Learned Video Compression
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Thumbor-Video-Engine Release 1.2.2
thumbor-video-engine Release 1.2.2 Aug 14, 2021 Contents 1 Installation 3 2 Setup 5 2.1 Contents.................................................6 2.2 License.................................................. 13 2.3 Indices and tables............................................ 13 i ii thumbor-video-engine, Release 1.2.2 thumbor-video-engine provides a thumbor engine that can read, crop, and transcode audio-less video files. It supports input and output of animated GIF, animated WebP, WebM (VP9) video, and MP4 (default H.264, but HEVC is also supported). Contents 1 thumbor-video-engine, Release 1.2.2 2 Contents CHAPTER 1 Installation pip install thumbor-video-engine Go to GitHub if you need to download or install from source, or to report any issues. 3 thumbor-video-engine, Release 1.2.2 4 Chapter 1. Installation CHAPTER 2 Setup In your thumbor configuration file, change the ENGINE setting to 'thumbor_video_engine.engines. video' to enable video support. This will allow thumbor to support video files in addition to whatever image formats it already supports. If the file passed to thumbor is an image, it will use the Engine specified by the configuration setting IMAGING_ENGINE (which defaults to 'thumbor.engines.pil'). To enable transcoding between formats, add 'thumbor_video_engine.filters.format' to your FILTERS setting. If 'thumbor.filters.format' is already present, replace it with the filter from this pack- age. ENGINE = 'thumbor_video_engine.engines.video' FILTERS = [ 'thumbor_video_engine.filters.format', 'thumbor_video_engine.filters.still', ] To enable automatic transcoding to animated gifs to webp, you can set FFMPEG_GIF_AUTO_WEBP to True. To use this feature you cannot set USE_GIFSICLE_ENGINE to True; this causes thumbor to bypass the custom ENGINE altogether. -

Opus, a Free, High-Quality Speech and Audio Codec
Opus, a free, high-quality speech and audio codec Jean-Marc Valin, Koen Vos, Timothy B. Terriberry, Gregory Maxwell 29 January 2014 Xiph.Org & Mozilla What is Opus? ● New highly-flexible speech and audio codec – Works for most audio applications ● Completely free – Royalty-free licensing – Open-source implementation ● IETF RFC 6716 (Sep. 2012) Xiph.Org & Mozilla Why a New Audio Codec? http://xkcd.com/927/ http://imgs.xkcd.com/comics/standards.png Xiph.Org & Mozilla Why Should You Care? ● Best-in-class performance within a wide range of bitrates and applications ● Adaptability to varying network conditions ● Will be deployed as part of WebRTC ● No licensing costs ● No incompatible flavours Xiph.Org & Mozilla History ● Jan. 2007: SILK project started at Skype ● Nov. 2007: CELT project started ● Mar. 2009: Skype asks IETF to create a WG ● Feb. 2010: WG created ● Jul. 2010: First prototype of SILK+CELT codec ● Dec 2011: Opus surpasses Vorbis and AAC ● Sep. 2012: Opus becomes RFC 6716 ● Dec. 2013: Version 1.1 of libopus released Xiph.Org & Mozilla Applications and Standards (2010) Application Codec VoIP with PSTN AMR-NB Wideband VoIP/videoconference AMR-WB High-quality videoconference G.719 Low-bitrate music streaming HE-AAC High-quality music streaming AAC-LC Low-delay broadcast AAC-ELD Network music performance Xiph.Org & Mozilla Applications and Standards (2013) Application Codec VoIP with PSTN Opus Wideband VoIP/videoconference Opus High-quality videoconference Opus Low-bitrate music streaming Opus High-quality music streaming Opus Low-delay -

