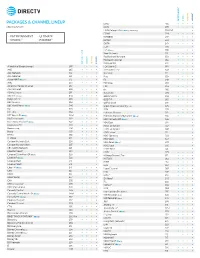
Packages & Channel Lineup
™ ™ ENTERTAINMENT CHOICE ULTIMATE PREMIER PACKAGES & CHANNEL LINEUP ESNE3 456 • • • • Effective 6/17/21 ESPN 206 • • • • ESPN College Extra2 (c only) (Games only) 788-798 • ESPN2 209 • • • • • ENTERTAINMENT • ULTIMATE ESPNEWS 207 • • • • CHOICE™ • PREMIER™ ESPNU 208 • • • EWTN 370 • • • • FLIX® 556 • FM2 (c only) 386 • • Food Network 231 • • • • ™ ™ Fox Business Network 359 • • • • Fox News Channel 360 • • • • ENTERTAINMENT CHOICE ULTIMATE PREMIER FOX Sports 1 219 • • • • A Wealth of Entertainment 387 • • • FOX Sports 2 618 • • A&E 265 • • • • Free Speech TV3 348 • • • • ACC Network 612 • • • Freeform 311 • • • • AccuWeather 361 • • • • Fuse 339 • • • ActionMAX2 (c only) 519 • FX 248 • • • • AMC 254 • • • • FX Movie 258 • • American Heroes Channel 287 • • FXX 259 • • • • Animal Planet 282 • • • • fyi, 266 • • ASPiRE2 (HD only) 381 • • Galavisión 404 • • • • AXS TV2 (HD only) 340 • • • • GEB America3 363 • • • • BabyFirst TV3 293 • • • • GOD TV3 365 • • • • BBC America 264 • • • • Golf Channel 218 • • 2 c BBC World News ( only) 346 • • Great American Country (GAC) 326 • • BET 329 • • • • GSN 233 • • • BET HER 330 • • Hallmark Channel 312 • • • • BET West HD2 (c only) 329-1 2 • • • • Hallmark Movies & Mysteries (c only) 565 • • Big Ten Network 610 2 • • • HBO Comedy HD (c only) 506 • 2 Black News Channel (c only) 342 • • • • HBO East 501 • Bloomberg TV 353 • • • • HBO Family East 507 • Boomerang 298 • • • • HBO Family West 508 • Bravo 237 • • • • HBO Latino3 511 • BYUtv 374 • • • • HBO Signature 503 • C-SPAN2 351 • • • • HBO West 504 • -

Supporting Information
S1 Supporting Information for Fighting misinformation on social media using crowdsourced judgments of news source quality Contents 1. Full list of news sources ............................................................................................................ S2 2. Average trust and familiarity ratings ........................................................................................ S3 3. Robustness across subgroups .................................................................................................... S6 4. Participant-level analysis of relationship with fact-checker ratings ....................................... S10 5. Cognitive reflection and media source discernment ............................................................... S11 6. The relationship between familiarity and trust ....................................................................... S12 7. Regression model details for participant-level analyses associated with Figure 1 ................. S16 8. Partisanship versus ideology ................................................................................................... S18 9. Partisan differences in trust are robust to accounting for political slant of sources ............... S19 10. Full materials – Study 1 ........................................................................................................ S23 11. Full materials – Study 2 ........................................................................................................ S39 12. Full materials – Expert survey