Stream Processing: Aplicación Directa Dentro De Una Arquitectura Distribuida
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Spread for ASP.NET Developer's Guide
Spread for ASP.NET Developer’s Guide 0 Developer's Guide This guide provides introductory conceptual material and how-to explanations for routine tasks for developers using Spread for ASP.NET. It describes how an application developer would use the properties and methods in Spread to create spreadsheets and grids on Web Forms, bind to databases, and customize the component for your application. Getting Started Understanding the Product Working with the Spread Designer Customizing the Appearance Customizing User Interaction Customizing with Cell Types Managing Data Binding Managing Data in the Component Managing Formulas Managing File Operations Using Sheet Models Maintaining State Working with the Chart Control Using Touch Support with the Component For complete API reference information, refer to the Assembly Reference (on-line documentation). For a complete list of documentation, refer to the Spread for ASP.NET Documentation (on-line documentation). Copyright © GrapeCity, inc. All rights reserved. Spread for ASP.NET Developer’s Guide 1 1 Table of Contents Developer's Guide 0 1. Table of Contents 1-16 Getting Started 17 Handling Installation 17 Installing the Product 17 Licensing a Trial Project after Installation 17 End-User License Agreement 17-18 Creating a Build License 18-19 Handling Redistribution 19-20 Product Requirements 20 Handling Variations In Windows Settings 20-21 Working with the Component 21 Adding a Component to a Web Site using Visual Studio 2015 or 2017 21-24 Adding a Component to a Web Site using Visual Studio 2013 -

Archiving Geocue Projects in Microsoft SQL Server
CueTip Archiving GeoCue Projects in Microsoft SQL Server GeoCue Group Support January 16, 2015 Revision 2.0 Introduction GeoCue Server runs on top of a SQL database. The database stores all the metadata about projects as well as all internal links to the geospatial data stored in the GeoCue warehouses. The database may be a full SQL database installation or a limited edition of SQL such as Microsoft SQL Server Express (Express) or Microsoft SQL Desktop Engine (MSDE). Express and MSDE are free versions of SQL limited to five concurrent users and a maximum database file size of 10GB (SQL Express 2008 R2 and later) or 2 GB respectively. Note that it is very important to make sure regular GeoCue database backups are integrated with your standard IT backup and archiving policies. Failure to back-up your GeoCue database on a regular basis can result in a significant loss of project data in the case of a hardware or software failure. Once the database size limit will be exceeded GeoCue will no longer be able to store additional metadata about projects as SQL will be unable to allocate additional space in the database - even if the current database size has yet to cross that threshold. Before the file size reaches the database limit of an Express version, it is recommended that a user upgrade to a full version of SQL Server. If a user does not have the ability to upgrade to a full version of SQL Server then the next best option is to delete old or unnecessary projects within the database using project utilities in the GeoCue Client. -

Technology Announcement - SQL Server Database Transition
October 20, 2003 Technology Announcement - SQL Server Database Transition DATAIR currently uses the Microsoft JET (Access) MDB database for its Windows- based products. Due to Microsoft’s announcement that this technology is no longer under active development, DATAIR has decided to transition its products to the Microsoft SQL Server client/server database platform tentatively scheduled to begin late in the first quarter of 2004. Moving to SQL Server will allow us to attain even greater levels of application performance, reliability, and scalability. We have prepared the following summary in Q&A format to help you understand what this change will mean to you, and the steps you may need to take to prepare for this transition. What does this mean to you? First and foremost, SQL Server is a client/server database technology unlike JET. When configured properly, client/server databases can offer higher levels of performance and stability than file based databases. Will my data transfer from my JET database? Yes, we will include a utility to transfer your data from current database to your new one. Do I need to buy SQL Server? Not necessarily. DATAIR will be including a limited version of SQL Server called the Microsoft SQL Desktop Engine (MSDE) that Microsoft allows us to distribute free of charge. Depending on the number of simultaneous users, and the type of work they will be doing, MSDE may be all you need. How many users can MSDE support? MSDE is designed to support a maximum of 5 simultaneous operations. That’s not to be confused with 5 users. -