Encoding H.264 Video for Streaming and Progressive Download
W4: KEY ENCODING SKILLS, TECHNOLOGIES TECHNIQUES STREAMING MEDIA EAST - 2019 Jan Ozer www.streaminglearningcenter.com [email protected]/ 276-235-8542 @janozer Agenda • Introduction • Lesson 5: How to build encoding • Lesson 1: Delivering to Computers, ladder with objective quality metrics Mobile, OTT, and Smart TVs • Lesson 6: Current status of CMAF • Lesson 2: Codec review • Lesson 7: Delivering with dynamic • Lesson 3: Delivering HEVC over and static packaging HLS • Lesson 4: Per-title encoding Lesson 1: Delivering to Computers, Mobile, OTT, and Smart TVs • Computers • Mobile • OTT • Smart TVs Choosing an ABR Format for Computers • Can be DASH or HLS • Factors • Off-the-shelf player vendor (JW Player, Bitmovin, THEOPlayer, etc.) • Encoding/transcoding vendor Choosing an ABR Format for iOS • Native support (playback in the browser) • HTTP Live Streaming • Playback via an app • Any, including DASH, Smooth, HDS or RTMP Dynamic Streaming iOS Media Support Native App Codecs H.264 (High, Level 4.2), HEVC Any (Main10, Level 5 high) ABR formats HLS Any DRM FairPlay Any Captions CEA-608/708, WebVTT, IMSC1 Any HDR HDR10, DolbyVision ? http://bit.ly/hls_spec_2017 iOS Encoding Ladders H.264 HEVC http://bit.ly/hls_spec_2017 HEVC Hardware Support - iOS 3 % bit.ly/mobile_HEVC http://bit.ly/glob_med_2019 Android: Codec and ABR Format Support Codecs ABR VP8 (2.3+) • Multiple codecs and ABR H.264 (3+) HLS (3+) technologies • Serious cautions about HLS • DASH now close to 97% • HEVC VP9 (4.4+) DASH 4.4+ Via MSE • Main Profile Level 3 – mobile HEVC (5+) -

CALIFORNIA STATE UNIVERSITY, NORTHRIDGE Optimized AV1 Inter
CALIFORNIA STATE UNIVERSITY, NORTHRIDGE Optimized AV1 Inter Prediction using Binary classification techniques A graduate project submitted in partial fulfillment of the requirements for the degree of Master of Science in Software Engineering by Alex Kit Romero May 2020 The graduate project of Alex Kit Romero is approved: ____________________________________ ____________ Dr. Katya Mkrtchyan Date ____________________________________ ____________ Dr. Kyle Dewey Date ____________________________________ ____________ Dr. John J. Noga, Chair Date California State University, Northridge ii Dedication This project is dedicated to all of the Computer Science professors that I have come in contact with other the years who have inspired and encouraged me to pursue a career in computer science. The words and wisdom of these professors are what pushed me to try harder and accomplish more than I ever thought possible. I would like to give a big thanks to the open source community and my fellow cohort of computer science co-workers for always being there with answers to my numerous questions and inquiries. Without their guidance and expertise, I could not have been successful. Lastly, I would like to thank my friends and family who have supported and uplifted me throughout the years. Thank you for believing in me and always telling me to never give up. iii Table of Contents Signature Page ................................................................................................................................ ii Dedication ..................................................................................................................................... -

Comparative Assessment of H.265/MPEG-HEVC, VP9, and H.264/MPEG-AVC Encoders for Low-Delay Video Applications
Pre-print of a paper to be published in SPIE Proceedings, vol. 9217, Applications of Digital Image Pro- cessing XXXVII Comparative Assessment of H.265/MPEG-HEVC, VP9, and H.264/MPEG-AVC Encoders for Low-Delay Video Applications Dan Grois*a, Detlev Marpea, Tung Nguyena, and Ofer Hadarb aImage Processing Department, Fraunhofer Heinrich-Hertz-Institute (HHI), Berlin, Germany bCommunication Systems Engineering Department, Ben-Gurion University of the Negev, Beer-Sheva, Israel ABSTRACT The popularity of low-delay video applications dramatically increased over the last years due to a rising demand for real- time video content (such as video conferencing or video surveillance), and also due to the increasing availability of rela- tively inexpensive heterogeneous devices (such as smartphones and tablets). To this end, this work presents a compara- tive assessment of the two latest video coding standards: H.265/MPEG-HEVC (High-Efficiency Video Coding), H.264/MPEG-AVC (Advanced Video Coding), and also of the VP9 proprietary video coding scheme. For evaluating H.264/MPEG-AVC, an open-source x264 encoder was selected, which has a multi-pass encoding mode, similarly to VP9. According to experimental results, which were obtained by using similar low-delay configurations for all three examined representative encoders, it was observed that H.265/MPEG-HEVC provides significant average bit-rate sav- ings of 32.5%, and 40.8%, relative to VP9 and x264 for the 1-pass encoding, and average bit-rate savings of 32.6%, and 42.2% for the 2-pass encoding, respectively. On the other hand, compared to the x264 encoder, typical low-delay encod- ing times of the VP9 encoder, are about 2,000 times higher for the 1-pass encoding, and are about 400 times higher for the 2-pass encoding. -

AVC, HEVC, VP9, AVS2 Or AV1? — a Comparative Study of State-Of-The-Art Video Encoders on 4K Videos
AVC, HEVC, VP9, AVS2 or AV1? | A Comparative Study of State-of-the-art Video Encoders on 4K Videos Zhuoran Li, Zhengfang Duanmu, Wentao Liu, and Zhou Wang University of Waterloo, Waterloo, ON N2L 3G1, Canada fz777li,zduanmu,w238liu,[email protected] Abstract. 4K, ultra high-definition (UHD), and higher resolution video contents have become increasingly popular recently. The largely increased data rate casts great challenges to video compression and communication technologies. Emerging video coding methods are claimed to achieve su- perior performance for high-resolution video content, but thorough and independent validations are lacking. In this study, we carry out an in- dependent and so far the most comprehensive subjective testing and performance evaluation on videos of diverse resolutions, bit rates and content variations, and compressed by popular and emerging video cod- ing methods including H.264/AVC, H.265/HEVC, VP9, AVS2 and AV1. Our statistical analysis derived from a total of more than 36,000 raw sub- jective ratings on 1,200 test videos suggests that significant improvement in terms of rate-quality performance against the AVC encoder has been achieved by state-of-the-art encoders, and such improvement is increas- ingly manifest with the increase of resolution. Furthermore, we evaluate state-of-the-art objective video quality assessment models, and our re- sults show that the SSIMplus measure performs the best in predicting 4K subjective video quality. The database will be made available online to the public to facilitate future video encoding and video quality research. Keywords: Video compression, quality-of-experience, subjective qual- ity assessment, objective quality assessment, 4K video, ultra-high-definition (UHD), video coding standard 1 Introduction 4K, ultra high-definition (UHD), and higher resolution video contents have en- joyed a remarkable growth in recent years. -