Dell Openmanage IT Assistant Version 8.9 Release Notes
Dell OpenManage IT Assistant Version 8.9 Release Notes What’s New New major features Now, you can launch the warranty support site and view the current warranty information. In addition to the Express Service Code for PowerEdge servers; now, IT Assistant displays Chassis Express Service code and Chassis Service Tag for PowerEdge Blade servers running OpenManage Server administrator version 6.5 or later. You can also see Enclosure specific Express service code in the Details tab. New OS Support Microsoft Windows 2008 Standard Server NOTE: These operating systems must be WoW64 enabled. Deprecated features The following features are not supported in IT Assistant: Topology view Volume Information Report—As IT Assistant does not support Volume Info Report, this will be removed if you upgrade from previous version to IT Assistant 8.9. Installation For information on Installation, see the Dell OpenManage IT Assistant version 8.9 on support.dell.com/manuals Prerequisites For more information on Operating system, Browser & Consoles, and Minimum hardware Configuration see the Dell Systems Software Support Matrix Version 6.5 on support.dell.com/manuals Database (SQL Server) SQL Server 2008 R2 (This is part of IT Assistant install). Also supports: SQL Server 2000 SQL Server 2005 SP1/SP2 Additional Softwares Navisphere(R) Secure CLI For Dell/EMC storage arrays inventory, ensure your array is FLARE(R) version 19 or above. You should also install Navisphere(R) Secure CLI (version 19 or above) on your management station. NOTE: This CLI software -

Address-Space Randomization for Windows Systems
Address-Space Randomization for Windows Systems∗ Lixin Li and JamesE.Just R.Sekar Global InfoTek, Inc., Reston, VA Stony Brook University, Stony Brook, NY {nli,jjust}@globalinfotek.com [email protected] Abstract Wehntrust [21] and Ozone [20]. In addition, Windows Address-space randomization (ASR) is a promising Vista is going to be shipped with a limited implemen- solution to defend against memory corruption attacks tation of ASR [9]. However, these products suffer from that have contributed to about three-quarters of US- one or more of the following drawbacks: CERT advisories in the past few years. Several tech- • Insufficient range of randomization. Windows Vista niques have been proposed for implementing ASR on randomizes base addresses over a range of 256 possi- Linux, but its application to Microsoft Windows, the ble values. This level of randomization is hardly suf- largest monoculture on the Internet, has not received ficient to defeat targeted attacks: the attacker simply as much attention. We address this problem in this pa- needs to try their attack an average of 128 times be- per and describe a solution that provides about 15-bits fore succeeding. This isn’t likely to significantly slow of randomness in the locations of all (code or data) ob- down self-replicating worms either. Wehntrust and jects. Our randomization is applicable to all processes Ozone provide more randomization, but significantly on a Windows box, including all core system services, less than that of DAWSON in some memory regions as well as applications such as web browsers, office ap- such as the stack. plications, and so on. -

Management System UNIVERGE MA4000 Installation Guide (R9.1.0)
UC for Enterprise (UCE) Management System (UNIVERGE MA4000) Installation Guide NEC NEC Corporation October 2010 NDA-30363, Revision 16 Liability Disclaimer NEC Corporation reserves the right to change the specifications, functions, or features, at any time, without notice. NEC Corporation has prepared this document for the exclusive use of its employees and customers. The information contained herein is the property of NEC Corporation and shall not be reproduced without prior written approval from NEC Corporation © 2010 NEC Corporation Microsoft®, Windows®, SQL Server®, and MSDE® are registered trademarks of Microsoft Corporation. All other brand or product names are or may be trademarks or registered trademarks of, and are used to identify products or services of, their respective owners. i Contents Introduction 1-1 MA4000 Overview. 1-1 How This Guide is Organized . 1-2 Getting Started 2-1 Web Server Requirements . 2-2 Web Server Recommendations . 2-3 Internet Information Services Requirements. 2-4 WMI and SNMP Requirements. 2-8 Database Server Requirements . 2-10 Database Storage Requirements . 2-10 SQL Server 2008 Installation Requirements. 2-11 SQL Server 2005 Installation Requirements. 2-12 Authentication Mode Configuration. 2-14 Distributed Transaction Coordinator . 2-15 Remote Database Connections . 2-17 Web Client Requirements . 2-24 Installation 3-1 Installing MA4000 . 3-1 Web Site and Application Pool (Advanced Mode) . 3-8 NEC Centralized Authentication Service Location . 3-9 Database Installation (Advanced Mode) . 3-9 Database Password (Advanced Mode) . 3-12 SQL Server Express Prerequisites . 3-14 Database User Account (Advanced Mode). 3-17 Database Settings (Advanced Mode) . 3-18 Windows User Account (Advanced Mode) . -