Performance Comparison of AV1, JEM, VP9, and HEVC Encoders
To be published in Applications of Digital Image Processing XL, edited by Andrew G. Tescher, Proceedings of SPIE Vol. 10396 © 2017 SPIE Performance Comparison of AV1, JEM, VP9, and HEVC Encoders Dan Grois, Tung Nguyen, and Detlev Marpe Video Coding & Analytics Department Fraunhofer Institute for Telecommunications – Heinrich Hertz Institute, Berlin, Germany [email protected],{tung.nguyen,detlev.marpe}@hhi.fraunhofer.de ABSTRACT This work presents a performance evaluation of the current status of two distinct lines of development in future video coding technology: the so-called AV1 video codec of the industry-driven Alliance for Open Media (AOM) and the Joint Exploration Test Model (JEM), as developed and studied by the Joint Video Exploration Team (JVET) on Future Video Coding of ITU-T VCEG and ISO/IEC MPEG. As a reference, this study also includes reference encoders of the respective starting points of development, as given by the first encoder release of AV1/VP9 for the AOM-driven technology, and the HM reference encoder of the HEVC standard for the JVET activities. For a large variety of video sources ranging from UHD over HD to 360° content, the compression capability of the different video coding technology has been evaluated by using a Random Access setting along with the JVET common test conditions. As an outcome of this study, it was observed that the latest AV1 release achieved average bit-rate savings of ~17% relative to VP9 at the expense of a factor of ~117 in encoder run time. On the other hand, the latest JEM release provides an average bit-rate saving of ~30% relative to HM with a factor of ~10.5 in encoder run time. -
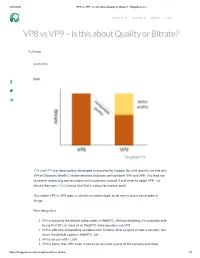
VP8 Vs VP9 – Is This About Quality Or Bitrate?
4/27/2020 VP8 vs VP9 - Is this about Quality or Bitrate? • BlogGeek.me PRODUCTS SERVICES ABOUT BLOG VP8 vs VP9 – Is this about Quality or Bitrate? Technology 09/05/2016 Both. VP8 and VP9 are video codecs developed and pushed by Google. Up until recently, we had only VP8 in Chrome’s WebRTC implementation and now, we have both VP8 and VP9. This lead me to several interesting conversations with customers around if and when to adopt VP9 – or should they use H.264 instead (but that’s a story for another post). This whole VP8 vs VP9 topic is usually misunderstood, so let me try to put some order in things. First things ƒrst: 1. VP8 is currently the default video codec in WebRTC. Without checking, it is probably safe to say that 90% or more of all WebRTC video sessions use VP8 2. VP9 is o∆cially and publicly available from Chrome 49 or so (give or take a version). But it isn’t the default codec in WebRTC. Yet 3. VP8 is on par with H.264 4. VP9 is better than VP8 when it comes to resultant quality of the compressed video https://bloggeek.me/vp8-vs-vp9-quality-or-bitrate/ 1/5 4/27/2020 VP8 vs VP9 - Is this about Quality or Bitrate? • BlogGeek.me 5. VP8 takes up less resources (=CPU) to compress video With that in mind, the following can be deduced: You can use the migration to VP9 for one of two things (or both): 1. Improve the quality of your video experience 2. -

Telestream Cloud High Quality Video Encoding Service in the Cloud
Telestream Cloud High quality video encoding service in the cloud Telestream Cloud is a high quality, video encoding software-as-a-service (SaaS) in the cloud, offering fast and powerful encoding for your workflow. Telestream Cloud pricing is structured as pay-as-you-go monthly subscriptions for quick scaling as your workflow changes with no upfront expenses. Who uses Telestream Cloud? Telestream Cloud’s elegantly simple user interface scales quickly and seamlessly for media professionals who utilize video transcoding heavily in their business like: ■ Advertising agencies ■ On-line broadcasters ■ Gaming ■ Entertainment ■ OTT service provider for media streaming ■ Boutique post production studios For content creators and video producers, Telestream Cloud encoding cloud service is pay-as-you-go, and allows you to collocate video files with your other cloud services across multiple cloud storage options. The service provides high quality output in most formats to meet the needs of: ■ Small businesses ■ Houses of worship ■ Digital marketing ■ Education ■ Nonprofits Telestream Cloud provides unlimited scalability to address peak demand times and encoding requirements for large files for video pros who work in: ■ Broadcast networks ■ Broadcast news or sports ■ Cable service providers ■ Large post-production houses Telestream Cloud is a complementary service to the Vantage platform. During peak demand times, Cloud service can offset the workload. The service also allows easy collaboration of projects across multiple sites or remote locations. Why choose Telestream Cloud? The best video encoding quality for all formats & codecs: An extensive set of encoding profiles built-in for all major formats to ensure the output is optimized for the highest quality. -

Video Compression Optimized for Racing Drones
Video compression optimized for racing drones Henrik Theolin Computer Science and Engineering, master's level 2018 Luleå University of Technology Department of Computer Science, Electrical and Space Engineering Video compression optimized for racing drones November 10, 2018 Preface To my wife and son always! Without you I'd never try to become smarter. Thanks to my supervisor Staffan Johansson at Neava for providing room, tools and the guidance needed to perform this thesis. To my examiner Rickard Nilsson for helping me focus on the task and reminding me of the time-limit to complete the report. i of ii Video compression optimized for racing drones November 10, 2018 Abstract This thesis is a report on the findings of different video coding tech- niques and their suitability for a low powered lightweight system mounted on a racing drone. Low latency, high consistency and a robust video stream is of the utmost importance. The literature consists of multiple comparisons and reports on the efficiency for the most commonly used video compression algorithms. These reports and findings are mainly not used on a low latency system but are testing in a laboratory environment with settings unusable for a real-time system. The literature that deals with low latency video streaming and network instability shows that only a limited set of each compression algorithms are available to ensure low complexity and no added delay to the coding process. The findings re- sulted in that AVC/H.264 was the most suited compression algorithm and more precise the x264 implementation was the most optimized to be able to perform well on the low powered system. -

RULING CODECS of VIDEO COMPRESSION and ITS FUTURE 1Dr.Manju.V.C, 2Apsara and 3Annapoorna
International Journal of Application or Innovation in Engineering & Management (IJAIEM) Web Site: www.ijaiem.org Email: [email protected] Volume 8, Issue 7, July 2019 ISSN 2319 - 4847 RULING CODECS OF VIDEO COMPRESSION AND ITS FUTURE 1Dr.Manju.v.C, 2Apsara and 3Annapoorna 1Professor,KSIT 2Under-Gradute, Telecommunication Engineering, KSIT 3Under-Gradute, Telecommunication Engineering, KSIT Abstract Development of economical video codecs for low bitrate video transmission with higher compression potency has been a vigorous space of analysis over past years and varied techniques are projected to fulfill this need. Video Compression is a term accustomed outline a technique for reducing the information accustomed cipher digital video content. This reduction in knowledge interprets to edges like smaller storage needs and lower transmission information measure needs, for a clip of video content. In this paper, we survey different video codec standards and also discuss about the challenges in VP9 codec Keywords: Codecs, HEVC, VP9, AV1 1. INTRODUCTION Storing video requires a lot of storage space. To make this task manageable, video compression technology was developed to compress video, also known as a codec. Video coding techniques provide economic solutions to represent video data in a more compact and stout way so that the storage and transmission of video will be completed in less value in less cost in terms of bandwidth, size and power consumption. This technology (video compression) reduces redundancies in spatial and temporal directions. Spatial reduction physically reduces the size of the video data by selectively discarding up to a fourth or more of unneeded parts of the original data in a frame [1]. -

Speeding up VP9 Intra Encoder with Hierarchical Deep Learning Based Partition Prediction Somdyuti Paul, Andrey Norkin, and Alan C
IEEE TRANSACTIONS ON IMAGE PROCESSING 1 Speeding up VP9 Intra Encoder with Hierarchical Deep Learning Based Partition Prediction Somdyuti Paul, Andrey Norkin, and Alan C. Bovik Abstract—In VP9 video codec, the sizes of blocks are decided during encoding by recursively partitioning 64×64 superblocks using rate-distortion optimization (RDO). This process is com- putationally intensive because of the combinatorial search space of possible partitions of a superblock. Here, we propose a deep learning based alternative framework to predict the intra- mode superblock partitions in the form of a four-level partition tree, using a hierarchical fully convolutional network (H-FCN). We created a large database of VP9 superblocks and the corresponding partitions to train an H-FCN model, which was subsequently integrated with the VP9 encoder to reduce the intra- mode encoding time. The experimental results establish that our approach speeds up intra-mode encoding by 69.7% on average, at the expense of a 1.71% increase in the Bjøntegaard-Delta bitrate (BD-rate). While VP9 provides several built-in speed levels which are designed to provide faster encoding at the expense of decreased rate-distortion performance, we find that our model is able to outperform the fastest recommended speed level of the reference VP9 encoder for the good quality intra encoding configuration, in terms of both speedup and BD-rate. Fig. 1. Recursive partition of VP9 superblock at four levels showing the possible types of partition at each level. Index Terms—VP9, video encoding, block partitioning, intra prediction, convolutional neural networks, machine learning. supports partitioning a block into four square quadrants, VP9 I.