Advanced Vbscript for Microsoft Windows Administrators Ebook
6-2244-2eBookFM.book Page 1 Thursday, December 15, 2005 5:22 PM 6-2244-2eBookFM.book Page ii Thursday, December 15, 2005 5:22 PM PUBLISHED BY Microsoft Press A Division of Microsoft Corporation One Microsoft Way Redmond, Washington 98052-6399 Copyright © 2006 by Don Jones and Jeffery Hicks All rights reserved. No part of the contents of this book may be reproduced or transmitted in any form or by any means without the written permission of the publisher. Library of Congress Control Number 2005937886 Printed and bound in the United States of America. 1 2 3 4 5 6 7 8 9 QWT 9 8 7 6 5 Distributed in Canada by H.B. Fenn and Company Ltd. A CIP catalogue record for this book is available from the British Library. Microsoft Press books are available through booksellers and distributors worldwide. For further information about international editions, contact your local Microsoft Corporation office or contact Microsoft Press Inter- national directly at fax (425) 936-7329. Visit our Web site at www.microsoft.com/mspress. Send comments to [email protected]. Microsoft, Active Directory, ActiveX, Excel, FrontPage, JScript, Microsoft Press, MSDN, Tahoma, Verdana, Visio, Visual Basic, Win32, Windows, the Windows logo, Windows NT, and Windows Server are either registered trademarks or trademarks of Microsoft Corporation in the United States and/or other countries. Other product and company names mentioned herein may be the trademarks of their respective owners. The example companies, organizations, products, domain names, e-mail addresses, logos, people, places, and events depicted herein are fictitious. No association with any real company, organization, product, domain name, e-mail address, logo, person, place, or event is intended or should be inferred. -

Untitled
01_109175 ffirs.qxp 3/5/07 10:20 PM Page iii Professional Microsoft® Virtual Server 2005 Ben Armstrong 01_109175 ffirs.qxp 3/5/07 10:20 PM Page ii 01_109175 ffirs.qxp 3/5/07 10:20 PM Page i Professional Microsoft® Virtual Server 2005 01_109175 ffirs.qxp 3/5/07 10:20 PM Page ii 01_109175 ffirs.qxp 3/5/07 10:20 PM Page iii Professional Microsoft® Virtual Server 2005 Ben Armstrong 01_109175 ffirs.qxp 3/5/07 10:20 PM Page iv Professional Microsoft® Virtual Server 2005 Published by Wiley Publishing, Inc. 10475 Crosspoint Boulevard Indianapolis, IN 46256 www.wiley.com Copyright © 2007 by Wiley Publishing, Inc., Indianapolis, Indiana Published simultaneously in Canada Library of Congress Control Number: 2007006575 ISBN: 978-0-470-10917-5 Manufactured in the United States of America 10 9 8 7 6 5 4 3 2 1 No part of this publication may be reproduced, stored in a retrieval system or transmitted in any form or by any means, electronic, mechanical, photocopying, recording, scanning or otherwise, except as permitted under Sections 107 or 108 of the 1976 United States Copyright Act, without either the prior written permis- sion of the Publisher, or authorization through payment of the appropriate per-copy fee to the Copyright Clearance Center, 222 Rosewood Drive, Danvers, MA 01923, (978) 750-8400, fax (978) 646-8600. Requests to the Publisher for permission should be addressed to the Legal Department, Wiley Publishing, Inc., 10475 Crosspoint Blvd., Indianapolis, IN 46256, (317) 572-3447, fax (317) 572-4355, or online at www.wiley.com/ go/permissions. -

This End-User License Agreement (“EULA”)
END-USER LICENSE AGREEMENT FOR MICROSOFT SOFTWARE IMPORTANT—READ CAREFULLY: This End-User License Agreement (“EULA”) is a legal agreement between you (either an individual or a single entity) and Microsoft Corporation (“Microsoft”) for the Microsoft software that accompanies this EULA, which includes computer software and may include associated media, printed materials, “online” or electronic documentation, and Internet-based services (“Software”). An amendment or addendum to this EULA may accompany the Software. YOU AGREE TO BE BOUND BY THE TERMS OF THIS EULA BY INSTALLING, COPYING, OR OTHERWISE USING THE SOFTWARE. IF YOU DO NOT AGREE, DO NOT INSTALL, COPY, OR USE THE SOFTWARE; YOU MAY RETURN IT TO YOUR PLACE OF PURCHASE (IF APPLICABLE) FOR A FULL REFUND. MICROSOFT SOFTWARE LICENSE 1. GRANTS OF LICENSE . Microsoft grants you the rights described in this EULA provided that you comply with all terms and conditions of this EULA. NOTE: Microsoft is not licensing to you any rights with respect to Crystal Reports for Microsoft Visual Studio .NET; your use of Crystal Reports for Microsoft Visual Studio .NET is subject to your acceptance of the terms and conditions of the enclosed (hard copy) end user license agreement from Crystal Decisions for that product . 1.1 General License Grant . Microsoft grants to you as an individual, a personal, nonexclusive license to use the Software, and to make and use copies of the Software for the purposes of designing, developing, testing, and demonstrating your software product(s), provided that you are the only individual using the Software. If you are an entity, Microsoft grants to you a personal, nonexclusive license to use the Software, and to make and use copies of the Software, provided that for each individual using the Software within your organization, you have acquired a separate and valid license for each such individual. -

Distributing SQL Server with Applications After Building and Testing a Microsoft® SQL Server™ 2000 Application, You Must Distribute It to Customers
Distributing SQL Server Applications Distributing SQL Server with Applications After building and testing a Microsoft® SQL Server™ 2000 application, you must distribute it to customers. You must also be able to distribute the SQL Server components required by your application. There are two options for how you distribute SQL Server components with your application: Distribute the SQL Server 2000 relational database engine and client components with your application. Distribute only the SQL Server 2000 client components if your customers will already have an instance of SQL Server to which they can connect from your application. The licensing terms controlling the redistribution of SQL Server components are defined in the file Redist.txt, which is located on your SQL Server compact disc. Distributing the SQL Server 2000 Desktop Engine The SQL Server 2000 Desktop Engine is a redistributable version of the relational database engine in SQL Server 2000. It allows an application that uses the SQL Server relational database engine to install the engine as a part of the application setup process. The Desktop Engine is designed so that an application can use it to store data without requiring any database administration from the end user. The Desktop Engine is designed to manage its configuration and resource usage dynamically, minimizing the requirement for administration of the engine after it has been installed. The Desktop Engine does not include SQL Server utilities or tools that have graphical user interfaces. The application setup is coded to install the engine. After the Desktop Engine has been installed, either the application setup or the application use the standard SQL Server APIs (SQL- DMO, Transact-SQL, and so on) to create and configure the database, and the application uses the SQL Server APIs to perform any needed administration. -
Compatibility List
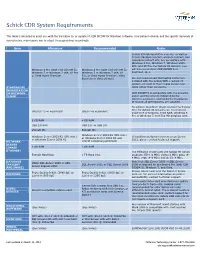
Schick CDR System Requirements This table is intended to assist you with the transition to, or update of, CDR DICOM for Windows software. Your patient volume, and the specific demands of your practice, may require you to adjust these guidelines accordingly. Item Minimum Recommended Notes Schick 33 high-resolution sensors, as well as Schick standard sensors, wireless sensors, and panoramic retrofit kits, are compatible with Windows 8 Pro, Windows 7, Windows Vista SP2, and XP Pro. For Schick 33 sensors, you Windows 8 Pro (with CDR DICOM 5), Windows 8 Pro (with CDR DICOM 5), will also need either CDR DICOM 5 or Windows 7 or Windows 7 x64, XP Pro Windows 7 or Windows 7 x64, XP EagleSoft 16.1. or Vista Home Premium Pro, or Vista Home Premium, Vista Business or Vista Ultimate We also recommend that laptop customers installed with the Schick WiFi + Schick 33 system, connect to their image server over STANDALONE cable rather than wirelessly. WORKSTATION OR NETWORK CDR DICOM 5 is compatible with the systems CLIENT above and the servers indicated below. Internet access is required during installation to ensure all prerequisites are satisfied. To achieve maximum image transfer-to-display time for Schick 33 Sensors, we recommend Intel i3 / i5 or equivalent Intel i7 or equivalent quad-core processors, 8 GB RAM, Windows 8 Pro or Windows 7, and 512 MB graphics card. 2 GB RAM 4 GB RAM USB 2.0 Port USB 2.0 or USB 3.0 250 GB HD 500 GB HD Windows Server 2003 R2 (SP1 min.) Windows Server 2003 R2 (SP1 min.) If installing on domain servers or on Server or Windows Server 2008 R2 and or Windows Server 2008 R2 2012, please contact technical support. -

Autotestsql Operation Manual
AutoTestSQL Operation Manual AutoTestSQL Operation Manual by Liam Elliott This manual is also available as 'on-line help' from the dScope software. You can access the on-line help from the 'Help' menu. The on-line version is context-sensitive: by pressing F1, you can get immediate help for whichever menu or dialogue box you are currently using. Table of Contents Part 1 General information 1 Part 2 Introduction to AutoTestSQL 3 1 About... .this....... .manual............. ........................................................................................................ 3 Part 3 Operation overview 7 1 How. .it.. .works.......... .................................................................................................................. 7 2 Getting...... .started............ .............................................................................................................. 7 3 User. .interface............... .basics........... .................................................................................................... 9 4 AutoTestSQL.................. .modes............ .................................................................................................. 10 5 Reporting............ ..................................................................................................................... 10 6 AutoTestSQL.................. .and....... .dScope............. ......................................................................................... 10 7 Licensing............ ....................................................................................................................